A Neural Influence Diffusion Model for Social Recommendation 笔记
一、摘言
之前协同过滤利用user-item交互历史很好的表示了user和item。但是由于用户行为的稀疏性,效果提升有限。
随着社交网络的发展,social recommendation system被提出,利用user的周围邻居的偏好来减轻用户稀疏性,从而得到更好嵌入表示模型。
然而现在的社交网络推荐模型都是简单的利用周围邻居提出静态模型,而没有模拟信息在全局的循环传播过程,这很可能会提升推荐性能。
所以,本文设计了一个层级的影响传播结构(layer-wise influence propagation structure ),建模用户的潜在嵌入表示是如何随着社交传播过程的持续而改变的。作者还进一步展示了模型的通用性,而且模型也能应用于这些情况,当user or item属性或者社交网络结构不可得时。
二、杂记
社交推荐的一般路线:把user和item先表示成低维向量,然后求其内积去预测user对item的偏好;
文中模型主要思想:提出的模型Diffnet,是基于神经网络模型模拟社交影响力传播过程,从而能更好的表示user和item,建模社交推荐。主要思想是为用户设计一个层次的影响传播结构,建模在社交传播过程中,用户的潜在表示是如何演变的。
具体来说,传播过程首先是在每个用户的特征融合和用户隐向量(描述用户潜在行为偏好)的基础上,为每个用户初始化嵌入表示;在item端,由于item不会在社交网络中传播,故每个item嵌入表示是由自由的item隐向量和其本身特征融合得到的。随着影响里传播到事先定义好的第K步,第K层的用户兴趣表示也就得到了。
模型还能无缝衔接到经典的CF模型上,例如BPR和SVD++。
贡献三点:
① 提出一个具有层级传播结构的DiffNet模型,建模在社交推荐中迭代的动态传播过程。除此之外,DiffNet有一个融合层,能够包含协作关系和属性内容的嵌入表示。(协作关系可能是指user-item的关系。//TODO)
② DiffNet是时间和空间都高效的,而且能泛化到相关的推荐模型上,也能很好的处理没有用户和item属性的情况。
③ 在Yelp和Flickr上实验结果要比其他模型高13%以上。
三、问题定义和一些准备工作
问题定义:social recommendation 其实都差不多,都是user-user,user-item两个网络,然后预测user会不会对item感兴趣。
基于潜在嵌入的模式是目前在社交系统中最成功、有效的描述协同信息的方法之一。也就是前文说的社交推荐的一般路线(把user和item先表示成低维向量,然后求其内积去预测user对item的偏好)。那各个文章的看点就是,如何去表征用有限的信息,设计良好的表示方法,去表征user和item,使得解释性更好,效果更优了。
SVD++:SVD++利用用户对item的历史评分记录,得到更好的user嵌入表示。所以在SVD++中,每个用户的嵌入表示除了利用经典隐因子模型的嵌入表示,还多了一个描述他历史评分item信息的嵌入表示,就是:
\[
\hat{r}_{ai} = v_i^T(u_a+\frac{1}{R_a}\sum_{j \in R_a}y_i)
\]
由于有时候,用户本身还有一些属性信息,所以也会把属性信息加入到公式当中去:
\[
\hat{r}_{ai} = w^T[x_a,y_i]+v_i^Tu_a
\]
通常,不同的嵌入模型是在嵌入矩阵的表示和优化函数上存在差异。例如BPR。
贝叶斯个性化排序(Bayesian Personalized Ranking,BPR):是一个成功的隐式反馈中基于节点对的优化函数。在BPR中,嵌入矩阵U和V是符合高斯先验的嵌入表示,等价于在优化函数中加入L2范式的正则项:
\[
\min _{[\mathrm{W}, \mathrm{U}, \mathrm{V}]} \mathcal{L}=\sum_{a=1}^{M} \sum_{(i, j) \in D_{a}} \sigma\left(\hat{r}_{a i}-\hat{r}_{a j}\right)+\lambda\left(\|\mathrm{U}\|_{F}^{2}+\|\mathrm{V}\|_{F}\right)^{2}
\]
当前社交推荐模型没有考虑到社交传播过程。而且,当用户属性可获得时,这些社交推荐模型需要重新设计来利用这些属性,以获得更好的推荐结果。[17](PS:此模型不是把feature作为可选的选项吧,这样,有feature的时候,就可以加到模型中,没有feature的时候,也就是结果差点,这样就比较flexible了么?)
四、模型真思想
1. 大概了解
输入:user-item对\(<a,i>\);输出:用户u喜欢物品i的概率。
整个框架分为四部分:①嵌入层;②融合层;③层级影响传播层;④预测层;
基本流程:
- 嵌入层输出user和item的嵌入表示。
- 对于每个user(item),都是通过融合层,融合用户的free embedding和user(item)的相关特征,产生hybrid user(item)表示。
- 然后融合的用户嵌入表示送入影响传播层,影响传播层利用一个层级的结构来建模在社交网络中的传播过程,这也是DiffNet的核心思想。
- 当影响力传播过程达到平衡后,输出层产生最终的user-item预测偏好。

2. 具体过程:
Embedding Layer:把user和item的one-hot表示,映射为潜在表示;
Fusion Layer:此部分叫融合层,其实就是把需要融合的部分\(concat\)起来,然后通过一个\(FC\)层。例如,对于一个用户a,\(p_a\)(表示???)和用户相关的属性\(x_a\)作为输入,然后(拼接起来,通过一个转换矩阵\(\mathbf{W}^0\)和一个非线性变换\(g\))输出融合后的嵌入表示\(h_a^0\),来刻画基于各种各样的输入,用户初始的兴趣。同样对于item也做同样的操作,如下公式:
\[
h_a^0 = g(\mathbf{W}^0 \times [x_a,p_a])
\]
\[
v_i= \sigma(\mathbf{F} \times [q_i,y_i])
\]
influence Diffusion Layers:把前面的输入\(h_a^0\)送入这一层,主要是建模用户潜在的偏好在社交网络中的动态传播过程。由于信息在社交网络中是随着时间不断传播的,所以影响力传播部分也是根据这个原理,类似的建立网络结构。每个层k从之前的层中获得并输入用户表示,在当前社交传播过程结束后,输出用户更新的表示。之后,更新的用户表示又被输入到下一个层中,在进行下一次传播过程。
举个例子,对于用户a,\(h_a^k\)表示它在k层的隐含向量,把\(h_a^k\)输入到第K+1层中,就得到了\(h_a^{k+1}\)。此处,\(h_a^{k+1}\)包含两部分:第一,从第k层,a的信任好友那里聚合的传播影响力,表示为\(h_{Sa}^{k+1}\):
\[
\mathbf{h}_{S a}^{k+1}=\operatorname{Pool}\left(\mathbf{h}_{b}^{k} | b \in S_{a}\right)
\]
Pool函数可以用平均池化操作,来计算用户信任好友在第k层表示的平均值。当然,也可以用max pooling,这都没啥。第二,跟自己从上一层输入的银行向量拼起来,然后通过一个带激活函数的FC层,公式如下:
\[
\mathbf{h}_{a}^{k+1}=s^{(k+1)}\left(\mathbf{W}^{k} \times\left[\mathbf{h}_{S_{a}}^{k+1}, \mathbf{h}_{a}^{k}\right]\right)
\]
传播深度K是预定义的,最终得到节点在深度为K的表示为\(h_a^K\)。
要注意的是,在这个影响力传播过程部分,没有用到任何跟item相关的向量,是因为item的隐含向量是静态的,不能在社交网络中传播。(PS:静态的应该也可以在网络中进行传播,或许可以考虑过程中如何加入。)
Prediction Layer:给定用户a的嵌入表示\(h_a^K\)和item i的融合向量\(v_i\),建模预测用户a的偏好:
\[
\mathbf{u}_{a}=\mathbf{h}_{a}^{K}+\sum_{i \in R_{a}} \frac{\mathbf{v}_{i}}{\left|R_{a}\right|}
\]
\[
{\hat{r}_{a i}=\mathbf{v}_{i}^{T} \mathbf{u}_{a}}
\]
这里就是把用户\(a\)所有喜欢的item,\(R_a\),全部拼接到用户的最终表示\(u_a\)当中去。
模型(●ˇ∀ˇ●)训练,类似于BPR,作者设计了一个基于pair-wise ranking 的损失函数:
\[
\min _{\Theta} \mathcal{L}(\mathrm{R}, \hat{\mathbf{R}})=\sum_{a=1}^{M} \sum_{(i, j) \in D_{a}} \sigma\left(\hat{r}_{a i}-\hat{r}_{a j}\right)+\lambda\left\|\Theta_{1}\right\|^{2}
\]
\(\sigma\)是softmax函数,\(\Theta=[\Theta_1,\Theta_2]\),其中\(\Theta_1=[P,Q]\),\(\Theta_2=[F,[W^k]^{K-1}_{k=0}]\)在正则化项内(上式应该是写错了吧,\(\Theta\)应该没有下标1。\(D_a = \{(i, j) |i \in R_a \and j \in V − R_a \}\)表示用户a和他喜欢的物品 集合\(R_a\)之间的pairwise training data。
训练的过程中还用了复杂杨,在训练过程中,随机挑选10个没有观察到的伪负反馈。
PS:看到这里感觉好熟悉啊,总是感觉我在那里看过这篇文章,可又想不起来了,后来想了一下,原来我看的是“SocialGCN:An Efficient Graph Convolutional Network based Model for Social Recommendation”(AAAI‘19),这两篇文章是同一批人写的,用的方法其实变化不大。
3. 使用GCN对比的算法:
作者说使用的思想和GCN差不多,所以要和一些使用GCN的方法比较一下。
- GC-MC:少有的几个把GCN应用到推荐的工作。GC-MC定义了一个user-item的二部图。每个用户的嵌入表示集合了周围相关的item的表示。同样,每个item的嵌入表示集合了周围相关的用户的嵌入表示。但是在图卷积操作的时候,仅卷积用户和item的一层可见网络,忽略了图中层级的传播结构。
- PinSage:通过用户的行为,构建了item-item的关系图,一个GCN算法PinSage就被提出来了。PinSage可以结合item关系和节点属性,产生item嵌入表示。主要的贡献就是,如何设计有效的采样方式来加速training,在消息在item-item网络中进行传播时,作者的工作做了一个循环的信息传播社交网络,这更加真实的反映了用户如何动态的被社交影响力影响的。把FCN应用在推荐中是非常自然的,据作者所知,这之前未被研究过。
五、实验部分
作者想在实验部分主要回答三个问题:
- DiffNet是不是有效?
- DiffNet是不是能应对各种稀疏数据?
- DiffNet各部分的有效性是怎么样的?
1. 实验设置
数据集:
Yelp数据集中用户评分是1~5,作者进行了阈值处理,大于3的认为喜欢。使用gensim 工具中Word2vec模型,通过平均池化其他用户和item的嵌入表示,获得用户和item的表示。
Flickr是一个who-trust-whom的在线图片分享网络。用户会分享图片,其他用户会对图片点赞,表示喜欢。在此,针对图片是有其类别的groundtruth的,所以通过VGG16学习出4096维向量。对于用户就是平均池化他喜欢的图片的表示。
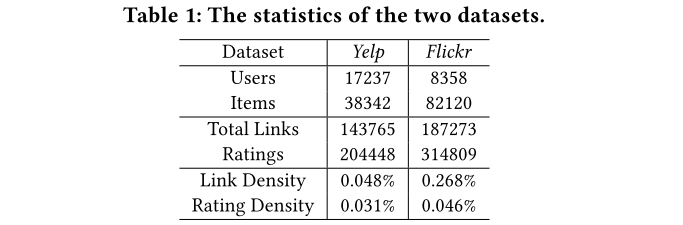
在两个数据集中都出了预处理,过滤掉少于2个评分记录或者2个社交边的用户;移除少于2个评分的item。最终选择了10%作为测试,90%作为训练,训练集中又选了了10%作为验证,数据集具体情况如下表:
BaseLine和评价标准:
- 对边算法:BPR、FM、TrustSVD、ContexMF、GC-MC、PinSage。
- 评价标准HR:用户在测试数据中喜欢,而且已经被预测的Top-k的list命中的数量。
- 评价标准NDCG:考虑的是命中的item如果在推荐列表的前面,则给一个较高的分数。
参数设置:
Adam、lr=0.001,bs=512;正则化参数\(\lambda=[0.0001,0.001,0.01,0.1]\)发现0.001最好。aggregating function发现平均池化效果要比最大池化好。层数K=2,跟GCN差不多。ReLU函数防止梯度消失。用batch normalization防止internal covariate shift problem。
实验结果:
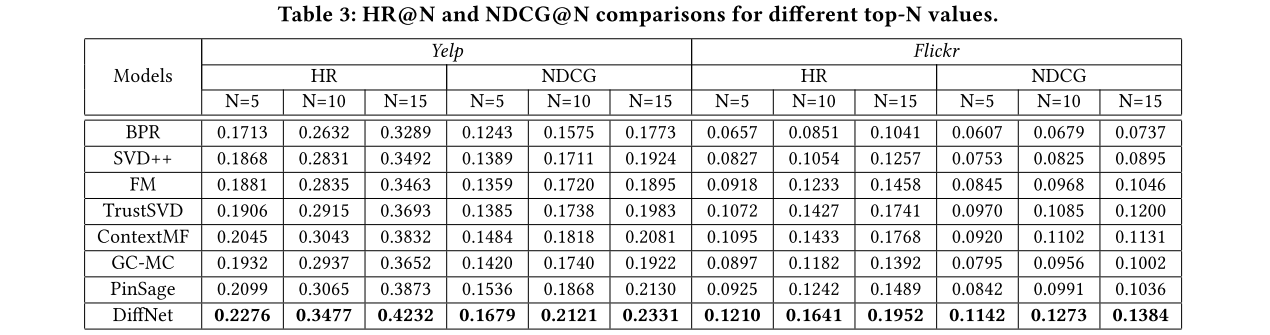
在不同稀疏性上也做了实验:
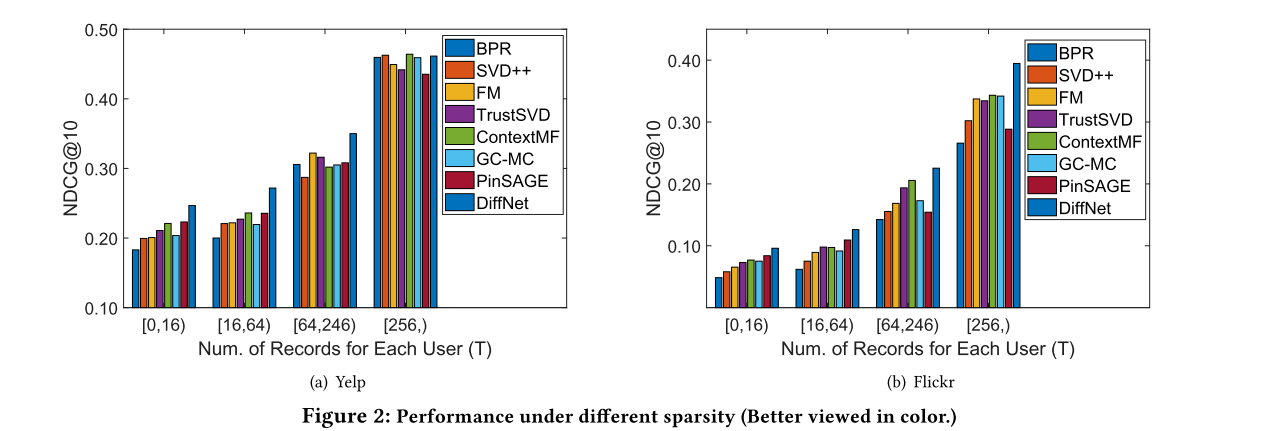
在不同的传播层数也做了实验:
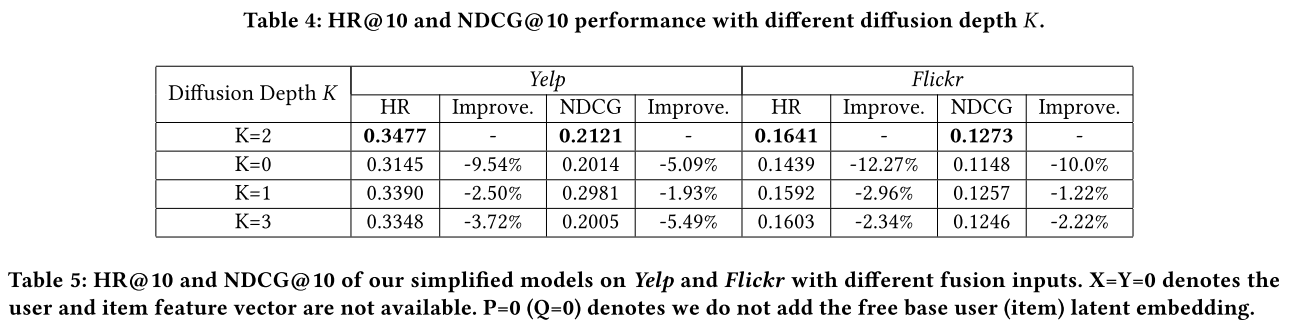
通过去掉user和item的属性特征,对比了实验:
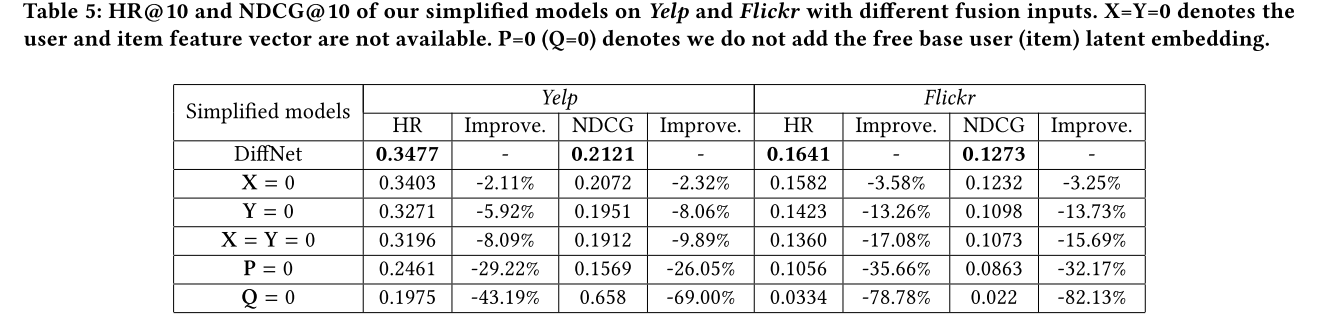
实验比较详细。
Related work:
//TODO
六、参考文献
[1]. Wu, Le, et al. “A Neural Influence Diffusion Model for Social Recommendation.” SIGIR 2019 - Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, 2019, pp. 235–44, doi:10.1145/3331184.3331214.
[2]. Wu, Le, et al. SocialGCN: An Efficient Graph Convolutional Network Based Model for Social Recommendation. 2017, www.aaai.org.
A Neural Influence Diffusion Model for Social Recommendation 笔记的更多相关文章
- 【论文笔记】SamWalker: Social Recommendation with Informative Sampling Strategy
SamWalker: Social Recommendation with Informative Sampling Strategy Authors: Jiawei Chen, Can Wang, ...
- 讲座:Influence maximization on big social graph
Influence maximization on big social graph Fanju PPT链接: social influence booming of online social ne ...
- A Neural Probabilistic Language Model
A Neural Probabilistic Language Model,这篇论文是Begio等人在2003年发表的,可以说是词表示的鼻祖.在这里给出简要的译文 A Neural Probabili ...
- A Word-Complexity Lexicon and A Neural Readability Ranking Model for Lexical Simplification-paper
https://github.com/mounicam/lexical_simplification 提供了SimplePPDBpp: SimplePPDB++ resource consisting ...
- 【转载 | 翻译】Visualizing A Neural Machine Translation Model(神经机器翻译模型NMT的可视化)
转载并翻译Jay Alammar的一篇博文:Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models Wi ...
- Django Model模型的实战操作笔记
Model模型的实战操作笔记 1. 创建数据库和表 进入MySQL数据库创建数据库:mytest 进入数据库创建数据表:mytest_users CREATE TABLE `mytest_users` ...
- Future Research Directions in Social Recommendation
From the tutorial published by Martin Ester in RecSys 2013 Future Research Directions --Recommendati ...
- A neural reinforcement learning model for tasks with unknown time delays
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Abstract 我们提出了一个基于生物学的神经模型,能够在复杂的任务中执行强化学习.该模型的独特之处在于,它能够在一个动作.状态转换和奖 ...
- 4----COM:a Generative Model for group recommendation(组推荐的一种生成模型)
1.摘要: 组推荐的一个挑战性问题:因为不同组的成员就有不同的偏好,如何平衡这些组员的偏好是一个难以解决的问题. 在本文中,作者提出了一个COM的概率模型来建立组活动生成过程. 直觉上: 一个组中的用 ...
随机推荐
- C语言笔记 06_作用域&数组
作用域 任何一种编程中,作用域是程序中定义的变量所存在的区域,超过该区域变量就不能被访问.C 语言中有三个地方可以声明变量: 在函数或块内部的局部变量 在所有函数外部的全局变量 在形式参数的函数参数定 ...
- netcore 2.2 使用 Autofac 实现自动注入
Autofac自动注入是通过名称约定来实现依赖注入 ps:本demo接口层都以“I”开头,以“Service”结尾.服务层实现都以“Service”结尾. 为什么要实现自动注入 大多时候,我们都是 以 ...
- 利用文件保存 Map 健值信息
Map<String,MobileCard> cards = new HashMap<String,MobileCard>(); Map<String,List<C ...
- springboot~maven集成开发里的docker构建
统一设计 maven很好的把项目整合在一起,在部署时,每个项目可以有自己的Dockerfile,在构建后把对应的jar包复制到Dockerfile的同级目录,使用使用统一的打包镜像和容器启动方法去执行 ...
- DialogHost 关闭对话框
<Window x:Class="DialogHost.ClosingConfirmation.CodeBehind.MainWindow" xmlns="http ...
- ORA-14061: 不能更改索引分区列的数据类型或长度
修改分区表主键时报错: 在行: 2 上开始执行命令时出错 -alter table KC23 modify AAZ210 VARCHAR2(50)错误报告 -SQL 错误: ORA-14061: 不能 ...
- hadoop搭建的前期准备
这个hadoop的搭建是以比赛前的练习为目的的,所以我直接以root用户来搭建hadoop,主要也是方便我自己以后复习用的 需要的软件:vmware15.5,xshell6,xftp6,jdk Lin ...
- 编译原理:直接推导、间接推导、n次推导、规范推导
直接推导,直接运用规则进行的推导 间接推导.n次推导 有两种符号 第一种是,表示多次运用直接推导 第二种是,表示零次或多次运用直接推导 n表示中间的步骤数 规范推导 其实就是最右推导
- LeetCode--回文数(简单)
题目描述: 判断一个整数是否是回文数.回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数. 示例 1: 输入: 121 输出: true 示例 2: 输入: -121 输出: false 解 ...
- 第一篇:C++之hello world
1.编辑器:Microsoft Visual C++ 2010,下载安装 2.新建项目 代码: #include <iostream>#include <Windows.h>/ ...