自己写的数据交换工具——从Oracle到Elasticsearch
先说说需求的背景,由于业务数据都在Oracle数据库中,想要对它进行数据的分析会非常非常慢,用传统的数据仓库-->数据集市这种方式,集市层表会非常大,查询的时候如果再做一些group的操作,一个访问需要一分钟甚至更久才能响应。
为了解决这个问题,就想把业务库的数据迁移到Elasticsearch中,然后针对es再去做聚合查询。
问题来了,数据库中的数据量很大,如何导入到ES中呢?
Logstash JDBC
Logstash提供了一款JDBC的插件,可以在里面写sql语句,自动查询然后导入到ES中。这种方式比较简单,需要注意的就是需要用户自己下载jdbc的驱动jar包。
input {
jdbc {
jdbc_driver_library => "ojdbc14-10.2.0.3.0.jar"
jdbc_driver_class => "Java::oracle.jdbc.driver.OracleDriver"
jdbc_connection_string => "jdbc:oracle:thin:@localhost:1521:test"
jdbc_user => "test"
jdbc_password => "test123"
schedule => "* * * * *"
statement => "select * from TARGET_TABLE"
add_field => ["type","a"]
}
}
output{
elasticsearch {
hosts =>["10.10.1.205:9200"]
index => "product"
document_type => "%{type}"
}
}
不过,它的性能实在是太差了!我导了一天,才导了两百多万的数据。
因此,就考虑自己来导。
自己的数据交换工具
思路:
- 1 采用JDBC的方式,通过分页读取数据库的全部数据。
- 2 数据库读取的数据存储成bulk形式的数据,关于bulk需要的文件格式,可以参考这里
- 3 利用bulk命令分批导入到es中
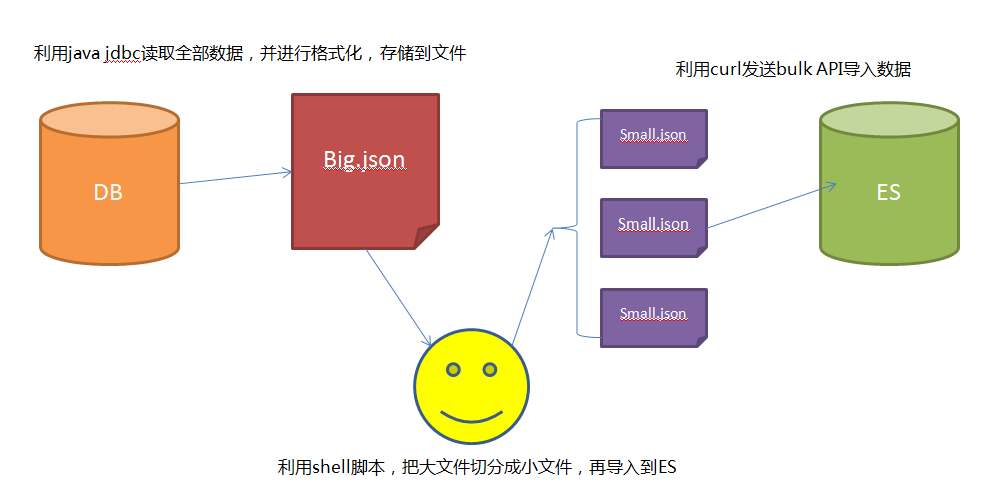
最后使用发现,自己写的导入程序,比Logstash jdbc快5-6倍~~~~~~ 嗨皮!!!!
遇到的问题
- 1 JDBC需要采用分页的方式读取全量数据
- 2 要模仿bulk文件进行存储
- 3 由于bulk文件过大,导致curl内存溢出
程序开源
下面的代码需要注意的就是
public class JDBCUtil {
private static Connection conn = null;
private static PreparedStatement sta=null;
static{
try {
Class.forName("oracle.jdbc.driver.OracleDriver");
conn = DriverManager.getConnection("jdbc:oracle:thin:@localhost:1521:test", "test", "test123");
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
System.out.println("Database connection established");
}
/**
* 把查到的数据格式化写入到文件
*
* @param list 需要存储的数据
* @param index 索引的名称
* @param type 类型的名称
* @param path 文件存储的路径
**/
public static void writeTable(List<Map> list,String index,String type,String path) throws SQLException, IOException {
System.out.println("开始写文件");
File file = new File(path);
int count = 0;
int size = list.size();
for(Map map : list){
FileUtils.write(file, "{ \"index\" : { \"_index\" : \""+index+"\", \"_type\" : \""+type+"\" } }\n","UTF-8",true);
FileUtils.write(file, JSON.toJSONString(map)+"\n","UTF-8",true);
// System.out.println("写入了" + ((count++)+1) + "[" + size + "]");
}
System.out.println("写入完成");
}
/**
* 读取数据
* @param sql
* @return
* @throws SQLException
*/
public static List<Map> readTable(String tablename,int start,int end) throws SQLException {
System.out.println("开始读数据库");
//执行查询
sta = conn.prepareStatement("select * from(select rownum as rn,t.* from "+tablename+" t )where rn >="+start+" and rn <"+end);
ResultSet rs = sta.executeQuery();
//获取数据列表
List<Map> data = new ArrayList();
List<String> columnLabels = getColumnLabels(rs);
Map<String, Object> map = null;
while(rs.next()){
map = new HashMap<String, Object>();
for (String columnLabel : columnLabels) {
Object value = rs.getObject(columnLabel);
map.put(columnLabel.toLowerCase(), value);
}
data.add(map);
}
sta.close();
System.out.println("数据读取完毕");
return data;
}
/**
* 获得列名
* @param resultSet
* @return
* @throws SQLException
*/
private static List<String> getColumnLabels(ResultSet resultSet)
throws SQLException {
List<String> labels = new ArrayList<String>();
ResultSetMetaData rsmd = (ResultSetMetaData) resultSet.getMetaData();
for (int i = 0; i < rsmd.getColumnCount(); i++) {
labels.add(rsmd.getColumnLabel(i + 1));
}
return labels;
}
/**
* 获得数据库表的总数,方便进行分页
*
* @param tablename 表名
*/
public static int count(String tablename) throws SQLException {
int count = 0;
Statement stmt = conn.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE, ResultSet.CONCUR_UPDATABLE);
ResultSet rs = stmt.executeQuery("select count(1) from "+tablename);
while (rs.next()) {
count = rs.getInt(1);
}
System.out.println("Total Size = " + count);
rs.close();
stmt.close();
return count;
}
/**
* 执行查询,并持久化文件
*
* @param tablename 导出的表明
* @param page 分页的大小
* @param path 文件的路径
* @param index 索引的名称
* @param type 类型的名称
* @return
* @throws SQLException
*/
public static void readDataByPage(String tablename,int page,String path,String index,String type) throws SQLException, IOException {
int count = count(tablename);
int i =0;
for(i =0;i<count;){
List<Map> map = JDBCUtil.readTable(tablename,i,i+page);
JDBCUtil.writeTable(map,index,type,path);
i+=page;
}
}
}
在main方法中传入必要的参数即可:
public class Main {
public static void main(String[] args) {
try {
JDBCUtil.readDataByPage("TABLE_NAME",1000,"D://data.json","index","type");
} catch (SQLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
这样得到bulk的数据后,就可以运行脚本分批导入了。
下面脚本的思路,就是每100000行左右的数据导入到一个目标文件,使用bulk命令导入到es中。注意一个细节就是不能随意的切分文件,因为bulk的文件是两行为一条数据的。
#!/bin/bash
count=0
rm target.json
touch target.json
while read line;do
((count++))
{
echo $line >> target.json
if [ $count -gt 100000 ] && [ $((count%2)) -eq 0 ];then
count=0
curl -XPOST localhost:9200/_bulk --data-binary @target.json > /dev/null
rm target.json
touch target.json
fi
}
done < $1
echo 'last submit'
curl -XPOST localhost:9200/_bulk --data-binary @target.json > /dev/null
最后执行脚本:
sh auto_bulk.sh data.json
自己测试最后要比logstasj jdbc快5-6倍。
自己写的数据交换工具——从Oracle到Elasticsearch的更多相关文章
- 从Oracle到Elasticsearch
自己写的数据交换工具——从Oracle到Elasticsearch 自己写的数据交换工具——从Oracle到Elasticsearch 先说说需求的背景,由于业务数据都在Oracle数据库中,想要 ...
- 数据交换工具Kettle
网上搜集了一些关于开源数据交换工具Kattle的文章,特收藏例如以下: 文章一:ETL和Kettle简单介绍 ETL即数据抽取(Extract).转换(Transform).装载(Load)的过程.它 ...
- 数据导入导出Oracle数据库
临近春节,接到了一个导入数据的任务,在Linux客户端中的数据有50G,大约3亿3千万行: 刚开始很天真,把原始的txt/csv文件用sh脚本转化成了oralce 的insert into 语句,然后 ...
- Oracle和Elasticsearch数据同步
Python编写Oracle和Elasticsearch数据同步脚本 标签: elasticsearchoraclecx_Oraclepython数据同步 Python知识库 一.版本 Pyth ...
- Java代码实现excel数据导入到Oracle
1.首先需要两个jar包jxl.jar,ojdbc.jar(注意版本,版本不合适会报版本错误)2.代码: Java代码 import java.io.File; import java.io.Fi ...
- SQL SERVER 2000/2005/2008数据库数据迁移到Oracle 10G细述
最近参与的一个系统涉及到把SQL Server 2k的数据迁移到Oracle 10G这一非功能需求.特将涉及到相关步骤列举如下供大家参考: 环境及现有资源: 1.OS: Windows 7 Enter ...
- Netty中如何写大型数据
因为网络饱和的可能性,如何在异步框架中高效地写大块的数据是一个特殊的问题.由于写操作是非阻塞的,所以即使没有写出所有的数据,写操作也会在完成时返回并通知ChannelFuture.当这种情况发生时,如 ...
- excel文件与txt文件互转,并且把excel里的数据导入到oracle中
一.excel文件转换成txt文件的步骤 a.首先要把excel文件转换成txt文件 1.Excel另存为中已经包含了TXT格式,所以我们可以直接将Excel表格另存为TXT格式,但是最后的效果好像不 ...
- 通过hive向写elasticsearch的写如数据
通过hive向写elasticsearch的写如数据 hive 和 elasticsearch 的整合可以参考官方的文档: ES-hadoop的hive整合 : https://www.elastic ...
随机推荐
- 菜鸟Python学习笔记第一天:关于一些函数库的使用
2017年1月3日 星期二 大一学习一门新的计算机语言真的很难,有时候连函数拼写出错查错都能查半天,没办法,谁让我英语太渣. 关于计算机语言的学习我想还是从C语言学习开始为好,Python有很多语言的 ...
- “.Net 社区虚拟大会”(dotnetConf) 2016 Day 1 Keynote: Scott Hunter
“.Net 社区虚拟大会”(dotnetConf) 2016 今天凌晨在Channel9 上召开,在Scott Hunter的30分钟的 Keynote上没有特别的亮点,所讲内容都是 微软“.Net社 ...
- nodejs之get/post请求的几种方式
最近一段时间在学习前端向服务器发送数据和请求数据,下面总结了一下向服务器发送请求用get和post的几种不同请求方式: 1.用form表单的方法:(1)get方法 前端代码: <form act ...
- Kooboo CMS技术文档之二:Kooboo CMS的安装步骤
在IIS上安装Kooboo CMS Kooboo CMS安装之后 安装的常见问题 1. 在IIS上安装Kooboo CMS Kooboo CMS部署到正式环境相当简单,安装过程是一个普通MVC站点在I ...
- AFNetworking 3.0 源码解读(十)之 UIActivityIndicatorView/UIRefreshControl/UIImageView + AFNetworking
我们应该看到过很多类似这样的例子:某个控件拥有加载网络图片的能力.但这究竟是怎么做到的呢?看完这篇文章就明白了. 前言 这篇我们会介绍 AFNetworking 中的3个UIKit中的分类.UIAct ...
- .NET CoreCLR开发人员指南(上)
1.为什么每一个CLR开发人员都需要读这篇文章 和所有的其他的大型代码库相比,CLR代码库有很多而且比较成熟的代码调试工具去检测BUG.对于程序员来说,理解这些规则和习惯写法非常的重要. 这篇文章让所 ...
- Javascript中的valueOf与toString
基本上,javascript中所有数据类型都拥有valueOf和toString这两个方法,null除外.它们俩解决javascript值运算与显示的问题,本文将详细介绍,有需要的朋友可以参考下. t ...
- Kotlin类:功能更强、而更简洁(KAD 03)
作者:Antonio Leiva 时间:Dec 7, 2016 原文链接:http://antonioleiva.com/classes-kotlin/ Kotlin类尽可能简单,这样用较少的代码完成 ...
- iOS开源项目周报1222
由OpenDigg 出品的iOS开源项目周报第二期来啦.我们的iOS开源周报集合了OpenDigg一周来新收录的优质的iOS开发方面的开源项目,方便iOS开发人员便捷的找到自己需要的项目工具等. io ...
- ios 获取或修改网页上的内容
UIWebView是iOS最常用的SDK之一,它有一个stringByEvaluatingJavaScriptFromString方法可以将javascript嵌 入页面中,通过这个方法我们可 ...