新型大语言模型的预训练与后训练范式,苹果的AFM基础语言模型

前言:大型语言模型(LLMs)的发展历程可以说是非常长,从早期的GPT模型一路走到了今天这些复杂的、公开权重的大型语言模型。最初,LLM的训练过程只关注预训练,但后来逐步扩展到了包括预训练和后训练在内的完整流程。后训练通常涵盖监督指导微调和对齐过程,而这些在ChatGPT的推广下变得广为人知。
自ChatGPT首次发布以来,训练方法学也在不断进化。在这几期的文章中,我将回顾近1年中在预训练和后训练方法学上的最新进展。
关于LLM开发与训练流程的概览,特别关注本文中讨论的新型预训练与后训练方法
每个月都有数百篇关于LLM的新论文提出各种新技术和新方法。然而,要真正了解哪些方法在实践中效果更好,一个非常有效的方式就是看看最近最先进模型的预训练和后训练流程。幸运的是,在近1年中,已经有四个重要的新型LLM发布,并且都附带了相对详细的技术报告。
• 在本文中,我将重点介绍以下模型中的**苹果的 AFM智能基础语言模型 **预训练和后训练流程:
• 阿里巴巴的 Qwen 2
• 苹果的 智能基础语言模型
• 谷歌的 Gemma 2
• Meta AI 的 Llama 3.1
我会完整的介绍列表中的全部模型,但介绍顺序是基于它们各自的技术论文在arXiv.org上的发表日期,这也巧合地与它们的字母顺序一致。
- 苹果的苹果智能基础语言模型(AFM)
我很高兴在arXiv.org上看到苹果公司发布的另一篇技术论文,这篇论文概述了他们的模型训练。这是一个意想不到但绝对是积极的惊喜!
2.1 AFM 概述
在《苹果智能基础语言模型》论文中,研究团队阐述了为“苹果智能”环境在苹果设备上使用而设计的两个主要模型的开发过程。为了简洁,本节将这些模型简称为AFM,即“苹果基础模型”。
具体来说,论文描述了两个版本的AFM:一个是30亿参数的设备上模型,用于在手机、平板或笔记本电脑上部署,另一个是更高能力的服务器模型,具体大小未指明。
这些模型是为聊天、数学和编程任务开发的,尽管论文并未讨论任何编程特定的训练和能力。
与Qwen 2一样,AFM是密集型的LLM,不使用混合专家方法。
2.2 AFM 预训练
我想向研究人员表示两大致敬。首先,他们不仅使用了公开可用的数据和出版商授权的数据,而且还尊重了网站上的robots.txt文件,避免爬取这些网站。其次,他们还提到进行了使用基准数据的去污染处理。
为了加强Qwen 2论文的一个结论,研究人员提到质量比数量更重要。(设备模型的词汇大小为49k词汇,服务器模型为100k词汇,这些词汇大小明显小于使用了150k词汇的Qwen 2模型。)
有趣的是,预训练不是进行了两个阶段,而是三个阶段!
1.核心(常规)预训练
2.持续预训练,其中网络爬取(较低质量)数据被降权;数学和代码被增权
3.通过更长的序列数据和合成数据增加上下文长度

AFM模型经历的三步预训练过程概述。
让我们更详细地看看这三个步骤。
**2.2.1 预训练I:核心预训练 **
核心预训练描述了苹果预训练流程中的第一阶段。这类似于常规预训练,AFM服务器模型在6.3万亿个标记上进行训练,批量大小为4096,序列长度为4096个标记。这与在7万亿标记上训练的Qwen 2模型非常相似。
然而,对于AFM设备上的模型更为有趣,它是从更大的64亿参数模型(从头开始训练,如上一段所描述的AFM服务器模型)中提炼和修剪得到的。
除了“使用蒸馏损失,通过将目标标签替换为真实标签和教师模型的top-1预测的凸组合(教师标签分配0.9的权重)”之外,关于蒸馏过程的细节不多。我觉得知识蒸馏对于LLM预训练越来越普遍且有用(Gemma-2也使用了)。我计划有一天更详细地介绍它。现在,这里是一个高层次上如何工作的简要概述。

知识蒸馏的概述,其中一个小型模型(此处为AFM设备3B模型)在原始训练标记上训练,外加来自一个更大的教师模型(此处为6.4B模型)的输出。注意,a)中的交叉熵损失是用于预训练LLM的常规训练损失(有关如何实现常规预训练步骤的更多细节,请参阅我的《从零开始构建大型语言模型》一书第5章)。
如上所示,知识蒸馏仍然涉及在原始数据集上训练。然而,除了数据集中的训练标记之外,被训练的模型(称为学生)还从更大的(教师)模型接收信息,这比没有知识蒸馏的训练提供了更丰富的信号。缺点是你必须:1)首先训练更大的教师模型,2)使用更大的教师模型计算所有训练标记的预测。这些预测可以提前计算(需要大量存储空间)或在训练期间计算(可能会减慢训练过程)。
2.2.2 预训练II:持续预训练
持续预训练阶段包括了一个从4096个标记到8192个标记的小幅上下文延长步骤,使用的数据集包含1万亿个标记(核心预训练集是其五倍大)。然而,主要关注点是使用高质量数据混合进行训练,特别强调数学和编码。
有趣的是,研究人员发现在这种情况下蒸馏损失并无益处。
2.2.3 预训练III:
上下文延长 第三阶段预训练只涉及1000亿个标记(第二阶段使用的标记的10%),但代表了更显著的上下文延长到32768个标记。为了实现这一点,研究人员用合成的长上下文问答数据增强了数据集。
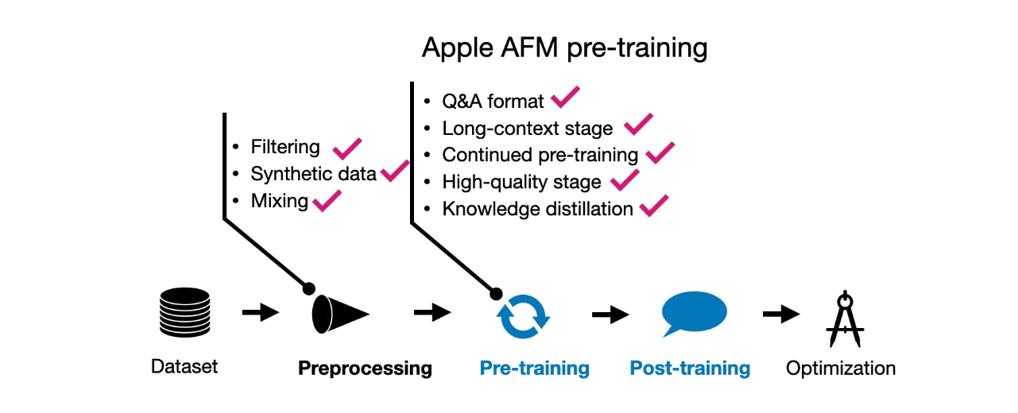
AFM预训练技术概述。
**2.3 AFM后训练 **
苹果公司在后训练过程中似乎采取了与预训练相似的全面方法。他们利用了人工标注数据和合成数据,强调优先考虑数据质量而非数量。有趣的是,他们没有依赖预设的数据比例;相反,他们通过多次实验精调数据混合,以达到最佳平衡。
后训练阶段包括两个步骤:监督指令微调,随后进行数轮带有人类反馈的强化学习(RLHF)。
这个过程中一个特别值得注意的方面是苹果引入了两种新算法用于RLHF阶段:
带教师委员会的拒绝采样微调(iTeC)
带镜像下降策略优化的RLHF
鉴于文章的长度,我不会深入这些方法的技术细节,但这里有一个简要概述:
iTeC算法结合了拒绝采样和多种偏好调整技术——具体来说,是SFT、DPO、IPO和在线RL。苹果没有依赖单一算法,而是使用每种方法独立训练模型。这些模型然后生成响应,由人类评估并提供偏好标签。这些偏好数据被用来在RLHF框架中迭代训练一个奖励模型。在拒绝采样阶段,一个模型委员会生成多个响应,奖励模型选择最佳的一个。
这种基于委员会的方法相当复杂,但应该相对可行,特别是考虑到涉及的模型相对较小(大约30亿参数)。在像Llama 3.1中的70B或405B参数模型上实现这样的委员会,无疑会更具挑战性。
至于第二种算法,带镜像下降的RLHF,之所以选择它是因为它比通常使用的PPO(邻近策略优化)更有效。

AFM后训练技术总结。
**2.4 结论 **
苹果在预训练和后训练的方法相对全面,这可能是因为赌注很高(该模型部署在数百万甚至数十亿的设备上)。然而,考虑到这些模型的小型性质,广泛的技术也变得可行,因为一个30亿参数的模型不到最小的Llama 3.1模型大小的一半。
其中一个亮点是,他们的选择不仅仅是在RLHF和DPO之间;相反,他们使用了多种偏好调整算法形成一个委员会。
同样有趣的是,他们在预训练中明确使用了问答数据——这是我在之前文章中讨论的《指令预训练LLM》。
总之,这是一份令人耳目一新且令人愉快的技术报告。
新型大语言模型的预训练与后训练范式,苹果的AFM基础语言模型的更多相关文章
- css预处理器和后处理器
因为我是前端刚入门,昨天看了一个大神写的的初级前端需要掌握的知识,然后我就开始一一搜索,下面是我对css预处理器和后处理器的搜索结果,一是和大家分享下这方面的知识,另一方面方便自己以后翻阅.所以感兴趣 ...
- 产品在焊接时出现异常,尤其是尺寸较大的QFP芯片,焊接后出现虚焊、冷焊、假焊等问题?
1 不良描述 客户采用我们提供的SMT设备后,部分产品在焊接时出现异常,尤其是尺寸较大的QFP芯片,焊接后出现虚焊.冷焊.假焊等不良.应客户要求对这一批不良产品以及生产条件进行分析,以便找到改善的依据 ...
- NLP问题特征表达基础 - 语言模型(Language Model)发展演化历程讨论
1. NLP问题简介 0x1:NLP问题都包括哪些内涵 人们对真实世界的感知被成为感知世界,而人们用语言表达出自己的感知视为文本数据.那么反过来,NLP,或者更精确地表达为文本挖掘,则是从文本数据出发 ...
- SVM训练结果参数说明 训练参数说明 归一化加快速度和提升准确率 归一化还原
原文:http://blog.sina.com.cn/s/blog_57a1cae80101bit5.html 举例说明 svmtrain -s 0 -?c 1000 -t 1 -g 1 -r 1 - ...
- 如何解决 Iterative 半监督训练 在 ASR 训练中难以落地的问题丨RTC Dev Meetup
前言 「语音处理」是实时互动领域中非常重要的一个场景,在声网发起的「RTC Dev Meetup丨语音处理在实时互动领域的技术实践和应用」活动中,来自微软亚洲研究院.声网.数美科技的技术专家,围绕该话 ...
- LLaMA:开放和高效的基础语言模型
LLaMA:开放和高效的基础语言模型 论文:https://arxiv.org/pdf/2302.13971.pdf 代码:https://github.com/facebookresearch/ll ...
- 训练指南 UVA - 10917(最短路Dijkstra + 基础DP)
layout: post title: 训练指南 UVA - 10917(最短路Dijkstra + 基础DP) author: "luowentaoaa" catalog: tr ...
- 迁移学习算法之TrAdaBoost ——本质上是在用不同分布的训练数据,训练出一个分类器
迁移学习算法之TrAdaBoost from: https://blog.csdn.net/Augster/article/details/53039489 TradaBoost算法由来已久,具体算法 ...
- Expo大作战(十九)--expo打包后,发布分用程序到商店的注意事项
简要:本系列文章讲会对expo进行全面的介绍,本人从2017年6月份接触expo以来,对expo的研究断断续续,一路走来将近10个月,废话不多说,接下来你看到内容,讲全部来与官网 我猜去全部机翻+个人 ...
- 【服务总线 Azure Service Bus】Service Bus在使用预提取(prefetching)后出现Microsoft.Azure.ServiceBus.MessageLockLostException异常问题
问题描述 Service Bus接收端的日志中出现大量的MessageLockLostException异常.完整的错误消息为: Microsoft.Azure.ServiceBus.MessageL ...
随机推荐
- webpack笔记-webpack初识与构建工具发展(一)
为什么需要构建工具? 转换 ES6 语法 转换 JSX CSS 前缀补全/预处理器 压缩混淆 图片压缩 前端构建演变之路 ant + YUI Tool grunt gulp.fis3 webpack. ...
- meltdown 安全漏洞原理是怎么样的?
Meltdown是2018年初公开的一种严重的计算机安全漏洞,影响了多种处理器,包括英特尔.ARM和某些AMD处理器.其原理基于利用现代CPU的"推测执行"(speculative ...
- 动态去读 dll 文件
// 反射动态读取 dll // Assembly assembly = Assembly.LoadFile(); 路径 // Assembly assembly = Assembly.LoadFro ...
- Spark任务OOM问题如何解决?
大家好,我是 V 哥.在实际的业务场景中,Spark任务出现OOM(Out of Memory) 问题通常是由于任务处理的数据量过大.资源分配不合理或者代码存在性能瓶颈等原因造成的.针对不同的业务场景 ...
- 云原生周刊:Linkerd 发布 v2.14 | 2023.9.4
开源项目推荐 Layerform Layerform 是一个 Terraform 包装器,可帮助工程师使用纯 Terraform 文件构建可重用的基础设施. 为了实现重用,Layerform 引入了层 ...
- PG 的 MergeJoin 就是鸡肋
好久没写博客,平时工作非常忙,而且现在对接的应用基本都是微服务架构. 微服务这种架构平时也很难遇到复杂SQL,架构层面也限制了不允许有复杂SQL,平时处理的都是简单一批的点查SQL. 基本上优化的内容 ...
- Linux Ubuntu 安装Python独立的不同版本
由于Ubuntu系统默认的Python版本基本为3.5.2,老掉牙的版本了,很多功能语法不可以使用,删除也并不好操作.所以不如新装一个最新的版本.速度快,操作简单,最重要的是使用只需要键入python ...
- 彻底搞懂ScheduledThreadPoolExecutor
前言 项目中经常会遇到一些非分布式的调度任务,需要在未来的某个时刻周期性执行.实现这样的功能,我们有多种方式可以选择: Timer类, jdk1.3引入,不推荐. 它所有任务都是串行执行的,同一时间只 ...
- NCNN 模型推理详解及实战
一,依赖库知识速学 aarch64 OpenMP AVX512 submodule apt upgrade 二,硬件基础知识速学 2.1,内存 2.2,CPU 三,ncnn 推理模型 3.1,shuf ...
- Java创建数组、赋值的四种方式,声明+创建+初始化 详解
@ 目录 一.创建数组的四种方式 二.详解 三.数组存储的弊端 一.创建数组的四种方式 以int数据类型为例 @Test public void testNewArray() { //创建数组 //法 ...