【spark】IDEA建立基于scala语言的spark项目
1.新建一个Spark项目
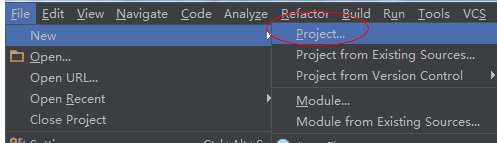
2.选择maven,用模板创建项目
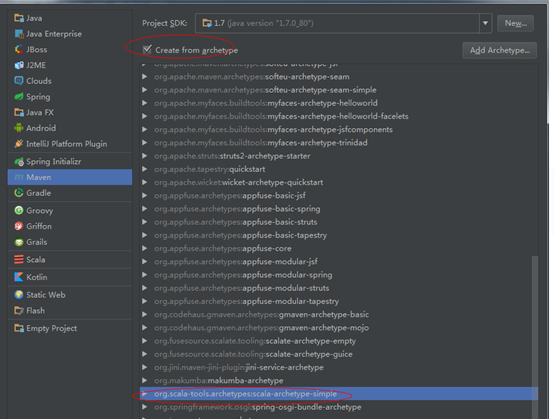
如果 没有这个模板,我们需要添加一个
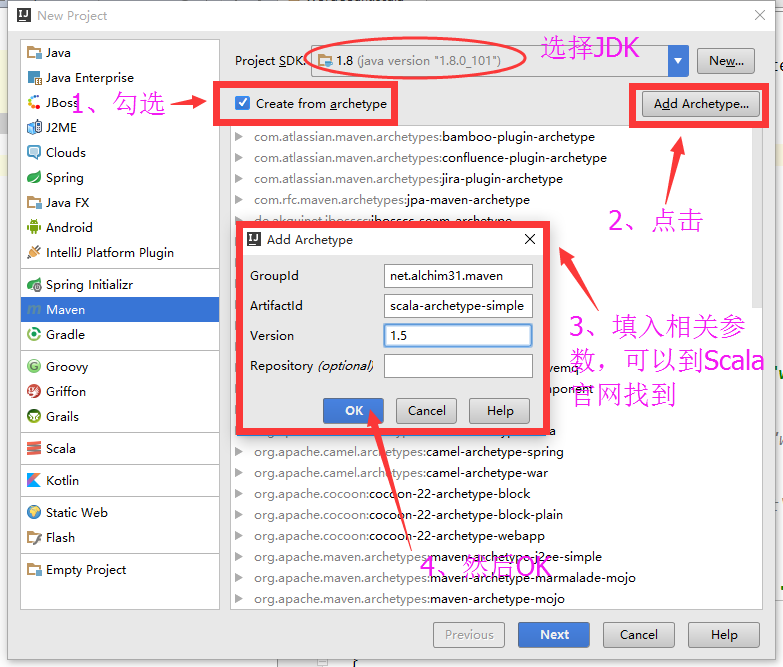
我们这里使用的是1.6版本
Archetype Group Id : net.alchim31.maven
Archetype Artifact Id : scala-archetype-simple
Archetype Version : 1.63.填写GoupId等。
4.选择本地的maven配置文件和仓库
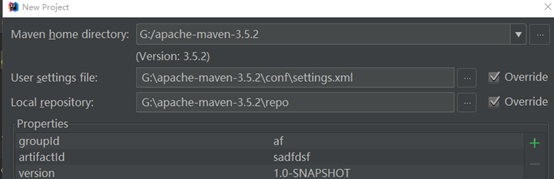
5.创建完毕
这里我们要注意项目pom.xml文件中的配置
核对scala版本
并在pom.xml文件中添加如下信息
<properties>
<scala.version>2.12.3</scala.version>
<spark.version>2.2.0</spark.version>
<hadoop.version>2.6.0</hadoop.version>
<hbase.version>1.2.0</hbase.version>
</properties> <dependencies>
<!--scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency> <!-- hadoop -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency> <!--hbase-->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
</dependencies>
6.更新pom.xml文件
7.编写项目Hello World
8.运行,如果运行的时候报错
(1)
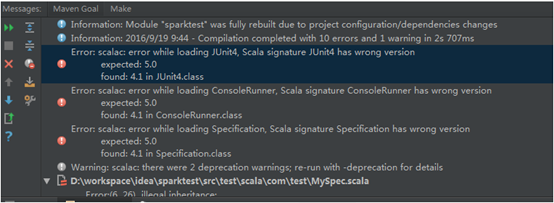
这是由于Junit版本造成的,我们可以删掉Test文件,以及删掉pom.xml文件中测试的相关依赖。
删除
和文件中的
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
我们可以也可以修改相应的版本为要求版本 4.5
(2)
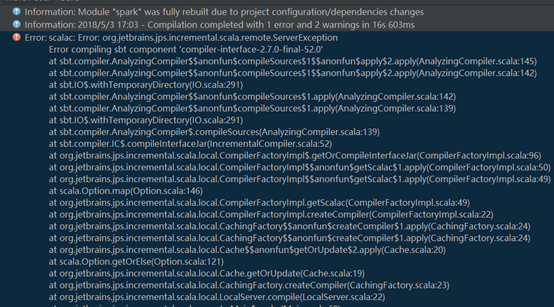
如果出现这种错误,是因为你的scala版本和maven中的scala版本不匹配

修改pom.xml文件中的对应scala版本为你本地的scala版本即可。
【spark】IDEA建立基于scala语言的spark项目的更多相关文章
- 利用Scala语言开发Spark应用程序
Spark内核是由Scala语言开发的,因此使用Scala语言开发Spark应用程序是自然而然的事情.如果你对Scala语言还不太熟悉,可 以阅读网络教程A Scala Tutorial for Ja ...
- 大数据spark学习第一周Scala语言基础
Scala简单介绍 Scala(Scala Language的简称)语言是一种能够执行于JVM和.Net平台之上的通用编程语言.既可用于大规模应用程序开发,也可用于脚本编程,它由由Martin Ode ...
- cloudera manager安装spark后使用spark shell编写基于scala的world count
val file = sc.textFile("hdfs://zhcloudil-lcnode04:8020/user/cloudil/wc_spark.txt") val cou ...
- 基于Spark环境对比Python和Scala语言利弊
在数据挖掘中,Python和Scala语言都是极受欢迎的,本文总结两种语言在Spark环境各自特点. 本文翻译自 https://www.dezyre.com/article/Scala-vs-Py ...
- Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈与熟练的掌握Scala语言【大数据Spark实战高手之路】
Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈 大数据的概念与应用,正随着智能手机.平板电脑的快速流行而日渐普及,大数据中图的并行化处理一直是一个非常热门的话题.图计算正在被广泛地应用于社交 ...
- Intellij IDEA使用Maven搭建spark开发环境(scala)
如何一步一步地在Intellij IDEA使用Maven搭建spark开发环境,并基于scala编写简单的spark中wordcount实例. 1.准备工作 首先需要在你电脑上安装jdk和scala以 ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Spark学习之路(二)—— Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择Spark版本和对应的Hadoop版本后再下载: 解压安装包: ...
随机推荐
- java 使用LinkedList模拟一个堆栈或者队列数据结构
近期在复习下java基础,看了下java基础,在看到集合时突然发现想起来曾经面试有一道笔试题:模拟一个堆栈或者队列数据结构,当时还没做出来,今天就写一下,首先得明确堆栈和队列的数据结构 堆栈:先进后出 ...
- 商业模式画布模板——From 《商业模式新生代》
看过<商业模式新生代>这本书,确实受益匪浅.书籍本身编写的形式很新颖,以此为模板可以启发自己对于商业模式的思考和定义,五星推荐!!! 下面是用PPT重新绘制的商业模式画布以及说明,希望对大 ...
- (4.17)sql server中的uuid获取与使用
sql server中的uuid 建表: 1.自增长 studentno int primary key identity(1,1)——bigint也是可以的 2.创建uuidcustomerid ...
- 你真的会用Gson吗?Gson使用指南
你真的会用Gson吗?Gson使用指南(一) 你真的会用Gson吗?Gson使用指南(二) 你真的会用Gson吗?Gson使用指南(三) 你真的会用Gson吗?Gson使用指南(四)
- django【原生分页】
1.urls.py url(r'^page2/',views.page2), 2.views.py from django.core.paginator import Paginator,PageNo ...
- github-----文件项目的推拉二式
将本地项目文件推送上线: $ git init $ git add . $ git commit -m "第一次修改" $ git log $ git remote add ori ...
- Python高阶函数-闭包
高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回. 在这里我们首先回忆一下python代码运行的时候遇到函数是怎么做的. 从python解释器开始执行之后,就在内存中开辟了一个空间 每当 ...
- Codeforces Round #303 (Div. 2)
A.Toy Cars 题意:给出n辆玩具车两两碰撞的结果,找出没有翻车过的玩具车. 思路:简单题.遍历即可. #include<iostream> #include<cstdio&g ...
- 初学hadoop的个人历程
在学习hadoop之前,我就明确了要致力于大数据行业,成为优秀的大数据研发工程师的目标,有了大目标之后要分几步走,然后每一步不断细分,采用大事化小的方法去学习hadoop.下面开始叙述我是如何初 ...
- gitlab + jenkins + docker + k8s
总体流程: 在开发机开发代码后提交到gitlab 之后通过webhook插件触发jenkins进行构建,jenkins将代码打成docker镜像,push到docker-registry 之后将在k8 ...