Redis(五)--- Redis的持久化RDB与AOF
一、Redis数据库
我们都知道Redis是基于内存的数据库,数据是以key-value键值对的方式存储的,那么key-value键值对是随意放在内存中的么,其实Redis的服务会创建很多的数据库空间,这些key-value键值对都是在各个数据库空间中存储的。
当我们使用客户端工具链接Redis服务时,会在客户端中看到一系列的db*命名的项(如图),这些就是一个个数据库,Redis初始化创建16个数据库,数据库创建个数可以在配置文件中修改。
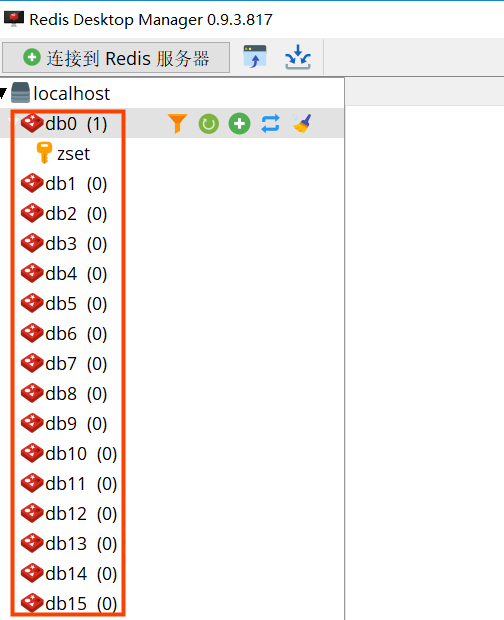
而在命令行模式中是看不到这些数据库的具体数量的,但在命令行提示符的右侧会提示我们当前处于哪个数据库(如图),并且可以用上一章说到的SELECT命令进行数据库的切换;客户端默认连接第一个数据库,即0号数据库。

(1)数据库键空间
key-value键值对存储在各个数据库中,而每个数据库内部都是由一个redisDb结构,结构中有若干个属性,最主要的有两个属性dict、expires。
typedef struct redisDb {
// ...
// 数据库键空间,保存着数据库中的所有键值对
dict *dict;
// 过期字典,保存着键的过期时间
dict *expires;
// ...
} redisDb;
- dict 是字典结构,存储我们的key-value键值对,这个字典称为数据库键空间,字典的键就是数据库的键,每个键都是一个字符串,存储key值;字典的值就是数据库的值,每个值都可以是五大对象中任意一种,存储value值;所以我们存储的key-value最终是在数据库中以字典的结构存储的。
- expires 同样是字典结构,但其存储的是key-value过期时间;当我们设置了key-value的过期时间,那么key-value存储在dict字典中,而过期时间则存储在expires中;字典的键存储key,字典的值存储过期时间;这里需要注意的是,无论设置的过期时间是秒还是毫秒,最终存储时都会转换为unix毫秒时间戳。
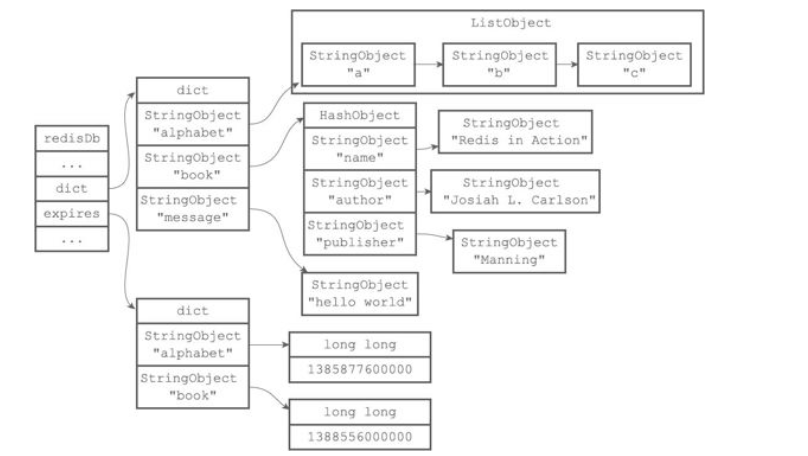
图中是带有过期字典的数据库例子
(2)持久化
上面说道的无论是数据库还是期内的数据都是存储在服务器内内存中的,如果服务器一旦发生掉电,进程退出等情况,那么其内存中的数据就都消失不见了,在我们大规模并发的项目下,显然这是灾难性的,所以应对这种情况的办法之一,就是持久化,把内存中的数放到磁盘中,意外发生后,能够从磁盘上进行数据恢复到内存中,这样就避免了数据丢失。
Redis提供了两种持久化方式RDB持久化和AOF持久化。
2、RDB持久化
RDB持久化是最直接的持久化方式,直接将内存中的数据保存到RDB文件中,当恢复时也是直接从RDB文件中恢复;

- RDB文件是经过压缩的二进制文件,这里对文件结构不做详解。
- RDB持久化可以手动执行,也可以设置定期执行。
- RDB持久化命令有两个SAVE(同步)和BGSAVE(异步),同步持久化过程中,会拒绝客户端的所有请求;异步则是创建子进程执行,不会对客户端产生影响,具体可以看上一章的命令介绍。
自动间隔性保存
因为BGSAVE命令是异步执行,不会阻塞服务器,所以Redis允许用户自行配置SAVE选项,当选项触发时自动执行BGSAVE命令。
当用户开启了触发自动BGSAVE后,如果不配置save选项,服务器会使用默认设置,如下:

(1)在900秒内,对数据库进行了至少1次修改。
(2)在300秒内,对数据库进行了至少10次修改。
(3)在60秒内,对数据库进行了至少10000次修改。
以上三个条件,满足任意一条,就会进行BGSAVE操作
3、AOF持久化
AOF持久化与RDB不同,AOF持久化是通过记录服务器所执行的命令来保存数据的。

- 被写入AOF文件的所有命令都是以Redis请求协议格式保存的。
- 数据的还原,就是通过读取AOF文件的这些命令进行的。
- 执行的命名并不是直接写入AOF文件的,而是先写入缓冲区,没执行一条命令就会追加到缓冲区的末尾,当一条命令执行完成后,返回数据前,会将缓冲区的数据写入到AOF文件中。
AOF文件的载入与还原
AOF持久化的数据还原过程就是读取AOF中命令重新执行命令的过程。
(1)Redis会创建一个伪客户端,伪客户端与真实的客户端执行命令的效果是一样的,只是不带网络连接。
(2)从AOF文件分析并读取一条命令。
(3)伪客户端执行这条命令。
(4)重复2和3过程,知道AOF文件中的所有命令处理完成。
AOF文件重写
AOF文件的持久化是记录被执行对的命令,这样随着时间越来越长,AOF文件中的内容会越来越多,体积也会越来越大,文件越大恢复数据的时间也越多。
在命令执行的过程中有些键值对被删除了,有些被修改了,而这些过程命令是完全没有必要再执行一遍的,所以Redis提供了AOF文件的重写功能对AOF进行重建,使用重建后的文件要比元AOF文件体积小很多。
- AOF文件重写,并不需要对原AOF文件进行任何访问改动,他是通过对数据库内的数据读取来操作的,即查看数据库内有什么数据,然后根据数据类型进行创建这些数据的写入命令。
- AOF文件重写过程中,创建写入命令时会先检查元素数量,如果数量超过了redis.h/REDIS_AOF_REWRITE_ITEMS_PER_CMD=64常量的值,就会分成多条命令,
- AOF文件重写是有子进程进行的,并不影响主进程处理命令;子进程而不是线程,因为进程带有数据副本,不锁数据的情况下,能保证安全。
- AOF文件子进程重写过程中,主进程仍然在处理数据,这样造成了子进程和主进程的数据不一致,子进程数据少了一部分,这种情况下Redis会创建一个AOF重写缓冲区;这样少的那部分命令会写到AOF重写缓冲区中,重写完成后,再把缓冲区这些命令写进新的AOF文件中,然后用新的AOF文件替换就得AOF文件。
4、总结
- Redis初始化会创建一批数据库,每个数据库的内部数据结构都是字典,key-value的最终存储也会落到字典上。
- AOF持久化比RDB持久化频率更高、速度更快;当有AOF持久化时,RDB持久化命令不会再执行;但当RDB持久化命令执行时,AOF命令会等待其执行完成后再执行,而其他RDB命令不会执行。
- AOF文件重写过程不会影响旧的AOF文件,即便AOF重写过程失败,也不会干扰原来的AOF恢复数据,只有在成功之后才会替换原来的文件。
参考:
《Redis设计与实现》黄健宏著,网上对Redis的详解等
此博客为笔者使用redis很久之后,参考网络上各类文章总结性书写,原创手打,如有错误欢迎指正。
Redis(五)--- Redis的持久化RDB与AOF的更多相关文章
- redis++:Redis的两种持久化 RDB 和 AOF
Redis持久化备份数据的方式有两种:RDB(Redis DataBase) . AOF(Append Only File). RDB 什么是RDB: 在指定时间间隔内,将内存中的数据集快照写入磁盘 ...
- Redis(二)、Redis持久化RDB和AOF
一.Redis两种持久化方式 对Redis而言,其数据是保存在内存中的,一旦机器宕机,内存中的数据会丢失,因此需要将数据异步持久化到硬盘中保存.这样,即使机器宕机,数据能从硬盘中恢复. 常见的数据持久 ...
- Redis之数据持久化RDB与AOF
Redis之数据持久化RDB与AOF https://www.cnblogs.com/zackku/p/10087701.html 大家都知道,Redis之所以性能好,读写快,是因为Redis是一个内 ...
- Linux - redis持久化RDB与AOF
目录 Linux - redis持久化RDB与AOF RDB持久化 redis持久化之AOF redis不重启,切换RDB备份到AOF备份 确保redis版本在2.2以上 实验环境准备 备份这个rdb ...
- redis持久化 RDB与AOF
redis持久化 RDB与AOF RDB与AOF区别 rdb: 基于快照的持久化,速度更快,一般用做备份,主从复制也是依赖于rdb持久化功能 aof:以追加的方式记录redis操作日志的文件,可以最大 ...
- Redis持久化RDB、AOF
持久化的意思就是保存,保存到硬盘.第一次接触这个词是在几年前学习EF. 为什么要持久化 redis定义:Redis是一个开源(BSD许可),内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代 ...
- Redis 持久化 rdb、Aof对比
一.Redis 简介: Redis是一个开源的.基于内存的数据结构存储器,可以用作数据库.缓存和消息中间件. Redis是一个key-value存储系统.和Memcached类似,它支持存储的valu ...
- redis基础:redis下载安装与配置,redis数据类型使用,redis常用指令,jedis使用,RDB和AOF持久化
知识点梳理 课堂讲义 课程计划 1. REDIS 入 门 (了解) (操作) 2. 数据类型 (重点) (操作) (理解) 3. 常用指令 (操作) 4. Jedis (重点) (操作) ...
- Redis持久化----RDB和AOF 的区别
关于Redis说点什么,目前都是使用Redis作为数据缓存,缓存的目标主要是那些需要经常访问的数据,或计算复杂而耗时的数据.缓存的效果就是减少了数据库读的次数,减少了复杂数据的计算次数,从而提高了服务 ...
随机推荐
- AIX/Linux/HP-UX查看CPU/内存/磁盘/存储命令
1.1 硬件环境验证方式 硬件环境主要包括CPU.内存.磁盘/存储.网络设备(如F5等).系统特有设备(如密押设备等)等,其中网络设备和系统特有设备由网络管理员或项目组提供为准,本节主要关注CP ...
- mysql5.7 group by语法 1055
先来看如下语句,查询默认存在的引擎表 之前使用的MySQL版本为5.7以下,根据support进行分组执行语句如下 添加跟分组support无关的字段engine 没有任何问题 现在使用的版本是5.7 ...
- 算法详解之最近公共祖先(LCA)
若图片出锅请转至here 概念 首先是最近公共祖先的概念(什么是最近公共祖先?): 在一棵没有环的树上,每个节点肯定有其父亲节点和祖先节点,而最近公共祖先,就是两个节点在这棵树上深度最大的公共的祖先节 ...
- 利用mapWithState实现按照首字母统计的有状态的wordCount
最近在做sparkstreaming整合kafka的时候遇到了一个问题: 可以抽象成这样一个问题:有状态的wordCount,且按照word的第一个字母为key,但是要求输出的格式为(word,1)这 ...
- Ceph原理动画演示
动图生动刻画Ceph的基本原理之集群搭建及数据写入流程:)
- leadcode的Hot100系列--二叉树创建和遍历
很多题目涉及到二叉树,所以先把二叉树的一些基本的创建和遍历写一下,方便之后的本地代码调试. 为了方便,这里使用的数据为char类型数值,初始化数据使用一个数组. 因为这些东西比较简单,这里就不做过多详 ...
- 源码解读·RT-Thread操作系统从开机到关机
本篇内容比较简单,但却很繁琐,篇幅也很长,毕竟是囊括了整个操作系统的生命周期.这篇文章的目的是作为后续设计多任务开发的铺垫,后续会单独再抽出一篇分析任务的相关知识.另外本篇文章以单核MCU为背景,并且 ...
- HDU 4819:Mosaic(线段树套线段树)
http://acm.hdu.edu.cn/showproblem.php?pid=4819 题意:给出一个矩阵,然后q个询问,每个询问有a,b,c,代表(a,b)这个点上下左右c/2的矩形区域内的( ...
- java判断年份是否为闰年
在t1.jsp 中,设置一个表单,可以输入年份,提交到另外一个action进行计算,如果算出来是闰年,那么就跳转到a1.jsp(显示闰年),如果是平年就跳转到a2.jsp(显示平年). 要求:需要把计 ...
- Linux命令及安装
1.三大操作系统 1.Unix Solaris(SUN) IOS(Aplle移动端) Mas OS(Aplle平板,电脑端) 2.Windows XP win7 win8 win10 3.Linux ...