Netty构建分布式消息队列实现原理浅析
在本人的上一篇博客文章:Netty构建分布式消息队列(AvatarMQ)设计指南之架构篇 中,重点向大家介绍了AvatarMQ主要构成模块以及目前存在的优缺点。最后以一个生产者、消费者传递消息的例子,具体演示了AvatarMQ所具备的基本消息路由功能。而本文的写作目的,是想从开发、设计的角度,简单的对如何使用Netty,构建分布式消息队列背后的技术细节、原理,进行一下简单的分析和说明。
首先,在一个企业级的架构应用中,究竟何时需引入消息队列呢?本人认为,最经常的情况,无非这几种:做业务解耦、事件消息广播、消息流控处理。其中,对于业务解耦是作为消息队列,要解决的一个首要问题。所谓业务解耦,就是说在一个业务流程处理上,只关注具体的流程,尽到通知的责任即可,不必等待消息处理的结果。
总得来看,企业级系统模块通信的方式通常情况下,无非两种。
同步方式:REST、RPC方式实现;异步方式:消息中间件(消息队列)方式实现。
同步方式的优点:可以基于http协议之上,无需中间件代理,系统架构相对而言比较简单。缺点是:客户端和服务端紧密耦合,并且要实时在线通信,否则会导致消息发送失败。
异步方式的优点:客户端和服务端互相解耦,双方可以不产生依赖。缺点是:由于引入了消息中间件,在编程的时候会增加难度系数。此外,消息中间件的可靠性、容错性、健壮性往往成为这类架构的决定性因素。
举一个本人工作中的例子向大家说明一下:移动业务中的产品订购中心,每当一个用户通过某些渠道(营业厅、自助终端等等)开通、订购了某个套餐之后,如果这些套餐涉及第三方平台派单的话,产品订购中心会向第三方平台发起订购请求操作。试想一下,如果遇到高峰受理时间段,由于业务受理量的激增,导致一些外围系统的响应速度降低(比如业务网关响应速度不及时、网络延时等等原因),最终用户开通一个套餐花在主流程的时间会延长很多,这个会造成极不好的用户体验,最终可能导致受理失败。在上述的场景里面,我们就可以很好的引入一个消息队列进行业务的解耦,具体来说,产品订购中心只要“通知”第三方平台,我们的套餐开通成功了,并不一定非要同步阻塞地等待其真正的开通处理完成。正因为如此,消息队列逐渐成为当下系统模块通信的主要方式手段。
当今在Java的消息队列通信领域,有很多主流的消息中间件,比如RabbitMQ、ActiveMQ、以及炙手可热Kafka。其中ActiveMQ是基于JMS的标准之上开发定制的一套消息队列系统,性能稳定,访问接口也非常友好,但是这类的消息队列在访问吞吐量上有所折扣;另外一个方面,比如Kafka这样,以高效吞吐量著称的消息队列系统,但是在稳定性和可靠性上,能力似乎还不够,因此更多的是用在服务日志传输、短消息推送等等对于可靠性不高的业务场景之中。总结起来,不管是ActiveMQ还是Kafka,其框架的背后涉及到很多异步网络通信、多线程、高并发处理方面的专业技术知识。但本文的重点,也不在于介绍这些消息中间件背后的技术细节,而是想重点阐述一下,如何透过上述消息队列的基本原理,在必要的时候,开发定制一套符合自身业务要求的消息队列系统时,能够获得更加全面的视角去设计、考量这些问题。
因此本人用心开发实现了一个,基于Netty的消息队列系统:AvatarMQ。当然,在设计、实现AvatarMQ的时候,我会适当参考这些成熟消息中间件中用到的很多重要的思想理念。
当各位从github上面下载到AvatarMQ的源代码的时候,可以发现,其中的包结构如下所示:

现在对每个包的主要功能进行一下简要说明(下面省略前缀com.newlandframework.avatarmq)。
broker:消息中间件的服务器模块,主要负责消息的路由、负载均衡,对于生产者、消费者进行消息的应答回复处理(ACK),AvatarMQ中的中心节点,是连接生产者、消费者的桥梁纽带。
consumer:消息中间件中的消费者模块,负责接收生产者过来的消息,在设计的时候,会对消费者进行一个集群化管理,同一个集群标识的消费者,会构成一个大的消费者集群,作为一个整体,接收生产者投递过来的消息。此外,还提供消费者接收消息相关的API给客户端进行调用。
producer:消息中间件中的生产者模块,负责生产特定主题(Topic)的消息,传递给对此主题感兴趣的消费者,同时提供生产者生产消息的API接口,给客户端使用。
core:AvatarMQ中消息处理的核心模块,负责消息的内存存储、应答控制、对消息进行多线程任务分派处理。
model:主要定义了AvatarMQ中的数据模型对象,比如MessageType消息类型、MessageSource消息源头等等模型对象的定义。
msg:主要定义了具体的消息类型对应的结构模型,比如消费者订阅消息SubscribeMessage、消费者取消订阅消息UnSubscribeMessage,消息服务器应答给生产者的应答消息ProducerAckMessage、消息服务器应答给消费者的应答消息ConsumerAckMessage。
netty:主要封装了Netty网络通信相关的核心模块代码,比如订阅消息事件的路由分派策略、消息的编码、解码器等等。
serialize:利用Kryo这个优秀高效的对象序列化、反序列框架对消息对象进行序列化网络传输。
spring:Spring的容器管理类,负责把AvatarMQ中的消息服务器模块:Broker,进行容器化管理。这个包里面的AvatarMQServerStartup是整个AvatarMQ消息服务器的启动入口。
test:这个就不用多说了,就是针对AvatarMQ进行消息路由传递的测试demo。
AvatarMQ运行原理示意图:
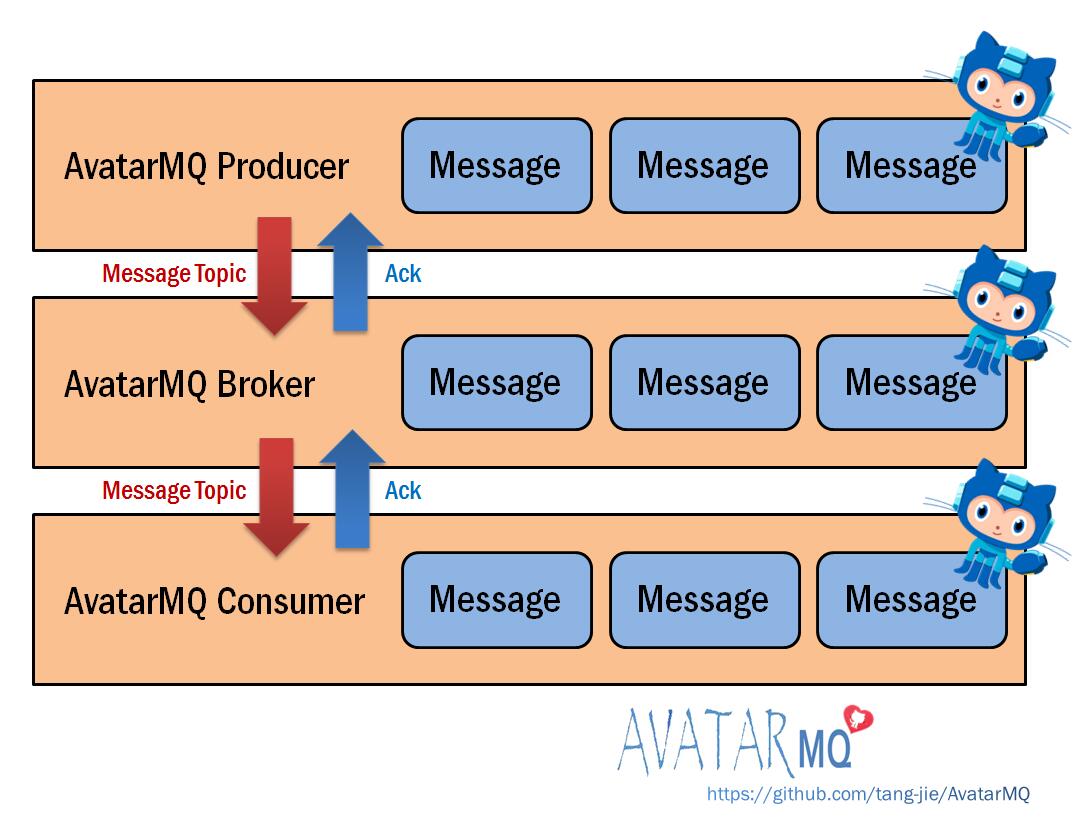
首先是消息生产者客户端(AvatarMQ Producer)发送带有主题的消息给消息转发服务器(AvatarMQ Broker),消息转发服务器确认收到生产者的消息,发送ACK应答给生产者,然后把消息继续投递给消费者(AvatarMQ Consumer)。同时broker服务器接收来自消费者的订阅、取消订阅消息,并发送ACK应该给对应的消费者,整个消息系统就是这样周而复始的工作。
现在再来看一下,AvatarMQ中的核心模块的组成,如下图所示:

Producer Manage:消息的生产者,其主要代码在(com.newlandframework.avatarmq.producer)包之下,其主要代码模块关键部分简要说明如下:
package com.newlandframework.avatarmq.producer; import com.newlandframework.avatarmq.core.AvatarMQAction;
import com.newlandframework.avatarmq.model.MessageSource;
import com.newlandframework.avatarmq.model.MessageType;
import com.newlandframework.avatarmq.model.RequestMessage;
import com.newlandframework.avatarmq.model.ResponseMessage;
import com.newlandframework.avatarmq.msg.Message;
import com.newlandframework.avatarmq.msg.ProducerAckMessage;
import com.newlandframework.avatarmq.netty.MessageProcessor;
import java.util.concurrent.atomic.AtomicLong; /**
* @filename:AvatarMQProducer.java
* @description:AvatarMQProducer功能模块
* @author tangjie<https://github.com/tang-jie>
* @blog http://www.cnblogs.com/jietang/
* @since 2016-8-11
*/
public class AvatarMQProducer extends MessageProcessor implements AvatarMQAction { private boolean brokerConnect = false;
private boolean running = false;
private String brokerServerAddress;
private String topic;
private String defaultClusterId = "AvatarMQProducerClusters";
private String clusterId = "";
private AtomicLong msgId = new AtomicLong(0L); //连接消息转发服务器broker的ip地址,以及生产出来消息附带的主题信息
public AvatarMQProducer(String brokerServerAddress, String topic) {
super(brokerServerAddress);
this.brokerServerAddress = brokerServerAddress;
this.topic = topic;
} //没有连接上消息转发服务器broker就发送的话,直接应答失败
private ProducerAckMessage checkMode() {
if (!brokerConnect) {
ProducerAckMessage ack = new ProducerAckMessage();
ack.setStatus(ProducerAckMessage.FAIL);
return ack;
} return null;
} //启动消息生产者
public void start() {
super.getMessageConnectFactory().connect();
brokerConnect = true;
running = true;
} //连接消息转发服务器broker,设定生产者消息处理钩子,用于处理broker过来的消息应答
public void init() {
ProducerHookMessageEvent hook = new ProducerHookMessageEvent();
hook.setBrokerConnect(brokerConnect);
hook.setRunning(running);
super.getMessageConnectFactory().setMessageHandle(new MessageProducerHandler(this, hook));
} //投递消息API
public ProducerAckMessage delivery(Message message) {
if (!running || !brokerConnect) {
return checkMode();
} message.setTopic(topic);
message.setTimeStamp(System.currentTimeMillis()); RequestMessage request = new RequestMessage();
request.setMsgId(String.valueOf(msgId.incrementAndGet()));
request.setMsgParams(message);
request.setMsgType(MessageType.AvatarMQMessage);
request.setMsgSource(MessageSource.AvatarMQProducer);
message.setMsgId(request.getMsgId()); ResponseMessage response = (ResponseMessage) sendAsynMessage(request);
if (response == null) {
ProducerAckMessage ack = new ProducerAckMessage();
ack.setStatus(ProducerAckMessage.FAIL);
return ack;
} ProducerAckMessage result = (ProducerAckMessage) response.getMsgParams();
return result;
} //关闭消息生产者
public void shutdown() {
if (running) {
running = false;
super.getMessageConnectFactory().close();
super.closeMessageConnectFactory();
}
} public String getTopic() {
return topic;
} public void setTopic(String topic) {
this.topic = topic;
} public String getClusterId() {
return clusterId;
} public void setClusterId(String clusterId) {
this.clusterId = clusterId;
}
}
Consumer Clusters Manage / Message Routing:消息的消费者集群管理以及消息路由模块,其主要模块在包(com.newlandframework.avatarmq.consumer)之中。其中消息消费者对象,对应的核心代码主要功能描述如下:
package com.newlandframework.avatarmq.consumer; import com.google.common.base.Joiner;
import com.newlandframework.avatarmq.core.AvatarMQAction;
import com.newlandframework.avatarmq.core.MessageIdGenerator;
import com.newlandframework.avatarmq.core.MessageSystemConfig;
import com.newlandframework.avatarmq.model.MessageType;
import com.newlandframework.avatarmq.model.RequestMessage;
import com.newlandframework.avatarmq.msg.SubscribeMessage;
import com.newlandframework.avatarmq.msg.UnSubscribeMessage;
import com.newlandframework.avatarmq.netty.MessageProcessor; /**
* @filename:AvatarMQConsumer.java
* @description:AvatarMQConsumer功能模块
* @author tangjie<https://github.com/tang-jie>
* @blog http://www.cnblogs.com/jietang/
* @since 2016-8-11
*/
public class AvatarMQConsumer extends MessageProcessor implements AvatarMQAction { private ProducerMessageHook hook;
private String brokerServerAddress;
private String topic;
private boolean subscribeMessage = false;
private boolean running = false;
private String defaultClusterId = "AvatarMQConsumerClusters";
private String clusterId = "";
private String consumerId = ""; //连接的消息服务器broker的ip地址以及关注的生产过来的消息钩子
public AvatarMQConsumer(String brokerServerAddress, String topic, ProducerMessageHook hook) {
super(brokerServerAddress);
this.hook = hook;
this.brokerServerAddress = brokerServerAddress;
this.topic = topic;
} //向消息服务器broker发送取消订阅消息
private void unRegister() {
RequestMessage request = new RequestMessage();
request.setMsgType(MessageType.AvatarMQUnsubscribe);
request.setMsgId(new MessageIdGenerator().generate());
request.setMsgParams(new UnSubscribeMessage(consumerId));
sendSyncMessage(request);
super.getMessageConnectFactory().close();
super.closeMessageConnectFactory();
running = false;
} //向消息服务器broker发送订阅消息
private void register() {
RequestMessage request = new RequestMessage();
request.setMsgType(MessageType.AvatarMQSubscribe);
request.setMsgId(new MessageIdGenerator().generate()); SubscribeMessage subscript = new SubscribeMessage();
subscript.setClusterId((clusterId.equals("") ? defaultClusterId : clusterId));
subscript.setTopic(topic);
subscript.setConsumerId(consumerId); request.setMsgParams(subscript); sendAsynMessage(request);
} public void init() {
super.getMessageConnectFactory().setMessageHandle(new MessageConsumerHandler(this, new ConsumerHookMessageEvent(hook)));
Joiner joiner = Joiner.on(MessageSystemConfig.MessageDelimiter).skipNulls();
consumerId = joiner.join((clusterId.equals("") ? defaultClusterId : clusterId), topic, new MessageIdGenerator().generate());
} //连接消息服务器broker
public void start() {
if (isSubscribeMessage()) {
super.getMessageConnectFactory().connect();
register();
running = true;
}
} public void receiveMode() {
setSubscribeMessage(true);
} public void shutdown() {
if (running) {
unRegister();
}
} public String getBrokerServerAddress() {
return brokerServerAddress;
} public void setBrokerServerAddress(String brokerServerAddress) {
this.brokerServerAddress = brokerServerAddress;
} public String getTopic() {
return topic;
} public void setTopic(String topic) {
this.topic = topic;
} public boolean isSubscribeMessage() {
return subscribeMessage;
} public void setSubscribeMessage(boolean subscribeMessage) {
this.subscribeMessage = subscribeMessage;
} public String getDefaultClusterId() {
return defaultClusterId;
} public void setDefaultClusterId(String defaultClusterId) {
this.defaultClusterId = defaultClusterId;
} public String getClusterId() {
return clusterId;
} public void setClusterId(String clusterId) {
this.clusterId = clusterId;
}
}
消息的集群管理模块,主要代码是ConsumerContext.java、ConsumerClusters.java。先简单说一下消费者集群模块ConsumerClusters,主要负责定义消费者集群的行为,以及负责消息的路由。主要的功能描述如下所示:
package com.newlandframework.avatarmq.consumer; import com.newlandframework.avatarmq.model.RemoteChannelData;
import com.newlandframework.avatarmq.model.SubscriptionData;
import com.newlandframework.avatarmq.netty.NettyUtil;
import io.netty.channel.Channel;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.ConcurrentHashMap;
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.collections.MapUtils;
import org.apache.commons.collections.Predicate; /**
* @filename:ConsumerClusters.java
* @description:ConsumerClusters功能模块
* @author tangjie<https://github.com/tang-jie>
* @blog http://www.cnblogs.com/jietang/
* @since 2016-8-11
*/
public class ConsumerClusters { //轮询调度(Round-Robin Scheduling)位置标记
private int next = 0;
private final String clustersId;
private final ConcurrentHashMap<String/*生产者消息的主题*/, SubscriptionData/*消息对应的topic信息数据结构*/> subMap
= new ConcurrentHashMap<String, SubscriptionData>(); private final ConcurrentHashMap<String/*消费者标识编码*/, RemoteChannelData/*对应的消费者的netty网络通信管道信息*/> channelMap
= new ConcurrentHashMap<String, RemoteChannelData>(); private final List<RemoteChannelData> channelList = Collections.synchronizedList(new ArrayList<RemoteChannelData>()); public ConsumerClusters(String clustersId) {
this.clustersId = clustersId;
} public String getClustersId() {
return clustersId;
} public ConcurrentHashMap<String, SubscriptionData> getSubMap() {
return subMap;
} public ConcurrentHashMap<String, RemoteChannelData> getChannelMap() {
return channelMap;
} //添加一个消费者到消费者集群
public void attachRemoteChannelData(String clientId, RemoteChannelData channelinfo) {
if (findRemoteChannelData(channelinfo.getClientId()) == null) {
channelMap.put(clientId, channelinfo);
subMap.put(channelinfo.getSubcript().getTopic(), channelinfo.getSubcript());
channelList.add(channelinfo);
} else {
System.out.println("consumer clusters exists! it's clientId:" + clientId);
}
} //从消费者集群中删除一个消费者
public void detachRemoteChannelData(String clientId) {
channelMap.remove(clientId); Predicate predicate = new Predicate() {
public boolean evaluate(Object object) {
String id = ((RemoteChannelData) object).getClientId();
return id.compareTo(clientId) == 0;
}
}; RemoteChannelData data = (RemoteChannelData) CollectionUtils.find(channelList, predicate);
if (data != null) {
channelList.remove(data);
}
} //根据消费者标识编码,在消费者集群中查找定位一个消费者,如果不存在返回null
public RemoteChannelData findRemoteChannelData(String clientId) {
return (RemoteChannelData) MapUtils.getObject(channelMap, clientId);
} //负载均衡,根据连接到broker的顺序,依次投递消息给消费者。这里的均衡算法直接采用
//轮询调度(Round-Robin Scheduling),后续可以加入:加权轮询、随机轮询、哈希轮询等等策略。
public RemoteChannelData nextRemoteChannelData() { Predicate predicate = new Predicate() {
public boolean evaluate(Object object) {
RemoteChannelData data = (RemoteChannelData) object;
Channel channel = data.getChannel();
return NettyUtil.validateChannel(channel);
}
}; CollectionUtils.filter(channelList, predicate);
return channelList.get(next++ % channelList.size());
} //根据生产者的主题关键字,定位于具体的消息结构
public SubscriptionData findSubscriptionData(String topic) {
return this.subMap.get(topic);
}
}
而ConsumerContext主要的负责管理消费者集群的,其主要核心代码注释说明如下:
package com.newlandframework.avatarmq.consumer; import com.newlandframework.avatarmq.model.RemoteChannelData;
import com.newlandframework.avatarmq.model.SubscriptionData;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.CopyOnWriteArrayList;
import org.apache.commons.collections.Predicate;
import org.apache.commons.collections.iterators.FilterIterator; /**
* @filename:ConsumerContext.java
* @description:ConsumerContext功能模块
* @author tangjie<https://github.com/tang-jie>
* @blog http://www.cnblogs.com/jietang/
* @since 2016-8-11
*/
public class ConsumerContext {
//消费者集群关系定义
private static final CopyOnWriteArrayList<ClustersRelation> relationArray = new CopyOnWriteArrayList<ClustersRelation>();
//消费者集群状态
private static final CopyOnWriteArrayList<ClustersState> stateArray = new CopyOnWriteArrayList<ClustersState>(); public static void setClustersStat(String clusters, int stat) {
stateArray.add(new ClustersState(clusters, stat));
} //根据消费者集群编码cluster_id获取一个消费者集群的状态
public static int getClustersStat(String clusters) { Predicate predicate = new Predicate() {
public boolean evaluate(Object object) {
String clustersId = ((ClustersState) object).getClusters();
return clustersId.compareTo(clusters) == 0;
}
}; Iterator iterator = new FilterIterator(stateArray.iterator(), predicate); ClustersState state = null;
while (iterator.hasNext()) {
state = (ClustersState) iterator.next();
break; }
return (state != null) ? state.getState() : 0;
} //根据消费者集群编码cluster_id查找一个消费者集群
public static ConsumerClusters selectByClusters(String clusters) {
Predicate predicate = new Predicate() {
public boolean evaluate(Object object) {
String id = ((ClustersRelation) object).getId();
return id.compareTo(clusters) == 0;
}
}; Iterator iterator = new FilterIterator(relationArray.iterator(), predicate); ClustersRelation relation = null;
while (iterator.hasNext()) {
relation = (ClustersRelation) iterator.next();
break;
} return (relation != null) ? relation.getClusters() : null;
} //查找一下关注这个主题的消费者集群集合
public static List<ConsumerClusters> selectByTopic(String topic) { List<ConsumerClusters> clusters = new ArrayList<ConsumerClusters>(); for (int i = 0; i < relationArray.size(); i++) {
ConcurrentHashMap<String, SubscriptionData> subscriptionTable = relationArray.get(i).getClusters().getSubMap();
if (subscriptionTable.containsKey(topic)) {
clusters.add(relationArray.get(i).getClusters());
}
} return clusters;
} //添加消费者集群
public static void addClusters(String clusters, RemoteChannelData channelinfo) {
ConsumerClusters manage = selectByClusters(clusters);
if (manage == null) {
ConsumerClusters newClusters = new ConsumerClusters(clusters);
newClusters.attachRemoteChannelData(channelinfo.getClientId(), channelinfo);
relationArray.add(new ClustersRelation(clusters, newClusters));
} else if (manage.findRemoteChannelData(channelinfo.getClientId()) != null) {
manage.detachRemoteChannelData(channelinfo.getClientId());
manage.attachRemoteChannelData(channelinfo.getClientId(), channelinfo);
} else {
String topic = channelinfo.getSubcript().getTopic();
boolean touchChannel = manage.getSubMap().containsKey(topic);
if (touchChannel) {
manage.attachRemoteChannelData(channelinfo.getClientId(), channelinfo);
} else {
manage.getSubMap().clear();
manage.getChannelMap().clear();
manage.attachRemoteChannelData(channelinfo.getClientId(), channelinfo);
}
}
} //从一个消费者集群中删除一个消费者
public static void unLoad(String clientId) { for (int i = 0; i < relationArray.size(); i++) {
String id = relationArray.get(i).getId();
ConsumerClusters manage = relationArray.get(i).getClusters(); if (manage.findRemoteChannelData(clientId) != null) {
manage.detachRemoteChannelData(clientId);
} if (manage.getChannelMap().size() == 0) {
ClustersRelation relation = new ClustersRelation();
relation.setId(id);
relationArray.remove(id);
}
}
}
}
ACK Queue Dispatch:主要是broker分别向对应的消息生产者、消费者发送ACK消息应答,其主要核心模块是在:com.newlandframework.avatarmq.broker包下面的AckPullMessageController和AckPushMessageController模块,主要职责是在broker中收集生产者的消息,确认成功收到之后,把其放到消息队列容器中,然后专门安排一个工作线程池把ACK应答发送给生产者。
Message Queue Dispatch:生产者消息的分派,主要是由com.newlandframework.avatarmq.broker包下面的SendMessageController派发模块进行任务的分派,其中消息分派支持两种策略,一种是内存缓冲消息区里面只要一有消息就通知消费者;还有一种是对消息进行缓冲处理,累计到一定的数量之后进行派发,这个是根据:MessageSystemConfig类中的核心参数:SystemPropertySendMessageControllerTaskCommitValue(com.newlandframework.avatarmq.system.send.taskcommit)决定的,默认是1。即一有消息就派发,如果改成大于1的数值,表示消息缓冲的数量。现在给出SendMessageController的核心实现代码:
package com.newlandframework.avatarmq.broker; import com.newlandframework.avatarmq.core.SemaphoreCache;
import com.newlandframework.avatarmq.core.MessageSystemConfig;
import com.newlandframework.avatarmq.core.MessageTaskQueue;
import com.newlandframework.avatarmq.core.SendMessageCache;
import com.newlandframework.avatarmq.model.MessageDispatchTask;
import java.util.Timer;
import java.util.TimerTask;
import java.util.concurrent.Callable;
import java.util.concurrent.ConcurrentLinkedQueue;
import java.util.concurrent.atomic.AtomicBoolean;
import java.util.logging.Level;
import java.util.logging.Logger; /**
* @filename:SendMessageController.java
* @description:SendMessageController功能模块
* @author tangjie<https://github.com/tang-jie>
* @blog http://www.cnblogs.com/jietang/
* @since 2016-8-11
*/
public class SendMessageController implements Callable<Void> { private volatile boolean stoped = false; private AtomicBoolean flushTask = new AtomicBoolean(false); private ThreadLocal<ConcurrentLinkedQueue<MessageDispatchTask>> requestCacheList = new ThreadLocal<ConcurrentLinkedQueue<MessageDispatchTask>>() {
protected ConcurrentLinkedQueue<MessageDispatchTask> initialValue() {
return new ConcurrentLinkedQueue<MessageDispatchTask>();
}
}; private final Timer timer = new Timer("SendMessageTaskMonitor", true); public void stop() {
stoped = true;
} public boolean isStoped() {
return stoped;
} public Void call() {
int period = MessageSystemConfig.SendMessageControllerPeriodTimeValue;
int commitNumber = MessageSystemConfig.SendMessageControllerTaskCommitValue;
int sleepTime = MessageSystemConfig.SendMessageControllerTaskSleepTimeValue; ConcurrentLinkedQueue<MessageDispatchTask> queue = requestCacheList.get();
SendMessageCache ref = SendMessageCache.getInstance(); while (!stoped) {
SemaphoreCache.acquire(MessageSystemConfig.NotifyTaskSemaphoreValue);
MessageDispatchTask task = MessageTaskQueue.getInstance().getTask(); queue.add(task); if (queue.size() == 0) {
try {
Thread.sleep(sleepTime);
continue;
} catch (InterruptedException ex) {
Logger.getLogger(SendMessageController.class.getName()).log(Level.SEVERE, null, ex);
}
} if (queue.size() > 0 && (queue.size() % commitNumber == 0 || flushTask.get() == true)) {
ref.commit(queue);
queue.clear();
flushTask.compareAndSet(true, false);
} timer.scheduleAtFixedRate(new TimerTask() { public void run() {
try {
flushTask.compareAndSet(false, true);
} catch (Exception e) {
System.out.println("SendMessageTaskMonitor happen exception");
}
}
}, 1000 * 1, period);
} return null;
}
}
消息分派采用多线程并行派发,其内部通过栅栏机制,为消息派发设置一个屏障点,后续可以暴露给JMX接口,进行对整个消息系统,消息派发情况的动态监控。比如发现消息积压太多,可以加大线程并行度。消息无堆积的话,降低线程并行度,减轻系统负荷。现在给出消息派发任务模块SendMessageTask的核心代码:
package com.newlandframework.avatarmq.core; import com.newlandframework.avatarmq.msg.ConsumerAckMessage;
import com.newlandframework.avatarmq.msg.Message;
import com.newlandframework.avatarmq.broker.SendMessageLauncher;
import com.newlandframework.avatarmq.consumer.ClustersState;
import com.newlandframework.avatarmq.consumer.ConsumerContext;
import com.newlandframework.avatarmq.model.MessageType;
import com.newlandframework.avatarmq.model.RequestMessage;
import com.newlandframework.avatarmq.model.ResponseMessage;
import com.newlandframework.avatarmq.model.RemoteChannelData;
import com.newlandframework.avatarmq.model.MessageSource;
import com.newlandframework.avatarmq.model.MessageDispatchTask;
import com.newlandframework.avatarmq.netty.NettyUtil;
import java.util.concurrent.Callable;
import java.util.concurrent.Phaser; /**
* @filename:SendMessageTask.java
* @description:SendMessageTask功能模块
* @author tangjie<https://github.com/tang-jie>
* @blog http://www.cnblogs.com/jietang/
* @since 2016-8-11
*/
public class SendMessageTask implements Callable<Void> { private MessageDispatchTask[] tasks;
//消息栅栏器,为后续进行消息JMX实时监控预留接口
private Phaser phaser = null;
private SendMessageLauncher launcher = SendMessageLauncher.getInstance(); public SendMessageTask(Phaser phaser, MessageDispatchTask[] tasks) {
this.phaser = phaser;
this.tasks = tasks;
} public Void call() throws Exception {
for (MessageDispatchTask task : tasks) {
Message msg = task.getMessage(); if (ConsumerContext.selectByClusters(task.getClusters()) != null) {
RemoteChannelData channel = ConsumerContext.selectByClusters(task.getClusters()).nextRemoteChannelData(); ResponseMessage response = new ResponseMessage();
response.setMsgSource(MessageSource.AvatarMQBroker);
response.setMsgType(MessageType.AvatarMQMessage);
response.setMsgParams(msg);
response.setMsgId(new MessageIdGenerator().generate()); try {
//消息派发的时候,发现管道不可达,跳过
if (!NettyUtil.validateChannel(channel.getChannel())) {
ConsumerContext.setClustersStat(task.getClusters(), ClustersState.NETWORKERR);
continue;
} RequestMessage request = (RequestMessage) launcher.launcher(channel.getChannel(), response); ConsumerAckMessage result = (ConsumerAckMessage) request.getMsgParams(); if (result.getStatus() == ConsumerAckMessage.SUCCESS) {
ConsumerContext.setClustersStat(task.getClusters(), ClustersState.SUCCESS);
}
} catch (Exception e) {
ConsumerContext.setClustersStat(task.getClusters(), ClustersState.ERROR);
}
}
}
//若干个并行的线程共同到达统一的屏障点之后,再进行消息统计,把数据最终汇总给JMX
phaser.arriveAndAwaitAdvance();
return null;
}
}
Message Serialize:消息的序列化模块,主要基于Kryo。其主要的核心代码为:com.newlandframework.avatarmq.serialize包下面的KryoCodecUtil、KryoSerialize完成消息的序列化和反序列化工作。其对应的主要核心代码模块是:
package com.newlandframework.avatarmq.serialize; import com.esotericsoftware.kryo.pool.KryoPool;
import io.netty.buffer.ByteBuf;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException; /**
* @filename:KryoCodecUtil.java
* @description:KryoCodecUtil功能模块
* @author tangjie<https://github.com/tang-jie>
* @blog http://www.cnblogs.com/jietang/
* @since 2016-8-11
*/
public class KryoCodecUtil implements MessageCodecUtil { private KryoPool pool; public KryoCodecUtil(KryoPool pool) {
this.pool = pool;
} public void encode(final ByteBuf out, final Object message) throws IOException {
ByteArrayOutputStream byteArrayOutputStream = null;
try {
byteArrayOutputStream = new ByteArrayOutputStream();
KryoSerialize kryoSerialization = new KryoSerialize(pool);
kryoSerialization.serialize(byteArrayOutputStream, message);
byte[] body = byteArrayOutputStream.toByteArray();
int dataLength = body.length;
out.writeInt(dataLength);
out.writeBytes(body);
} finally {
byteArrayOutputStream.close();
}
} public Object decode(byte[] body) throws IOException {
ByteArrayInputStream byteArrayInputStream = null;
try {
byteArrayInputStream = new ByteArrayInputStream(body);
KryoSerialize kryoSerialization = new KryoSerialize(pool);
Object obj = kryoSerialization.deserialize(byteArrayInputStream);
return obj;
} finally {
byteArrayInputStream.close();
}
}
}
package com.newlandframework.avatarmq.serialize; import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.io.Input;
import com.esotericsoftware.kryo.io.Output;
import com.esotericsoftware.kryo.pool.KryoPool;
import com.google.common.io.Closer;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream; /**
* @filename:KryoSerialize.java
* @description:KryoSerialize功能模块
* @author tangjie<https://github.com/tang-jie>
* @blog http://www.cnblogs.com/jietang/
* @since 2016-8-11
*/
public class KryoSerialize { private KryoPool pool = null;
private Closer closer = Closer.create(); public KryoSerialize(final KryoPool pool) {
this.pool = pool;
} public void serialize(OutputStream output, Object object) throws IOException {
try {
Kryo kryo = pool.borrow();
Output out = new Output(output);
closer.register(out);
closer.register(output);
kryo.writeClassAndObject(out, object);
pool.release(kryo);
} finally {
closer.close();
}
} public Object deserialize(InputStream input) throws IOException {
try {
Kryo kryo = pool.borrow();
Input in = new Input(input);
closer.register(in);
closer.register(input);
Object result = kryo.readClassAndObject(in);
pool.release(kryo);
return result;
} finally {
closer.close();
}
}
}
Netty Core:基于Netty对producer、consumer、broker的网络事件处理器(Handler)进行封装处理,核心模块在:com.newlandframework.avatarmq.netty包之下。其中broker的Netty网络事件处理器为ShareMessageEventWrapper、producer的Netty网络事件处理器为MessageProducerHandler、consumer的Netty网络事件处理器为MessageConsumerHandler。其对应的类图为:

可以看到,他们共同的父类是:MessageEventWrapper。该类的代码简要说明如下:
package com.newlandframework.avatarmq.netty; import com.newlandframework.avatarmq.core.HookMessageEvent;
import io.netty.channel.ChannelHandlerContext;
import io.netty.channel.ChannelInboundHandlerAdapter;
import org.springframework.aop.framework.ProxyFactory;
import org.springframework.aop.support.NameMatchMethodPointcutAdvisor; /**
* @filename:MessageEventWrapper.java
* @description:MessageEventWrapper功能模块
* @author tangjie<https://github.com/tang-jie>
* @blog http://www.cnblogs.com/jietang/
* @since 2016-8-11
*/
public class MessageEventWrapper<T> extends ChannelInboundHandlerAdapter implements MessageEventHandler, MessageEventProxy { final public static String proxyMappedName = "handleMessage";
protected MessageProcessor processor;
protected Throwable cause;
protected HookMessageEvent<T> hook;
protected MessageConnectFactory factory;
private MessageEventWrapper<T> wrapper; public MessageEventWrapper() { } public MessageEventWrapper(MessageProcessor processor) {
this(processor, null);
} public MessageEventWrapper(MessageProcessor processor, HookMessageEvent<T> hook) {
this.processor = processor;
this.hook = hook;
this.factory = processor.getMessageConnectFactory();
} public void handleMessage(ChannelHandlerContext ctx, Object msg) {
return;
} public void beforeMessage(Object msg) { } public void afterMessage(Object msg) { } //管道链路激活
public void channelActive(ChannelHandlerContext ctx) throws Exception {
super.channelActive(ctx);
} //读管道数据
public void channelRead(ChannelHandlerContext ctx, Object msg)
throws Exception {
super.channelRead(ctx, msg); ProxyFactory weaver = new ProxyFactory(wrapper);
NameMatchMethodPointcutAdvisor advisor = new NameMatchMethodPointcutAdvisor();
advisor.setMappedName(MessageEventWrapper.proxyMappedName);
advisor.setAdvice(new MessageEventAdvisor(wrapper, msg));
weaver.addAdvisor(advisor); //具体的如何处理管道中的数据,直接由producer、consumer、broker自行决定
MessageEventHandler proxyObject = (MessageEventHandler) weaver.getProxy();
proxyObject.handleMessage(ctx, msg);
} //管道链路失效,可能网络连接断开了,后续如果重连broker,可以在这里做文章
public void channelInactive(ChannelHandlerContext ctx) throws Exception {
super.channelInactive(ctx);
} public void setWrapper(MessageEventWrapper<T> wrapper) {
this.wrapper = wrapper;
}
}
整个AvatarMQ消息队列系统的运行情况,可以参考:Netty构建分布式消息队列(AvatarMQ)设计指南之架构篇,里面说的很详细了,本文就不具体演示了。
下图是VisualVM监控AvatarMQ中broker服务器的CPU使用率曲线。

可以发现,随着消息的堆积,broker进行消息投递、ACK应答的压力增大,CPU的使用率明细提高。现在具体看下broker的CPU使用率增高的原因是调用哪个热点方法呢?
从下图可以看出,热点方法是:SemaphoreCache的acquire。

这个是因为broker接收来自生产者消息的同时,会先把消息缓存起来,然后利用多线程机制进行消息的分派,这个时候会对信号量维护的许可集合进行获取操作,获取成功之后,才能进行任务的派发,主要防止临界区的共享资源竞争。这里的Semaphore是用来控制多线程访问共享资源(生产者过来的消息),类似操作系统中的PV原语,P原语相当于acquire(),V原语相当于release()。
写在最后
本文通过一个基于Netty构建分布式消息队列系统(AvatarMQ),简单地阐述了一个极简消息中间件的内部结构、以及如何利用Netty,构建生产者、消费者消息路由的通信模块。一切都是从零开始,开发、实现出精简版的消息中间件!本系列文章的主要灵感源自,自己业余时间,阅读到的一些消息队列原理阐述文章以及相关开源消息中间件的源代码,其中也结合了自己的一些理解和体会。由于自身技术水平、理解能力方面的限制,不能可能拥有大师一样高屋建瓴的视角,本文有说得不对、写的不好的地方,恳请广大同行批评指正。现在,文章写毕,算是对自己平时学习的一些经验总结,在这之前,对于消息中间件都是很简单的使用别人造好的轮子,没有更多的深入了解背后的技术细节,只是单纯的觉得别人写的很强大、很高效。其实有的时候提升自己能力,要更多的深究其背后的技术原理,举一反三,而不是简单的蜻蜓点水,一味地点到为止,长此以往、日复一日,自身的技术积累就很难有质的飞跃。
AvatarMQ一定还有许多不足、瓶颈甚至是bug,确实它不是一个完美的消息中间件,真因为如此,还需要不断地进行重构优化。后续本人还会持续更新、维护这个开源项目,希望有兴趣的朋友,共同关注!
文章略长,谢谢大家的观赏,如果觉得不错,还请多多推荐!
附上AvatarMQ项目开源网址:https://github.com/tang-jie/AvatarMQ
唐洁写于2016年9月7日 白露。
Netty构建分布式消息队列实现原理浅析的更多相关文章
- Netty构建分布式消息队列(AvatarMQ)设计指南之架构篇
目前业界流行的分布式消息队列系统(或者可以叫做消息中间件)种类繁多,比如,基于Erlang的RabbitMQ.基于Java的ActiveMQ/Apache Kafka.基于C/C++的ZeroMQ等等 ...
- 分布式服务(RPC)+分布式消息队列(MQ)面试题精选
分布式系统(distributed system)是建立在网络之上的软件系统.正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性.因此,网络和分布式系统之间的区别更多的在于高层软件(特别是 ...
- [.NET领域驱动设计实战系列]专题八:DDD案例:网上书店分布式消息队列和分布式缓存的实现
一.引言 在上一专题中,商家发货和用户确认收货功能引入了消息队列来实现的,引入消息队列的好处可以保证消息的顺序处理,并且具有良好的可扩展性.但是上一专题消息队列是基于内存中队列对象来实现,这样实现有一 ...
- 【转】快速理解Kafka分布式消息队列框架
from:http://blog.csdn.net/colorant/article/details/12081909 快速理解Kafka分布式消息队列框架 标签: kafkamessage que ...
- 深入浅出理解基于 Kafka 和 ZooKeeper 的分布式消息队列
消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题.实现高性能,高可用,可伸缩和最终一致性架构,是大型分布式系统不可缺少的中间件. 本场 Chat 主要内容: Kafk ...
- Kafka 和 ZooKeeper 的分布式消息队列分析
1. Kafka 总体架构 基于 Kafka-ZooKeeper 的分布式消息队列系统总体架构如下: 如上图所示,一个典型的 Kafka 体系架构包括若干 Producer(消息生产者),若干 bro ...
- 快速入门分布式消息队列之 RabbitMQ(2)
目录 目录 前文列表 RabbitMQ 的特性 Message Acknowledgment 消息应答 Prefetch Count 预取数 RPC 远程过程调用 vhost 虚拟主机 插件系统 最后 ...
- 分布式消息队列Apache Pulsar
Pulsar简介 Apache Pulsar是一个企业级的分布式消息系统,最初由Yahoo开发并在2016年开源,目前正在Apache基金会下孵化.Plusar已经在Yahoo的生产环境使用了三年多, ...
- 分布式消息队列RocketMQ(一)安装与启动
分布式消息队列RocketMQ 一.RocketMQ简介 RocketMQ(火箭MQ) 出自于阿里,后开源给apache成为apache的顶级开源项目之一,顶住了淘宝10年的 双11压力 是电商产品的 ...
随机推荐
- Socket聊天程序——初始设计
写在前面: 可能是临近期末了,各种课程设计接踵而来,最近在csdn上看到2个一样问答(问题A,问题B),那就是编写一个基于socket的聊天程序,正好最近刚用socket做了一些事,出于兴趣,自己抽了 ...
- OEL上使用yum install oracle-validated 简化主机配置工作
环境:OEL 5.7 + Oracle 10.2.0.5 RAC 如果你正在用OEL(Oracle Enterprise Linux)系统部署Oracle,那么可以使用yum安装oracle-vali ...
- .NET同步与异步之相关背景知识(六)
在之前的五篇随笔中,已经介绍了.NET 类库中实现并行的常见方式及其基本用法,当然.这些基本用法远远不能覆盖所有,也只能作为一个引子出现在这里.以下是前五篇随笔的目录: .NET 同步与异步之封装成T ...
- Windos环境用Nginx配置反向代理和负载均衡
Windos环境用Nginx配置反向代理和负载均衡 引言:在前后端分离架构下,难免会遇到跨域问题.目前的解决方案大致有JSONP,反向代理,CORS这三种方式.JSONP兼容性良好,最大的缺点是只支持 ...
- trigger事件模拟
事件模拟trigger 在操作DOM元素中,大多数事件都是用户必须操作才会触发事件,但有时,需要模拟用户的操作,来达到效果. 需求:页面初始化时触发搜索事件并获取input控件值,并打印输出(效果图如 ...
- CSS3新特性应用之结构与布局
一.自适应内部元素 利用width的新特性min-content实现 width新特性值介绍: fill-available,自动填充盒子模型中剩余的宽度,包含margin.padding.borde ...
- iOS 自定义方法 - 不完整边框
示例代码 ///////////////////////////OC.h////////////////////////// //// UIView+FreeBorder.h// BHBFreeB ...
- 跟着老男孩教育学Python开发【第二篇】:Python基本数据类型
运算符 设定:a=10,b=20 . 算数运算 2.比较运算 3.赋值运算 4.逻辑运算 5.成员运算 基本数据类型 1.数字 int(整型) 在32位机器上,整数的位数为32位,取值范围为-2**3 ...
- Intelli IDEA 设置项目编码(Mac)
Intelli IDEA->Editor->File Encodings
- javascript中的变量作用域以及变量提升
在javascript中, 理解变量的作用域以及变量提升是非常有必要的.这个看起来是否很简单,但其实并不是你想的那样,还要一些重要的细节你需要理解. 变量作用域 “一个变量的作用域表示这个变量存在的上 ...