NameNode数据存储
HDFS架构图
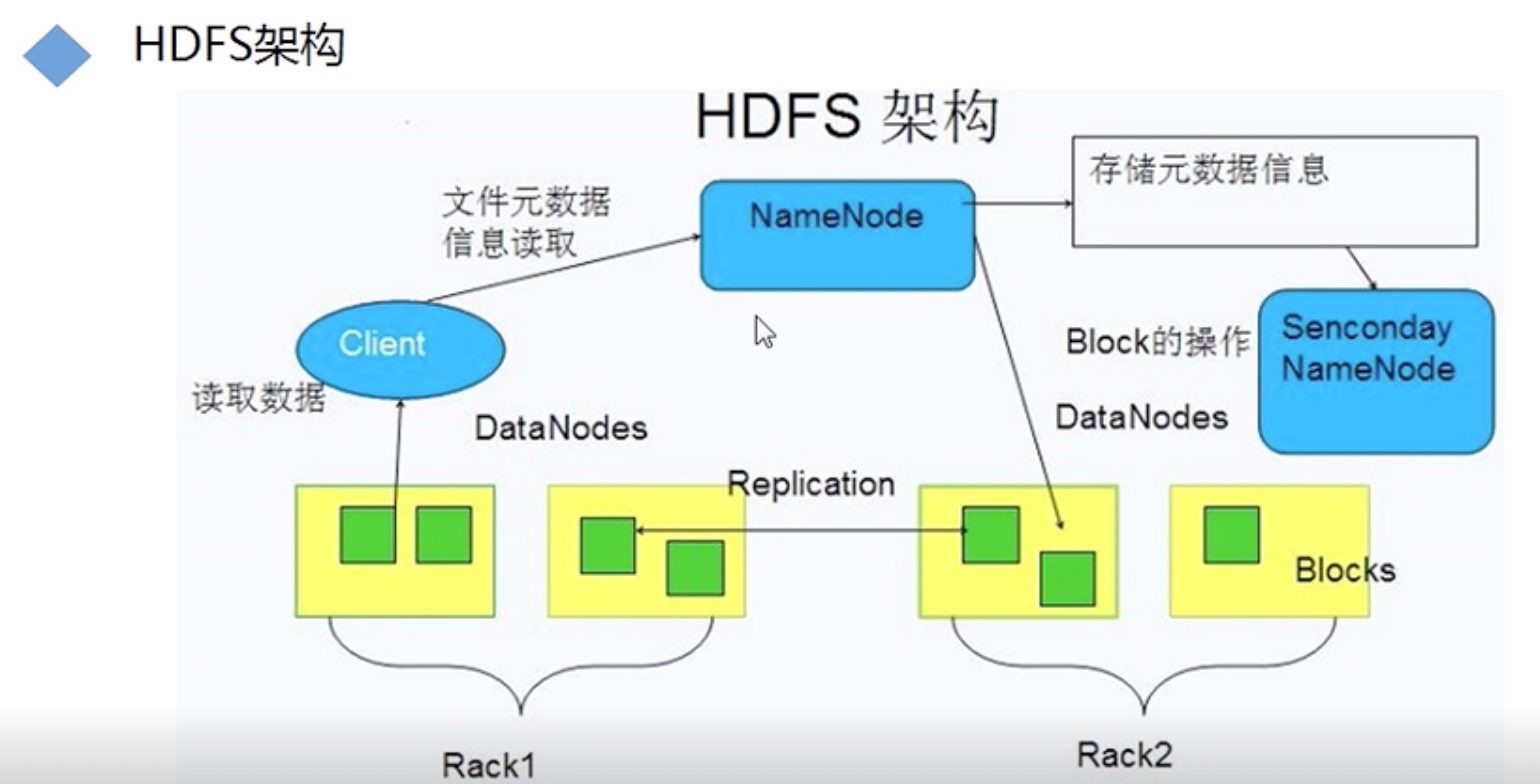
HDFS原理
1) 三大组件
NameNode、 DataNode 、SecondaryNameNode
2)NameNode
存储元数据(文件名、创建时间、大小、权限、文件与block块映射关系)
3)DataNode
存储真实的数据信息
4)SecondaryNameNode
合并edits日志文件和fsimage镜像文件进行合并
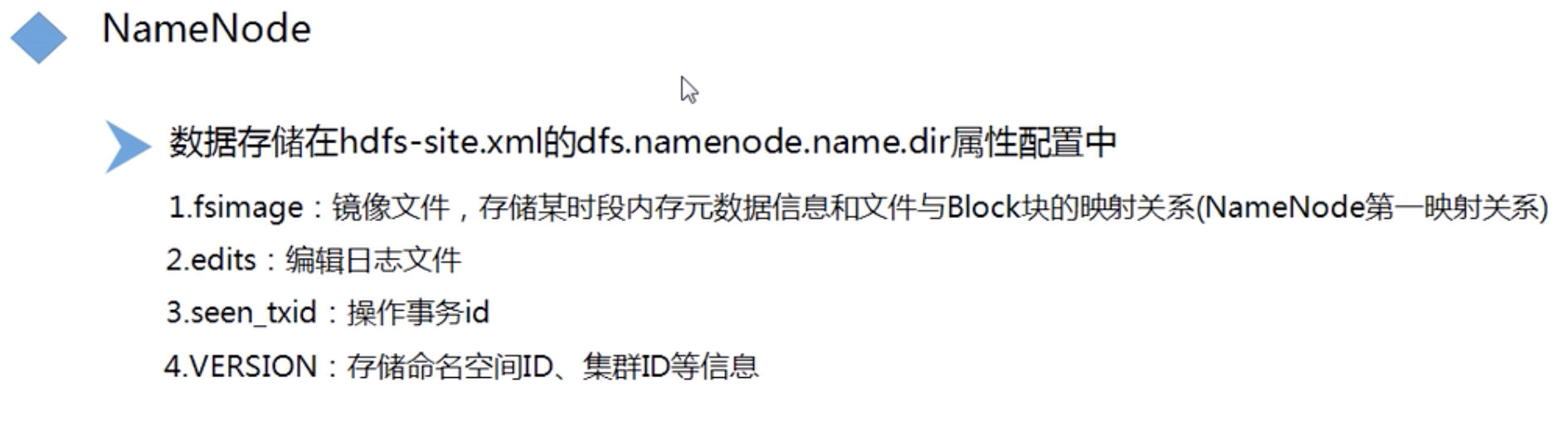
详细信息如下:
其中fsimage_0000000000000000000000属于镜像文件
see_txid操作事务id
其中fsimage_0000000000000000000000.md5属于校验和
VERSION属于版本号,详细信息如下:
(1)dfs.namenode.name.dir file://{$hadoop.tmp.dir}/dfs/name
hadoop.tmp.dir /tmp/hadoop-${user.name}
多次格式化的问题:
hdfs格式化会改变VERSION文件中的clusterID, 首次格式化时datanode和namenode会产生相同的clusterID;
如果重新执行格式化,namenode的clusterID改变,就会愈datanode的cluseterID不一致,如果重启或者读写hdfs,就会挂掉
(2)dfs.datanode.data.dir file://${hadoop.tmp.dir}/dfs/data
hadoop.tmp.dir /tmp/hadoop-${user.name}
例:/tmp/hadoop-root/dfs目录下:
name、data、namesecondary
(3)dfs.namenode.checkpoint.dir file://{hadoop.tmp.dir}/dfs/namesecondary
tmp/hadoop-${user.name}/dfs/name或者 tmp/hadoop-${user.name}/dfs/data下的datanode和namenode信息在系统
在重启时,会被清空处理。为了防止数据丢失,接下来我们更改路径存储,以namenode为例:
配置hdfs信息如下:将namenode数据存储在data/name下面
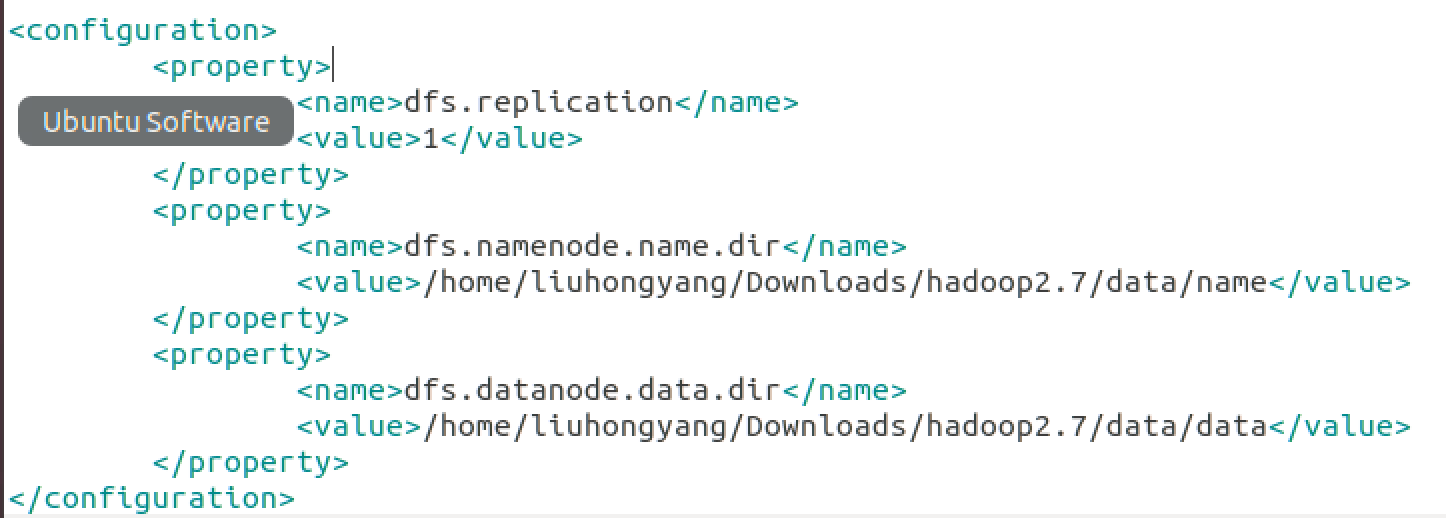
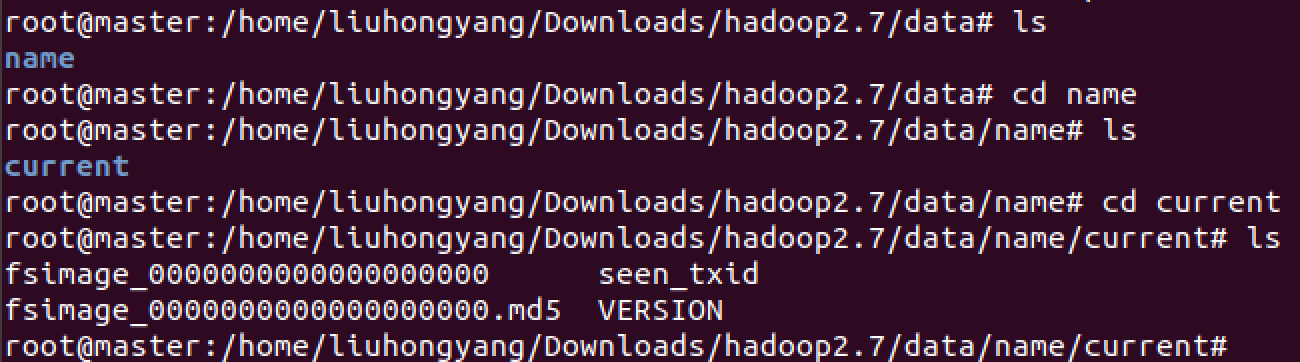
在执行格式化之前,查询data下的目录信息:

进行格式化:
hdfs namenode -format -force
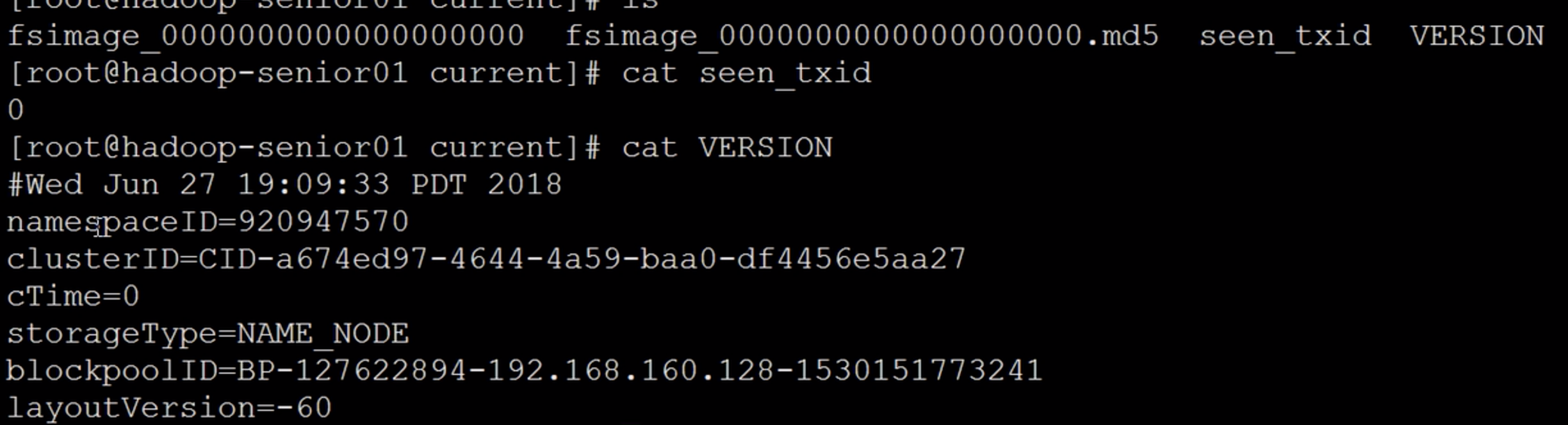
格式化之后,在data/name/current下查看name信息
NameNode数据存储的更多相关文章
- 从 RAID 到 Hadoop Hdfs 『大数据存储的进化史』
我们都知道现在大数据存储用的基本都是 Hadoop Hdfs ,但在 Hadoop 诞生之前,我们都是如何存储大量数据的呢?这次我们不聊技术架构什么的,而是从技术演化的角度来看看 Hadoop Hdf ...
- [HDFS_add_2] SecondaryNameNode 滚动 NameNode 数据流程
0. 说明 在 将 SecondaryNameNode 配置到 s105 节点上 的基础上进行 SecondaryNameNode 滚动 NameNode 数据流程 分析 1. SecondaryNa ...
- 网易大数据之数据存储:HDFS
一.HDFS基础架构 1.HDFS特点:水平扩展.高容错性.廉价硬件.开源生态系统 2.Hadoop生态圈 1).分布式存储系统(HDFS),2).资源管理框架(YARN),3).批处理框架(MapR ...
- 大数据存储的进化史 --从 RAID 到 Hdfs
我们都知道现在大数据存储用的基本都是 Hdfs ,但在 Hadoop 诞生之前,我们都是如何存储大量数据的呢?这次我们不聊技术架构什么的,而是从技术演化的角度来看看 Hadoop Hdfs. 我们先来 ...
- 【solr】SolrCloud中索引数据存储于HDFS
SolrCloud中索引数据存储于HDFS 本人最近使用SolrCloud存储索引日志条件,便于快速索引,因为我的索引条件较多,每天日志记录较大,索引想到将日志存入到HDFS中,下面就说说怎么讲sol ...
- BigData NoSQL —— ApsaraDB HBase数据存储与分析平台概览
一.引言 时间到了2019年,数据库也发展到了一个新的拐点,有三个明显的趋势: 越来越多的数据库会做云原生(CloudNative),会不断利用新的硬件及云本身的优势打造CloudNative数据库, ...
- 大数据软件安装之Hadoop(Apache)(数据存储及计算)
大数据软件安装之Hadoop(Apache)(数据存储及计算) 一.生产环境准备 1.修改主机名 vim /etc/sysconfig/network 2.修改静态ip vim /etc/udev/r ...
- Kooboo CMS技术文档之三:切换数据存储方式
切换数据存储方式包括以下几种: 将文本内容存储在SqlServer.MySQL.MongoDB等数据库中 将站点配置信息存储在数据库中 将后台用户信息存储在数据库中 将会员信息存储在数据库中 将图片. ...
- Android之数据存储的五种方法
1.Android数据存储的五种方法 (1)SharedPreferences数据存储 详情介绍:http://www.cnblogs.com/zhangmiao14/p/6201900.html 优 ...
随机推荐
- 统一流控服务开源:基于.Net Core的流控服务
先前有一篇博文,梳理了流控服务的场景.业界做法和常用算法 统一流控服务开源-1:场景&业界做法&算法篇 最近完成了流控服务的开发,并在生产系统进行了大半年的验证,稳定可靠.今天整理一下 ...
- java学习-NIO(一)简介
I/O简介 在 Java 编程中,直到最近一直使用 流 的方式完成 I/O.所有 I/O 都被视为单个的字节的移动,通过一个称为 Stream 的对象一次移动一个字节.流 I/O 用于与外部世界接触. ...
- form提交的几种方式
背景 一直使用postman作为restful接口的调试工具,但是针对post方法的几种类型,始终不明白其含义,今天彻底了解了下 form提交的来源 html页面上的form表单 <form a ...
- [转载]windows下mongodb安装与使用整理
windows下mongodb安装与使用整理 一.首先安装mongodb 1.下载地址:http://www.mongodb.org/downloads 2.解压缩到自己想要安装的目录,比如d:\mo ...
- 洛谷 P2787 语文1(chin1)- 理理思维
题意简述 维护字符串,支持以下操作: 0 l r k:求l~r中k的出现次数 1 l r k:将l~r中元素赋值为k 2 l r:询问l~r中最大连续1的长度 题解思路 珂朵莉树暴力赋值,查询 代码 ...
- (十二)c#Winform自定义控件-分页控件
前提 入行已经7,8年了,一直想做一套漂亮点的自定义控件,于是就有了本系列文章. 开源地址:https://gitee.com/kwwwvagaa/net_winform_custom_control ...
- https理论及实践
什么是https协议? http协议以明文的方式在网络中传输,安全性难以保证,https在http协议的基础上加入SSL/TLS层.TLS是SSL协议的最新版本,SSL使用SSL数字证书在通信两端建立 ...
- 完美解决迅雷极速版强制升级到迅雷X
虽然迅雷已死,但是还是软件还是有点点用的.废话不好多说,直接上解决办法: 1. 找到桌面的迅雷图标,右键选择打开文件位置; 2. 根据路径找到: 相对路径:Thunder Network\Thunde ...
- SpringBoot Mybatis解决使用PageHelper一对多分页问题
一般来说使用 PageHelper 能解决绝大多数的分页问题,相关使用可在博客园上搜索,能找到很多资料. 之前我在做SpringBoot 项目时遇到这样一个问题,就是当一对多联合查询时需要分页的情况下 ...
- 【转】[Python小记] 通俗的理解闭包 闭包能帮我们做什么?
https://blog.csdn.net/sc_lilei/article/details/80464645