MySQL 笔记整理(16) --“order by”是怎么工作的?
笔记记录自林晓斌(丁奇)老师的《MySQL实战45讲》
(本篇内图片均来自丁奇老师的讲解,如有侵权,请联系我删除)
16) --“order by”是怎么工作的?
在林老师的课程中,第15讲是前面问题的答疑,我打算最后将答疑问题统一整理出来,所以就继续这些内容的笔记了。
全字段排序:
假设有一个表是这么设计的:
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`city` varchar(16) NOT NULL,
`name` varchar(16) NOT NULL,
`age` int(11) NOT NULL,
`addr` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `city` (`city`)
) ENGINE=InnoDB;
这时,你的SQL语句可以这么写:
select city,name,age from t where city='杭州' order by name limit 1000;
如果我们使用explain命令来看这个语句的情况会发现,extra这个字段中的"Using filesort"表示的就是需要排序,MySQL会给每个线程分配一块内存用于排序,称为sort buffer.我们知道,非主键索引其实存储的是对应的主键id。因此上述语句的执行流程大致如下:
- 初始化sort_buffer,确定放入name,city,age三个字段。
- 从索引city找到第一个满足city=‘杭州’条件的主键id。
- 到主键id索引取出整行,取name,city,age三个字段的值,存入sort_buffer中
- 从索引city取下一个记录的主键id;
- 重复步骤3,4直到city的值不满足查询条件为止。
- 对sort_buffer中的数据按照字段name做快速排序。
- 按照排序结果取前1000行返回给客户端。
我们暂且把这个排序过程,称为全字段排序,执行流程的示意图如下:
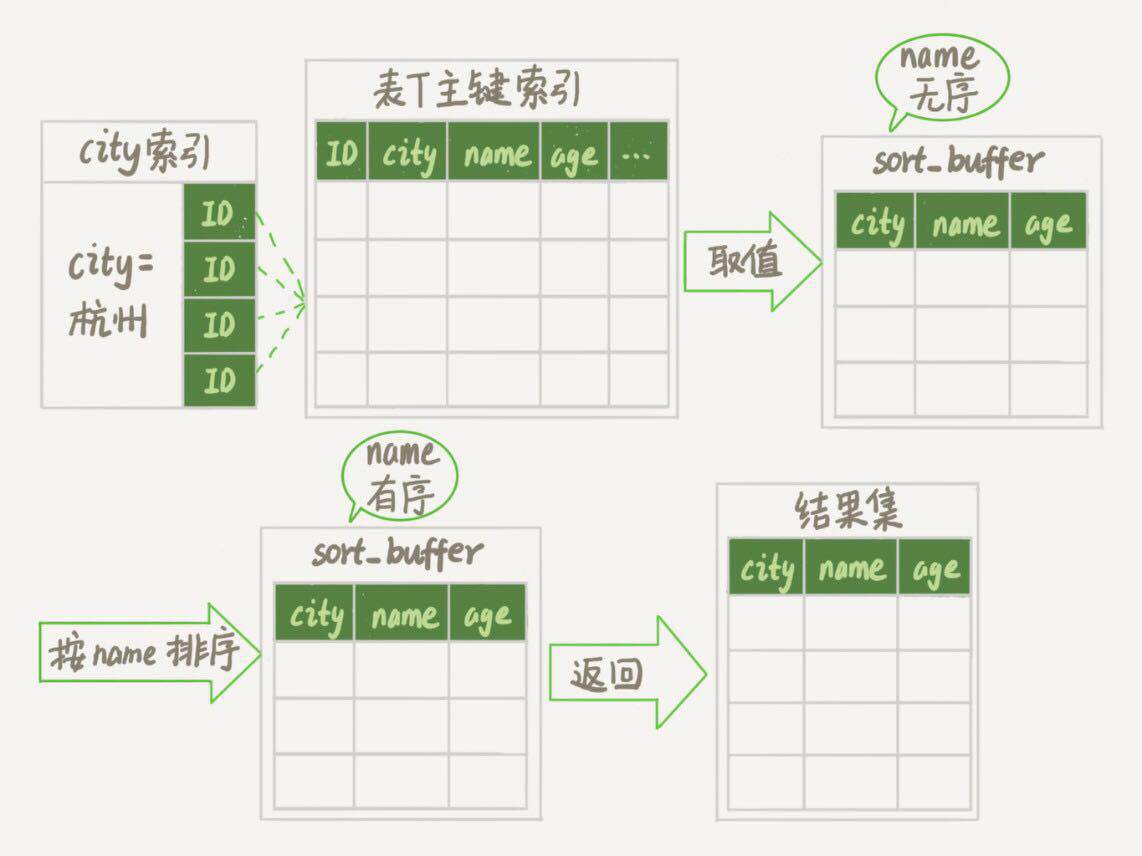
其中的“按name排序”这个动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数sort_buffer_size。这个参数的含义是MySQL为排序开辟的内存(sort buffer)大小。如果要排序的数据量小于sort_buffer_size,排序就在内存中完成。但如果排序量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。而关于外部排序,需要知道的是:外部排序一般使用归并算法进行排序。可以这么简单理解,MySQL将需要排序的数据分成N份,每一份单独排序后存在这些临时文件中。然后把这N个有序文件再合并成一个有序的大文件。如果sort_buffer_size越小,需要分成的份数就越多,number_of_tmp_files的值就越大。
RowId排序:
上面这个过程中,排序操作是在sort_buffer和临时文件中执行的。但这个算法有一个问题,就是如果查询要返回的字段很多,那么sort_buffer里面要放的字段就会很多,这样能放得下的行数就会很少,要分成很多个临时文件,排序的性能会很差。那么,如果MySQL认为排序的单行长度太大会怎么做呢?
我们先来修改一个参数的值。SET max_length_for_sort_data=16.这个参数是MySQL中专门用于控制排序的行数据的长度的一个参数。它的意思是,如果单行的长度超过这个值,MySQL就认为单行太大,要换一个排序算法。上述建表中可以看到,city,name,age的总长度为36,大于我们刚刚设置的16,我们再来看看计算过程有什么变化。
新的方式中要放入sort_buffer的字段由原来的name,city,age变为了要排序的列(name)和主键Id.很明显,这样排序的结果是不包含city和age字段的,因此不能直接返回。所以整个流程就变为:
- 初始化sort_buffer,确定放入两个字段,name和id
- 从索引city找到一个满足city='杭州'条件的主键id
- 到主键id索引取出整行,取name,id这两个字段,存入sort_buffer中;
- 从索引city取下一个记录的主键id
- 重复步骤3,4,直到不满足city='杭州'条件为止。
- 对sort_buffer中的数据按照字段name进行排序。
- 遍历排序结果,取前1000行,并按照id的值回到原表中取出city,name和age三个字段返回给客户端。
全字段排序 VS rowid排序:
如果MySQL担心排序内存太小,会影响排序效率,才会采用rowid排序算法,这样排序过程中一次可以排序更多行,但是需要回到原表去取数据。
如果MySQL认为内存足够大,会优先选择全字段排序,把需要的字段都放到sort_buffer中,这样排序后就会直接从内存里面返回查询结果了,不用再回到原表去取数据。这也体现了MySQL的一个设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。对于InnoDB表来说,rowid排序会要求会标多造成磁盘读,因此不会被优先选择。排序是一个成本比较高的操作,其实,并不是所有的order by语句,都需要排序操作的。从上面分析的执行过程,我们可以看到,MySQL之所以需要临时表来进行排序,原因是原来的数据都是无序的。(好像有点废话~~)。如果能保证从city这个索引上取出来的行,天然就是按照name递增来排序的,就可以不用排序了。
因此,我们可以在这个表上创建一个city和name的联合索引,对应的sql语句是:
alter table t add index city_user(city,name);
这个索引除了满足city=‘杭州’的数据会聚集在一起,还额外满足了一个条件。那就是如果一组city='杭州'的记录,那么就可以保证这些记录都是按name继续进行排序的。所以语句执行流程就变为:
- 从索引city_user找到第一个满足条件city=‘杭州’的主键id
- 到主键id索引去除整行,取name,city,age三个字段的值,作为结果集的一部分直接返回。
- 从索引city_user取下一个记录
- 重复步骤2,3直到查到第1000条记录或是不满足city=‘杭州’为止。
额外补充一点,假设city=‘杭州’的数据有4000条,当你用explain命令去查看上面几次的排序语句时会发现,除city_user这个索引外,其他的扫描行数都为4000。因为要获取全部的city=‘杭州’之后才能按照name排序取前一行。而如果使用了city_user索引,则只需要扫描1000行就能返回结果。
那么,还有没有可能再快一点呢?答案是肯定的。我们之前有介绍过“覆盖索引”.如果你要查询的字段完全包含在覆盖索引之内,就不需要再返回主键id索引中取出全部的数据来了。即减少了回表,具体流程就不写出来了。
上期问题:
在上期关于count计数的讨论中,我们用了事务来确保数据的精确性。由于事务可以保证中间结果不被别的事务读到,因此修改计数值和插入新的记录的顺序是不影响逻辑结果的。但是,从并发系统性能的角度考虑,你觉得在这个事务序列里,应该先插入操作记录,还是先更新计数表呢?
关于上期的内容,具体可以点击这里查看上一篇。
用一个计数表记录一个业务表的总行数,在往业务表插入数据的时候,需要给计数值加1.逻辑上实现是启动一个事务,执行两个语句:
- insert into 数据表。
- update 计数表,计数值加1.
应该怎么安排这两个语句的顺序呢?并发系统性能的角度考虑,应该先插入操作记录,再更新计数表。因为更新计数表涉及到行锁的竞争,先插入再更新能最大程度地减少事务之间的锁等待,提升并发度。
关于每篇最后这个问题,我打算更换一下格式,以后整理几篇文章之后再单独出一篇问题的总结,也方便阅读。因此这篇就先不留下问题了。
MySQL 笔记整理(16) --“order by”是怎么工作的?的更多相关文章
- 最全mysql笔记整理
mysql笔记整理 作者:python技术人 博客:https://www.cnblogs.com/lpdeboke Windows服务 -- 启动MySQL net start mysql -- 创 ...
- 16 | “order by”是怎么工作的? 学习记录
<MySQL实战45讲>16 | “order by”是怎么工作的? 学习记录http://naotu.baidu.com/file/0be0e0acdf751def1c0ce66215e ...
- MySQL 笔记整理(1) --基础架构,一条SQL查询语句如何执行
最近在学习林晓斌(丁奇)老师的<MySQL实战45讲>,受益匪浅,做一些笔记整理一下,帮助学习.如果有小伙伴感兴趣的话推荐原版课程,很不错. 1) --基础架构,一条SQL查询语句如何执行 ...
- MySQL 笔记整理(10) --MySQL为什么有时会选错索引?
笔记记录自林晓斌(丁奇)老师的<MySQL实战45讲> (本篇内图片均来自丁奇老师的讲解,如有侵权,请联系我删除) 10) --MySQL为什么有时会选错索引? MySQL中的一张表上可以 ...
- MySQL 笔记整理(5) --深入浅出索引(下)
笔记记录自林晓斌(丁奇)老师的<MySQL实战45讲> 5) --深入浅出索引(下) 这次的笔记从一个简单的查询开始: 建表语句是这样的 mysql> create table T ...
- MySQL 笔记整理(18) --为什么这些SQL语句逻辑相同,性能却差异巨大?
笔记记录自林晓斌(丁奇)老师的<MySQL实战45讲> (本篇内图片均来自丁奇老师的讲解,如有侵权,请联系我删除) 18) --为什么这些SQL语句逻辑相同,性能却差异巨大? 本篇我们以三 ...
- MySQL 笔记整理(17) --如何正确地显示随机消息?
笔记记录自林晓斌(丁奇)老师的<MySQL实战45讲> (本篇内图片均来自丁奇老师的讲解,如有侵权,请联系我删除) 17) --如何正确地显示随机消息? 如果有这么一个英语单词表,需要每次 ...
- MySQL 笔记整理(14) --count(*)这么慢,我该怎么办?
笔记记录自林晓斌(丁奇)老师的<MySQL实战45讲> (本篇内图片均来自丁奇老师的讲解,如有侵权,请联系我删除) 14) --count(*)这么慢,我该怎么办? 有时你会发现,随着系统 ...
- MySQL 笔记整理(6) --全局锁和表锁:给表加个字段怎么有这么多阻碍
笔记记录自林晓斌(丁奇)老师的<MySQL实战45讲> 6) --全局锁和表锁:给表加个字段怎么有这么多阻碍 数据库锁设计的初衷是处理并发问题.作为多用户共享的资源,当出现并发访问的时候, ...
随机推荐
- mysql输入中文出现ERROR 1366
MySQL输入中文出现如下错误: ERROR 1366: 1366: Incorrect string value: '\xE6\xB0\xB4\xE7\x94\xB5...' for column ...
- eclipse使用Git基本流程
1.安装GIT 2.Git的使用 ①下载代码到eclipse(右键导入工程) ②提交代码到本地(commit) ③更新代码到本地(pull) ④当本地出现冲突时,解决冲突,没有冲突当然就最好啦 ⑤提交 ...
- Appscan 工具快速上手教程
1.appscan扫描 (1)白盒扫描=静态扫描,扫描源代码.(2)动态扫描=黑盒扫描,用工具来模拟黑客的攻击,查看应用层的响应.产品内部会有大量受攻击的库,当我们把一个模拟攻击发给我们的应用的时 ...
- 理解线程池到走进dubbo源码
引言 合理利用线程池能够带来三个好处. 第一:降低资源消耗.通过重复利用已创建的线程降低线程创建和销毁造成的消耗. 第二:提高响应速度.当任务到达时,任务可以不需要等到线程创建就能立即执行. ...
- asp.net core系列 46 Identity介绍
一. Identity 介绍 ASP.NET Core Identity是一个会员系统,可为ASP.NET Core应用程序添加登录功能.可以使用SQL Server数据库配置身份以存储用户名,密码和 ...
- 学习 JavaScript (七) 内存问题
内存问题是 JavaScript 比较底层的东西,依葫芦画瓢学会了怎么使用变量,但是对于内存的概念依然模糊,今天让我们一起来了解一下内存在这门语言是怎么样的存在. 内存在不同类型的数值面前表现有很大的 ...
- 简述Java变量和强制转换类型
简述Java变量和强制转换类型 java变量 1. java变量 变量:顾名思义,就是在java执行程序过程中可以发生改变的量,就好比方程式中的未知数X一样. 变量的内存分配过程 int a ; // ...
- java技术栈范畴
基础 进阶 数据 安全
- Java面向接口编程,低耦合高内聚的设计哲学
接口体现的是一种规范和实现分离的设计哲学,充分利用接口可以极大的降低程序中各个模块之间的耦合,提高系统的可维护性以及可扩展性. 因此,很多的软件架构设计理念都倡导"面向接口编程"而 ...
- 好看又能打的CRM系统大比拼:Salesforce, SugarCRM, Odoo等
介绍 今天的CRM市场提供了大量的解决方案和软件替代品.有些适合大型企业(通常需要内部托管),而其他企业则更多地应用于SME的需求(通常使用云托管解决方案). 在CRM解决方案方面,提供商必须调整其产 ...