【并发编程】Future模式及JDK中的实现
1.1、Future模式是什么
先简单举个例子介绍,当我们平时写一个函数,函数里的语句一行行同步执行,如果某一行执行很慢,程序就必须等待,直到执行结束才返回结果;但有时我们可能并不急着需要其中某行的执行结果,想让被调用者立即返回。比如小明在某网站上成功创建了一个账号,创建完账号后会有邮件通知,如果在邮件通知时因某种原因耗时很久(此时账号已成功创建),使用传统同步执行的方式那就要等完这个时间才会有创建成功的结果返回到前端,但此时账号创建成功后我们并不需要立即关心邮件发送成功了没,此时就可以使用Future模式,让安在后台慢慢处理这个请求,对于调用者来说,则可以先处理一些其他任务,在真正需要数据的场合(比如某时想要知道邮件发送是否成功)再去尝试获取需要的数据。
使用Future模式,获取数据的时候可能无法立即得到需要的数据。而是先拿到一个包装,可以在需要的时候再去get获取需要的数据。
1.2、Future模式与传统模式的区别
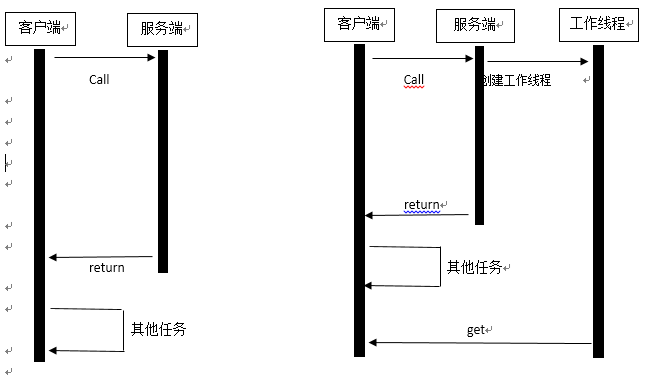
先看看请求返回的时序图,明显传统的模式是串行同步执行的,在遇到耗时操作的时候只能等待。反观Future模式,发起一个耗时操作后,函数会立刻返回,并不会阻塞客户端线程。所以在执行实际耗时操作时候客户端无需等待,可以做其他事情,直到需要的时候再向工作线程获取结果。
2.1、动手实现简易Future模式
下面的DataFuture类只是一个包装类,创建它时无需阻塞等待。在工作线程准备好数据后使用setRealData方法将数据传入。客户端只要在真正需要数据时调用getRealData方法即可,如果此时数据已准备好则立即返回,否则getRealData方法就会等待,直到获取数据完成。
public class DataFuture<T> {
private T realData;
private boolean isOK = false;
public synchronized T getRealData() {
while (!isOK) {
try {
// 数据未准备好则等待
wait();
} catch (Exception e) {
e.printStackTrace();
}
}
return realData;
}
public synchronized void setRealData(T data) {
isOK = true;
realData = data;
notifyAll();
}
}
下面实现一服务端,客户端向服务端请求数据时,服务端并不会立刻去加载真正数据,只是创建一个DataFuture,创建子线程去加载真正数据,服务端直接返回DataFuture即可。
public class Server {
public DataFuture<String> getData() {
final DataFuture<String> data = new DataFuture<>();
Executors.newSingleThreadExecutor().execute(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
data.setRealData("最终数据");
}
});
return data;
}
}
最终客户端调用 代码如下:
long start = System.currentTimeMillis();
Server server = new Server();
DataFuture<String> dataFuture = server.getData(); try {
// 先执行其他操作
Thread.sleep(5000);
// 模拟耗时...
} catch (InterruptedException e) {
e.printStackTrace();
} System.out.print("结果数据:" + dataFuture.getRealData());
System.out.println("耗时: " + (System.currentTimeMillis() - start));
结果:
结果数据:最终数据
耗时: 5021
执行最终数据耗时都在5秒左右,如果串行执行的话就是10秒左右。
2.2、JDK中的Future与FutureTask
先来看看Future接口源码:
public interface Future<V> {
/**
* 用来取消任务,取消成功则返回true,取消失败则返回false。
* mayInterruptIfRunning参数表示是否允许取消正在执行却没有执行完毕的任务,设为true,则表示可以取消正在执行过程中的任务。
* 如果任务已完成,则无论mayInterruptIfRunning为true还是false,此方法都返回false,即如果取消已经完成的任务会返回false;
* 如果任务正在执行,若mayInterruptIfRunning设置为true,则返回true,若mayInterruptIfRunning设置为false,则返回false;
* 如果任务还没有执行,则无论mayInterruptIfRunning为true还是false,肯定返回true。
*/
boolean cancel(boolean mayInterruptIfRunning);
/**
* 表示任务是否被取消成功,如果在任务正常完成前被取消成功,则返回true
*/
boolean isCancelled();
/**
* 表示任务是否已经完成,若任务完成,则返回true
*/
boolean isDone();
/**
* 获取执行结果,如果最终结果还没得出该方法会产生阻塞,直到任务执行完毕返回结果
*/
V get() throws InterruptedException, ExecutionException;
/**
* 获取执行结果,如果在指定时间内,还没获取到结果,则抛出TimeoutException
*/
V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
}
从上面源码可看出Future就是对于Runnable或Callable任务的执行进行查询、中断任务、获取结果。下面就以一个计算1到1亿的和为例子,看使用传统方式和使用Future耗时差多少。先看传统方式代码:
public class FutureTest {
public static void main(String[] args) {
long start = System.currentTimeMillis();
List<Integer> retList = new ArrayList<>();
// 计算1000次1至1亿的和
for (int i = 0; i < 1000; i++) {
retList.add(Calc.cal(100000000));
}
System.out.println("耗时: " + (System.currentTimeMillis() - start));
for (int i = 0; i < 1000; i++) {
try {
Integer result = retList.get(i);
System.out.println("第" + i + "个结果: " + result);
} catch (Exception e) {
}
}
System.out.println("耗时: " + (System.currentTimeMillis() - start));
}
public static class Calc implements Callable<Integer> {
@Override
public Integer call() throws Exception {
return cal(10000);
}
public static int cal (int num) {
int sum = 0;
for (int i = 0; i < num; i++) {
sum += i;
}
return sum;
}
}
}
执行结果(耗时40+秒):
耗时: 43659
第0个结果: 887459712
第1个结果: 887459712
第2个结果: 887459712
...
第999个结果: 887459712
耗时: 43688
再来看看使用Future模式下程序:
public class FutureTest {
public static void main(String[] args) {
long start = System.currentTimeMillis();
ExecutorService executorService = Executors.newCachedThreadPool();
List<Future<Integer>> futureList = new ArrayList<>();
// 计算1000次1至1亿的和
for (int i = 0; i < 1000; i++) {
// 调度执行
futureList.add(executorService.submit(new Calc()));
}
System.out.println("耗时: " + (System.currentTimeMillis() - start));
for (int i = 0; i < 1000; i++) {
try {
Integer result = futureList.get(i).get();
System.out.println("第" + i + "个结果: " + result);
} catch (InterruptedException | ExecutionException e) {
}
}
System.out.println("耗时: " + (System.currentTimeMillis() - start));
}
public static class Calc implements Callable<Integer> {
@Override
public Integer call() throws Exception {
return cal(100000000);
}
public static int cal (int num) {
int sum = 0;
for (int i = 0; i < num; i++) {
sum += i;
}
return sum;
}
}
}
执行结果(耗时12+秒):
耗时: 12058
第0个结果: 887459712
第1个结果: 887459712
...
第999个结果: 887459712
耗时: 12405
可以看到,计算1000次1至1亿的和,使用Future模式并发执行最终的耗时比使用传统的方式快了30秒左右,使用Future模式的效率大大提高。
2.3、FutureTask
说完Future,Future因为是接口不能直接用来创建对象,就有了下面的FutureTask。
先看看FutureTask的实现:
public class FutureTask<V> implements RunnableFuture<V>
可以看到FutureTask类实现了RunnableFuture接口,接着看RunnableFuture接口源码:
public interface RunnableFuture<V> extends Runnable, Future<V> {
/**
* Sets this Future to the result of its computation
* unless it has been cancelled.
*/
void run();
}
可以看到RunnableFuture接口继承了Runnable接口和Future接口,也就是说其实FutureTask既可以作为Runnable被线程执行,也可以作为Future得到Callable的返回值。
看下面FutureTask的两个构造方法,可以看出就是为这两个操作准备的。
public FutureTask(Callable<V> var1) {
if (var1 == null) {
throw new NullPointerException();
} else {
this.callable = var1;
this.state = 0;
}
}
public FutureTask(Runnable var1, V var2) {
this.callable = Executors.callable(var1, var2);
this.state = 0;
}
FutureTask使用实例:
public class FutureTest {
public static void main(String[] args) {
ExecutorService executor = Executors.newCachedThreadPool();
Calc task = new Calc();
FutureTask<Integer> futureTask = new FutureTask<Integer>(task);
executor.submit(futureTask);
executor.shutdown();
}
public static class Calc implements Callable<Integer> {
@Override
public Integer call() throws Exception {
return cal(100000000);
}
public static int cal (int num) {
int sum = 0;
for (int i = 0; i < num; i++) {
sum += i;
}
return sum;
}
}
}
2.4、Future不足之处
上面例子可以看到使用Future模式比传统模式效率明显提高了,使用Future一定程度上可以让一个线程池内的任务异步执行;但同时也有个明显的缺点:就是回调无法放到与任务不同的线程中执行,传统回调最大的问题就是不能将控制流分离到不同的事件处理器中。比如主线程要等各个异步执行线程返回的结果来做下一步操作,就必须阻塞在future.get()方法等待结果返回,这时其实又是同步了,如果遇到某个线程执行时间太长时,那情况就更糟了。
到Java8时引入了一个新的实现类CompletableFuture,弥补了上面的缺点,在下篇会讲解CompletableFuture的使用。
作者注:原文发表在公号(点击查看),定期分享IT互联网、金融等工作经验心得、人生感悟,欢迎订阅交流,目前就职阿里-移动事业部,需要大厂内推的也可到公号砸简历。(公众号ID:weknow619)

【并发编程】Future模式及JDK中的实现的更多相关文章
- java并发编程系列原理篇--JDK中的通信工具类Semaphore
前言 java多线程之间进行通信时,JDK主要提供了以下几种通信工具类.主要有Semaphore.CountDownLatch.CyclicBarrier.exchanger.Phaser这几个通讯类 ...
- 并发编程学习笔记(4)----jdk5中提供的原子类及Lock使用及原理
(1)jdk中原子类的使用: jdk5中提供了很多原子类,它会使变量的操作变成原子性的. 原子性:原子性指的是一个操作是不可中断的,即使是在多个线程一起操作的情况下,一个操作一旦开始,就不会被其他线程 ...
- 《 .NET并发编程实战》一书中的节流为什么不翻译成限流
有读者问,为什么< .NET并发编程实战>一书中的节流为什么不翻译成限流? 这个问题问得十分好!毕竟“限流”这个词名气很大,耳熟能详,知名度比“节流”大多了. 首先,节流的原词Thrott ...
- Java并发编程(十)-- Java中的锁
在学习或者使用Java的过程中进程会遇到各种各样的锁的概念:公平锁.非公平锁.自旋锁.可重入锁.偏向锁.轻量级锁.重量级锁.读写锁.互斥锁.死锁.活锁等,本文将简概的介绍一下各种锁. 公平锁和非公平锁 ...
- 并发编程-Future+callable+FutureTask 闭锁机制
项目中经常有些任务需要异步(提交到线程池中)去执行,而主线程往往需要知道异步执行产生的结果,这时我们要怎么做呢?用runnable是无法实现的,我们需要用callable实现. FutureTask ...
- Java并发编程(十一)-- Java中的锁详解
上一章我们已经简要的介绍了Java中的一些锁,本章我们就详细的来说说这些锁. synchronized锁 synchronized锁是什么? synchronized是Java的一个关键字,它能够将代 ...
- 并发编程(二)Java中的多线程
一.创建多线程 创建多线程有以下几种方法: 继承Thread,重写run方法 实现Runnable接口,重写run方法[无返回值] 实现Callable接口,重写call方法[有返回值] 继承Thre ...
- Java并发编程:Future接口、FutureTask类
在前面的文章中我们讲述了创建线程的2种方式,一种是直接继承Thread,另外一种就是实现Runnable接口. 这2种方式都有一个缺陷就是:在执行完任务之后无法获取执行结果. 如果需要获取执行结果,就 ...
- 《Java并发编程的艺术》--Java中的锁
No1: Lock接口 Lock lock = new ReentrantLock(); lock.lock(); try{ }finally{ lock.unlock(); } No2: 不要讲获取 ...
随机推荐
- 安卓开发笔记(三十一):shape标签下子类根结点的具体使用
在我的上一篇博文当中阐述了我们如何使用shape标签进行自定义控件,这里对shape控件的属性进行阐述,不知道如何使用这些属性的可以参见我的上一篇博文(自定义Button):https://www.c ...
- 实时监听input输入框value的变化:
HTML5 标准事件 oninput 和 IE 专属事件 onpropertychange 事件实时监听输入框value的变化 oninput 事件在用户输入时触发. 该事件在 <input&g ...
- 你可能不知道的jvm的类加载机制
引言:在java代码中,类型的加载.连接与初始化过程都是在程序运行期间完成的. 加载:查找并加载类的二进制数据(class文件加载到内存中) 连接:a 验证:确保被加载类的正确性. b准备:为类的静态 ...
- [区块链] 拜占庭将军问题 [BFT]
背景: 拜占庭将军问题很多人可能听过,但不知道具体是什么意思.那么究竟什么是拜占庭将军问题呢? 本文从最通俗的故事讲起,并对该问题进行抽象,并告诉大家拜占庭将军问题为什么在区块链领域作为一个重点研究问 ...
- SpringBoot从零单排 ------ 拦截器的使用
在项目开发中我们常常需要对请求进行验证,如登录校验.权限验证.防止重复提交等等,通过拦截器来过滤请求.自定义一个拦截器需要实现HandlerInterceptor接口.代码如下: import org ...
- Mybatis框架的简单运用
一.配置流程 1.流程示意图(通过XML映射文件实现): 2.流程: 2.1 导入包: 2.1.1 下载包 数据库驱动包(本文以MySQL为例):https://mvnrepository.com/a ...
- 关于JAVA中Byte类型的取值范围的推论(*零为正数,-128在计算机中的表示方法...)
先看一段推理<*一切都是在8个比特位的前提下,讨论二进制的符号位,溢出等等,才有意义*> +124:0111 1100 -124:1000 0100 +125:0111 1101 -125 ...
- 【Matlab&Mathematica】对三维空间上的点进行椭圆拟合
问题是这样:比如有一个地心惯性系的轨道,然后从轨道上取了几个点,问能不能根据这几个点把轨道还原了? 当然,如果知道轨道这几个点的速度的情况下,根据轨道六根数也是能计算轨道的,不过真近点角是随时间变动的 ...
- 通过 mysqlbinlog 和 grep 命令定位binlog文件中指定操作
1.binlog日志基本知识 MySQL的二进制日志binlog可以说是MySQL最重要的日志,它记录了所有的DDL和DML语句(除了数据查询语句select),以事件形式记录,还包含语句所执行的消耗 ...
- 异常:System.InvalidOperationException: This implementation is not part of the Windows Platform FIPS validated cryptographic algorithms FIPS信息标准限值了MD5加密
最近做的winform项目中,有个功能使用了MD5 加密,本地测试是没有问题的,但是上线后有些用户反馈说提示如下错误 一.问题描述 中文版错误截图 英语版错误截图 具体错误信息: 有关调用实时(JIT ...