用python实现对元素的长截图
一.目标
浏览网页的时候,看见哪个元素,就能截取哪个元素当图片,不管那个元素有多长

二.所用工具和第三方库
python ,PIL,selenium
pycharm
三.代码部分
长截图整体思路:
1.获取元素
2.移动,截图,移动,截图,直到抵达元素的底部
3.把截图按照元素所在位置切割,在所有图片中只保留该元素
4.拼接
如果driver在环境变量中,那么不用指定路径
b=webdriver.Chrome(executable_path=r"C:\Users\Desktop\chromedriver.exe")#指定一下driver
b.get("https://www.w3school.com.cn/html/html_links.asp")
b.maximize_window()#最大化窗口
打开网站
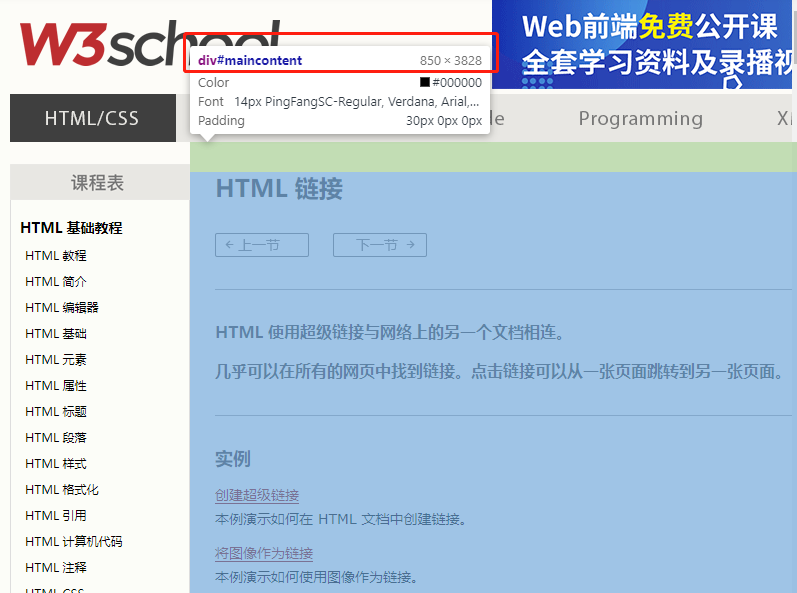
我们可以看见一个ID为maincontent的元素,宽度为850PX,长度为3828PX,这个长度必须使用才能长截图才能完整截下来
el=b.find_element_by_id("maincontent")#找到元素
我们还需要一个重要的参数,就是你电脑一次能截取多高的像素
先用下图代码获取一个图片
#fp为存放图片的地址
b.get_screenshot_as_file(fp)

也就是说用我电脑上截图的默认高度为614像素
所以我设置一个变量:
sc_hight=614
然后设置一下其他变量
count = int(el.size["height"] / sc_hight) # 元素的高度除以你每次截多少就是次数
start_higth = el.location["y"] # 元素的初始高度
max_px = start_higth + (count - 1) * sc_hight # for循环中最大的px
last_px = el.size["height"] + start_higth - sc_hight # 元素最底部的位置
surplus_px = last_px - max_px # 剩余的边的高度
img_path = [] # 用来存放图片地址
注释:
1.count为元素的高度/每次截取的高度,比如这次实例中元素高度为3828PX,我每次截614px,需要6.2次,int之后变成6,也就是截6次,还剩一点,那一点后面再说
2.start_higth为初始高度,这个没有什么可说的
3.max_px为循环结束后,到达的高度
4.last_px为元素最底部的高度
5.surplus_px就是移动6次后,还没有截取的高度
屏幕每次移动,移动sc_hight个像素,初始位置为(0,元素的Y值)
for i in range(0, count):
js = "scrollTo(0,%s)" % (start_higth + i * sc_hight) # 用于移动滑轮,每次移动614px,初始值是元素的初始高度
b.execute_script(js) # 执行js
time.sleep(0.5)
fp = r"C:\Users\wdj\Desktop\%s.png" % i # 图片地址,运行的话,改一下
b.get_screenshot_as_file(fp) # 屏幕截图,这里是截取是完整的网页图片,你可以打断点看一下图片
img = Image.open(fp=fp)
img2 = img.crop((el.location["x"], 0, el.size["width"] + el.location["x"], sc_hight)) # 剪切图片
img2.save(fp) # 保存图片,覆盖完整的网页图片
img_path.append(fp) # 添加图片路径
time.sleep(0.5)
print(js)
else:
js = "scrollTo(0,%s)" % last_px # 滚动到最后一个位置
b.execute_script(js)
fp = r"C:\Users\wdj\Desktop\last.png"
b.get_screenshot_as_file(fp)
img = Image.open(fp=fp)
print((el.location["x"], sc_hight - surplus_px, el.size["width"] + el.location["x"], sc_hight))
img2 = img.crop((el.location["x"], sc_hight - surplus_px, el.size["width"] + el.location["x"], sc_hight))
img2.save(fp)
img_path.append(fp)
print(js)
上面是把该元素的在页面都截完,并且剪切,把图片保存的路径放入img_path
最后一步:把所有截图都贴到新创建的图片中
new_img = Image.new("RGB", (el.size["width"], el.size["height"])) # 创建一个新图片,大小为元素的大小
k = 0
for i in img_path:
tem_img = Image.open(i)
new_img.paste(tem_img, (0, sc_hight * k)) # 把图片贴上去,间隔一个截图的距离
k += 1
else:
new_img.save(r"C:\Users\wdj\Desktop\test.png") # 保存
运行效果图:
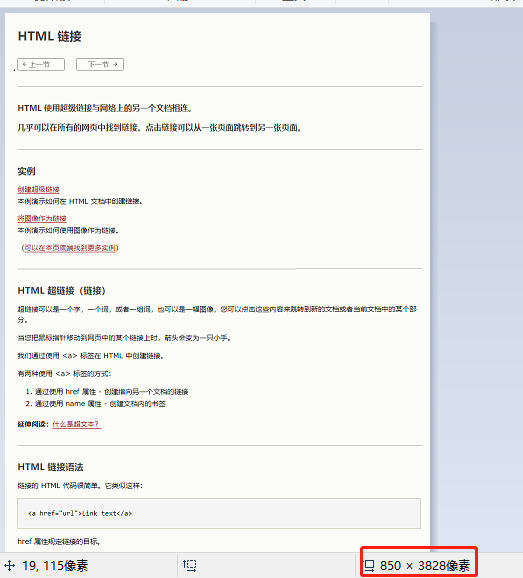
说明完整的截取下来了
补充优化:
如果是个小元素怎么办,不用长截图就能截取的那种
因为很简单我就直接贴代码了
start_higth = el.location["y"]
js = "scrollTo(0,%s)" % (start_higth)
b.execute_script(js) # 执行js
time.sleep(0.5)
fp = r"C:\Users\wdj\Desktop\test.png" # 图片地址,运行的话,改一下
b.get_screenshot_as_file(fp)
img = Image.open(fp=fp)
img2 = img.crop((el.location["x"], 0, el.size["width"] + el.location["x"], el.size["height"])) # 剪切图片
img2.save(fp)
效果如下:

完整代码:
from selenium import webdriver
from PIL import Image
import time
def short_sc(el,b):
start_higth = el.location["y"]
js = "scrollTo(0,%s)" % (start_higth)
b.execute_script(js) # 执行js
time.sleep(0.5)
fp = r"C:\Users\wdj\Desktop\test.png" # 图片地址,运行的话,改一下
b.get_screenshot_as_file(fp)
img = Image.open(fp=fp)
img2 = img.crop((el.location["x"], 0, el.size["width"] + el.location["x"], el.size["height"])) # 剪切图片
img2.save(fp) def long_sc(el,b):
count = int(el.size["height"] / sc_hight) # 元素的高度除以你每次截多少就是次数
start_higth = el.location["y"] # 元素的初始高度
max_px = start_higth + (count - 1) * sc_hight # for循环中最大的px
last_px = el.size["height"] + start_higth - sc_hight # 元素最底部的位置
surplus_px = last_px - max_px # 剩余的边的高度
img_path = [] # 用来存放图片地址
for i in range(0, count):
js = "scrollTo(0,%s)" % (start_higth + i * sc_hight) # 用于移动滑轮,每次移动614px,初始值是元素的初始高度
b.execute_script(js) # 执行js
time.sleep(0.5)
fp = r"C:\Users\wdj\Desktop\%s.png" % i # 图片地址,运行的话,改一下
b.get_screenshot_as_file(fp) # 屏幕截图,这里是截取是完整的网页图片,你可以打断点看一下图片
img = Image.open(fp=fp)
img2 = img.crop((el.location["x"], 0, el.size["width"] + el.location["x"], sc_hight)) # 剪切图片
img2.save(fp) # 保存图片,覆盖完整的网页图片
img_path.append(fp) # 添加图片路径
time.sleep(0.5)
print(js)
else:
js = "scrollTo(0,%s)" % last_px # 滚动到最后一个位置
b.execute_script(js)
fp = r"C:\Users\wdj\Desktop\last.png"
b.get_screenshot_as_file(fp)
img = Image.open(fp=fp)
print((el.location["x"], sc_hight - surplus_px, el.size["width"] + el.location["x"], sc_hight))
img2 = img.crop((el.location["x"], sc_hight - surplus_px, el.size["width"] + el.location["x"], sc_hight))
img2.save(fp)
img_path.append(fp)
print(js) new_img = Image.new("RGB", (el.size["width"], el.size["height"])) # 创建一个新图片,大小为元素的大小
k = 0
for i in img_path:
tem_img = Image.open(i)
new_img.paste(tem_img, (0, sc_hight * k)) # 把图片贴上去,间隔一个截图的距离
k += 1
else:
new_img.save(r"C:\Users\wdj\Desktop\test.png") # 保存 b=webdriver.Chrome(executable_path=r"C:\Users\wdj\Desktop\chromedriver.exe")#指定一下driver
b.get("https://www.w3school.com.cn/html/html_links.asp")
b.maximize_window()#最大化窗口
# b.get_screenshot_as_file(fp)
sc_hight=614#你屏幕截图默认的大小,可以去截一张,去画图里面看看是多少像素,我这里是614像素 # b.switch_to.frame(b.find_element_by_xpath('//*[@id="intro"]/iframe'))
el=b.find_element_by_id("maincontent")#找到元素
if el.size["height"]>sc_hight:
long_sc(el,b)
else:
short_sc(el,b)
完整代码
PS:
有些特殊情况,比如截取的元素在iframe中,直接用driver.switch_to.frame(iframe元素)即可
或者不是iframe,但是元素有overflow属性,直接用JS把他的overflow去掉就行
用python实现对元素的长截图的更多相关文章
- 截图还在使用QQ的Ctrl + Alt + A 截图?还不会网页长截图?
截图还在使用QQ的Ctrl + Alt + A 截图?还不会网页长截图? 手机自带快捷键,常常使用组合键进行快速截图编辑发好友.保存等,但是貌似到了电脑截图就出现了一大堆拍屏幕党,不少人需要打开微 ...
- Noah的学习笔记之Python篇:函数“可变长参数”
Noah的学习笔记之Python篇: 1.装饰器 2.函数“可变长参数” 3.命令行解析 注:本文全原创,作者:Noah Zhang (http://www.cnblogs.com/noahzn/) ...
- python删除列表元素remove,pop,del
python删除列表元素 觉得有用的话,欢迎一起讨论相互学习~Follow Me remove 删除单个元素,删除首个符合条件的元素,按值删除,返回值为空 List_remove = [1, 2, 2 ...
- 003 Python基本语法元素
目录 一.概要 1.1 方法论 1.2 实践能力 一.概要 程序设计基本方法:https://www.cnblogs.com/nickchen121/p/11164043.html Python开发环 ...
- Python检查数组元素是否存在类似PHPisset()方法
Python检查数组元素是否存在类似PHP isset()方法 sset方法来检查数组元素是否存在,在Python中无对应函数,在Python中一般可以通过异常来处理数组元素不存在的情况,而无须事先检 ...
- 如何实现批量截取整个网页完整长截图,批量将网页保存成图片web2pic/webshot/screencapture/html2picture
如何实现批量截取整个网页完整长截图,批量将网页保存成图片web2pic/webshot/screencapture [困扰?疑问?]: 您是否正受到:如何将网页保存为图片的困扰?网页很高很长截图截不全 ...
- python中列表元素连接方法join用法实例
python中列表元素连接方法join用法实例 这篇文章主要介绍了python中列表元素连接方法join用法,实例分析了Python中join方法的使用技巧,非常具有实用价值,分享给大家供大家参考. ...
- Selenium with Python 008 - WebDriver 元素等待
如今大多数Web应用程序使用Ajax技术,当浏览器在加载页面时,页面上的元素可能并不是同时被加载完成的,这给元素的定位增加了困难.如果因为在加载某个元素时延迟而造成ElementNotVisibleE ...
- Python+Selenium设置元素等待
显式等待 显式等待使 WebdDriver 等待某个条件成立时继续执行,否则在达到最大时长时抛弃超时异常 (TimeoutException). #coding=utf-8 from selenium ...
随机推荐
- 【Java基础】Java开发过程中的常用工具类库
目录 Java开发过程中的常用工具类库 1. Apache Commons类库 2. Guava类库 3. Spring中的常用工具类 4. 其他工具 参考 Java开发过程中的常用工具类库 1. A ...
- ACM-图论-同余最短路
https://www.cnblogs.com/31415926535x/p/11692422.html 一种没见过的处理模型,,记录一下,,主要是用来处理一个多元一次方程的解的数量的问题,,数据量小 ...
- luogu P4035 [JSOI2008]球形空间产生器
[返回模拟退火略解] 题目描述 今有 n+1n+1n+1 个 nnn 维的点,它们都在一个球上.求它们所在球的球心. Solution 4035\text{Solution 4035}Solution ...
- Cocos2d-x 学习笔记(9) Action 运行原理
1. 从一个Action开始 1.1 创建 在Scene里写一个Sprite,并添加Action: Sprite *sp = Sprite::create("m1.png"); M ...
- SpringBoot 2.0整合阿里云OSS,实现动静分离架构
前言 相信大部分开发者对下面这张架构图并不陌生吧,现在很多网站/应用都采用了动静分离的架构进行部署.博主的博客也不例外,主机采用的是阿里云的 ECS,使用 CDN 做静态内容分发,不过静态文件还是存储 ...
- 详解AJAX工作原理以及实例讲解(通俗易懂)
什么是 AJAX ? AJAX = 异步 JavaScript 和 XML. AJAX 是一种用于创建快速动态网页的技术. 通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新.这意味 ...
- vue——同一局域网内访问项目
1.想要在手机上访问本地的vue项目,首先要保证手机和电脑处在同一局域网内(连着同一个无线网) 2.将你电脑的ip设置为固定ip(ipconfig查找本地的ip,然后修改它,改为你想变的数字) 3.在 ...
- Kafka源码研究--Comsumer获取partition下标
背景 由于项目上Flink在设置parallel多于1的情况下,job没法正确地获取watermark,所以周末来研究一下一部分,大概已经锁定了原因: 虽然我们的topic只设置了1的partitio ...
- Java Stream函数式编程图文详解(二):管道数据处理
一.Java Stream管道数据处理操作 在本号之前发布的文章<Java Stream函数式编程?用过都说好,案例图文详解送给你>中,笔者对Java Stream的介绍以及简单的使用方法 ...
- Linux对目录操作命令
cd /home 进入 '/ home' 目录 cd .. 返回上一级目录 cd ../.. 返回上两级目录 cd 进入个人的主目录 cd ~u ...