从感知机到 SVM,再到深度学习(一)
在上篇博客中提到,如果想要拟合一些空间中的点,可以用最小二乘法,最小二乘法其实是以样例点和理论值之间的误差最小作为目标。那么换个场景,如果有两类不同的点,而我们不想要拟合这些点,而是想找到一条直线把点区分开来,就像下图一样,那么我们应该怎么做呢?这个是一个最简单的分类问题。
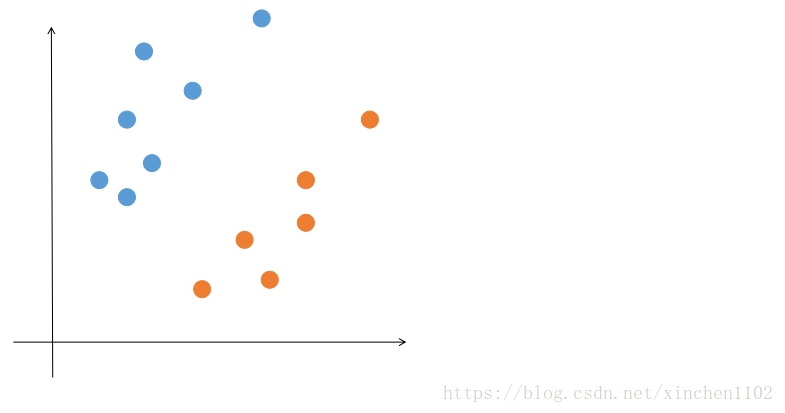
线性可分数据集
先考虑最简单的情况,也就是这两类点是没有交错在一起的,能够用一条直线 \(ax_{1}+bx_{2}+c=0\) 把它们区分开(是线性可分的)。所以只要能够确定参数 \(a\) 和 \(b\) 就行了。我们想让红点和黑点尽量分布在直线两侧,所以其实是想最小化最终分错的点(误分类点)的个数。那么怎么才算是分错呢,现在我们只知道黄点和蓝点应该不在同一侧,但是并不知道具体应该在那一侧(不只是这个图,考虑一般情况)。但是对于直线而言,把直线两侧的点带入直线方程得到的符号是相反的。我们可以根据这个判断某一个点是在直线的大于 0 的一侧还是小于 0 的一侧。
对于直线(或超平面),其实我们为了方便,我们可以给直线加一些不会影响最终结果的限制,让求解的模型少一些选择,只要依旧可以通过调整参数找到最优解就没问题。比如规定直线的大于 0 的一面一定是蓝点,小于 0 的一面一定是黄点。可能有人会问,那找到最优的直线的时候蓝点在小于 0 的一侧怎么办。但是没关系,即使是同一条直线,也可以通过两边同乘以 -1 达到让小于 0 和大于 0 换边的情况,所以这样假设没有关系,在进行参数优化的时候它自己就可以通过调整 a,b 来达到要求。加上这个限制,最终的目标函数就很好写了。首先给蓝、黄点分别标记为 p, q,训练集就是\(\left ( x_{1}, x_{2}, y\right )\),y 属于\(\left \{ p, q \right \}\)了。那么我们就是要最小化 $\sum f(ax_{1}+bx_{2}+c) $ ,其中 f 是一个用来数误分类点的个数的函数,对于分错的点 f 的函数值为 1,反之为 0。这个 f 函数有个名字叫激活函数(里面的信号强就激活一下)。根据限制,可以根据 \((y_{i}-mid) (ax_{1}+bx_{2}+c)\) (其中\(mid=\frac{p+q}{2}\))是否大于 0 来判断是否分错。为了方便,就可以去 p, q 为 -1 和 +1,这样这个判断条件就变成 \(y_{i} (ax_{1}+bx_{2}+c)\)了。我们要最小化的函数就叫损失函数。
接下来就是要对这个损失函数进行调参优化了。可以看出来,这个函数其实是找到当前的所有误分类点,然后通过它们进行调参,所以它是误分类点驱动的。但是即使找到了所有的无误分类点,由于损失函数是离散的,不连续也不可导,很难优化。所以需要找一个近似的,连续可导的函数来替换 f 函数。对于分错的点,我们可以用 \(\left | ax_{1}+bx_{2}+c \right |\) 去代替 f 中的 1 ,这里又面临去绝对值的问题了,还是可以通过平方法去绝对值。而对于分对的点,还是 0。这样损失函数就是\(\sum(ax_{1}+bx_{2}+c)^{2}\),找到误分类点之后就可以用梯度下降法优化了。但是对于这个问题,还有一个更巧妙的去绝对值的方式,既然我们已经知道 -1 在 \(ax_{1}+bx_{2}+c\) 大于 0 的一侧,而 1 在 <0 的一侧,所以:\(y_{i} * (ax_{1}+bx_{2}+c)\) 就一定是正的了。所以可以用\(y_{i}(ax_{1}+bx_{2}+c)\) 替换 1,损失函数就是\(\sum_{1}(ax_{1}+bx_{2}+c)\)。以这个为损失函数的整个优化流程就是:
- 随机给定 w, b
- 找到当前这条直线 \(ax_{1}+bx_{2}+c=0\) 的情况下,找到所有分错的点(x_no,y_no)
- 把直线写作矩阵的形式:\(wx+c=0\),其中\(w=(w_{1},w_{2})\), \(x=(x_{1},x_{2})^ \mathrm{ T }\),然后通过找到的误分点用梯度下降法进行参数调优。
\(\frac{\partial L(w, b)}{\partial w}=\sum_{i=1}^{n} y_{i}x_{i}\)
\(\frac{\partial L(w,b)}{\partial b}=\sum_{i=1}^{n} y_{i}\)
\(w:=w+\alpha*\sum_{i=1}^{n} y_{i}x_{i}\)
\(b:=b+\alpha*\sum_{i=1}^{n} y_{i}\)
其中 \(\alpha\) 是学习率。 - 重复 2, 3 步。直到找不到错分的点或者到达迭代上限为止。
经过实验发现这种目标函数收敛比平方的那个的要快,而且对于点刚好在直线上时,平方法中求出来的 a, b 的梯度都是 0,就无法处理了,所以只能认为刚好在直线上也是分对了。而这种方法由于有 \(y_{i}\) 的先验知识,b 的梯度至少不会是0,可以处理这种情况。当然还可以用点到直线的距离来代替用来计数的函数:, 同样用 \(y_{i}\) 去绝对值,但是没有必要,徒增了很多复杂度。
如果初始值是线性不可分的,就会出现不收敛,一直在交叉的点之间震荡的情况。
这个就是传说中的感知机算法,这里的例子都是二维的,但是对于多维的情况也是一样的。无非就是直线变成一个超平面 $wx+b=0 ,x = (x0,x1,...,xn), w = (w0,w1,...,wn) $了。感知机算法本身还有很多内容,比如如何证明算法是收敛的,用对偶方法提高速度等等,这些跟主线无关~,以后再写吧。
感知机算法虽然能够将线性可分的数据集区分开,但是比较没追求...只要能找到一条能把两类点完全分开的直线就满足了。但是这样的直线是有无穷多条的,我们希望能根据训练数据找到一条“最优”的,这样有利于算法的泛化能力,也更加充分的利用了数据的信息。比如下图:
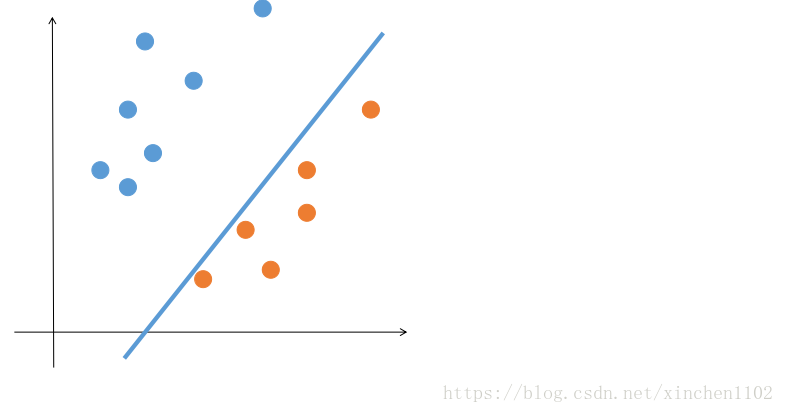
图 1.
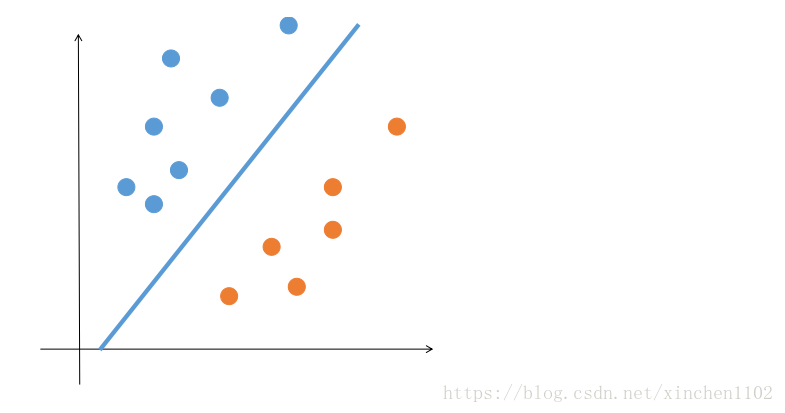
图 3.
感知机会认为上面的图都是最优解。但是显然第二个优于第一个。那么怎么解决呢?
我们期望能找到一条基于当前训练数据的“最优”的直线。所谓“最优”还是需要量化,其实就对应了最大化目标函数。而感知机之所以没有最优是因为它的目标函数 \(\sum f(ax_{1}+bx_{2}+c)\) 过于粗糙了,它只考虑当前错分的点,分对的点的 f 值都是 0,本质上优化的还是分错的点的个数,所以当点全部分对之后目标函数就达到最优了。但其实点全部分对之后直线还有优化的空间,比如直线离开两类数据都尽量远一点。那么如果我们能够给出一个更精细的 f 函数,不止能告诉目标函数某个点是否分对了,还能够告诉它分正确的程度有多大,或者是分错的程度有多大。也就是说当点分对或分错的时候,f 的值不再是 0 或 1 了,而是一个表示分对、分错的确信度的值,那么最终直线就能到一个更精细的最优位置,即尽量不分错,且分对的程度之和最大。而这个计数的函数(激活函数)只要满足单调递增就行了,表示分对程度越大,奖励就越大,反之也是。用的时候比较常见的有:
- 线性函数 \(y=x\)
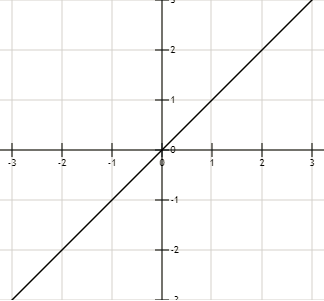
线性函数图像
sigmoid 函数 \(y=\frac{1}{1+e^-x}\)
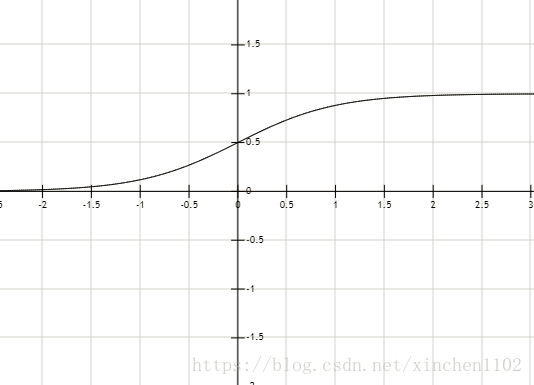
sigmoid 函数图像
而感知机中用的是阶跃函数,相对比较粗糙。
其中用 sigmoid 函数作为激活函数的就算法就叫 logistic 回归了,也是最常用的。sigmod 函数在 x > 0 的时候 y > 0.5, x< 0 的时候 y<0.5。这样函数就能与 0.5 进行比较,从而自动识别出点是否分对,以及分对(或分错)的程度了。
那么这个怎么转化为需要最大化的目标函数呢?其实这个还是用直线进行划分,我们还是假设 {a, b} 两类,其中让 a 类带入直线大于 0, b 类小于零(之前已经解释,这样做是没有问题的) 那么对于某个点,如果它是 a 类,我们就让 p 尽量大 ,如果是 b 类我们是要让 1 - p 尽量大。把这个目标写成式子就是:对于某个点,我们要 \((y_{i} - a) p_{i} + (y_{i} - b) (1 - p_{i})\) 尽量大。为了方便,我们就取 a、b 为 0, 1,式子就变成 $y_{i}p_{i} + (y_{i} - 1) (1 - p_{i}) $了。所以对于整个数据集目标就是最大化 \(\sum y_{i}p_{i} + (y_{i} - 1)(1-p_{i})\)。可以对它直接求偏导进行参数优化。在最优化问题的,一般习惯上喜欢最小化某个函数,而那个函数就叫损失函数。所以这里可以把 \(-\sum y_{i}p_{i} + (y_{i} - 1)(1-p_{i})\)作为损失函数,要让它最小。这样做是没问题的,但是比较朴素,效果也不好。
其实对于 sigmoid 函数而言,它已经把最后的输出值限制在 [0, 1] 的范围内,并且是以 0.5 为界。那么我们就可以把输出值看做一个概率,把分对、分错的程度(确信度)用一个概率值表示出来当分对的概率大于 0.5 的时候,我们就可以认为确实分对了。这样就有很多更好的损失函数的公式可以直接用进来,比如交叉熵,极大似然估计等。
比如用交叉熵,交叉熵的公式是:\(H(p,q)=-\sum_{x} p(x)logq(x)\),其中p(x)表示训练样本的标签,q(x) 表示模型预测的值,它其实是衡量了预测的值的分布和真实标签分布之间的距离,具体参看 wiki 百科。
这里带入交叉熵公式得到的损失函数是:$-\sum_{i=1}^{n} y_{i}p(x_{i}) + (y_{i} - 1)(1-p(x_{i})) $ 其中 n 为训练样本数。用的时候一般需要对 n 做个归一化,得到$-\frac{1}{n}\sum_{i=1}^{n} y_{i}p(x_{i}) + (y_{i} - 1)(1-p(x_{i})) $ 。
然后用梯度下降法优化就行了,步骤是:- 获取 n 个训练样本 (x_{1}, x_{2}, y) , y 属于\({0,1}\)
- 对于直线 \(wx+b=0\),需要 $min L(w, b) = -\frac{1}{n}\sum_{i=1}^{n} y_{i} sigmoid(x_{i}))) + (y_{i} - 1)(1-sigmoid(x_{i}))) $,对参数求梯度:
\(\frac{\partial L(w,b)}{w}=-\frac{1}{n}\sum_{i=1}^{n} x_{i}(y_{i}-sigmoid(wx_{i}+b))\)
\(\frac{\partial L(w,b)}{b}=-\frac{1}{n}\sum_{i=1}^{n} y_{i}-sigmoid(wx_{i}+b)\)
\(w := w - \alpha \frac{\partial L(w,b)}{w}\)
\(b := b - \alpha \frac{\partial L(w,b)}{b}\) 重复 1,2,直到 w, b 的梯度小于某个很小的值,或者达到循环上限。
如果用极大似然估计,由于在极大似然估计中需要取对数操作,为了方便,可以把 \(y_{i} p + (1 - y_{i}) (1-p)\) 改写为 \(p^{y_{i}} (1-p)^{1 - y_{i}}\),这两个是完全等价的。极大似然估计写出来的式子是:
\(max \quad L(w,b) = \prod_{i=1}^{n} p^{y_{i}} (1-p)^{1 - y_{i}}\)
然后为了计算方便,取对数。为了把这个 max 变成 min,需要进行取反,这都是极大似然估计的标准步骤:
\(min \quad L(w,b) = -\sum_{i=1}^{n} (y_{i}logp+ (1 - y_{i})log(1-p))\)
最后发现两种方法得到的表达式是一样的,所以后面的优化步骤都一样。
这个就是 logistic 回归的思路了。这里还是用二维的举例,对于高维的情况几乎是一样的,就是参数从 \((w_{1},w_{2})\)变为 \((w_{1},w_{2},...,w_{n})\)了而已。由于 logistic 回归是基于全部点去定义、优化目标函数,所以已经解决了只能处理二分类的问题。logistic 回归可以很容易的扩展成能多分类的 softmax 算法,softmax 算法对于 n 类,就用 n-1 个超平面把它们分开。这个就是另外一个方法了。
那么 logistic 回归就是完美的了吗,它至少还有两个缺点:1. 还是只能解决数据线性可分的问题 2. 考虑所有的点得到的最优直线还是会带来一些问题,比如:
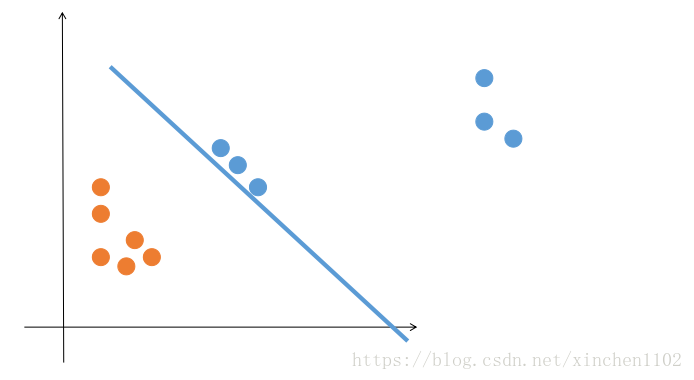
图1
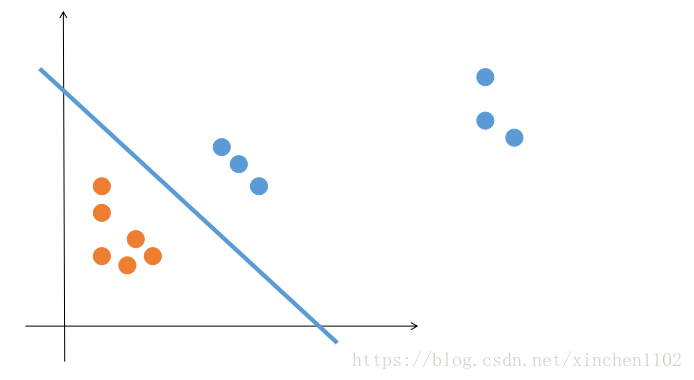
图2
明显图 2 优于图1 ,图 1 的泛化能力较差,新的黑点很容易就被分到黄点一侧了。
为什么会这样呢?通过 sigmoid 函数的图像可以看出来。
两个类别的数据量是一样的。但是由于黑点有一部分离得比较远,所以把直线向黑点侧移动一些对于那些黑点而言目标函数减少的很少。而黄点比较集中且离平面较近,让平面远离黄点的收益更大。这个问题当数据量不平衡的时候会更加严重。
那么如果用线性函数作为激活函数呢?这样对于两类的数据量不相同的时候这个问题依然会出现。
感知机只考虑分错的点,会无法找到最理想的直线。而 logistic 回归考虑了所有点,但是对于离得比较远的点,甚至异常点也会过于敏感(比如这里黄点离得比较远的点就对平面产生了很大影响)。其实问题还是在我们对“最优直线”的定义上,我们其实是想让最终的直线离开两边的点都尽量远。所以其实可以只考虑离直线最近的那些点,只要让它们和直线的距离尽量大就行了。
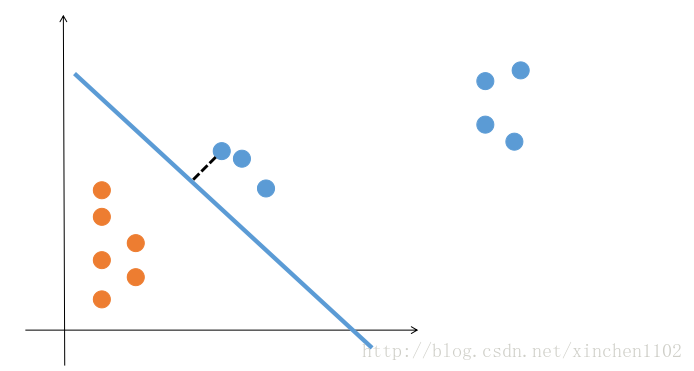
最小间隔示意图
如图,黑色虚线就是当前需要优化的目标。当它过于靠近黄点的时候,优化的目标就会变成直线跟最近的黄点的距离。因为需要对点和直线衡量距离,而不是像感知机中只要知道点在直线的那一侧就行了。所以这里就需要用点到直线的距离公式了,距离公式为 \(\frac {|w_{1}x_{1} + w_{2}x_{2} + w_{3}|}{||(w_{1}, w_{2})||}\),用 y_{i} 去绝对值,得到\(d(x) = y_{i}\frac {w_{1}x_{1} + w_{2}x_{2} + w_{3}}{||(w_{1}, w_{2})||}\)。目标是让距离直线最近的那个点到直线的距离越大越好,即 \(max_{w,b}min_{x} \quad d(x)\)。这个式子写成带约束的优化问题就是:
\[\begin{align*}
max_{\gamma,w,b} \quad \gamma \\
&s.t. \quad y_{i}\frac {w_{1}x_{1} + w_{2}x_{2} + w_{3}}{||(w_{1}, w_{2})||} > \gamma
\end{align*}\]
用这个目标函数的算法叫最优间隔分类器。接下来就需要用凸优化的理论来求解这个优化问题了,比较复杂,下次再写吧。
参考链接:
对机器学习感兴趣的新手或者大牛,如果有觉得对别人有帮助的,高质量的网页,大家可以通过 chrome 插件分享给其他人,在这里安装分享插件。
从感知机到 SVM,再到深度学习(一)的更多相关文章
- 从感知机到 SVM,再到深度学习(三)
这篇博文详细分析了前馈神经网络的内容,它对应的函数,优化过程等等. 在上一篇博文中已经完整讲述了 SVM 的思想和原理.讲到了想用一个高度非线性的曲线作为拟合曲线.比如这个曲线可以是: ...
- 从感知机到 SVM,再到深度学习(二)
这篇博文承接上一篇,详细推导了 SVM 算法,包括对偶算法,SMO 优化算法,核函数技巧等等,最后还提到用高度非线性的曲线代替超平面,就是神经网络的方法. 在第一篇中已经得到了最优间隔 ...
- 转:深度学习斯坦福cs231n 课程笔记
http://blog.csdn.net/dinosoft/article/details/51813615 前言 对于深度学习,新手我推荐先看UFLDL,不做assignment的话,一两个晚上就可 ...
- 20个令人惊叹的深度学习应用(Demo+Paper+Code)
20个令人惊叹的深度学习应用(Demo+Paper+Code) 从计算机视觉到自然语言处理,在过去的几年里,深度学习技术被应用到了数以百计的实际问题中.诸多案例也已经证明,深度学习能让工作比之前做得更 ...
- 13.深度学习(词嵌入)与自然语言处理--HanLP实现
笔记转载于GitHub项目:https://github.com/NLP-LOVE/Introduction-NLP 13. 深度学习与自然语言处理 13.1 传统方法的局限 前面已经讲过了隐马尔可夫 ...
- linux(Ubuntu)下机器学习/深度学习环境配置
为了开发环境纯净,应该首先创建虚拟环境 mkvirtualenv -p python3 虚拟环境名称 如,mkvirtualenv -p python3 ai 但是有的童鞋会卡在这一步,会报一个这样的 ...
- Tensorflow 2.0 深度学习实战 —— 详细介绍损失函数、优化器、激活函数、多层感知机的实现原理
前言 AI 人工智能包含了机器学习与深度学习,在前几篇文章曾经介绍过机器学习的基础知识,包括了监督学习和无监督学习,有兴趣的朋友可以阅读< Python 机器学习实战 >.而深度学习开始只 ...
- 深度学习基础-基于Numpy的感知机Perception构建和训练
1. 感知机模型 感知机Perception是一个线性的分类器,其只适用于线性可分的数据. f(x) = sign(w.x + b) 其试图在所有线性可分超平面构成的假设空间中找 ...
- (转)神经网络和深度学习简史(第一部分):从感知机到BP算法
深度|神经网络和深度学习简史(第一部分):从感知机到BP算法 2016-01-23 机器之心 来自Andrey Kurenkov 作者:Andrey Kurenkov 机器之心编译出品 参与:chen ...
随机推荐
- VLOOKUP函数常用套路大全
今天和大家来说说VLOOKUP的那些事儿,深入了解一下VLOOKUP函数的各种用法,看看这位大众情人还藏着多少不为人知的秘密.函数的语法为:VLOOKUP(要找谁,在哪儿找,返回第几列的内容,精确找还 ...
- elasticsearch基本操作之--java基本操作 api
/** * 系统环境: vm12 下的centos 7.2 * 当前安装版本: elasticsearch-2.4.0.tar.gz */ 默认进行了elasticsearch安装和ik安装, 超时配 ...
- S/4 HANA中的ACDOCT和FAGLFLEXT
最近的几个需求让我对ACDOCT和FAGLFLEXT这两个财务相关表(准确地说是视图)产生了一些了解,同时也发现某些开发同行和业务顾问并没有认识到这些东西.因此打算从技术角度来说明一下这两个视图在S4 ...
- Python进阶_类与实例
上一节将到面对对象必须先抽象模型,之后直接利用模型.这一节我们来具体理解一下这句话的意思. 面对对象最重要的概念就是类(class)和实例(instance),必须牢记类是抽象的模板,比如studen ...
- Axis1.4之即时发布服务
下载axis1.4开发包,解压开发包,将webapps目录下的axis文件夹拷贝到tomcat的webapps目录下.启动tomcat,在浏览器输入http://localhost:8080/axis ...
- poj-3185-开关问题
描述 牛一行20他们喝的水碗.碗可以那么(面向正确的为清凉水)或颠倒的(一个位置而没有水).他们希望所有20个水碗那么,因此用宽鼻子翻碗. 嘴太宽,他们不仅翻转一碗还碗的碗两侧(总共三个或三个——在两 ...
- 将 Shiro 作为应用的权限基础 一:shiro的整体架构
将 Shiro 作为应用的权限基础 一:shiro的整体架构 近来在做一个重量级的项目,其中权限.日志.报表.工作量由我负责,工作量还是蛮大的,不过想那么多干嘛,做就是了. 这段时间,接触的东西挺多, ...
- Android 的消息队列模型
Android 的消息队列模型 Android是参考Windows的消息循环机制来实现Android自身的消息循环的. Android通过Looper.Handler来实现消息循环机制,Andr ...
- [BZOJ 1297][SCOI2009]迷路
1297: [SCOI2009]迷路 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 1418 Solved: 1017[Submit][Status ...
- C#/AutoCAD 2018/ObjectArx/二次开发添加删除实体的工具函数(四)
1.添加删除实体 C# ObjectARX二次开发添加删除实体是非常容易主要代码如下: 添加实体: objId = btr.AppendEntity(entity); trans.AddNewlyCr ...