helm部署Filebeat + ELK
helm部署Filebeat + ELK
系统架构图:
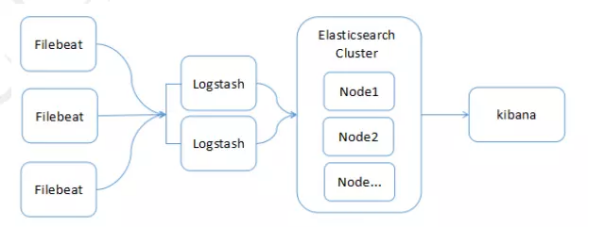
1) 多个Filebeat在各个Node进行日志采集,然后上传至Logstash
2) 多个Logstash节点并行(负载均衡,不作为集群),对日志记录进行过滤处理,然后上传至Elasticsearch集群
3) 多个Elasticsearch构成集群服务,提供日志的索引和存储能力
4) Kibana负责对Elasticsearch中的日志数据进行检索、分析
1. Elasticsearch部署
官方chart地址:https://github.com/elastic/helm-charts/tree/master/elasticsearch
创建logs命名空间
kubectl create ns logs
添加elastic helm charts 仓库
helm repo add elastic https://helm.elastic.co
安装
helm install --name elasticsearch elastic/elasticsearch --namespace logs
参数说明
image: "docker.elastic.co/elasticsearch/elasticsearch"
imageTag: "7.2.0"
imagePullPolicy: "IfNotPresent"
podAnnotations: {}
esJavaOpts: "-Xmx1g -Xms1g"
resources:
requests:
cpu: "100m"
memory: "2Gi"
limits:
cpu: "1000m"
memory: "2Gi"
volumeClaimTemplate:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "nfs-client"
resources:
requests:
storage: 50Gi
2. Filebeat部署
官方chart地址:https://github.com/elastic/helm-charts/tree/master/filebeat
Add the elastic helm charts repo
helm repo add elastic https://helm.elastic.co
Install it
helm install --name filebeat elastic/filebeat --namespace logs
参数说明:
image: "docker.elastic.co/beats/filebeat"
imageTag: "7.2.0"
imagePullPolicy: "IfNotPresent"
resources:
requests:
cpu: "100m"
memory: "100Mi"
limits:
cpu: "1000m"
memory: "200Mi"
那么问题来了,filebeat默认收集宿主机上docker的日志路径:/var/lib/docker/containers。如果我们修改了docker的安装路径要怎么收集呢,很简单修改chart里的DaemonSet文件里边的hostPath参数:
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers #改为docker安装路径
对java程序的报错异常log实现多行合并,用multiline定义正则来匹配。
filebeatConfig:
filebeat.yml: |
filebeat.inputs:
- type: docker
containers.ids:
- '*'
multiline.pattern: '^[0-9]'
multiline.negate: true
multiline.match: after
processors:
- add_kubernetes_metadata:
in_cluster: true output.elasticsearch:
hosts: '${ELASTICSEARCH_HOSTS:elasticsearch-master:9200}'
3. Kibana部署
官方chart地址:https://github.com/elastic/helm-charts/tree/master/kibana
Add the elastic helm charts repo
helm repo add elastic https://helm.elastic.co
Install it
helm install --name kibana elastic/kibana --namespace logs
参数说明:
elasticsearchHosts: "http://elasticsearch-master:9200"
replicas: 1
image: "docker.elastic.co/kibana/kibana"
imageTag: "7.2.0"
imagePullPolicy: "IfNotPresent"
resources:
requests:
cpu: "100m"
memory: "500m"
limits:
cpu: "1000m"
memory: "1Gi"
4. Logstash部署
官方chart地址:https://github.com/helm/charts/tree/master/stable/logstash
安装
$ helm install --name logstash stable/logstash --namespace logs
参数说明:
image: repository: docker.elastic.co/logstash/logstash-oss tag: 7.2.0 pullPolicy: IfNotPresent persistence: enabled: true storageClass: "nfs-client" accessMode: ReadWriteOnce size: 2Gi
匹配label:json的pod日志,没有的话正常收集。
filebeatConfig:
filebeat.yml: |
filebeat.autodiscover:
providers:
- type: kubernetes
templates:
- condition:
equals:
kubernetes.labels.logFormat: "json"
config:
- type: docker
containers.ids:
- "${data.kubernetes.container.id}"
json.keys_under_root: true
json.overwrite_keys: true
json.add_error_key: true
- config:
- type: docker
containers.ids:
- "${data.kubernetes.container.id}"
processors:
- add_kubernetes_metadata:
in_cluster: true
output.elasticsearch:
hosts: '${ELASTICSEARCH_HOSTS:elasticsearch-master:9200}'
5. Elastalert部署
官方chart地址:https://github.com/helm/charts/tree/master/stable/elastalert
安装
helm install -n elastalert ./elastalert --namespace logs
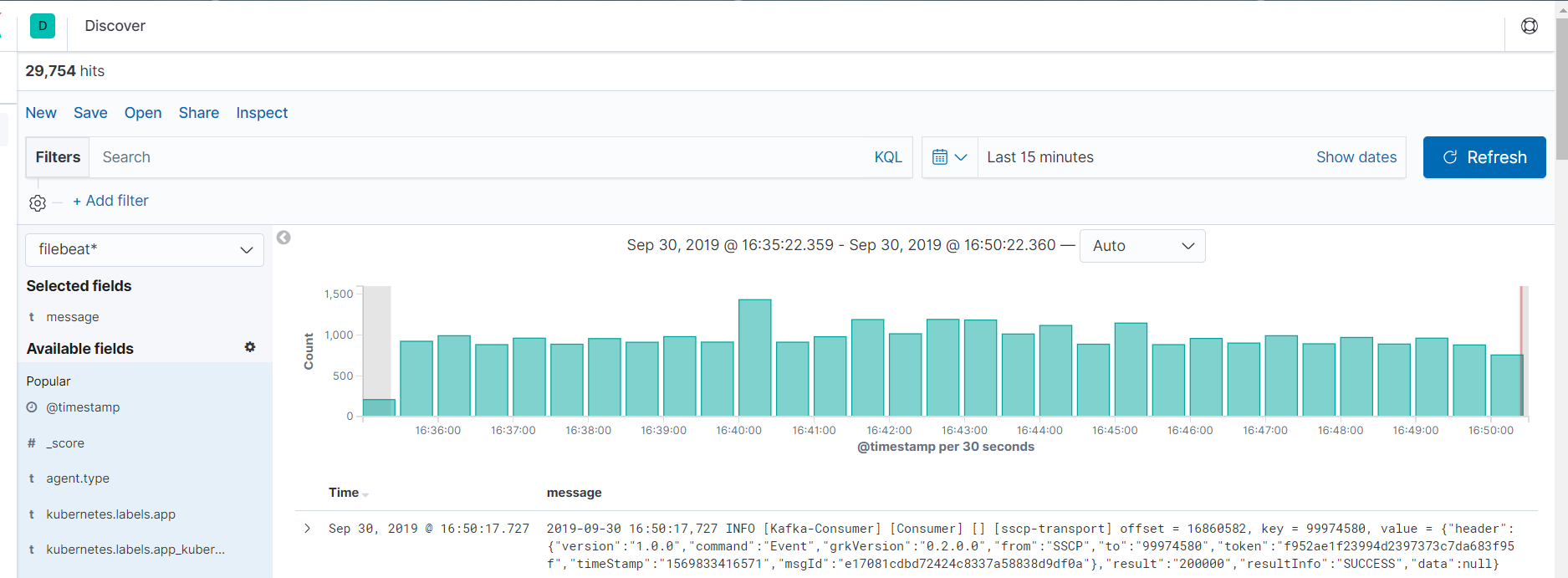
效果图:
helm部署Filebeat + ELK的更多相关文章
- 5分钟部署filebeat + ELK 5.1.1
标题有点噱头,不过网络环境好的情况下也差不多了^_^ 1. 首先保证安装了jdk. elasticsearch, logstash, kibana,filebeat都可以通过yum安装,这里前 ...
- Filebeat+ELK部署文档
在日常运维工作中,对于系统和业务日志的处理尤为重要.今天,在这里分享一下自己部署的Filebeat+ELK开源实时日志分析平台的记录过程,有不对的地方还望指出. 简单介绍: 日志主要包括系统日志.应用 ...
- filebeat + ELK 部署篇
ELK Stack Elasticsearch:分布式搜索和分析引擎,具有高可伸缩.高可靠和易管理等特点.基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储.搜索和分析操作.通 ...
- linux单机部署kafka(filebeat+elk组合)
filebeat+elk组合之kafka单机部署 准备: kafka下载链接地址:http://kafka.apache.org/downloads.html 在这里下载kafka_2.12-2.10 ...
- Kafka+Zookeeper+Filebeat+ELK 搭建日志收集系统
ELK ELK目前主流的一种日志系统,过多的就不多介绍了 Filebeat收集日志,将收集的日志输出到kafka,避免网络问题丢失信息 kafka接收到日志消息后直接消费到Logstash Logst ...
- docker stack 部署 filebeat
=============================================== 2018/7/21_第3次修改 ccb_warlock 更新 ...
- Filebeat+ELK
Filebeat+ELK filebeat是logstash的升级版,从功能上来说肯定不如logstash,但是logstah比较耗费资源: filebeat安装 暂时依托于window系统 下载fi ...
- FILEBEAT+ELK日志收集平台搭建流程
filebeat+elk日志收集平台搭建流程 1. 整体简介: 模式:单机 平台:Linux - centos - 7 ELK:elasticsearch.logstash.kiban ...
- 使用docker部署filebeat和logstash
想用filebeat读取项目的日志,然后发送logstash.logstash官网有相关的教程,但是docker部署的教程都太简洁了.自己折腾了半天,踩了不少坑,总算是将logstash和filebe ...
随机推荐
- 设计模式(C#)——03建造者模式
推荐阅读: 我的CSDN 我的博客园 QQ群:704621321 当一个复杂对象由一些子对象构成,并且子对象的变化会导致复杂对象的修改.这时我们需要提供一种"封装机制&qu ...
- Leetcode之深度优先搜索(DFS)专题-494. 目标和(Target Sum)
Leetcode之深度优先搜索(DFS)专题-494. 目标和(Target Sum) 深度优先搜索的解题详细介绍,点击 给定一个非负整数数组,a1, a2, ..., an, 和一个目标数,S.现在 ...
- Leetcode之回溯法专题-79. 单词搜索(Word Search)
Leetcode之回溯法专题-79. 单词搜索(Word Search) 给定一个二维网格和一个单词,找出该单词是否存在于网格中. 单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元 ...
- Codeforces Round #506 (Div. 3) 1029 F. Multicolored Markers
CF-1029F 题意: a,b个小正方形构造一个矩形,大小为(a+b),并且要求其中要么a个小正方形是矩形,要么b个小正方形是矩形. 思路: 之前在想要分a,b是否为奇数讨论,后来发现根本不需要.只 ...
- BZOJ2038 小Z的袜子 莫队
BZOJ2038 题意:q(5000)次询问,问在区间中随意取两个值,这两个值恰好相同的概率是多少?分数表示: 感觉自己复述的题意极度抽象,还是原题意有趣(逃: 思路:设在L到R这个区间中,x这个值得 ...
- codeforces 762 D. Maximum path(dp)
题目链接:http://codeforces.com/problemset/problem/762/D 题意:给出一个3*n的矩阵然后问从左上角到右下角最大权值是多少,而且每一个点可以走上下左右,但是 ...
- PAT 天梯杯 L3-008. 喊山 bfs
L3-008. 喊山 时间限制 150 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 陈越 喊山,是人双手围在嘴边成喇叭状,对着远方高山发出“喂—喂喂 ...
- Mysql InnoDB引擎下 事务的隔离级别
mysql InnoDB 引擎下事物学习 建表user CREATE TABLE `user` ( `uid` bigint(20) unsigned NOT NULL AUTO_INCREMENT, ...
- 【3】Decision tree(决策树)
前言 Decision tree is one of the most popular classification tools 它用一个训练数据集学到一个映射,该映射以未知类别的新实例作为输入,输出 ...
- 获取mysql自主生成的主键
一.sql语句 CREATE TABLE `testgeneratedkeys` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) ...