实现一个正则表达式引擎in Python(一)
前言
项目地址:Regex in Python
开学摸鱼了几个礼拜,最近几天用Python造了一个正则表达式引擎的轮子,在这里记录分享一下。
实现目标
实现了所有基本语法
st = 'AS342abcdefg234aaaaabccccczczxczcasdzxc'
pattern = '([A-Z]+[0-9]*abcdefg)([0-9]*)(\*?|a+)(zx|bc*)([a-z]+|[0-9]*)(asd|fgh)(zxc)'
regex = Regex(st, pattern)
result = regex.match()
log(result)
更多示例可以在github上看到
前置知识
其实正则表达式的引擎完全可以看作是一个小型的编译器,所以完全可以按之前写的那个C语言的编译器的思路来,只是没有那么复杂而已
- 首先进行词法分析
- 语法分析(这里用自顶向下)
- 语义分析 (因为正则的表达能力非常弱,所以可以省略生成AST的部分直接进行代码生成)
- 代码生成,这里也就是进行NFA的生成
- NFA到DFA的转换,这里开始就是正则和状态机的相关的知识了
- DFA的最小化
NFA和DFA
有限状态机可以看作是一个有向图,状态机中有若干个节点,每个节点都可以根据输入字符来跳转到下一个节点,而区别NFA((非确定性有限状态自动机)和DFA(确定性有限状态自动机)的是DFA的下一个跳转状态是唯一确定的)
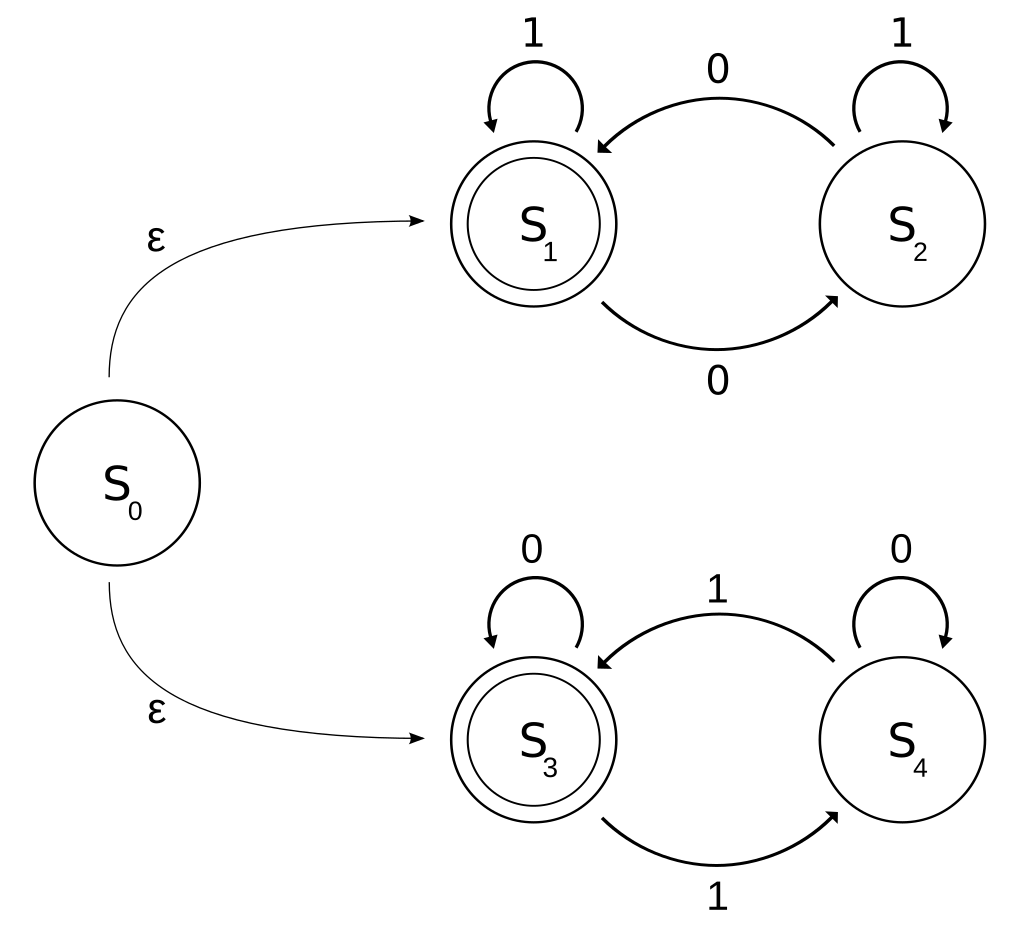
有限状态自动机从开始的初始状态开始读取输入的字符串,自动机使用状态转移函数move根据当前状态和当前的输入字符来判断下一个状态,但是NFA的下一个状态不是唯一确定的,所以只能确定的是下一个状态集合,这个状态集合还需要依赖之后的输入才能确定唯一所处的状态。如果当自动机完成读取的时候,它处于接收状态的话,则说明NFA可以接收这个输入字符串
对于所有的NFA最后都可以转换为对应的DFA
NFA构造O(n),匹配O(nm)
DFA构造O(2^n),最小化O(kn'logn')(N'=O(2^n)),匹配O(m)
n=regex长度,m=串长,k=字母表大小,n'=原始的dfa大小
NFA接受的所有字符串的集合是NFA接受的语言。这个语言是正则语言。
例子
对于正则表达式:[0-9]*[A-Z]+,对应的NFA就是将下面两个NFA的节点3和节点4连接起来
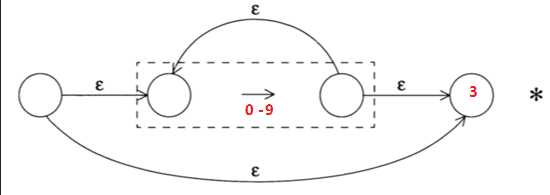
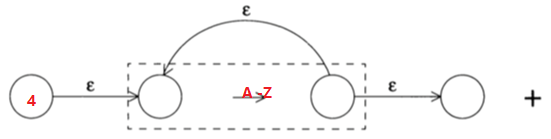
词法分析
对于NFA和DFA其实只要知道这么多和一些相应的算法就已经足够了,相应的算法在后面提及,先完成词法分析的部分,
这个词法分析比之前C语言编译器的语法分析要简单许多,只要处理几种可能性
- 普通字符
- 含有语义的字符
- 转义字符
token
token没什么好说的,就是对应正则里的语法
Tokens = {
'.': Token.ANY,
'^': Token.AT_BOL,
'$': Token.AT_EOL,
']': Token.CCL_END,
'[': Token.CCL_START,
'}': Token.CLOSE_CURLY,
')': Token.CLOSE_PAREN,
'*': Token.CLOSURE,
'-': Token.DASH,
'{': Token.OPEN_CURLY,
'(': Token.OPEN_PAREN,
'?': Token.OPTIONAL,
'|': Token.OR,
'+': Token.PLUS_CLOSE,
}
advance
advance是词法分析里最主要的函数,用来返回当前输入字符的Token类型
def advance(self):
pos = self.pos
pattern = self.pattern
if pos > len(pattern) - 1:
self.current_token = Token.EOS
return Token.EOS
text = self.lexeme = pattern[pos]
if text == '\\':
self.isescape = not self.isescape
self.pos = self.pos + 1
self.current_token = self.handle_escape()
else:
self.current_token = self.handle_semantic_l(text)
return self.current_token
advance的主要逻辑就是读入当前字符,再来判断是否是转义字符或者是其它字符
handle_escape用来处理转义字符,当然转义字符最后本质上返回的还是普通字符类型,这个函数的主要功能就是来记录当前转义后的字符,然后赋值给lexem,供之后构造自动机使用
handle_semantic_l只有两行,一是查表,这个表保存了所有的拥有语义的字符,如果查不到就直接返回普通字符类型了
完整代码就不放上来了,都在github上
构造NFA
构造NFA的主要文件都在nfa包下,nfa.py是NFA节点的定义,construction.py是实现对NFA的构造
NFA节点定义
NFA节点的定义也很简单,其实这个正则表达式引擎完整的实现只有900行左右,每一部分拆开看都非常简单
edge和input_set都是用来指示边的,边一共可能有四种种可能的属性
- 对应的节点有两个出去的ε边
edge = PSILON = -1 - 边对应的是字符集
edge = CCL = -2
input_set = 相应字符集 - 一条ε边
edge = EMPTY = -3 - 边对应的是单独的一个输入字符c
edge = c
- 对应的节点有两个出去的ε边
status_num每个节点都有唯一的一个标识
visited则是为了debug用来遍历NFA
class Nfa(object):
STATUS_NUM = 0
def __init__(self):
self.edge = EPSILON
self.next_1 = None
self.next_2 = None
self.visited = False
self.input_set = set()
self.set_status_num()
def set_status_num(self):
self.status_num = Nfa.STATUS_NUM
Nfa.STATUS_NUM = Nfa.STATUS_NUM + 1
def set_input_set(self):
self.input_set = set()
for i in range(ASCII_COUNT):
self.input_set.add(chr(i))
简单节点的构造
节点的构造在nfa.construction下,这里为了简化代码把Lexer作为全局变量,让所有函数共享
正则表达式的BNF范式如下,这样我们可以采用自顶向下来分析,从最顶层的group开始向下递归
group ::= ("(" expr ")")*
expr ::= factor_conn ("|" factor_conn)*
factor_conn ::= factor | factor factor*
factor ::= (term | term ("*" | "+" | "?"))*
term ::= char | "[" char "-" char "]" | .
BNF在之前写C语言编译器的时候有提到:从零写一个编译器(二)
主入口
这里为了简化代码,就把词法分析器作为全局变量,让所有函数共享
主要逻辑非常简单,就是初始化词法分析器,然后传入NFA头节点开始进行递归创建节点
def pattern(pattern_string):
global lexer
lexer = Lexer(pattern_string)
lexer.advance()
nfa_pair = NfaPair()
group(nfa_pair)
return nfa_pair.start_node
term
虽然是采用的是自顶向下的语法分析,但是从自底向上看会更容易理解,term是最底部的构建,也就是像单个字符、字符集、.符号的节点的构建
term ::= char | "[" char "-" char "]" | | .
term的主要逻辑就是根据当前读入的字符来判断应该构建什么节点
def term(pair_out):
if lexer.match(Token.L):
nfa_single_char(pair_out)
elif lexer.match(Token.ANY):
nfa_dot_char(pair_out)
elif lexer.match(Token.CCL_START):
nfa_set_nega_char(pair_out)
三种节点的构造函数都很简单,下面图都是用markdown的mermaid随便画画的
- nfa_single_char
单个字符的NFA构造就是创建两个节点然后把当前匹配的字符作为edge

def nfa_single_char(pair_out):
if not lexer.match(Token.L):
return False
start = pair_out.start_node = Nfa()
pair_out.end_node = pair_out.start_node.next_1 = Nfa()
start.edge = lexer.lexeme
lexer.advance()
return True
- nfa_dot_char
. 这个的NFA和上面单字符的唯一区别就是它的edge被设置为CCL,并且设置了input_set
# . 匹配任意单个字符
def nfa_dot_char(pair_out):
if not lexer.match(Token.ANY):
return False
start = pair_out.start_node = Nfa()
pair_out.end_node = pair_out.start_node.next_1 = Nfa()
start.edge = CCL
start.set_input_set()
lexer.advance()
return False
- nfa_set_nega_char
这个函数逻辑上只比上面的多了一个处理input_set
def nfa_set_nega_char(pair_out):
if not lexer.match(Token.CCL_START):
return False
neagtion = False
lexer.advance()
if lexer.match(Token.AT_BOL):
neagtion = True
start = pair_out.start_node = Nfa()
start.next_1 = pair_out.end_node = Nfa()
start.edge = CCL
dodash(start.input_set)
if neagtion:
char_set_inversion(start.input_set)
lexer.advance()
return True
小结
篇幅原因,现在已经写到了三百多行,所以就分篇写,准备在三篇内完成。下一篇写构造更复杂的NFA和通过构造的NFA来分析输入字符串。最后写从NFA转换到DFA,再最后用DFA分析输入的字符串
实现一个正则表达式引擎in Python(一)的更多相关文章
- 实现一个正则表达式引擎in Python(二)
项目地址:Regex in Python 在看一下之前正则的语法的 BNF 范式 group ::= ("(" expr ")")* expr ::= fact ...
- 实现一个正则表达式引擎in Python(三)
项目地址:Regex in Python 前两篇已经完成的写了一个基于NFA的正则表达式引擎了,下面要做的就是更近一步,把NFA转换为DFA,并对DFA最小化 DFA的定义 对于NFA转换为DFA的算 ...
- 1000行代码徒手写正则表达式引擎【1】--JAVA中正则表达式的使用
简介: 本文是系列博客的第一篇,主要讲解和分析正则表达式规则以及JAVA中原生正则表达式引擎的使用.在后续的文章中会涉及基于NFA的正则表达式引擎内部的工作原理,并在此基础上用1000行左右的JAVA ...
- Python的regex模块——更强大的正则表达式引擎
Python自带了正则表达式引擎(内置的re模块),但是不支持一些高级特性,比如下面这几个: 固化分组 Atomic grouping 占有优先量词 Possessive quantifi ...
- 基于ε-NFA的正则表达式引擎
正则表达式几乎每个程序员都会用到,对于这么常见的一个语言,有没有想过怎么去实现一个呢?乍一想,也许觉得困难,实际上实现一个正则表达式的引擎并没有想像中的复杂,<编译原理>一书中有一章专门讲 ...
- DEELX 正则表达式引擎(v1.2)
DEELX 正则表达式引擎(v1.2) 简介见文末. 选择使用deelx的理由:全部代码位于一个头文件(.h)中, 比任何引擎都使用简单和方便. 利用分组从字符串当中提取出化学元素英文名.比如 Ag, ...
- 正则表达式学习与python中的应用
目录: 一.正则表达式的特殊符号 二.几种重要的正则表达式 三.python的re模块应用 四.参考文献 一.正则表达式的特殊符号 特殊符号可以说是正则表达式的关键,掌握并且可以灵活运用重要的pyth ...
- 一个简单的多线程Python爬虫(一)
一个简单的多线程Python爬虫 最近想要抓取拉勾网的数据,最开始是使用Scrapy的,但是遇到了下面两个问题: 前端页面是用JS模板引擎生成的 接口主要是用POST提交参数的 目前不会处理使用JS模 ...
- 只有20行Javascript代码!手把手教你写一个页面模板引擎
http://www.toobug.net/article/how_to_design_front_end_template_engine.html http://barretlee.com/webs ...
随机推荐
- Windows Server 2008 R2服务器内存使用率过高,但与任务管理器中进程占用内存和不一致
系统环境: Windows Server 2008 R2 + Sql Server 2008 R2 问题描述: Windows Server 2008 R2系统内存占用率过大,而在任务管理器中各进 ...
- 设计模式(C#)——05适配器模式
推荐阅读: 我的CSDN 我的博客园 QQ群:704621321 自然界有一条规则--适者生存.意思是生物要使用自然界的变化:在程序界中则需要新环境调用现存对象.那么,如何在新环境中 ...
- Javaweb之文件的上传与下载
Javaweb之文件的上传与下载 一.基于表单的文件上传 如果在表单中使用表单元素 <input type=“file” />,浏览器在解析表单时,会自动生成一个输入框和一个按钮,输入框可 ...
- C# Memcache集群原理、客户端配置详细解析
概述 memcache是一套开放源的分布式高速缓存系统.由服务端和客户端组成,以守护程序(监听)方式运行于一个或多个服务器中,随时会接收客户端的连接和操作.memcache主要把数据对象缓存到内存中, ...
- GC回收算法&&GC回收器
GC回收算法 什么是垃圾? 类比日常生活中,如果一个东西经常没被使用,那么就可以说是垃圾. 同理,如果一个对象不可能再被引用,那么这个对象就是垃圾,应该被回收. 垃圾:不可能再被引用的对象. fina ...
- 信道估计系列之LS
在无线通信系统中,系统的性能主要受到无线信道的制约.基站和接收机之间的传播路径复杂多变,从简单的视距传输到受障碍物反射.折射.散射影响的传播.在无线传输环境中,接收信号会存在多径时延,时间选择性衰落和 ...
- 从零开始搭建Java开发环境第一篇:Java工程师必备软件大合集
1.JDK https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 目前主流的JDK版 ...
- Linux中JDK安装配置
安装jdk 1)下载地址:https://www.oracle.com/technetwork/java/javase/downloads/index.html 我选择jdk1.8版本 2)上传至服务 ...
- vmware12中安装MAC OS X 10.10
1. 准备工作 1) VMware Workstation 12 (去vmware官网下载即可) 2) unlocker 203 (OS X 插件补丁) 链接:http://pan.bai ...
- [USACO07OCT]障碍路线 & yzoj P1130 拐弯 题解
题意 给出n* n 的图,A为起点,B为终点,* 为障碍,.可以行走,问最少需要拐90度的弯多少次,无法到达输出-1. 解析 思路:构造N * M * 4个点,即将原图的每个点分裂成4个点.其中点(i ...