Python数据结构——散列表
散列表的实现常常叫做散列(hashing)。散列仅支持INSERT,SEARCH和DELETE操作,都是在常数平均时间执行的。需要元素间任何排序信息的操作将不会得到有效的支持。
散列表是普通数组概念的推广。如果空间允许,可以提供一个数组,为每个可能的关键字保留一个位置,就可以运用直接寻址技术。
当实际存储的关键字比可能的关键字总数较小时,采用散列表就比较直接寻址更为有效。在散列表中,不是直接把关键字用作数组下标,而是根据关键字计算出下标,这种
关键字与下标之间的映射就叫做散列函数。
1.散列函数
一个好的散列函数应满足简单移植散列的假设:每个关键字都等可能的散列到m个槽位的任何一个中去,并与其它的关键字已被散列到哪个槽位无关。
1.1 通常散列表的关键字都是自然数。
1.11 除法散列法
通过关键字k除以槽位m的余数来映射到某个槽位中。
hash(k)=k mod m
应用除法散列时,应注意m的选择,m不应该是2的幂,通常选择与2的幂不太接近的质数。
1.12 乘法散列法
乘法方法包含两个步骤,第一步用关键字k乘上常数A(0<A<1),并取出小数部分,然后用m乘以这个值,再取结果的底(floor)。
hash(k)=floor(m(kA mod 1))
乘法的一个优点是对m的选择没有什么特别的要求,一般选择它为2的某个幂。
一般取A=(√5-1)/2=0.618比较理想。
1.13 全域散列
随机的选择散列函数,使之独立于要存储的关键字。在执行开始时,就从一族仔细设计的函数中,随机的选择一个作为散列函数,随机化保证了
没有哪一种输入会始终导致最坏情况发生。
1.2 如果关键字是字符串,散列函数需要仔细的选择
1.2.1 将字符串中字符的ASCII码值相加
def _hash(key,m):
hashVal=0
for _ in key:
hashVal+=ord(_)
return hashVal%m
由于ascii码最大127,当表很大时,函数不会很好的分配关键字。
1.2.2 取关键字的前三个字符。
值27表示英文字母表的字母个数加上一个空格。
hash(k)=k[0]+27*k[1]+729*k[2]
1.2.3 用霍纳法则把所有字符扩展到n次多项式。
用32代替27,可以用于位运算。
def _hash(key,m):
hashval=0
for _ in key:
hashval=(hashval<<5)+ord(_)
return hashval%m
2. 分离链接法
散列表会面临一个问题,当两个关键字散列到同一个值的时候,称之为冲突或者碰撞(collision)。解决冲突的第一种方法通常叫做分离链接法(separate chaining)。
其做法是将散列到同一个值的所有元素保留到一个链表中,槽中保留一个指向链表头的指针。
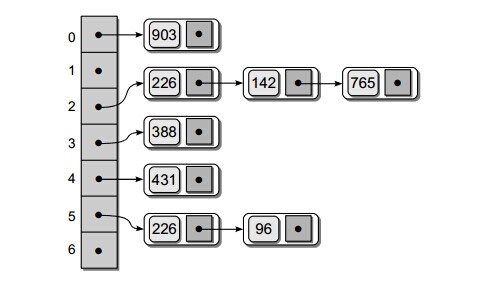
为执行FIND,使用散列函数来确定要考察哪个表,遍历该表并返回关键字所在的位置。
为执行INSERT,首先确定该元素是否在表中。如果是新元素,插入表的前端或末尾。
为执行DELETE,找到该元素执行链表删除即可。
散列表中元素个数与散列表大小的比值称之为装填因子(load factor)λ。
执行一次不成功的查找,遍历的链接数平均为λ,成功的查找则花费1+(λ/2)。
分离链接散列的一般做法是使得λ尽量接近于1。
代码:
class _ListNode(object):
def __init__(self,key):
self.key=key
self.next=None
class HashMap(object):
def __init__(self,tableSize):
self._table=[None]*tableSize
self._n=0 #number of nodes in the map
def __len__(self):
return self._n
def _hash(self,key):
return abs(hash(key))%len(self._table)
def __getitem__(self,key):
j=self._hash(key)
node=self._table[j]
while node is not None and node.key!=key :
node=node.next
if node is None:
raise KeyError,'KeyError'+repr(key)
return node
def insert(self,key):
try:
self[key]
except KeyError:
j=self._hash(key)
node=self._table[j]
self._table[j]=_ListNode(key)
self._table[j].next=node
self._n+=1
def __delitem__(self,key):
j=self._hash(key)
node=self._table[j]
if node is not None:
if node.key==key:
self._table[j]=node.next
self._-=1
else:
while node.next!=None:
pre=node
node=node.next
if node.key==key:
pre.next=node.next
self._n-=1
break
3.开放定址法
在开放定址散列算法中,如果有冲突发生,那么就要尝试选择另外的单元,直到找出空的单元为止。
h(k,i)=(h'(k)+f(i)) mod m,i=0,1,...,m-1 ,其中f(0)=0
3.1 线性探测法
函数f(i)是i的线性函数
h(k,i)=(h'(k)+i) mod m
相当于逐个探测每个单元

线性探测会存在一个问题,称之为一次群集。随着被占用槽的增加,平均查找时间也会不断增加。当一个空槽前有i个满的槽时,该空槽为下一个将被占用
槽的概率是(i+1)/m。连续被占用槽的序列会越来越长,平均查找时间也会随之增加。
如果表有一半多被填满的话,线性探测不是个好办法。
3.2 平法探测
平方探测可以取消线性探测中的一次群集问题。
h(k,i)=(h'(k)+c1i+c2i2) mod m
平方探测中,如果表的一半为空,并且表的大小是质数,保证能够插入一个新的元素。
平方探测会引起二次群集的问题。
3.3 双散列
双散列是用于开放定址法的最好方法之一。
h(k,i)=(h1(k)+ih2(k)) mod m
为能查找整个散列表,值h2(k)要与m互质。确保这个条件成立的一种方法是取m为2的幂,并设计一个总产生奇数的h2。另一种方法是取m为质数,并设计一个总是产生
较m小的正整数的h2。
例如取:
h1(k)=k mod m,h2(k)=1+(k mod m'),m'为略小于m的整数。
给定一个装填因子λ的开放定址散列表,插入一个元素至多需要1/(1-λ)次探查。
给定一个装填因子λ<1的开放定址散列表,一次成功查找中的期望探查数至多为(1/λ)ln(1/1-λ)。
4. 再散列
如果表的元素填得太满,那么操作的运行时间将开始消耗过长。一种解决方法是当表到达某个装填因子时,建立一个大约两倍大的表,而且使用一个相关的新散列函数,
扫描整个原始散列表,计算每个元素的新散列值并将其插入到新表中。
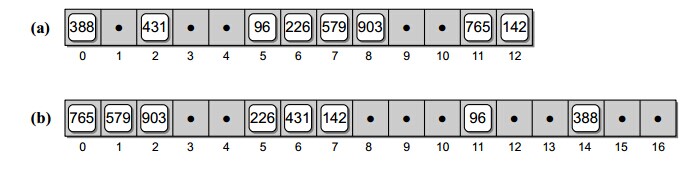
为避免开放定址散列查找错误,删除操作要采用懒惰删除。
代码
class HashEntry(object):
def __init__(self,key,value):
self.key=key
self.value=value
class HashTable(object):
_DELETED=HashEntry(None,None) #用于删除
def __init__(self,tablesize):
self._table=tablesize*[None]
self._n=0
def __len__(self):
return self._n
def __getitem__(self,key):
found,j=self._findSlot(key)
if not found:
raise KeyError
return self._table[j].value
def __setitem__(self,key,value):
found,j=self._findSlot(key)
if not found:
self._table[j]=HashEntry(key,value)
self._n+=1
if self._n>len(self._table)//2:
self._rehash()
else:
self._table[j].value=value
def __delitem__(self,key):
found,j=self._findSlot(key)
if found:
self._table[j]=HashTable._DELETED # 懒惰删除
def _rehash(self):
oldList=self._table
newsize=2*len(self._table)+1
self._table=newsize*[None]
self._n=0
for entry in oldList:
if entry is not None and entry is not HashTable._DELETED:
self[entry.key]=entry.value
self._n+=1
def _findSlot(self,key):
slot=self._hash1(key)
step=self._hash2(key)
firstSlot=None
while True:
if self._table[slot] is None:
if firstSlot is None:
firstSlot=slot
return (False,firstSlot)
elif self._table[slot] is HashTable._DELETED:
firstSlot=slot
elif self._table[slot].key==key:
return (True,slot)
slot=(slot+step)%len(self._table)
def _hash1(self,key):
return abs(hash(key))%len(self._table)
def _hash2(self,key):
return 1+abs(hash(key))%(len(self._table)-2)
Python数据结构——散列表的更多相关文章
- python实现散列表的直接寻址法
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构.也就是说,它通过计算一个关于键值的函数, 将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速 ...
- 数据结构---散列表查找(哈希表)概述和简单实现(Java)
散列表查找定义 散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,是的每个关键字key对应一个存储位置f(key).查找时,根据这个确定的对应关系找到给定值的key的对应f(key) ...
- python数据结构-数组/列表/栈/队列及实现
首先 我们要分清楚一些概念和他们之间的关系 数组(array) 表(list) 链表(linked list) 数组链表(array list) 队列(queue) 栈(stack) li ...
- Python数据结构之列表、元组及字典
一位大牛Niklaus Wirth曾有一本书,名为<Algorithms+Data Structures=Programs>,翻译过来也就是算法+数据结构=程序.而本文就是介绍一下Pyth ...
- Python数据结构之列表
1.Python列表是Python内置的数据结构对象之一,相当于数组 2.列表用[] 包含,内有任意的数据对象,每一个数据对象以 ,逗号分隔,每隔数据对象称之为元素 3.Python列表是一个有序的序 ...
- Python数据结构:列表、元组和字典
在Python中有三种内建的数据结构——列表list.元组tuple和字典dict 列表中的项目包括在方括号中,项目之间用逗号分割 元组和列表十分类似,只不过元组和字符串一样是不可变的 即你不能修改元 ...
- python实现散列表的链表法
在散列中,链接法是一种最简单的碰撞解决技术,这种方法的原理就是把散列到同一槽中的所有元素 都放在一个链表中. 链接法有两个定理,定理一: 在简单一致散列的假设下,一次不成功查找的期望时间为O(1 + ...
- Python数据结构 将列表作为栈和队列使用
列表作为栈使用 Python列表方法使得列表作为堆栈非常容易,最后一个插入,最先取出(“后进先出”).要添加一个元素到堆栈的顶端,使用 append() .要从堆栈顶部取出一个元素,使用 pop() ...
- Python数据结构:列表、字典、元组、集合
列表:shoplist = ['apple', 'mango', 'carrot', 'banana']字典:di = {'a':123,'b':'something'}集合:jihe = {'app ...
随机推荐
- 360开源的类Redis存储系统:Pika
Pika 是 360 DBA 和基础架构组联合开发的类 Redis 存储系统,完全支持 Redis 协议,用户不需要修改任何代码,就可以将服务迁移至 Pika.有维护 Redis 经验的 DBA 维护 ...
- string与数值之间的转换
9.50 编写程序处理一个vector<string>,其元素都表示整数型.计算vector中所有元素之和.修改程序,使之计算表示浮点值的string之和. 程序如下: #include& ...
- Hibernate初级
文章来源: http://blog.csdn.net/jiuqiyuliang/article/details/39078749/ 持久化(Persistence),把数据(如内存中的对象)保存到可永 ...
- iOS 对网络视频采集视频截图
在播放网络视频是 经常可以看到播放按钮下面是该制品的某个截图 : 一般情况下 后台服务器是可以把视频截图一起返回给你 你直接拿到图片显示就可以了 但是当后台没有提供时 我们也可以根据视频地址 自 ...
- 深入理解计算机系统第二版习题解答CSAPP 2.17
假设w=4,我们能给每个可能的十六进制数字赋予一个数值,假设用一个无符号或者补码表示.完成下表: x 无符号(B2U(x)) 补码(B2T(x)) 十六进制 二进制 0xE 1110 14 -2 0x ...
- fedora 23中配置tftp-server
fedora 23中配置tftp-server */--> fedora 23中配置tftp-server Table of Contents 1. 简介 2. tftp安装 3. 启动和允许 ...
- 解决myeclipse过期问题
一般myeclise使用期限为30天,超过之后,会频繁的提醒你,购买软件,很讨厌,有个这个小工具,,以后再也不怕啦!!! 使用方法: 1:将这个类导入到myeclipse包中 2:运行main方法,提 ...
- mysql命令行方式添加用户及设置权限
以前总是喜欢通过phpmyadmin去添加用户和数据库,这次装完系统后,配置了一大堆东东,实在不想安装phpmyadmin了,就通过命令行方式创建了数据库和设置权限,记录一下,免得以后总是百度 关键步 ...
- MSP430常见问题之开发工具类
Q1:我自己做了一块MSP430F149的试验板,以前用下载线进行调试没有出现过问题,但是,最近我每次make后用下载线调试时,总是弹出一个窗口,给我提示:Could not find target ...
- C#播放音乐,调用程序
一:C# 播放音乐 string sound = Application.StartupPath + "/sound/msg.wav"; //Application.Startup ...