selenium+谷歌无头浏览器爬取网易新闻国内板块
网页分析
首先来看下要爬取的网站的页面
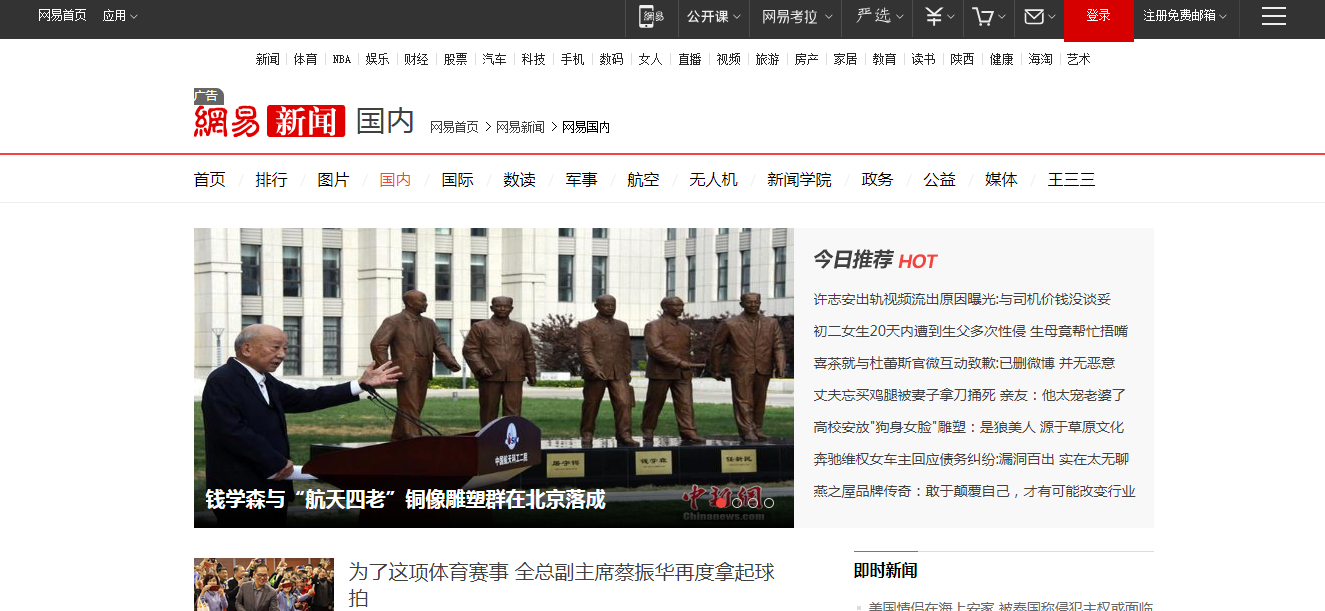
查看网页源代码:你会发现它是由js动态加载显示的
所以采用selenium+谷歌无头浏览器来爬取它
1 加载网站,并拖动到底,发现其还有个加载更多
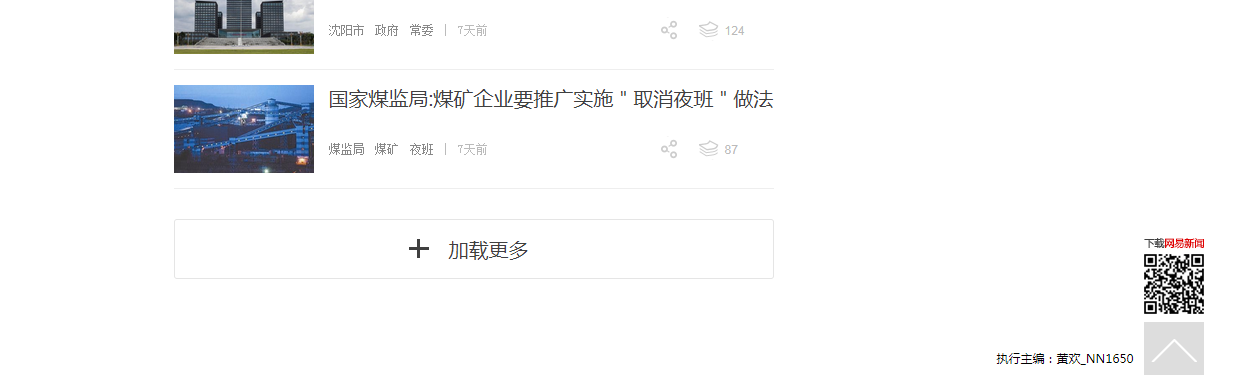
2 模拟点击它,然后再次拖动到底,,就可以加载完整个页面
示例代码
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from time import sleep
from lxml import etree
import os
import requests # 使用谷歌无头浏览器来加载动态js
def main():
# 创建一个无头浏览器对象
chrome_options = Options()
# 设置它为无框模式
chrome_options.add_argument('--headless')
# 如果在windows上运行需要加代码
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(chrome_options=chrome_options)
# 设置一个10秒的隐式等待
browser.implicitly_wait(10)
browser.get(url)
sleep(1)
# 翻到页底
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
# 点击加载更多
browser.find_element(By.CSS_SELECTOR, '.load_more_btn').click()
sleep(1)
# 再次翻页到底
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
# 拿到页面源代码
source = browser.page_source
browser.quit()
with open('xinwen.html', 'w', encoding='utf-8') as f:
f.write(source)
parse_page(source) # 对新闻列表页面进行解析
def parse_page(html):
# 创建etree对象
tree = etree.HTML(html)
new_lst = tree.xpath('//div[@class="ndi_main"]/div')
for one_new in new_lst:
title = one_new.xpath('.//div[@class="news_title"]/h3/a/text()')[0]
link = one_new.xpath('.//div[@class="news_title"]/h3/a/@href')[0]
write_in(title, link) # 将其写入到文件
def write_in(title, link):
print('开始写入篇新闻{}'.format(title))
response = requests.get(url=link, headers=headers)
tree = etree.HTML(response.text)
content_lst = tree.xpath('//div[@class="post_text"]//p')
title = title.replace('?', '')
with open('new/' + title + '.txt', 'a+', encoding='utf-8') as f:
for one_content in content_lst:
if one_content.text:
con = one_content.text.strip()
f.write(con + '\n') if __name__ == '__main__':
url = 'https://news.163.com/domestic/'
headers = {"User-Agent": 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0'}
if not os.path.exists('new'):
os.mkdir('new')
main()
得到结果:
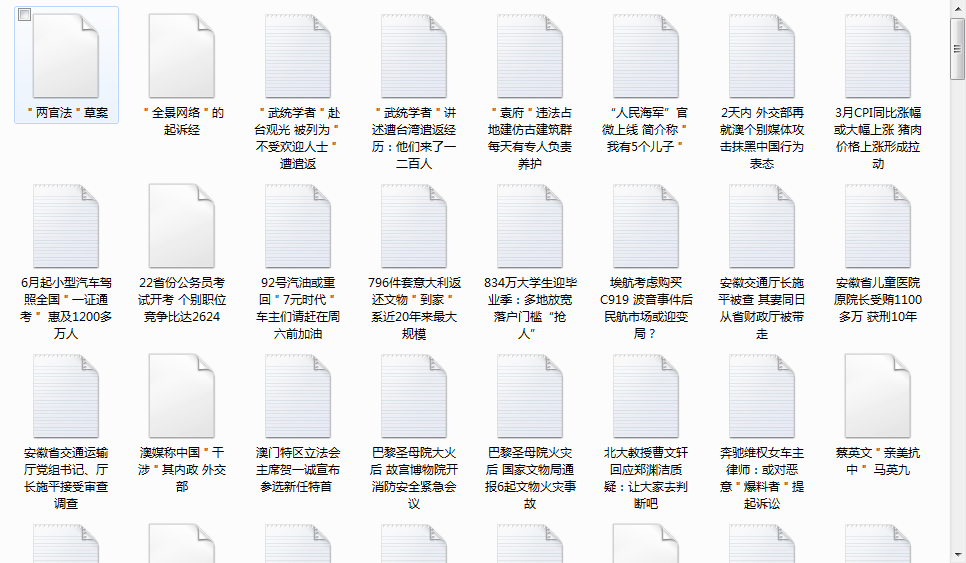
随意打开一个txt:

Scrapy版
wangyi.py
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from happy1.items import Happy1Item class WangyiSpider(scrapy.Spider):
name = 'wangyi'
# allowed_domains = ['https://news.163.com/domestic/']
start_urls = ['http://news.163.com/domestic/'] def __init__(self):
# 创建一个无头浏览器对象
chrome_options = Options()
# 设置它为无框模式
chrome_options.add_argument('--headless')
# 如果在windows上运行需要加代码
chrome_options.add_argument('--disable-gpu')
# 示例话一个浏览器对象(实例化一次)
self.bro = webdriver.Chrome(chrome_options=chrome_options) def parse(self, response):
new_lst = response.xpath('//div[@class="ndi_main"]/div')
for one_new in new_lst:
item = Happy1Item()
title = one_new.xpath('.//div[@class="news_title"]/h3/a/text()')[0].extract()
link = one_new.xpath('.//div[@class="news_title"]/h3/a/@href')[0].extract()
item['title'] = title
yield scrapy.Request(url=link,callback=self.parse_detail, meta={'item':item}) def parse_detail(self, response):
item = response.meta['item']
content_list = response.xpath('//div[@class="post_text"]//p/text()').extract()
item['content'] = content_list
yield item # 在爬虫结束后,关闭浏览器
def close(self, spider):
print('爬虫结束')
self.bro.quit()
pipelines.py
class Happy1Pipeline(object):
def __init__(self):
self.fp = None def open_spider(self, spider):
print('开始爬虫') def process_item(self, item, spider):
title = item['title'].replace('?', '')
self.fp = open('news/' + title + '.txt', 'a+', encoding='utf-8')
for one in item['content']:
self.fp.write(one.strip() + '\n')
self.fp.close()
return item
items.py
import scrapy class Happy1Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()
middlewares.py
def process_response(self, request, response, spider):
if request.url in ['http://news.163.com/domestic/']:
spider.bro.get(url=request.url)
time.sleep(1)
spider.bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
spider.bro.find_element(By.CSS_SELECTOR, '.load_more_btn').click()
time.sleep(1)
spider.bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
page_text = spider.bro.page_source
return HtmlResponse(url=spider.bro.current_url, body=page_text, encoding='utf-8', request=request)
else:
return response
settings.py
DOWNLOADER_MIDDLEWARES = {
'happy1.middlewares.Happy1DownloaderMiddleware': 543,
}
ITEM_PIPELINES = {
'happy1.pipelines.Happy1Pipeline': 300,
}
得到结果

总结:
1 其实主要的工作还是模拟浏览器来进行操作。
2 处理动态的js其实还有其他办法。
3 爬虫的方法有好多种,主要还是选择适合自己的。
4 自己的代码写的太烂了。
selenium+谷歌无头浏览器爬取网易新闻国内板块的更多相关文章
- 如何利用python爬取网易新闻
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: LSGOGroup PS:如有需要Python学习资料的小伙伴可以 ...
- Python爬虫实战教程:爬取网易新闻
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Amauri PS:如有需要Python学习资料的小伙伴可以加点击 ...
- Python爬虫实战教程:爬取网易新闻;爬虫精选 高手技巧
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. stars声明很多小伙伴学习Python过程中会遇到各种烦恼问题解决不了.为 ...
- Python 爬虫实例(4)—— 爬取网易新闻
自己闲来无聊,就爬取了网易信息,重点是分析网页,使用抓包工具详细的分析网页的每个链接,数据存储在sqllite中,这里只是简单的解析了新闻页面的文字信息,并未对图片信息进行解析 仅供参考,不足之处请指 ...
- 爬虫之 图片懒加载, selenium , phantomJs, 谷歌无头浏览器
一.图片懒加载 懒加载 : JS 代码 是页面自然滚动 window.scrollTo(0,document.body.scrollHeight) (重点) bro.execute_ ...
- Selenium+Chrome/phantomJS模拟浏览器爬取淘宝商品信息
#使用selenium+Carome/phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏 ...
- 爬虫之selenium模块;无头浏览器的使用
一,案例 爬取站长素材中的图片:http://sc.chinaz.com/tupian/gudianmeinvtupian.html import requests from lxml import ...
- 利用scrapy抓取网易新闻并将其存储在mongoDB
好久没有写爬虫了,写一个scrapy的小爬爬来抓取网易新闻,代码原型是github上的一个爬虫,近期也看了一点mongoDB.顺便小用一下.体验一下NoSQL是什么感觉.言归正传啊.scrapy爬虫主 ...
- Python实训day07pm【Selenium操作网页、爬取数据-下载歌曲】
练习1-爬取歌曲列表 任务:通过两个案例,练习使用Selenium操作网页.爬取数据.使用无头模式,爬取网易云的内容. ''' 任务:通过两个案例,练习使用Selenium操作网页.爬取数据. 使用无 ...
随机推荐
- jquery选择器 看这个链接吧!2017.6.2
http://www.cnblogs.com/tylerdonet/archive/2013/04/02/2996713.html关于jquery选择器说明.
- JS奇淫巧技:防抖函数与节流函数
应用场景 实际工作中,我们经常性的会通过监听某些事件完成对应的需求,比如: 通过监听 scroll 事件,检测滚动位置,根据滚动位置显示返回顶部按钮 通过监听 resize 事件,对某些自适应页面调整 ...
- 第七章 函数表达式和函数声明,关于this对象 ,私有作用域(function(){})() ,私有变量和特权方法
一:函数表达式和函数声明 1:函数声明和函数表达式的区别 ①函数声明不需要分号结尾 ②函数声明有函数提升的特点 ③函数声明后面不能跟圆括号直接调用,因为javascript将function关键字当作 ...
- 玩转JPA(一)---异常:Repeated column in mapping for entity/should be mapped with insert="false" update="fal
最近用JPA遇到这样一个问题:Repeated column in mapping for entity: com.ketayao.security.entity.main.User column: ...
- python运行js
安装 pip install PyExecJS # 需要注意, 包的名称:PyExecJS 简单使用 import execjs execjs.eval("new Date") 返 ...
- persistent_storage_worker.go
package) ) :length],) ) :length]) } func (engine *Engine) persistentStorageInitWorker(shard int) { ...
- index_init_oprions.go
{ options.DocCacheSize = defaultDocCacheSize } }
- 在MFC中通过访问IP地址下载文件到本地
void CDownLoad::OnBnClickedOk() { // TODO: 在此添加控件通知处理程序代码 CDialogEx::OnOK(); UpdateData(TRUE); CStri ...
- BZOJ_2956_模积和_数学
BZOJ_2956_模积和_数学 Description 求∑∑((n mod i)*(m mod j))其中1<=i<=n,1<=j<=m,i≠j. Input 第一行两个数 ...
- JVM学习记录-类加载时机
虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验.转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这就是类的加载机制. 在Java语言里面,类型的加载.连接和初始化过程都 ...