3.16 使用Zookeeper对HDFS HA配置自动故障转移及测试
一、说明
从上一节可看出,虽然搭建好了HA架构,但是只能手动进行active与standby的切换;
接下来看一下用zookeeper进行自动故障转移:
#
在启动HA之后,两个NameNode都是standby状态,可以利用zookeeper的选举功能,选出一个当Active #
监控
ZKFC
FailoverController
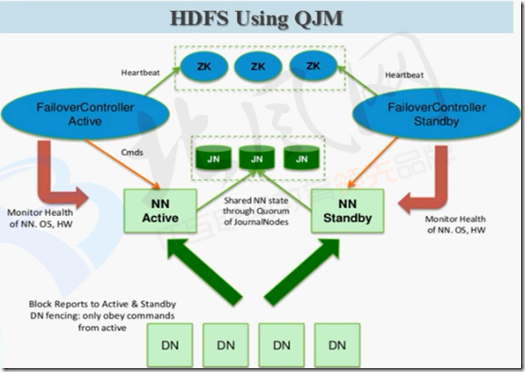
二、配置
1、hdfs-site.xml
#”开启自动转移功能“,加入以下内容;
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
2、core-site.xml
#”设置故障转移的zookeeper集群“,加入以下内容;
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
3、关闭集群所有服务
#master
[root@master hadoop-2.5.0]# sbin/stop-dfs.sh [root@master ~]# xcall jps
====== master jps ======
18719 Jps
====== slave1 jps ======
19150 Jps
====== slave2 jps ======
13595 Jps #如果还有其他服务(zookeeper等)也要关闭;
4、同步配置文件
[root@master hadoop]# pwd
/opt/app/hadoop-2.5.0/etc/hadoop [root@master hadoop]# scp -r hdfs-site.xml core-site.xml root@slave1:/opt/app/hadoop-2.5.0/etc/hadoop/ [root@master hadoop]# scp -r hdfs-site.xml core-site.xml root@slave2:/opt/app/hadoop-2.5.0/etc/hadoop/
5、启动zookeeper
#所有节点启动zookeeper
[root@master ~]# /opt/app/zookeeper-3.4.5/bin/zkServer.sh start [root@slave1 ~]# /opt/app/zookeeper-3.4.5/bin/zkServer.sh start [root@slave2 ~]# /opt/app/zookeeper-3.4.5/bin/zkServer.sh start #查看
[root@master ~]# xcall jps
====== master jps ======
18824 Jps
18765 QuorumPeerMain
====== slave1 jps ======
19201 QuorumPeerMain
19263 Jps
====== slave2 jps ======
13646 QuorumPeerMain
13702 Jps
6、初始化HA在Zookeeper中状态
#master
[root@master hadoop-2.5.0]# bin/hdfs zkfc -formatZK #
此时可以在slave1上用客户端连入zookeeper查看:
[root@slave1 zookeeper-3.4.5]# bin/zkCli.sh [zk: localhost:2181(CONNECTED) 1] ls /
[zookeeper] [zk: localhost:2181(CONNECTED) 2] ls / #生成了hadoop-ha
[hadoop-ha, zookeeper]
7、启动HDFS服务
#master
[root@master hadoop-2.5.0]# sbin/start-dfs.sh #查看启动情况
[root@master ~]# xcall jps
====== master jps ======
19588 DFSZKFailoverController #ZKFC监控进程
19087 NameNode
19193 DataNode
19393 JournalNode
18765 QuorumPeerMain
19662 Jps
====== slave1 jps ======
19743 DFSZKFailoverController #ZKFC监控进程
19201 QuorumPeerMain
19800 Jps
19613 JournalNode
19521 DataNode
19443 NameNode
====== slave2 jps ======
13646 QuorumPeerMain
13850 DataNode
14014 Jps
13942 JournalNode #查看nn1 nn2的状态
[root@master hadoop-2.5.0]# bin/hdfs haadmin -getServiceState nn1
19/04/18 10:34:50 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
active [root@master hadoop-2.5.0]# bin/hdfs haadmin -getServiceState nn2
19/04/18 10:34:54 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
standby #可见已经自动把nn1选举为active了,nn2为standby;在web中也可以看到;
8、测试故障自动转移
可以kill掉active状态的namenode,查看standby状态的namenode是否已经自动变为active了;
3.16 使用Zookeeper对HDFS HA配置自动故障转移及测试的更多相关文章
- 第6章 HDFS HA配置
目录 6.1 hdfs-site.xml文件配置 6.2 core-site.xml文件配置 6.3 启动与测试 6.4 结合ZooKeeper进行自动故障转移 在Hadoop 2.0.0之前,一个H ...
- 【解决】HDFS HA无法自动切换问题
[解决]HDFS HA无法自动切换问题 原因: 最早设置为root互相登录,可是zkfc服务是hdfs账号运行的,没有权限访问到root的id_rsa文件.更改为hdfs账号免密钥登录恢复正常. ...
- keepalive配置mysql自动故障转移
keepalive配置mysql自动故障转移 原创 2016年02月29日 02:16:52 2640 本文先配置了一个双master环境,互为主从,然后通过Keepalive配置了一个虚拟IP,客户 ...
- Apache版本的Hadoop HA集群启动详细步骤【包括Zookeeper、HDFS HA、YARN HA、HBase HA】(图文详解)
不多说,直接上干货! 1.先每台机器的zookeeper启动(bigdata-pro01.kfk.com.bigdata-pro02.kfk.com.bigdata-pro03.kfk.com) 2. ...
- 【Hadoop 分布式部署 十 一: NameNode HA 自动故障转移】
问题描述: 上一篇就是NameNode 的HA 部署完成,但是存在问题,问题是如果 主NameNode的节点宕机了,还是需要人工去使用命令来切换NameNode的Acitve 这样很不方便,所以 ...
- zookeeper:springboot+dubbo配置zk集群并测试
1.springboot配置zk集群 1.1:非主从配置方法 dubbo: registry: protocol: zookeeper address: ,, check: false 1.2:主从配 ...
- MongoDB副本集配置系列十一:MongoDB 数据同步原理和自动故障转移的原理
1:数据同步的原理: 当Primary节点完成数据操作后,Secondary会做出一系列的动作保证数据的同步: 1:检查自己local库的oplog.rs集合找出最近的时间戳. 2:检查Primary ...
- 大数据(3) - 高可用 HDFS HA
HDFS HA高可用 1 HA概述 1)所谓HA(high available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA机制 ...
- 【Zookeeper】利用zookeeper搭建Hdoop HA高可用
HA概述 所谓HA(high available),即高可用(7*24小时不中断服务). 实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA. ...
随机推荐
- linux查找文件夹下的全部文件里是否含有某个字符串
查找文件夹下的全部文件里是否含有某个字符串 find .|xargs grep -ri "IBM" 查找文件夹下的全部文件里是否含有某个字符串,而且仅仅打印出文件名称 fin ...
- liunx安装pip
安装pip之前要先安装Anaconda. 1.下载: # wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar. ...
- angular 复选框checkBox多选的应用
应用场景是这样的,后台返回的数据在页面上复选框的形式repeat出来 可能会有两种需求: 第一:后台返回的只有项,而没有默认选中状态(全是待选状态) 这种情况相对简单只要repeat出相应选项 第二: ...
- caffe搭建--ubuntu标准平台的搭建
http://caffe.berkeleyvision.org/install_apt.html Ubuntu Installation General dependencies sudo apt-g ...
- window下Jira+SQL Server部署+汉化+破解
网上很多都是jira+mysql部署的文章,由于我现在有需求要用SQL Server数据库,因此就动手试了一下,参考网上许多文章,再加上自己的几次尝试,很快也成功了,分享出来. 全文章节: 一.事前准 ...
- live555直播
http://www.cppblog.com/tx7do/archive/2014/05/31/207155.aspx http://blog.csdn.net/sunkwei/article/det ...
- repeter中应用三元运算符
应用情景一:根据ID显示名称例如:0代表启动,1:代表关闭例子如下 <td><%#Eval("ID").ToString() == "0" ? ...
- TEA对称加密算法
今天在看<Distributed Systems Concepts and Design>这本书的时候,在讲到分布式系统的安全性的时候,给出了TEA算法,书本上有现成的代码,所以摘录下来以 ...
- 各种数据库(oracle、mysql、sqlserver等)在Spring中数据源的配置和JDBC驱动包----转
在开发基于数据库的应用系统时,需要在项目中进行数据源的配置来为数据 库的操作取得数据库连接.配置不同数据库的数据源的方法大体上都是相同的,不同的只是不同数据库的JDBC驱动类和连接URL以及相应的数据 ...
- Android笔记之平移View
方法有多种,只讲一种 使用View.setLeft和View.setRight 对于wrap_content的View,要横向平移,setRight是必要的,否则View的宽度会被改变(right应设 ...