SQL Server 存储(1/8):理解数据页结构
我们都很清楚SQL Server用8KB 的页来存储数据,并且在SQL Server里磁盘 I/O 操作在页级执行。也就是说,SQL Server 读取或写入所有数据页。页有不同的类型,像数据页,GAM,SGAM等。在这文章里,让我们一起来理解下数据页结构。
SQL Server把数据记录存在数据页(Data Page)里。数据记录是堆表里、聚集索引里叶子节点的行。
数据页由3个部分组成。页头(标头),数据区(数据行和可用空间)及行偏移数组。

在我们讨论在SQL Server里,数据页内部结构具体是什么样之前,我们来创建一个表并插入一些记录。
USE [InternalStorageFormat]
GO IF EXISTS ( SELECT *
FROM sysobjects
WHERE id = OBJECT_ID(N'[dbo].[Customers]')
AND OBJECTPROPERTY(id, N'IsUserTable') = 1 )
DROP TABLE dbo.Customers CREATE TABLE Customers
(
FirstName CHAR(50) NOT NULL,
LastName CHAR(50) NOT NULL,
Address CHAR(100) NOT NULL,
ZipCode CHAR(5) NOT NULL,
Rating INT NOT NULL,
ModifiedDate DATETIME NOT NULL,
)
GO INSERT INTO dbo.Customers
( FirstName ,
LastName ,
Address ,
ZipCode ,
Rating ,
ModifiedDate
) VALUES ( 'Woody' , -- FirstName - char(50)
'Tu' , -- LastName - char(50)
'ZUOQIAO YOUXI TOWN LINHAI CITY' , -- Address - char(50)
'' , -- ZipCode - char(5)
1 , -- Rating - int
'2015-05-07 10:09:51' -- ModifiedDate - datetime
)
go 2
现在我们要找出SQL Server给这个表分配的页有哪些,这个就要用到非文档的命令DBCC IND。
它的语法如下:
DBCC IND 命令用于查询一个存储对象的内部存储结构信息,该命令有4个参数, 前3个参数必须指定。语法如下:
DBCC IND ( { 'dbname' | dbid }, { 'objname' | objid },{ nonclustered indid | 1 | 0 | -1 | -2 } [, partition_number] )
第一个参数是数据库名或数据库ID。
第二个参数是数据库中的对象名或对象ID,对象可以是表或者索引视图。
第三个参数是一个非聚集索引ID或者 1, 0, 1, or 2. 值的含义:
0: 只显示对象的in-row data页和 in-row IAM 页。
1: 显示对象的全部页, 包含IAM 页, in-row数据页, LOB 数据页row-overflow 数据页 . 如果请求的对象含有聚集所以则索引页也包括。
-1: 显示全部IAM页,数据页, 索引页 也包括 LOB 和row-overflow 数据页。
-2: 显示全部IAM页。
Nonclustered index ID:显示索引的全部 IAM页, data页和索引页,包含LOB和 row-overflow数据页。
为了兼容sql server 2000,第四个参数是可选的,该参数用于指定一个分区号.如果不给定值或者给定0, 则显示全部分区数据。
和DBCC PAGE不同的是, SQL Server运行DBCC IND不需要开启3604跟踪标志.
我们来执行下列的命令:
DBCC IND('InternalStorageFormat','Customers',-1)
SQL Server会给我们如下的输出结果:
可以看到有2条记录,一条记录为页面类型(PageType)为10的页和一条记录为页面类型(PageType)为1的页。页面类型(PageType)10是IAM页,页面类型(PageType)1是数据页,它的页ID是79.
关于数据库页类型如下所示:
- 1 Data page 堆表和聚集索引的叶子节点数据
2 Index page 聚集索引的非叶子节点和非聚集索引的所有索引记录
3 Text mixed page A text page that holds small chunks of LOB values plus internal parts of text tree. These can be shared between LOB values in the same partition of an index or heap.
4 Text tree page A text page that holds large chunks of LOB values from a single column value.
7 Sort page 排序时所用到的临时页,排序中间操作存储数据用的。
8 GAM page 全局分配映射(Global Allocation Map,GAM)页面 这些页面记录了哪些区已经被分配并用作何种用途。
9 SGAM page 共享全局分配映射(Shared Global Allocation Map,GAM)页面 这些页面记录了哪些区当前被用作混合类型的区,并且这些区需含有至少一个未使用的页面。
10 IAM page 有关每个分配单元中表或索引所使用的区的信息
11 PFS page 有关页分配和页的可用空间的信息
13 boot page 记录了关于数据库的信息,仅存于每个数据库的第9页
15 file header page 记录了关于数据库文件的信息,存于每个数据库文件的第0页
16 DCM page 记录自从上次全备以来的数据改变的页面,以备差异备份
17 BCM page 有关每个分配单元中自最后一条 BACKUP LOG 语句之后的大容量操作所修改的区的信息
现在我们来看看79号类型为1的数据页里存放的数据,这个就要用到DBCC PAGE命令,它的语法如下:
dbcc page 命令读取数据页结构的命令DBCC Page。
该命令为非文档化的命令,具体如下:
DBCC Page ({dbid|dbname},filenum,pagenum[,printopt])
具体参数描述如下:
dbid 包含页面的数据库ID
dbname 包含页面的数据库的名称
filenum 包含页面的文件编号
pagenum 文件内的页面
printopt 可选的输出选项;选用其中一个值:
0:默认值,输出缓冲区的标题和页面标题
1:输出缓冲区的标题、页面标题(分别输出每一行),以及行偏移量表
2:输出缓冲区的标题、页面标题(整体输出页面),以及行偏移量表
3:输出缓冲区的标题、页面标题(分别输出每一行),以及行偏移量表;每一行
后跟分别列出的它的列值
要想看到这些输出的结果,还需要设置DBCC TRACEON(3604)。
我们来执行下列的命令:
DBCC TRACEON(3604)
DBCC PAGE(InternalStorageFormat,1,79,3)
GO
SQL Server会给我们包含4个部分的输出。第1部分是BUFFER,里面是一些内存分配信息,对此我们没多少兴趣。下一部分是固定96 bytes大小的页头(page header),页头(page header)会类似如下显示:
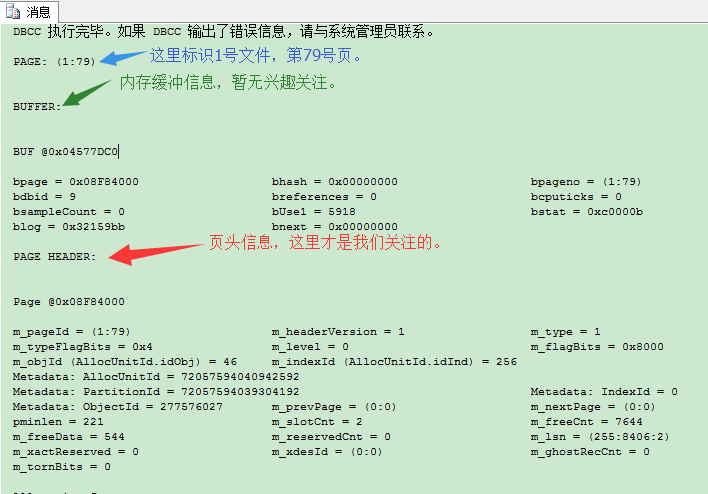
页头相关字段的含义:
- Page @0x08F84000 同BUFFER中的bpage地址
- m_pageId = (1:79) 数据页号
- m_headerVersion = 1 头文件版本号,一直为1
- m_type = 1 页面类型,1为数据页面
- m_typeFlagBits = 0x4 数据页和索引页为4,其他页为0
- m_level = 0 该页在索引页(B树)中的级数
- m_flagBits = 0x8000 页面标志
- m_objId (AllocUnitId.idObj) = 46 同Metadata: ObjectId
- m_indexId (AllocUnitId.idInd) = 256 同Metadata: IndexId
- Metadata: AllocUnitId = 72057594040942592 存储单元的ID,sys.allocation_units.allocation_unit_id
- Metadata: PartitionId = 72057594039304192 数据页所在的分区号,sys.partitions.partition_id
- Metadata: IndexId = 0 页面的索引号,sys.objects.object_id&sys.indexes.index_id
- Metadata: ObjectId = 277576027 该页面所属的对象的id,sys.objects.object_id
- m_prevPage = (0:0) 该数据页的前一页面;主要用在数据页、索引页和IAM页
- m_nextPage = (0:0) 该数据页的后一页面;主要用在数据页、索引页和IAM页
- pminlen = 221 定长数据所占的字节数
- m_slotCnt = 2 页面中的数据的行数
- m_freeCnt = 7644 页面中剩余的空间
- m_freeData = 544 从第一个字节到最后一个字节的空间字节数
- m_reservedCnt = 0 活动事务释放的字节数
- m_lsn = (255:8406:2) 日志记录号
- m_xactReserved = 0 最新加入到m_reservedCnt领域的字节数
- m_xdesId = (0:0) 添加到m_reservedCnt的最近的事务id
- m_ghostRecCnt = 0 幻影数据的行数
- m_tornBits = 0 页的校验位或者被由数据库页面保护形式决定分页保护位取代
再来看下页面相关分配情况:

- GAM (1:2) = ALLOCATED 在GAM页上的分配情况
- SGAM (1:3) = ALLOCATED 在SGAM页上的分配情况
- PFS (1:1) = 0x61 MIXED_EXT ALLOCATED 50_PCT_FULL 在PFS页上的分配情况,该页为50%满,
- DIFF (1:6) = CHANGED
- ML (1:7) = NOT MIN_LOGGED
接下来就是用于存放实际数据的槽(slot),每条记录存放一个槽(slot)里。0号槽在页里拥有第1条数据,1号槽拥有第2条数据,以此类推。通过下面的图片,你可以看到我们记录大小是224 bytes,217 bytes(50+50+100+5+4+8) 的定长和7 bytes 的系统行开销。
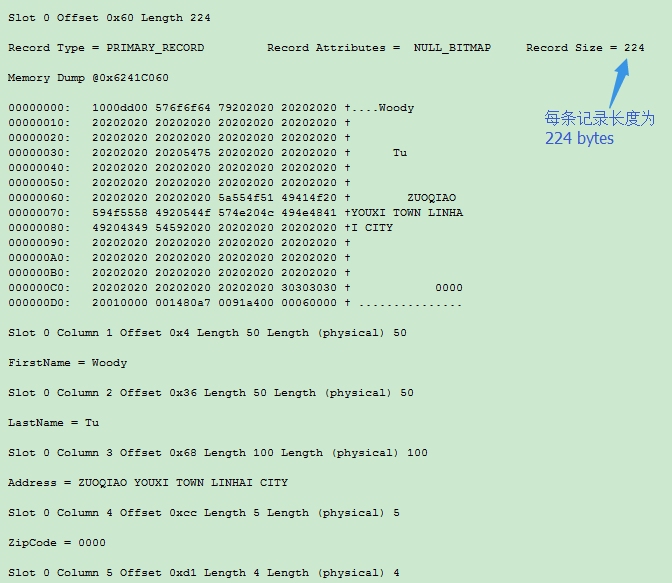
页的最后一部分是行偏移数组表,我们可以用参数为1的DBCC PAGE命令来,在输出信息的底部获得。
执行如下的命令:
DBCC TRACEON(3604)
DBCC PAGE(InternalStorageFormat,1,79,3)
GO
SQL Server在输出信息的底部,给我们如下的信息:

这个行偏移表,应该从下往上读。每条槽条目是一个2 bytes长的指针指向页里槽偏移量。这里我们插入了2条记录,所以表里有2个槽条目。第1条记录指向第96 bytes,刚好在页头后。这个行偏移表可以帮助我们管理页面的记录。在页里的行偏移表里,每条记录需要2 bytes的大小来存储。于此类似,在堆表上建立的非聚集索引,每个非聚集索引行里都包含一个物理指针映射回堆表里的行记录。这个物理指针是[文件号:页号:槽号](file:page:solt)的结构,因此在读取页的时候,可以找到堆表里的对应行,再通过行偏移表里槽号里的偏移量,就可以在页里读取到对应的行记录。如果我们要修改页中间的记录,我们并不一定需要重组整个页,我们只要修改偏移表里偏移量即可。

在页头我们看到当前页面还有7644 bytes可以用,我们一起来验证下。
(8 * 1024) - 96 - (217 * 2)-(7 * 2)-(2 * 2)=7644 bytes
8 * 1024 = 页的总大小,8K
96 = 页头大小 96 bytes
217 * 2 = 每条记录的总长 * 记录数
7 * 2 = 每条记录的系统行开销 * 记录数
2 * 2 = 行偏移表里每槽占用字节数 * 记录数
现在我们已经知道了页的结构,我们一起来小结下。
页是 8KB 的大小,即 8192 bytes,固定 96 bytes的大小给页头使用,接下来是具体的数据以槽的方式存储。数据记录的最大长度是 8060 bytes(包括 7 bytes的系统行开销),因此一条记录中你拥有的最大字节数是 8053 bytes。下列的表创建语句会失败。
CREATE TABLE Maxsize(
id CHAR(8000) NOT NULL,
id1 CHAR(54) NOT NULL
)

剩下的 36 bytes (8192-96-8060)保留给槽数组(Slot array)或者任何转发行返回指针(forwarding row back pointer)(每条10 bytes)。这就意味一个页不一定就能保存18(36/2)条记录。槽数组(Slot array)根据你的记录数从下往上增长。如果记录长度小,页里就可以存储更多的记录,偏移表也会自下而上占用更多的空间。
参考文章:
SQL Server 存储(1/8):理解数据页结构的更多相关文章
- SQL Server :理解数据页结构
原文:SQL Server :理解数据页结构 我们都很清楚SQL Server用8KB 的页来存储数据,并且在SQL Server里磁盘 I/O 操作在页级执行.也就是说,SQL Server 读取或 ...
- SQL Server数据库中导入导出数据及结构时主外键关系的处理
2015-01-26 软件开发中,经常涉及到不同数据库(包括不同产品的不同版本)之间的数据结构与数据的导入导出.处理过程中会遇到很多问题,尤为突出重要的一个问题就是主从表之间,从表有外检约束,从而导致 ...
- SQL Server 存储(2/8):理解数据记录结构
在SQL Server :理解数据页结构我们提到每条记录都有7 bytes的系统行开销,那这个7 bytes行开销到底是一个什么样的结构,我们一起来看下. 数据记录存储我们具体的数据,换句话说,它存在 ...
- SQL Server 存储(8/8):理解数据文件结构
这段时间谈了很多页,现在我们可以看下这些页在数据文件里是如何组织的. 我们都已经知道,SQL Server把数据文件分成8k的页,页是IO的最小操作单位.SQL Server把数据文件里的第1页标记为 ...
- SQL Server :理解数据记录结构
原文:SQL Server :理解数据记录结构 在SQL Server :理解数据页结构我们提到每条记录都有7 bytes的系统行开销,那这个7 bytes行开销到底是一个什么样的结构,我们一起来看下 ...
- SQL Server 存储(3/8):理解GAM和SGAM页
我们知道SQL Server在8K 的页里存储数据.分区就是物理上连续的8个页.当我们创建一个数据库,数据文件会被逻辑分为页和区,当用户对象创建时,页会分配给它用来存储数据.GAM(Global Al ...
- SQL Server存储(6/8) :理解DCM页
我们已经讨论了各种不同的页,包括数据页.GAM与SGAM页.PFS页,还有IAM页.今天我们来看下差异变更页(Differential Change Map:DCM ),还有差异备份(differen ...
- SQL SERVER存储引擎——04.数据
4. SQL SERVER存储引擎之数据篇 (4.1)文件 (0)主数据文件.mdf初始文件大小至少为3MB,次要数据文件.ndf初始大小,同日志文件一样至少为512KB: (1)SQL SERVER ...
- SQL Server 存储引擎-剖析Forwarded Records
我们都知道数据在存储引擎中是以页的形式组织的,但数据页在不同的组织形式中其中对应的数据行存储是不尽相同的,这里通过实例为大家介绍下堆表的中特有的一种情形Forwared Records及处理方式. 概 ...
随机推荐
- WPF整理-使用ResourceDictionary管理Logical Resources
“Logical resources may be of various types, such as brushes, geometries, styles, and templates.Placi ...
- unity3D学习—坦克大战(一)
背景介绍 本人一名C#程序员,从事C#开发已经有四年有余了,目前在一家大型公司上班.鉴于公司的业务需要,现在需要学习unity3D游戏开发,好在unity支持C#脚本开发,无形中省下了许多重新学习新语 ...
- 浅谈Js闭包现象
一.1.我们探究这个问题的时候如果按照正常的思维顺序,需要知道闭包是什么它是什么意思,但是这样做会让我们很困惑,了解这个问题我们需要知道它的来源,就是我们为什么要使用闭包,先不管它是什么意思! ...
- EQueue - 一个纯C#写的分布式消息队列介绍2
一年前,当我第一次开发完EQueue后,写过一篇文章介绍了其整体架构,做这个框架的背景,以及架构中的所有基本概念.通过那篇文章,大家可以对EQueue有一个基本的了解.经过了1年多的完善,EQueue ...
- 如何让你的JavaScript代码更加语义化
语义化这个词在 HTML 中用的比较多,即根据内容的结构化选择合适的标签.其作用不容小觑: 赋予标签含义,让代码结构更加清晰,虽然我们可以在标签上添加 class 来标识,但这种通过属性来表示本体的形 ...
- 关于大型网站技术演进的思考(二十一)--网站静态化处理—web前端优化—下【终篇】(13)
本篇继续web前端优化的讨论,开始我先讲个我所知道的一个故事,有家大型的企业顺应时代发展的潮流开始投身于互联网行业了,它们为此专门设立了一个事业部,不过该企业把这个事业部里的人事成本,系统运维成本特别 ...
- TCP状态
TCP状态 TCP连接中包含不同的状态,如何通过状态来判断程序问题尤为重要. 三次握手 图中的connection部分为三次握手. 四次握手 图中的close部分为四次握手. CLOSE_WAIT 服 ...
- C#设计模式之组合
IronMan之组合 在上个篇幅中讲到怎么把“武器”装饰到“部件”上,这个篇幅呢,还是要讲到“武器”,不过呢是关于“武器”使用的. 本篇介绍"武器"的合理使用方式,不说废话,直接来 ...
- Copy 与MutableCopy的区别
NSString *string = @"origion"; NSString *stringCopy = [string copy]; NSMutableString *stri ...
- PHPCMS后台密码忘记解决办法
什么是PHPCMS? PHPCMS是一款网站管理软件.该软件采用模块化开发,支持多种分类方式,使用它可方便实现个性化网站的设计.开发与维护.它支持众多的程序组合,可轻松实现网站平台迁移,并可广泛满足各 ...