简单谈谈dom解析xml和html
前言
文件对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展标志语言的标准编程接口。html,xml都是基于这个模型构造的。这也是一个W3C推出的标准。java,python,javascript等语言都提供了一套基于dom的编程接口。
java使用dom解析xml
一段xml文档, note.xml:
<?xml version="1.0" encoding="UTF-8"?>
<note>
<to id="1">George</to>
<from>John</from>
<heading>Reminder</heading>
<body>Don't forget the meeting!</body>
</note>
我们先使用w3c dom解析该xml:
@Test
public void test() {
NodeList nodeList = doc.getChildNodes().item(0).getChildNodes();
System.out.println("xml size: " + nodeList.getLength());
for(int i = 0; i < nodeList.getLength(); i ++) {
Node node = nodeList.item(i);
System.out.println(node.getNodeType());
System.out.println(node.getNodeName());
}
}
输出:
xml size: 9
3
#text
1
to
3
#text
1
from
3
#text
1
heading
3
#text
1
body
3
#text
我们看到代码输出note节点的字节点的时候,有9个节点,但是xml文档中note节点实际上只有to、from、heading、body4个节点。 那为什么是9个呢,原因是这样的。
选取几个w3c规范中关于节点类型的描述:
| 节点类型 | 描述 | nodeName返回值 | nodeValue返回值 | 子元素 | 类型常量值 |
|---|---|---|---|---|---|
| Document | 表示整个文档(DOM 树的根节点) | #document | null | Element(max. one),Comment,DocumentType | 9 |
| Element | 表示 element(元素)元素 | element name | null | Text,Comment,CDATASection | 1 |
| Attr | 表示属性 | 属性名称 | 属性值 | Text | 2 |
| Text | 表示元素或属性中的文本内容。 | #text | 节点内容 | None | 3 |
| CDATASection | 表示文档中的 CDATA 区段(文本不会被解析器解析) | #cdata-section | 节点内容 | None | 4 |
| Comment | 表示注释 | #comment | 注释文本 | None | 8 |
更多细节请查看w3c DOM节点类型
下面解释一下文档节点的字节点的处理过程:

其中红色部分为Text节点,紫色部分是Element节点(只画了部分)。</body>后面的也是一个Element节点,所有4个Element节点,5个Text节点。
所以输出的内容中3 #text表示该节点是个Text节点,1 节点name是个Element节点,这与表格中表述的是一样的。
测试代码:
@Test
public void test1() {
NodeList nodeList = doc.getChildNodes().item(0).getChildNodes();
System.out.println("xml size: " + nodeList.getLength());
for(int i = 0; i < nodeList.getLength(); i ++) {
Node node = nodeList.item(i);
if(node.getNodeType() == Node.TEXT_NODE) {
System.out.println(node.getNodeValue().replace("\n","hr").replace(' ', '-'));
}
}
}
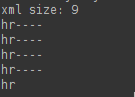
很明显,我们把空格和回车键替换打印后发现我们的结论是正确的。
测试代码:
@Test
public void test2() {
System.out.println("doc type: " + doc.getNodeType());
NodeList nodeList = doc.getChildNodes().item(0).getChildNodes();
Node secondNode = nodeList.item(1);
System.out.println("element [to] node type: " + secondNode.getNodeType());
System.out.println("element [to] node name: " + secondNode.getNodeName());
System.out.println("element [to] node value: " + secondNode.getNodeValue());
System.out.println("element [to] children len: " + secondNode.getChildNodes().getLength());
System.out.println("element [to] children node type: " + secondNode.getChildNodes().item(0).getNodeType());
System.out.println("element [to] children node value: " + secondNode.getChildNodes().item(0).getNodeValue());
System.out.println("element [to] children node name: " + secondNode.getChildNodes().item(0).getNodeName());
Node attNode = secondNode.getAttributes().item(0);
System.out.println("attr type: " + attNode.getNodeType());
}
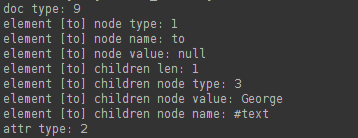
输出结果跟表格中是一样的。
大家有兴趣的话其他类型的节点比如CDATA节点大家可以自行测试~
javascript使用dom解析html
html代码:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>JS Bin</title>
</head>
<body>
<div>
<p>gogogo</p>
</div>
</body>
</html>
js代码:
console.log(document.nodeType);
var div = document.getElementsByTagName("div")[0]; //9
console.log(div.nodeType); //1
for(var i = 0;i < div.childNodes.length; i ++) {
console.log(div.childNodes[i].nodeType);
}
分别输出9,1,3,1,3
跟我们在表格中对应~
总结
本次博客主要讲解了dom解析xml和html。 以前使用java解析xml的时候总是使用一些第三方库,比如jdom。 但是dom却是w3c的规范,不止java,包括javascript,python这些主流语言也都主持,有了规范,语言只是实现了这些规范而已。
简单谈谈dom解析xml和html的更多相关文章
- Java解析XML文档(简单实例)——dom解析xml
一.前言 用Java解析XML文档,最常用的有两种方法:使用基于事件的XML简单API(Simple API for XML)称为SAX和基于树和节点的文档对象模型(Document Object ...
- DOM的概念和简单应用:使用DOM解析XML数据
概念:DOM是Document Object Model的简称,即文档数据模型. Oracle公司提供了JAXP(Java API for XML Processing)来解析XML.JAXP会把XM ...
- JAVA中使用DOM解析XML文件
XML是一种方便快捷高效的数据保存传输的格式,在JSON广泛使用之前,XML是服务器和客户端之间数据传输的主要方式.因此,需要使用各种方式,解析服务器传送过来的信息,以供使用者查看. JAVA作为一种 ...
- xml语法、DTD约束xml、Schema约束xml、DOM解析xml
今日大纲 1.什么是xml.xml的作用 2.xml的语法 3.DTD约束xml 4.Schema约束xml 5.DOM解析xml 1.什么是xml.xml的作用 1.1.xml介绍 在前面学习的ht ...
- xml--通过DOM解析XML
此文章通过3个例子表示DOM方式解析XML的用法. 通过DOM解析XML必须要写的3行代码. step 1: 获得dom解析器工厂(工作的作用是用于创建具体的解析器) step 2:获得具体的dom解 ...
- POPTEST老李分享DOM解析XML之java
POPTEST老李分享DOM解析XML之java Java提供了两种XML解析器:树型解释器DOM(Document Object Model,文档对象模型),和流机制解析器SAX(Simple ...
- Java解析XML文档——dom解析xml
一.前言 用Java解析XML文档,最常用的有两种方法:使用基于事件的XML简单API(Simple API for XML)称为SAX和基于树和节点的文档对象模型(Document Object M ...
- DOM解析XML文件例子
DOM解析XML文件是一次性将目标文件中的所有节点都读入,然后再进行后续操作的方式. 一般分为以下几步: 1. 定义好目标XML文件路径path . 2. 实例化DOM解析工厂对象 ,Document ...
- 使用DOM解析XML文档
简单介绍一下使用DOM解析XML文档,解析XML文件案例: <?xml version="1.0" encoding="UTF-8"?> -< ...
随机推荐
- jquery.serialize() 函数详解
jQuery - serialize() 方法 W3School给出的定义与用法: serialize() 方法通过序列化表单值,创建 URL 编码文本字符串. 您可以选择一个或多个表单元素(比如 i ...
- CSS3 Gradient线性渐变
废话小说,看代码 <!DOCTYPE html > <html > <head> <meta charset="utf-8"> &l ...
- numpy函数fromfunction分析
从函数规则创建数组是非常方便的方法.在numpy中我们常用fromfunction函数来实现这个功能. 在numpy的官网有这么一个例子. >>> def f(x,y): ... r ...
- Java并发之CountDownLatch 多功能同步工具类
package com.thread.test.thread; import java.util.Random; import java.util.concurrent.*; /** * CountD ...
- Activiti之 Exclusive Gateway
一.Exclusive Gateway Exclusive Gateway(也称为XOR网关或更多技术基于数据的排他网关)经常用做决定流程的流转方向.当流程到达该网关的时候,所有的流出序列流到按照已定 ...
- 初步认识Hive
初步认识Hive hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行.其优点是学习 ...
- my_strcat()
char* my_strcat(char* S1,const char* S2){ //严格符合strcat()的接口形式,需要的S1空间是两个字符串空间总和-1. int i=0,j=0; whil ...
- WIN 下的超动态菜单(二)用法
WIN 下的超动态菜单(一)简介 WIN 下的超动态菜单(二)用法 WIN 下的超动态菜单(三)代码 作者:黄山松,发表于博客园:http://www.cnblogs.com/tomview/ ...
- 远程连接mysql报错【1130 -host 'localhost' is not allowed to connect to this mysql server】
远程连接mysql时包如下错误: 1130 -host 'localhost' is not allowed to connect to this mysql server 解决办法 本地用root账 ...
- canvas作为背景
比如canvas的id是HB, 画好后执行document.body.style.background = "url('"+HB.toDataURL()+"')" ...