深度学习之Batch归一化
前言
以下内容是个人学习之后的感悟,转载请注明出处~
Batch归一化
在神经网络中,我们常常会遇到梯度消失的情况,比如下图中的sigmod激活函数,当离零点很远时,梯度基本为0。为了
解决这个问题,我们可以采用Batch归一化。
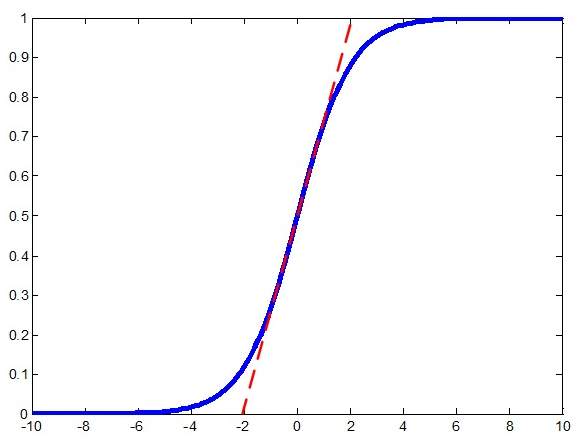
通过BN法,我们将每层的激活值都进行归一化,将它们拉到均值为0、方差为1的区域,这样大部分数据都从梯度趋于0变
换到中间梯度较大的区域,如上图中红线所示,从而解决梯度消失的问题。但是做完归一化后,函数近似于一个线性函数,多
层网络相当于一层,这不是我们想要的效果,故又加入了两个参数γ、β,整体步骤如下所示:
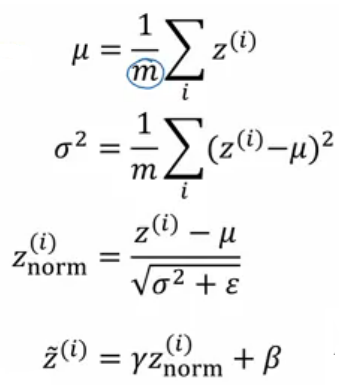
参数的加入固然可以解决问题,但是如何求解参数又增加了任务量。求法很简单,和求Wx+b中的W、b参数一样,不断
迭代减去代价函数对于Υ、β的倒数。
此算法的优势:
(1) 可以使用更高的学习率。如果每层的scale不一致,实际上每层需要的学习率是不一样的,同一层不同维度的scale往往也需
要不同大小的学习率,通常需要使用最小的那个学习率才能保证损失函数有效下降,Batch Normalization将每层、每维的scale
保持一致,那么我们就可以直接使用较高的学习率进行优化。
(2) 移除或使用较低的dropout。 dropout是常用的防止overfitting的方法,而导致overfit的位置往往在数据边界处,如果初始化权重
就已经落在数据内部,overfit现象就可以得到一定的缓解。论文中最后的模型分别使用10%、5%和0%的dropout训练模型,与之前
的40%-50%相比,可以大大提高训练速度。
(3) 降低L2权重衰减系数。 还是一样的问题,边界处的局部最优往往有几维的权重(斜率)较大,使用L2衰减可以缓解这一问题,
现在用了Batch Normalization,就可以把这个值降低了,论文中降低为原来的5倍。
(4) 取消Local Response Normalization层。 由于使用了一种Normalization,再使用LRN就显得没那么必要了。而且LRN实际上
也没那么work。
(5) 减少图像扭曲的使用。 由于现在训练epoch数降低,所以要对输入数据少做一些扭曲,让神经网络多看看真实的数据。
以上是全部内容,如果有什么地方不对,请在下面留言,谢谢~
深度学习之Batch归一化的更多相关文章
- 深度学习中 Batch Normalization
深度学习中 Batch Normalization为什么效果好?(知乎) https://www.zhihu.com/question/38102762
- 深度学习之Batch Normalization
在机器学习领域中,有一个重要的假设:独立同分布假设,也就是假设训练数据和测试数据是满足相同分布的,否则在训练集上学习到的模型在测试集上的表现会比较差.而在深层神经网络的训练中,当中间神经层的前一层参数 ...
- 关于深度学习之中Batch Size的一点理解(待更新)
batch 概念:训练时候一批一批的进行正向推导和反向传播.一批计算一次loss mini batch:不去计算这个batch下所有的iter,仅计算一部分iter的loss平均值代替所有的. 以下来 ...
- 【深度学习】批归一化(Batch Normalization)
BN是由Google于2015年提出,这是一个深度神经网络训练的技巧,它不仅可以加快了模型的收敛速度,而且更重要的是在一定程度缓解了深层网络中"梯度弥散"的问题,从而使得训练深层网 ...
- 深度学习中 Batch Normalization为什么效果好
看mnist数据集上其他人的CNN模型时了解到了Batch Normalization 这种操作.效果还不错,至少对于训练速度提升了很多. batch normalization的做法是把数据转换为0 ...
- 深度学习中batch normalization
目录 1 Batch Normalization笔记 1.1 引包 1.2 构建模型: 1.3 构建训练函数 1.4 结论 Batch Normalization笔记 我们将会用MNIST数 ...
- 深度学习面试题21:批量归一化(Batch Normalization,BN)
目录 BN的由来 BN的作用 BN的操作阶段 BN的操作流程 BN可以防止梯度消失吗 为什么归一化后还要放缩和平移 BN在GoogLeNet中的应用 参考资料 BN的由来 BN是由Google于201 ...
- 算法工程师<深度学习基础>
<深度学习基础> 卷积神经网络,循环神经网络,LSTM与GRU,梯度消失与梯度爆炸,激活函数,防止过拟合的方法,dropout,batch normalization,各类经典的网络结构, ...
- AI面试必备/深度学习100问1-50题答案解析
AI面试必备/深度学习100问1-50题答案解析 2018年09月04日 15:42:07 刀客123 阅读数 2020更多 分类专栏: 机器学习 转载:https://blog.csdn.net ...
随机推荐
- 【每日Scrum】第五天(4.15) TD学生助手Sprint1站立会议
TD学生助手Sprint1站立会议(4.15) 任务看板 站立会议内容 组员 昨天 今天 困难 签到 刘铸辉 (组长) 今天和静姐,娇哥把图片3D画廊效果的功能实现了,GPS功能没什么进展,所以只能继 ...
- Asp.Net Core 初探 (三)
昨天失败的生产环境部署就先放着,明天再解决! 今天利用中午的空余时间看了一下Asp.net core 的Areas . 相对于Asp.net MVC5 以及之前的版本,asp.net core 的Ar ...
- iOS用户是否打开APP通知开关跳转到系统的设置界面
1.检测用户是否打开推送通知 /** 系统通知是否打开 @return 是否打开 */ //检测通知是否打开iOS8以后有所变化 所以需要适配iOS7 + (BOOL)openThePushNoti ...
- EasyPlayer Android安卓流媒体播放器实现播放同步录像功能实现(附源码)
本文转自EasyDarwin团队John的博客:http://blog.csdn.net/jyt0551,John是EasyPusher安卓直播推流.EasyPlayer直播流媒体播放端的开发和维护者 ...
- HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件
HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件.它将每个文件存储成一系列的数据块,除了最后一个,所有的数据块都是同样大小的.为了容错,文件的所有数据块都会有副本.每个文件的数据块大小和副本 ...
- C++笔记之外部类访问内部类的私有成员
如下图所示 内部类可以访问外部类的私有成员 而外部类无法访问内部类的私有成员 为了能让外部类访问内部类的私有成员,将外部类声明为内部类的友元类即可 #include <iostream> ...
- VCL里的构造函数
好奇,为什么Create函数明明是个构造函数,还要带上override;这是C++里没有的事情.我虽然也明白其大致的作用和目的,但还是没有见到官方和权威的说法.如果哪位大大见到此文,还望给一个详细一点 ...
- 分词系统简介:PHPAnalysis分词程序
分词系统简介:PHPAnalysis分词程序使用居于unicode的词库,使用反向匹配模式分词,理论上兼容编码更广泛,并且对utf-8编码尤为方便. 由于PHPAnalysis是无组件的系统,因此速度 ...
- office web apps的搭建部署(1)(写于2017.12.27)
因为业务方面的需求,项目要求搭建office-web-apps这个玩意儿,做一个在线预览编辑的功能,为了方便,我下面都用OWA代替这个服务. 首先说一下什么是office-web-apps-serve ...
- javascript ajax和jquery ajax
一 进行ajax步骤: 1 获取dom值 2发送ajax请求 3返回成功进行前端逻辑处理 二 原生javascript的ajax <!DOCTYPE html> <html> ...