Hurst指数以及MF-DFA
转:https://uqer.io/home/
https://uqer.io/community/share/564c3bc2f9f06c4446b48393
写在前面
9月的时候说想把arch包加进去,昨儿发现优矿已经加好了,由于优矿暂时没有开放历史高频接口,我索性就分享一个冷冷的小知识:分形市场假说(FMH),分析中玩的是低频数据(日线,或者分钟线)。
所谓分形市场假说,就是人们发现有效市场假说的种种不合理后,提出的一种假说,我曾经有仔细关注过这一块,因为这个假说真是太「中国特色」了:
它有几个主要论点:
- 当市场是由各种投资期限的投资者组成时,市场是稳定的(长期投资者和短期投资者),当投资者单一时,则市场会出流动性问题;
- 信息集对基本分析和技术分析来讲短期影响比长期影响要大;
- 当某一事件的出现使得基础分析的有效性值得怀疑时,长期投资者或者停止入市操作或者基于短期信息进行买卖;
- 价格是短期技术分析和长期基础分析的综合反应;
- 如果某种证券与经济周期无关,那么它本身就不存在长期趋势。此时,交易行为、市场流动性和短期信息将占主导地位。
- 总之就是一个具有「正反馈、非线性、分形、混沌、耗散」等等很牛逼的概念,深深吸引着曾经学过物理学的我。。。
关于Hurst指数以及MF-DFA
现在对于分形市场假说的主要方法论就是 Hurst指数,通过MF-DFA(Multifractal detrended fluctuation analysis)来计算, 具体的可以维基百科一下,大体就是当hurst>0.5时时间序列是一个persistent的过程,当hurst>0.5时时间序列是一个anti-persistent的过程,当hurst=0.5时间序列是一个不存在记忆的随机游走过程。
而在实际计算中,不会以理论值0.5作为标准(一般会略大于0.5)
写在最后
- 这份工作来自于LADISLAV KRISTOUFEK这位教授在12年的工作,论文名叫做RACTAL MARKETS HYPOTHESIS AND THE GLOBAL FINANCIAL CRISIS: SCALING, INVESTMENT HORIZONS AND LIQUIDITY
- 这位教授后来在13年把这项工作强化了一下(加了点小波的方法),把论文的图画得美美哒,竟然发表在了Nature的子刊Scientific Report上。当年我的导师发了一篇SR可是全校通报表扬啊,虽然现在我以前在物理系的导师说今年有4篇SR发表。。
- 总之,如果谁对这个感兴趣,或者想在Nature上水一篇文章,可以研究研究。
- 这个方法对设计策略有没有什么用? 好像没有用哎,所以我发表在「研究」板块里了哈。不过10年海通有研究员测试过根据这个方法写的策略,据说alpha还不错。
- 算法部分我用的是自己的library库。
import numpy as np
import pandas as pd
from arch import arch_model # GARCH(1,1)
from matplotlib import pyplot as plt
from datetime import timedelta
from CAL.PyCAL import *
from lib.Hurst import * inter = 320 #滑动时间窗口
#设置时间
today = Date.todaysDate()
beginDate = ''
endDate = today.toDateTime().strftime('%Y%m%d') #设置指数类型
indexLabel = '' # SSE index
#indexLabel = '399006' # CYB index #读取指数
indexPrice = DataAPI.MktIdxdGet(ticker=indexLabel,beginDate=beginDate,endDate=endDate,field=["tradeDate","closeIndex"],pandas="")
price = np.array(indexPrice.loc[:,'closeIndex']) #计算对数收益
back_price = np.append(price[0],price.copy())
back_price = back_price[:-1]
return_price = np.log(price) - np.log(back_price) #计算波动率 from GARCH(1,1)
am = arch_model(return_price)
res = am.fit()
sqt_h = res.conditional_volatility #去除波动性
f = return_price/sqt_h #计算hurst指数,函数来自自定义library
hurst = Hurst(f,T=inter,step=1,q=2,Smin=10,Smax=50,Sintr=1) indexPrice['Hurst'] = pd.DataFrame(np.array([0] * len(indexPrice)))
indexPrice.loc[inter-1:,'Hurst'] = hurst
indexPrice.index = indexPrice['tradeDate']
plt.figure(figsize=(10,6))
plt.subplot(3,1,1)
plt.plot(f)
plt.subplot(3,1,2)
plt.plot(return_price)
plt.subplot(3,1,3)
plt.plot(sqt_h)
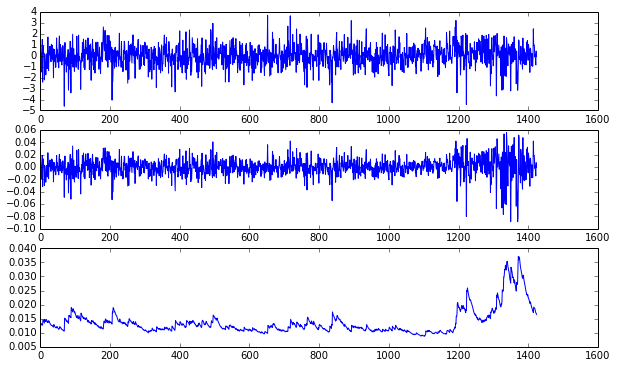
上面的图能够看到garch(1,1)到底做了什么,它主要是对波动率进行了建模,在做分析时消去了这部分的影响。
plt.figure(1)
indexPrice['closeIndex'].tail(len(indexPrice)-inter).plot(figsize=(10,4),color='red',title='SSE Index',linewidth=1)
plt.figure(2)
indexPrice['Hurst'].tail(len(indexPrice)-inter).plot(figsize=(10,4),color='green',title='Hurst Index',linewidth=1,marker='.')
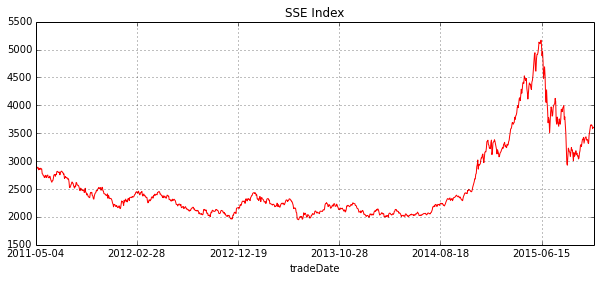

- 看出了啥没?简单点说,就是hurst越大,越有可能延续之前的趋势(即动量),若hurst越小,则越有可能违反之前的趋势(即反转)。LADISLAV KRISTOUFEK这位教授的想法是通过极大极小值来判断,当然它分析的是美股啦。
- 再看看上面的图,是对上证指数的分析,取的是日线的数据(其实我喜欢用分钟线,因为A股波动辣么牛逼,日线颗粒度哪里够啊。。),可以得(meng)出这些结论:
- 13年中旬hurst出现最小值,说明熊市的跌势要反转了,马上要进入牛市了?!
- 15年中旬hurst出现最小值,说明牛市的涨势要反转了,马上要进入熊市了?!
- 算卦完毕。
看到好多人在克隆这份东西,我索性就把自定义的lib分享出来,仅限学术交流。命名为Hurst并添加到library即可。
#coding=utf-8 import numpy as np
from sklearn.linear_model import LinearRegression def avgFluctuation(Xseries,q,S):
lr = LinearRegression(fit_intercept = True)
T = Xseries.shape[0]
Ts = int(T/S)
qorder = q
aFlu = 0
Xtime = np.array(range(1,S+1))
Xtime.shape = (S,1)
for v in range(1,Ts+1):
Xstarts = (v-1)*S
Xends = v*S
Xtemp = Xseries[Xstarts:Xends]
Xtemp.shape = (S,1)
lr.fit(Xtime,Xtemp)
fitX = map(lr.predict,Xtime)
eX = fitX - Xtemp
Flu = np.sum(eX*eX)/S
aFlu += (Flu)**(qorder/2)/(2*Ts)
for v in range(Ts+1,2*Ts+1):
Xstarts = T-(v-Ts)*S
Xends = T-(v-Ts)*S+S
Xtemp = Xseries[Xstarts:Xends]
Xtemp.shape = (S,1)
lr.fit(Xtime,Xtemp)
fitX = map(lr.predict,Xtime)
eX = fitX - Xtemp
Flu = np.sum(eX*eX)/S
aFlu += (Flu)**(qorder/2)/(2*Ts)
aFlu = aFlu**(1./qorder)
return aFlu def MFDFA(Xseries,q,Smin,Smax,Sintr=1):
T = Xseries.shape[0]
N = (Smax - Smin + 1)/Sintr
aFlus = np.zeros(N)
i = 0
for S in range(Smin,Smax+1,Sintr):
aFlus[i] = avgFluctuation(Xseries,q,S)
i += 1
logaFlus = np.log(aFlus)
logS = np.log(range(Smin,Smax+1,Sintr))
lr = LinearRegression(fit_intercept = True)
logaFlus.shape = (N,1)
logS.shape = (N,1)
lr.fit(logS,logaFlus)
h = lr.coef_
return h def Hurst(X,T=300,step=1,q=2,Smin=10,Smax=50,Sintr=1):
X = np.array(X)
nX = X.shape[0]
hurst = np.zeros(nX-T+1)
for i in range(0,nX-T+1,step):
XX = X[i:i+T]
Xseries = np.zeros(T)
for j in range(T):
Xseries[j] = np.sum(XX[0:j+1])
hurst[i] = MFDFA(Xseries,q,Smin,Smax,Sintr)
return hurst
由于上面的代码运行有点问题,下面是我自己改过的代码:
def avgFluctuation(Xseries, q, S):
lr = LinearRegression(fit_intercept = True)
T = Xseries.shape[0]
Ts = int(T/S)
qorder = q
aFlu = 0
Xtime = np.array(range(1, S+1))
Xtime.shape = (S, 1)
for v in range(1, Ts+1):
Xstarts = (v-1)*S
Xends = v*S
Xtemp = Xseries[Xstarts:Xends]
Xtemp.shape = (S, 1)
lr.fit(Xtime, Xtemp)
fitX = list(map(lr.predict, [Xtime]))
eX = fitX - Xtemp
Flu = np.sum(eX*eX) / S
aFlu += (Flu)**(qorder/2) / (2*Ts)
for v in range(Ts+1,2*Ts+1):
Xstarts = T-(v-Ts)*S
Xends = T-(v-Ts)*S+S
Xtemp = Xseries[Xstarts:Xends]
Xtemp.shape = (S,1)
lr.fit(Xtime,Xtemp)
fitX = list(map(lr.predict, [Xtime]))
eX = fitX - Xtemp
Flu = np.sum(eX*eX) / S
aFlu += (Flu)**(qorder/2) / (2*Ts)
aFlu = aFlu**(1./qorder)
return aFlu def MFDFA(Xseries, q, Smin, Smax, Sintr=1):
T = Xseries.shape[0]
N = int((Smax - Smin + 1) / Sintr)
aFlus = np.zeros(N)
i = 0
for S in range(Smin, Smax+1, Sintr):
aFlus[i] = avgFluctuation(Xseries, q, S)
i += 1
logaFlus = np.log(aFlus)
logS = np.log(range(Smin, Smax+1, Sintr))
lr = LinearRegression(fit_intercept = True)
logaFlus.shape = (N,1)
logS.shape = (N,1)
lr.fit(logS, logaFlus)
h = lr.coef_
return h def Hurst(X, T=300, step=1, q=2, Smin=10, Smax=50, Sintr=1):
X = np.array(X)
nX = X.shape[0]
hurst = np.zeros(nX-T+1)
for i in range(0, nX-T+1, step):
XX = X[i:i+T]
Xseries = np.zeros(T)
for j in range(T):
Xseries[j] = np.sum(XX[0:j+1])
hurst[i] = MFDFA(Xseries, q, Smin, Smax, Sintr)
return hurst
Hurst指数以及MF-DFA的更多相关文章
- 股指的趋势持续研究(Hurst指数)
只贴基本的适合小白的Matlab实现代码,深入的研究除了需要改进算法,我建议好好研究一下混沌与分形,不说让你抓住趋势,至少不会大亏,这个资金盈亏回调我以前研究过. function [line_H,R ...
- 大数据DDos检测——DDos攻击本质上是时间序列数据,t+1时刻的数据特点和t时刻强相关,因此用HMM或者CRF来做检测是必然! 和一个句子的分词算法CRF没有区别!
DDos攻击本质上是时间序列数据,t+1时刻的数据特点和t时刻强相关,因此用HMM或者CRF来做检测是必然!——和一个句子的分词算法CRF没有区别!注:传统DDos检测直接基于IP数据发送流量来识别, ...
- DFA简介
DFA(Detrend Fluctuation Analysis)与scale-free scale-free的本质特征是self-affine or self-similar.具体的,体现在几何上, ...
- 86-Money Flow Index 资金流量指数指标.(2015.7.3)
Money Flow Index 资金流量指数指标 计算: 1.典型价格(TP)=当日最高价.最低价与收盘价的算术平均值 2.货币流量(MF)=典型价格(TP)×N日内成交金额 3.如果当日MF> ...
- 自己实现一个 DFA 串模式识别器
自己实现一个 DFA 串模式识别器 前言 这是我编译原理课程的实验.希望读完这篇文章的人即便不知道 NFA,DFA 和正规表达式是什么,也能够对它们有一个简单的理解,并能自己去实现一个能够识别特定模式 ...
- 基于DFA敏感词查询的算法简析
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.背景 项目中需要对敏感词做一个过滤,首先有几个方案可以选择: a.直 ...
- 【.NET MF】.NET Micro Framework USB移植
1.开发环境 windows 7 32位 MDK 4.54 .Net Micro Framework Porting Kit 4.2(RTM QFE2) .Net Micro Framework ...
- java实现敏感词过滤(DFA算法)
小Alan在最近的开发中遇到了敏感词过滤,便去网上查阅了很多敏感词过滤的资料,在这里也和大家分享一下自己的理解. 敏感词过滤应该是不用给大家过多的解释吧?讲白了就是你在项目中输入某些字(比如输入xxo ...
- 使用DFA做文本编辑器的自动提示
之前看龙书的时候,龙书提到可以在编译器里用动态的生成的NFA自动机来动态匹配自己的输入串,NFA的简单实现其实写起来非常简单,但是我是实际凭感觉写完之后,却觉得并不是非常的好用,在处理自己已经输入过的 ...
随机推荐
- hadoop单节点配置
首先按照官网的单机去配置,如果官网不行的话可以参考一下配置,这个是配置成功过的.但是不一定每次都成功 http://hadoop.apache.org/docs/r2.6.5/ centos 6.7 ...
- busybox中的inittab解析
init进程是由内核启动的第一个(也是唯一一个)用户进程(进程ID为1),是所有进程的祖先.然后init进程根据配置文件决定启动哪些程序,init是后续所有进程的发起者. 用busybox制作的文件系 ...
- 善用php-fpm的慢执行日志slow log,分析php性能问题
众所周知,mysql有slow query log,根据慢查询日志,我们可以知道那些sql语句有性能问题.作为mysql的好搭档,php也有这样的功能.如果你使用php-fpm来管理php的话,你可以 ...
- sublime text 格式化html css 与显示函数列表
sublime 格式化html css 1.ctrl + shift + p 2.输入install package,选择install package 3.输入:HTML-CSS-JS Pretti ...
- RMAN Restore, Recovery
Complete recovery: rman target / nocatalog startup mount; restore database; recover database; alter ...
- datagrid 溢出文本显示省略号
.datagrid-cell, .datagrid-cell-group, .datagrid-header-rownumber, .datagrid-cell-rownumber{ -o-text- ...
- android RadioGroup实现单选以及默认选中
代码下载链接:http://download.csdn.net/detail/a123demi/7511835 本文将通过radiogroup和radiobutton实现组内信息的单选, 当中radi ...
- VS中常用的环境变量
环境变量名 含义 $(SolutionDir) 解决方案目录:即.sln文件所在路径 $(ProjectDir) 项目根目录:, 即.vcxproj文件所在路径 $(Configuration) 当前 ...
- 【转】 VC++6.0 在Win7 64位下调试,Shift+F5无法退出
Win7 64位VC++6.0调试代码无法关闭窗口解决方法 VC++6.0 在64位Windows7下调试的时候,再结束调试,程序无法退出,只能关闭VC++6.0 IDE环境. 问题描述:当我击F5开 ...
- Telnet发送邮件之聊以自慰
北京的冬天,闲着无聊,得做点什么暖暖脑袋,用windows系统自带工具telnet玩了把邮件发送 准备工作: 1.打开windows系统telnet客户端功能 2.准备两个邮箱帐号(xxx@163.c ...