LeNet-5识别MINIST数据集
LeNet-5
LeNet于90年代被提出,鉴于当时的计算能力和内存容量,直到2010年才能真正的实施这样的大规模计算。LeNet-5是LeCun于1998年提出的深度神经网络结构,总共包含7层网络(除输入层外):2层卷积层、2层池化层、3层全连接层(在原论文中第一个全连接层被称为卷积层)。网络结构图[2]如下图所示:

输入数据是公认的MNIST[1]手写数字数据集,尺寸为32*32*1的灰度图,在论文中卷积层记为Cx()、池化层记为Sx(降采样)、全连接层记为Fx,x表示层级,接下来对7层网络结构分析如下:
- C1(32x32x1 => 28x28x6)
采用5x5x1,6 个卷积核,不使用0填充,输出尺寸是(N-P+1)=(32-5+1)=28,维度是28x28x6:
- 卷积可训练参数:每个卷积核大小是5*5,有6个channel,所以是(5*5+1)*6=156
- 连接数:计算连接数的时候从输出的特征图(feature map)中具体特征点入手,每个特征点是有输入图和卷积核相乘得来的,计算量为1*5*5+1,共有28*28个特征点,所以连接数为(28*28*6)*(5*5+1)=122304
- S2(28x28x6 => 14x14x6)
采用2x2x6,strides=2的平均池化层(目前最流行的是max pool,所以后面代码中替换了),输出尺寸是floor((N-P)/strides+1)=floor((28-2)/2+1)=14,维度是14x14x6:
- 卷积可训练参数(每个池化层有两个训练参数,有一个系数和一个偏置):(1+1)*6=12
- 连接数:(14*14*6)*(2*2+1)=5880
- C3(14x14x6 => 10x10x16)
采用5x5x6,16 个卷积核,不使用0填充,输出尺寸是(14-5+1)=10,维度是10x10x16:
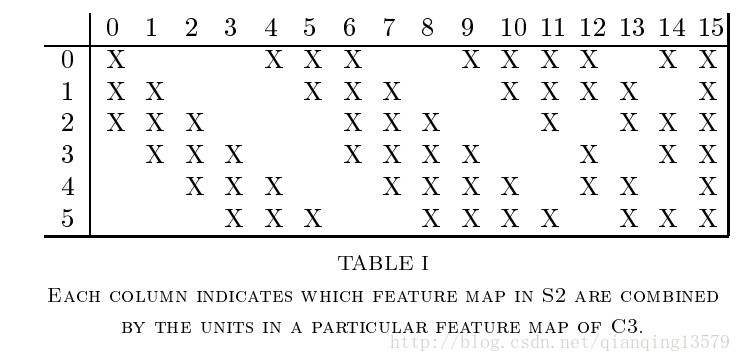
- 卷积可训练参数:C3采用了不完全连接的方式,第0个feature map与上一层的第0,1,2个feature map连接,其他的具体连接方式参照上图[2],有(5x5x3+1)x6 + (5x5x4 + 1) x 3 + (5x5x4 +1)x6 + (5x5x6+1)x1 = 1516个训练参数
- 连接数:1516x10x10=151600个
- S4(10x10x16 => 5x5x16)
采用与S2相同的结构。
- 卷积可训练参数:(1+1)*16=32
- 连接数:(5*5*16)*(2*2+1)=2000
- C5/F5(5*5*15 => 120)
因为输入尺寸已经是5x5,这里采用5x5卷积核,所以跟全连接没有区别,输出为120个logits。
- 卷积可训练参数/连接数:(5*5*16+1)*120=48120
- F6(120 => 84)
输入尺寸为120,输出为84
- 参数/连接数:(120+1)*84=10164
- F7(84 => 10)
原文中通过RBF方法来计算欧氏距离,细节详见论文,本文采用了softmax分类。
CNN三大思想:
CNN网络通过稀疏连接、权值共享、下采样等方式,来解决全连接神经网络中参数爆炸和过度拟合问题。
- 感受野(receptive field)/稀疏连接
特征图中的一个特征点在上一层特征图中的映射区域叫做感受野。特征图中的某个特征点的值只与上层特征图中的感受野相关,与剩余的其他任何特征点都无关。
- 权值共享
相比于全连接,可有效减少因为层级增加导致的参数量爆炸问题。
- 下采样
卷积层其实就是特征提取器,在最开始的层级获取的是特征细节,比如横向或者竖向的特征,随着层级的加深和特征图的增加,下采样能有效较小输入特征图的分辨率,能避免因为精确的细节特征对训练结果的影响,从而使得CNN善于捕捉平移不变,具有更强的鲁棒性。
读取MNIST数据集
MNIST数据集共有60000个训练数据,10000个验证数据,可在[1]网站下载,是以大端存储的二进制格式文件,训练图像数据格式:
TRAINING SET LABEL FILE (train-labels-idx1-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 60000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
........
xxxx unsigned byte ?? label
训练标签数据格式:
[offset] [type] [value] [description]
0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 60000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
........
xxxx unsigned byte ?? label
验证图像数据格式和标签格式与训练的一致,这里运用python struct库来读取文件并返回数据尺寸和numpy array格式数据。具体python代码如下:
#readMNIST.py
#encoding:utf-8
import numpy as np
import struct
import matplotlib.pyplot as plt
from skimage import transform
#读取mnist images数据集
def read_mnist_image_data(file_name):
file = open(file_name,'rb')
buff = file.read()#一次性读取全部数据
header_format = '>IIII'
#偏移量
buf_pointer = 0
#图片大小尺寸信息
magic_number=0
number_of_images = 0
number_of_rows = 0
number_of_columns = 0
#读取images数据
magic_number,number_of_images ,number_of_rows ,number_of_columns = struct.unpack_from(header_format,buff,buf_pointer)
print("magic_number:%d,number_of_images:%d,number_of_rows:%d,number_of_columns:%d"%(magic_number,number_of_images,number_of_rows,number_of_columns))
buf_pointer += struct.calcsize(header_format)
images = []#图片数据
image_byte_size = number_of_rows * number_of_columns
date_format = ">%dB"%image_byte_size
for idx in range(number_of_images):
#for idx in range(1):
image = struct.unpack_from(date_format ,buff,buf_pointer)
#print(image)
#偏移
buf_pointer += struct.calcsize(date_format )
image = np.array(image)
#print(image.shape)
#print(image)
#image = transform.resize(image,(number_of_rows,number_of_columns))
image = image.reshape(number_of_rows, number_of_columns,1)
#print(image.shape)
#print(image)
#显示图片
#fig = plt.figure()
#plt.imshow(image,cmap='binary')
#plt.show()
images.append(image)
file.close()
#返回图片数据
return number_of_images ,number_of_rows ,number_of_columns,np.asarray(images,np.ubyte)
#读取mnist label数据集
def read_mnist_label_data(file_name):
file = open(file_name,'rb')
buff = file.read()#一次性读取全部数据
header_format = ''
#偏移量
buf_pointer = 0
#图片大小尺寸信息
magic_number=0
number_of_labels = 0
#读取label数据
header_format = '>II'
magic_number,number_of_labels = struct.unpack_from(header_format,buff,buf_pointer)
print("magic_number:%d,number_of_labels:%d"%(magic_number,number_of_labels))
buf_pointer += struct.calcsize(header_format)
labels = []#label数据
date_format = ">B"
for idx in range(number_of_labels):
#for idx in range(10):
label = struct.unpack_from(date_format ,buff,buf_pointer)
#偏移
buf_pointer += struct.calcsize(date_format )
#输出label(因为label输出是tuple)
#print(label[0])
labels.append(label[0])
file.close()
return number_of_labels ,np.asarray(labels,np.ubyte)
基于tensorflow 1.0.0实现LeNet-5
config.py,主要用于配置参数,如train和test的比例(ratio),是训练模型还是直接使用已经训练好的模型(isTrain)。
#config.py
#coding:utf-8
#tensorflow 1.0.0
#是否训练
isTrain = False
#train vs. test ratio
ratio=0.8
#训练集数据
train_images_file = "./mnist-database/train-images-idx3-ubyte"
train_labels_file = "./mnist-database/train-labels-idx1-ubyte"
#测试集数据
valid_images_file = "./mnist-database/t10k-images-idx3-ubyte"
valid_labels_file = "./mnist-database/t10k-labels-idx1-ubyte"
#checkpoint
checkpoint_dir = './trained_model/'
model_name = 'model-mnist.ckpt'
运用tensorflow实现的LeNet-5源码如下,与原论文有区别的主要在:
(1)未使用平均池化层,而是使用最流行的最大池化层;
(2)S2和C3采用CNN的完全连接方式;
(3)激活函数使用最流行的relu而不是sigmoid,可以加快收敛速度;
(4)输出未采用论文中分类函数,使用的是稀疏softmax交叉损失熵函数tf.losses.sparse_softmax_cross_entropy,当分类问题只有一个正确答案时,可以使用这个函数来加速交叉熵的计算,这个函数的第一个参数是不包含softmax层的前向传播结果,第二个是训练数据的正确答案。
#mnist_Lenet-5.py
#encoding:utf-8
import tensorflow as tf
import numpy as np
from readMNIST import *
from config import * #mnist数据集尺寸
w=28
h=28
c=1 #读取训练数据images和labels
#读取训练集图片数据
train_images_nums,train_images_rows,train_images_cols,train_images = read_mnist_image_data(train_images_file)
#print(train_images.shape)
#print(train_images)
#读取训练集数据label数据
train_labels_nums,train_labels = read_mnist_label_data(train_labels_file)
#print(train_labels.shape)
#print(train_labels)
#读取验证集图片数据
#valid_images_nums,valid_images_rows,valid_images_cols,valid_images = read_mnist_image_data(valid_images_file)
#print(valid_images)
#读取验证集数据label数据
#valid_labels_nums,valid_labels = read_mnist_label_data(valid_labels_file)
#print(valid_labels) #打乱顺序
#训练数据
data = train_images
label = train_labels
nums = train_images_nums
#验证数据
#data = valid_images
#label = valid_labels
#nums = valid_label_nums
if isTrain:
arr=np.arange(nums)
#print(arr)
np.random.shuffle(arr)
print(arr[0])
data=data[arr]
label=label[arr]
x_train = []
y_train = []
x_val = []
y_val = []
#将所有数据分为训练集和验证集
#按照经验,8成为训练集,2成为验证集
if isTrain:
s=np.int(nums*ratio)
#训练集
x_train=data[:s]
y_train=label[:s]
#验证集
x_val=data[s:]
y_val=label[s:]
else:
x_train = data #-----------------构建网络----------------------
#占位符
x=tf.placeholder(tf.float32,shape=[None,w,h,c],name='x')
y_=tf.placeholder(tf.int32,shape=[None,],name='y_') #第一层:卷积层(28-->28)
conv1=tf.layers.conv2d(
inputs=x,
filters=6,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01))
#第二层:最大池化层(28-->14)
pool1=tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2) #第三层:卷积层(14->10)
conv2=tf.layers.conv2d(
inputs=pool1,
filters=16,
kernel_size=[5, 5],
padding="valid",
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01))
#第四层:最大池化层(10-->5)
pool2=tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2) #在输入全连接层前,先拍成一维向量
re1 = tf.reshape(pool2, [-1, 5 * 5 * 16]) #全连接层,只有全连接层才会进行L1和L2正则化
dense1 = tf.layers.dense(inputs=re1,
units=120,
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.contrib.layers.l2_regularizer(0.003))
dense2= tf.layers.dense(inputs=dense1,
units=84,
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.contrib.layers.l2_regularizer(0.003))
logits= tf.layers.dense(inputs=dense2,
units=10,
activation=None,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.contrib.layers.l2_regularizer(0.003))
#---------------------------网络结束--------------------------- loss=tf.losses.sparse_softmax_cross_entropy(labels=y_,logits=logits)
train_op=tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
correct_prediction = tf.equal(tf.cast(tf.argmax(logits,1),tf.int32), y_)
acc= tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) #定义一个函数,按批次取数据
def minibatches(inputs=None, targets=None, batch_size=None, shuffle=False):
assert len(inputs) == len(targets)
if shuffle:
indices = np.arange(len(inputs))
np.random.shuffle(indices)
for start_idx in range(0, len(inputs) - batch_size + 1, batch_size):
if shuffle:
excerpt = indices[start_idx:start_idx + batch_size]
else:
excerpt = slice(start_idx, start_idx + batch_size)
yield inputs[excerpt], targets[excerpt] #训练和测试数据,可将n_epoch设置更大一些 n_epoch=20
batch_size=64 sess=tf.InteractiveSession()
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer()) if isTrain:
for epoch in range(n_epoch):
#start_time = time.time()
print("epoch %d"%epoch)
#training
train_loss, train_acc, n_batch = 0, 0, 0
for x_train_a, y_train_a in minibatches(x_train, y_train, batch_size, shuffle=True):
#print(x_train_a)
_,err,ac=sess.run([train_op,loss,acc], feed_dict={x: x_train_a, y_: y_train_a})
train_loss += err; train_acc += ac; n_batch += 1
print(" train loss: %f" % (train_loss/ n_batch))
print(" train acc: %f" % (train_acc/ n_batch))
print("\n")
if epoch == n_epoch - 1:
print("Saving trained mode as ckpt format!")
save_path = saver.save(sess,checkpoint_dir+model_name) #validation
val_loss, val_acc, n_batch = 0, 0, 0
for x_val_a, y_val_a in minibatches(x_val, y_val, batch_size, shuffle=False):
err, ac = sess.run([loss,acc], feed_dict={x: x_val_a, y_: y_val_a})
val_loss += err; val_acc += ac; n_batch += 1
print(" validation loss: %f" % (val_loss/ n_batch))
print(" validation acc: %f" % (val_acc/ n_batch))
print("\n") else:
class_begin_idx = 0
class_end_idx = 0
saver.restore(sess, checkpoint_dir+model_name)
#print(label[0:20])
result = sess.run(logits,feed_dict={x:data})
class_index = np.argmax(result,axis=1)
#print(result)
#print(train_labels)
#class_result = []
correct_nums = 0
cnt_idx = 0
#print("The number is:\n")
#predict_result = []
for idx in class_index:
if idx == label[cnt_idx]:#softmax的标签为0开始的整数,所以这里数字0-9刚好对应了softmax的0-9层输出
correct_nums += 1
#predict_result.append(idx) #将错误图片显示出来
#else:
#fig = plt.figure()
#plt.imshow(data[class_begin_idx+error_idx ],cmap='binary')
#plt.show()
cnt_idx += 1
correct_pro = correct_nums / (len(result)*1.0)
#print(predict_result[0:20])
print("Input number of mnist set is %d, correct num:%d, correct proportion:%f"%(len(result), correct_nums,correct_pro))
print("\n")
sess.close()
最终训练结果,在train准确率99.54%,valid准确率98.53%。
Refrence
[1] THE MNIST DATABASE:http://yann.lecun.com/exdb/mnist/
[2] [LeCun et al., 1998]: Gradient-Based Learning Applied to Document Recognition
[3] Md Zahangir Alom et al.,2018: The History Began from AlexNet: A Comprehensive Survey on Deep Learning Approaches
LeNet-5识别MINIST数据集的更多相关文章
- 用CNN及MLP等方法识别minist数据集
用CNN及MLP等方法识别minist数据集 2017年02月13日 21:13:09 hnsywangxin 阅读数:1124更多 个人分类: 深度学习.keras.tensorflow.cnn ...
- SGD与Adam识别MNIST数据集
几种常见的优化函数比较:https://blog.csdn.net/w113691/article/details/82631097 ''' 基于Adam识别MNIST数据集 ''' import t ...
- Python实现bp神经网络识别MNIST数据集
title: "Python实现bp神经网络识别MNIST数据集" date: 2018-06-18T14:01:49+08:00 tags: [""] cat ...
- RNN入门(一)识别MNIST数据集
RNN介绍 在读本文之前,读者应该对全连接神经网络(Fully Connected Neural Network, FCNN)和卷积神经网络( Convolutional Neural Netwo ...
- 单向LSTM笔记, LSTM做minist数据集分类
单向LSTM笔记, LSTM做minist数据集分类 先介绍下torch.nn.LSTM()这个API 1.input_size: 每一个时步(time_step)输入到lstm单元的维度.(实际输入 ...
- BP算法在minist数据集上的简单实现
BP算法在minist上的简单实现 数据:http://yann.lecun.com/exdb/mnist/ 参考:blog,blog2,blog3,tensorflow 推导:http://www. ...
- TensorFlow笔记三:从Minist数据集出发 两种经典训练方法
Minist数据集:MNIST_data 包含四个数据文件 一.方法一:经典方法 tf.matmul(X,w)+b import tensorflow as tf import numpy as np ...
- 吴裕雄 python 神经网络TensorFlow实现LeNet模型处理手写数字识别MNIST数据集
import tensorflow as tf tf.reset_default_graph() # 配置神经网络的参数 INPUT_NODE = 784 OUTPUT_NODE = 10 IMAGE ...
- Tensorflow机器学习入门——MINIST数据集识别
参考网站:http://www.tensorfly.cn/tfdoc/tutorials/mnist_beginners.html #自动下载并加载数据 from tensorflow.example ...
随机推荐
- ubuntu网络设置及遇到问题
1.在ubuntu下面显示有线网络设备未托管 解决:在ubuntu下面输入:sudo gedit /etc/NetworkManager/nm-system-settings.conf然后将里面 ...
- 用Node.JS+MongoDB搭建个人博客(model目录)(三)
model目录主要是封装一些经常使用的方法,便于使用. setting.js文件: 很简单,就单单封装了一个url作为公用,以后改就方便改了. md5.js(不推荐用): db.js文件: db.js ...
- R语言︱机器学习模型评估方案(以随机森林算法为例)
笔者寄语:本文中大多内容来自<数据挖掘之道>,本文为读书笔记.在刚刚接触机器学习的时候,觉得在监督学习之后,做一个混淆矩阵就已经足够,但是完整的机器学习解决方案并不会如此草率.需要完整的评 ...
- apache和tomcat公用80端口
原理主要利用apache的代理. 第一步:修改apache的httpd.conf配置文件. 首先,要让apache支持转发也就是做tomcat的代理那么就要先启用apache的代理模块.首先我在Apa ...
- MyEclipse10+Flash Builder4+BlazeDS+Tomcat7配置J2EE Web项目报错(一)
1.错误描述 usage: java org.apache.catalina.startup.Catalina [ -config {pathname} ] [ -nonaming ] { -help ...
- python爬虫--爬取某网站电影下载地址
前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索. 友情提示:本代码用 ...
- Coursera DeepLearning.ai Logistic Regression逻辑回归总结
既<Machine Learning>课程后,Andrew Ng又推出了新一系列的课程<DeepLearning.ai>,注册了一下可以试听7天.之后每个月要$49,想想还是有 ...
- RobotFramework自动化测试框架的基础关键字(三)
1.1.1 如何定义一个字典 此处我们说的字典,其实就等同于python语言中的字典,和列表一样,字典也是python语言中非常常用的一种数据结构,也类似于Java 语言中的Map. 在 ...
- 【BZOJ1997】Planar(2-sat)
[BZOJ1997]Planar(2-sat) 题面 BZOJ 题解 很久没做过\(2-sat\)了 今天一见,很果断的就来切 这题不难呀 但是有个玄学问题: 平面图的性质:边数\(m\)的最大值为\ ...
- [Lugu3380]【模板】二逼平衡树(树套树)
题面戳我 您需要写一种数据结构来维护一个有序数列,其中需要提供以下操作: 1.查询k在区间内的排名 2.查询区间内排名为k的值 3.修改某一位值上的数值 4.查询k在区间内的前驱(前驱定义为严格小于x ...