python 之post、get与cookie实战
项目名称:登陆考勤管理系统爬取个人考勤信息并写入excel表格
编写目的:
公司经常要统计员工的考勤信息,而员工每次都要登陆考勤系统,再复制相关信息出来,贴到EXCEL,再转给统计人员,统计人员再挨个核对,麻烦无比,实在是看不下去了。我擦。。。。。
由于登陆的是内网的考勤系统,出了公司就登陆不了,所以本篇文章仅做参考,来体验一下cookie、post与get登陆使用。
先说用用到哪些知识吧:
1、tkinter Gui编程,写爬虫没有GUI怎么能行
2、cookie
3、post,get
其实不多是吧,简单。
要爬取一个网站,总得要矢爬的网站登陆地址,及登陆信息吧。分析一下看看。。。

好的,我们获取了如下信息:
登陆地址:LoginUrl = 'http://17.xx.xx.xx/j_acegi_security_check'
post提交:post_data = {'j_username':'your_username','j_password':'your_password'}
那就开工 ,写一下登陆代码吧
#!/usr/bin/env python
# _*_ coding:utf-8 _*_ import urllib
import urllib2
import cookielib LoginUrl = 'http://17.xx.xx.xx/j_acegi_security_check'
post_data = {'j_username':'your_username','j_password':'your_password'} # 定义一个类
class kaoqin_login(object):
def __init__(self):
self.cj = cookielib.CookieJar() # 初始化一个cookie补全,用于存储cookie
self.handler = urllib2.HTTPCookieProcessor(self.cj) # 创建一个cookie处理器
self.opener = urllib2.build_opener(self.handler) # 创建一个功能强大的opener def login(self,url,post): # post提交
post_data = urllib.urlencode(post) # 编码post数据为标准格式
req = urllib2.Request(url,post_data) # 做为data参数传给Request对象,此处也可以写成data=post_data
response = self.opener.open(req) # 登陆网站,获取返回结果
print response.url if __name__ == '__main__':
cls = kaoqin_login()
cls.login(LoginUrl,post_data) 返回信息如下:
http://17.xx.xx.xx/;jsessionid=7AC236C4B9C5E653208D59ECCE55E8EF
好,登陆成功了,之后怎么办呢?嗯,对了,找一下考勤页面在哪里,分析一下吧
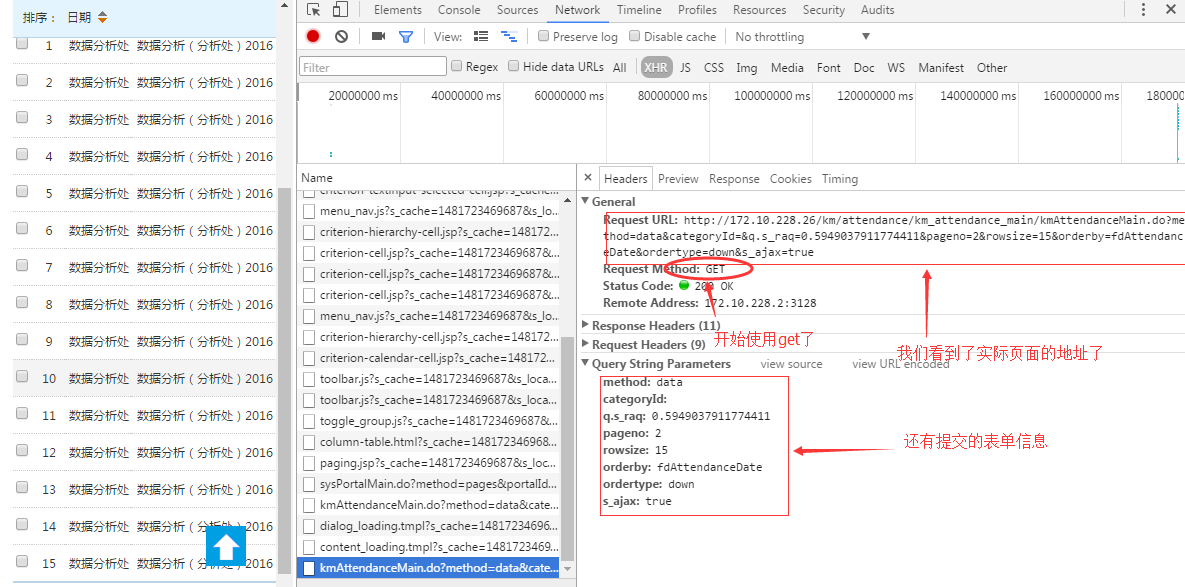
瞧,真实页面的信息就这些了。自己把url和post信息整理出来吧,注意,提交表单信息要写成字典,url呢,问号之前的都是了。
示例代码
#!/usr/bin/env python
# _*_ coding:utf-8 _*_ import urllib
import urllib2
import cookielib
import json LoginUrl = 'http://17.xx.xx.xx/j_acegi_security_check'
post_data = {'j_username':'your_username','j_password':'your_password'} # 定义一个类
class kaoqin_login(object):
def __init__(self):
self.cj = cookielib.CookieJar() # 初始化一个cookie补全,用于存储cookie
self.handler = urllib2.HTTPCookieProcessor(self.cj) # 创建一个cookie处理器
self.opener = urllib2.build_opener(self.handler) # 创建一个功能强大的opener def login(self,url,post): # post提交
post_data = urllib.urlencode(post) # 编码post数据为标准html格式
req = urllib2.Request(url,post_data) # 做为data参数传给Request对象,由request做post数据隐式提交,此处也可以写成data=post_data
response = self.opener.open(req) # 登陆网站,获取返回结果
print response.url def get_response(self,url,post): # get方式提交数据
get = urllib.urlencode(post) # 将提交的数据编码成html标准格式
response = self.opener.open(url,get) # 将标准的编码数据放到url后面,变成真正的url地址
try:
JsData = json.loads(response.read())
return JsData['datas']
except Exception as e:
return False if __name__ == '__main__':
cls = kaoqin_login()
cls.login(LoginUrl,post_data)
Login = 'http://17.xx.xx.xx/km/attendance/km_attendance_main/kmAttendanceMain.do'
data ={
'method':'data'
,'categoryId':''
,'q.s_raq':0.5949037911774411
,'pageno':2
,'rowsize':15
,'orderby':'fdAttendanceDate'
,'ordertype':'down'
,'s_ajax':'true'
}
jsdata = cls.get_response(Login,data)
print jsdata
好了,数据取到了,发一下全部的代码吧.
上面的代码是我重点想说的,下面的代码就不是那么重要了,关于excel的读取,博客里有详细的解释,GUI开发也有相关文档。
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import urllib
import urllib2
import cookielib
import json,re,time '''
因为脚本只取了前4页数据,所以最好用来爬取本月的考勤信息
如需爬取其它月的信息,需要更改代码
for i in range(1,5) 将5改为更大,最大15 ''' # ==============框口区==================
from Tkinter import *
from ScrolledText import ScrolledText
import tkFileDialog
root = Tk()
root.iconbitmap('../data/spider_128px_1169260_easyicon.net.ico')
root.title('邮储个人考勤记录爬虫')
# 第一行
Label(root,text='考勤日期',fg='#8F8C8F').grid(row=0,column=0)
var_date1 = StringVar()
var_date1.set('2016-01-01')
var_date2 = StringVar()
var_date2.set('2016-01-31')
date1 = Entry(root,fg='red',bg='#FFFACD',textvariable=var_date1)
date1.grid(row=0,column=1)
Label(root,text='至',fg='#8F8C8F').grid(row=0,column=2)
date2 =Entry(root,fg='red',bg='#FFFACD',textvariable=var_date2)
date2.grid(row=0,column=3)
# 第二行
Label(root,text='用户密码文件',fg='#8F8C8F').grid(row=1,column=0)
var = StringVar()
def get_file():
filename = tkFileDialog.askopenfilename(initialdir='c:')
var.set(filename)
def get_file_des():
filename = tkFileDialog.askopenfilename(initialdir='c:')
ent_des.set(filename)
var.set(r'C:\spider_dev\data\kaoqin_user_pwd.txt')
Ent = Entry(root,textvariable=var).grid(row=1,column=1)
Button(root,text='选择文件',command=get_file,fg='#006400').grid(row=1,column=2)
ent_des = StringVar()
timpsta = '%d'%(time.time()*1000)
ent_des.set(r'C:\spider_dev\data\kaoqin_%s.xls'%str(timpsta))
Ent_d = Entry(root,textvariable=ent_des).grid(row=2,column=1,sticky=N)
Button(root,text='目标文件',command=get_file_des,fg='#006400').grid(row=2,column=2,sticky=N) T_logi_info = ScrolledText(root,width=20)
T_logi_info.grid(row=2,column=0) # 标签
v_lable = StringVar()
v_lable.set('错误记录...')
Label(root,textvariable=v_lable,fg='red').grid(row=3,column=0)
# 信息框
text = ScrolledText(root,bg='#87CEFA')
text.grid(row=0,column=4,rowspan=3) # ==============框口区================== # --------------爬虫区-----------------
class kaoqin_login(object):
def __init__(self):
self.cj = cookielib.CookieJar()
self.handler = urllib2.HTTPCookieProcessor(self.cj)
self.opener = urllib2.build_opener(self.handler) def login(self,url,post):
post_data = urllib.urlencode(post)
req = urllib2.Request(url,post_data)
response = self.opener.open(req)
if response.code == 200:
return True
else:
return False def get_response(self,url,post):
get = urllib.urlencode(post)
response = self.opener.open(url,get)
try:
JsData = json.loads(response.read())
return JsData['datas']
except Exception as e:
return False def post_page(self,pages):
get={
'method':'data'
,'categoryId':''
,'q.s_raq':0.9518796035349586
,'pageno':pages
,'rowsize':15
,'orderby':'fdAttendanceDate'
,'ordertype':'down'
,'s_ajax':'true'
}
return get def get_data_file(self,filename):
with open(filename,'rb') as f:
data = f.read().split('\r\n')
return data # --------------爬虫区----------------- # <------------Excel文件数据写入-------->
from openpyxl.workbook import Workbook
from openpyxl.writer.excel import ExcelWriter
from openpyxl.cell import get_column_letter wb = Workbook()
ew = ExcelWriter(workbook=wb)
ws = wb.worksheets[0]
ws.title = u'第一个sheet' # 数据开始写入的行、列、无组数据及文件名
def write_2_excel(r,c,t_data,FileName):
i = r
for record in t_data:
for x in range(c,len(record)+c):
col = get_column_letter(x)
ws.cell('%s%s'%(col,i)).value ='%s'%record[x-c]
i+=1
ew.save(filename=FileName)
# <------------Excel文件数据写入--------> # ************主函数*****************
if __name__ == '__main__':
def Spider():
#初始化实例
cls = kaoqin_login()
if var.get():
List_username = cls.get_data_file(var.get())
else:
v_lable.set('密码文件对吗???')
#出勤状态,如正常、迟到
Real_Data = []
#按用户获取数据
for each_user in List_username:
#标题数据,比如excel的头部,日期,星期、上下午
Title_Data = []
#网站登陆用户信息
Pno,Pname,username,password = each_user.split(',')[0],each_user.split(',')[1],each_user.split(',')[2],each_user.split(',')[3]
LoginUrl = 'http://17.xx.xx.xx/j_acegi_security_check'
LoginPost ="{'j_username':'%s','j_password':'%s'}"%(username,password)
LoginPost = eval(LoginPost)
if cls.login(LoginUrl,LoginPost):
#进入考勤页面
Kq_Url = 'http://17.xx.xx.xx/km/attendance/km_attendance_main/kmAttendanceMain.do'
tmp1=[]
tmp2=[]
tmp3=[]
tmp4=[]
tmp4.append(Pno)
tmp4.append(Pname)
#考勤post列表,第一页到第四页数据
for i in range(1,5):
jsret = cls.get_response(Kq_Url,cls.post_page(i))
if jsret:
pass
else:
T_logi_info.insert(END,Pname+'登陆失败'+ '\n')
T_logi_info.see(END)
break
#对考勤数据处理
for each_day in jsret:
v_date=v_week=v_Bc=v_status=v_name=''
start_date = var_date1.get()
end_date = var_date2.get()
if start_date and end_date:
for item_dic in each_day:
col = item_dic['col']
if col == 'fdAttendanceDate':
v_date = item_dic['value'].strip()
if col == 'fdWeek':
v_week = item_dic['value'].strip()
if col == 'fdBc':
v_Bc = item_dic['value'].strip()
if col == 'fdStatus':
v_status = item_dic['value'].strip()
v_status = re.search('>(.*?)<',v_status).group(1)
if col == 'fdPerson.fdName':
v_name = item_dic['value'] if v_date >= start_date and v_date <= end_date:
tmp1.append(v_date)
tmp2.append(v_week)
tmp3.append(v_Bc)
tmp4.append(v_status)
text.insert(END, v_name +',' + v_date+','+v_week+','+v_Bc+','+v_status+'\n')
text.see(END)
text.update()
else:
v_lable.set('时间不对吧...')
pass
Title_Data.append(tmp1)
Title_Data.append(tmp2)
Title_Data.append(tmp3)
Real_Data.append(tmp4)
write_2_excel(1,3,Title_Data,ent_des.get())
write_2_excel(4,1,Real_Data,ent_des.get()) #第三行
Button(root,text='开始爬取',fg='#3CB371',command=Spider).grid(row=3,column=4)
root.mainloop()
好了,看看一下实际效果吧


python 之post、get与cookie实战的更多相关文章
- python爬虫 - Urllib库及cookie的使用
http://blog.csdn.net/pipisorry/article/details/47905781 lz提示一点,python3中urllib包括了py2中的urllib+urllib2. ...
- 国内第一本micropython的书出版《机器人Python极客编程入门与实战》
第一本micropython的书<机器人Python极客编程入门与实战>. 购买地址:https://item.taobao.com/item.htm?spm=2013.1.w4018-1 ...
- python操作三大主流数据库(14)python操作redis之新闻项目实战②新闻数据的展示及修改、删除操作
python操作三大主流数据库(14)python操作redis之新闻项目实战②新闻数据的展示及修改.删除操作 项目目录: ├── flask_redis_news.py ├── forms.py ├ ...
- Python爬虫入门六之Cookie的使用
大家好哈,上一节我们研究了一下爬虫的异常处理问题,那么接下来我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在 ...
- Python Flask搭建一个视频网站实战视频教程
点击了解更多Python课程>>> Python Flask搭建一个视频网站实战视频教程 第1章 课程介绍 第2章 预备开发环境 第3章 项目分析.建立目录及模型规划 第4章 建立前 ...
- Python分布式爬虫开发搜索引擎 Scrapy实战视频教程
点击了解更多Python课程>>> Python分布式爬虫开发搜索引擎 Scrapy实战视频教程 课程目录 |--第01集 教程推介 98.23MB |--第02集 windows下 ...
- Python数据抓取技术与实战 pdf
Python数据抓取技术与实战 目录 D11章Python基础1.1Python安装1.2安装pip1.3如何查看帮助1.4D1一个实例1.5文件操作1.6循环1.7异常1.8元组1.9列表1.10字 ...
- python学习(25) BeautifulSoup介绍和实战
BeautifulSoup是python的html解析库,处理html非常方便 BeautifulSoup 安装 pip install beautifulsoup4 BeautifulSoup 配合 ...
- Python Flask打造一个视频网站实战视频教程
下载链接:https://www.yinxiangit.com/607.html 目录: 本套课程从零基础讲解flask开发网站.涉及到的知识点包括:Python和pycharm的安装.urls和视图 ...
随机推荐
- iOS开发 Apple Pay
一.什么是Apple Pay? 1. 概念 Apple Pay,简单来说, 就是一种移动支付方式.通过Touch ID/ Passcode,用户可使用存储在iPhone 6, 6p等设备上的信用卡和借 ...
- 0505 Scrum 项目1.0
应用NABCD模型,分析你们初步选定的项目,充分说明你们选题的理由. 录制为演说视频,上传到视频网站,并把链接发到团队博客上. 团队项目选题 一个售书网站(O2O) NABCD 模型 1) N (N ...
- PHP判断变量是否为整型
1.使用is_int() 2.使用is_numeric() 两个函数的区别,当变量为'1'时, is_int()的返回值为false, is_numeric()的返回值为true 当变量为1时, 两个 ...
- [转]深入理解Java 8 Lambda(类库篇——Streams API,Collectors和并行)
以下内容转自: 作者:Lucida 微博:@peng_gong 豆瓣:@figure9 原文链接:http://zh.lucida.me/blog/java-8-lambdas-insideout-l ...
- Question and Answer
1.VS2013使用EntityFrame问题解决办法 解决办法参照博客http://pinter.org/?p=2374 使用到EntityFrame的项目配置文件修改如下: 项目中凡是使用到DbC ...
- iOS开发网络篇—使用ASI框架进行文件下载
iOS开发网络篇—使用ASI框架进行文件下载 说明:本文介绍iOS网络编程中经常用到的框架ASI,如何使用该框架进行文件的下载. 一.简单介绍 代码示例: #import "YYViewCo ...
- 爱默生UPS并机系统:进入与退出操作方法
UPS并机系统的进入与退出: 进入:.合UPS的出线及进线开关:开启第一台UPS,等待整流指示灯常亮.然后Invert On,正常开机,此时UPS进入逆变状态 .合另外一台UPS的出线及进线开关,等待 ...
- Discuz升级提示static/image/postbg/3.jpg下载出现问题的解决办法
discuz2.5升级3.0的时候出现错误.提示static/image/postbg/3.jpg下载出现问题,其解决办法如下 找到 source/admincp/admincp_upgrade.ph ...
- error: C++ preprocessor "/lib/cpp" fails sanity check
在安装protobuf,知悉./Configure时候报错“error: C++ preprocessor "/lib/cpp" fails sanity check” 下面是转载 ...
- Scala深入浅出实战经典---001-Scala开发环境搭建和HelloWorld解析
001-Scala开发环境搭建和HelloWorld解析 Scala 函数式编程和面向对象结合的语言 函数式编程擅长数值计算 面向对象擅长大型工程和项目的组织以及团队的分工协作 Scala会是下一个伟 ...