什么是spark(二) RDD
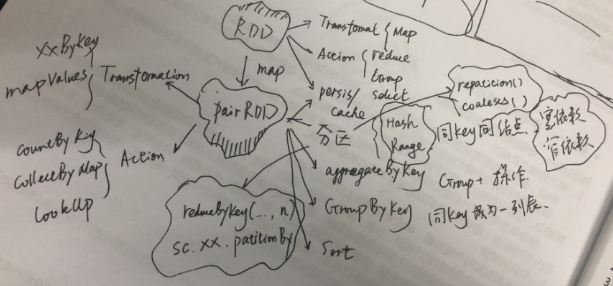
其实你会发现很多概念都是基于RDD提出来的,比如分区,缓存这些操作的对象其实都是RDD;所以不要讲spark的分区,这其实很不专业,分区其实是属于RDD的概念(只有pair RDD才有分区概念)
RDD在(一)已经介绍了RDD,本质上是数据的描述(检索条件)以及处理描述(算法);等待着Action调用之后将会根据数据描述来获取数据,然后再根据算法来处理获取到的数据。简单讲,RDD包含了两部分:一部分是本身定义了数据的描述:比如设置数据源inputRDD = sc.textFile("log.txt")另外一部分RDD提供了对于数据的操作接口:比如filter,union等。
那么在处理数据上面有两类操作,一类是Transformation(map, flatMap);上段提到的数据的描述就是在Transformation中定义,处理描述其实也是在其实在T中描述;当且建档Action类函数被调用了才会触发,比如reduce(),才会执行数据获取和数据处理;所以,spark里面的数据处理其实是一个延迟处理(Lazy Evaluation);一类是Action(reduce,first,take,folder,foreach等);所有的Transformation操作返回的都是RDD,所有的Action返回的是单值或者集合对象;这个是T和A的本质区别,因为T是用于形成DAG,定义了要如何对数据进行准备(transform就是变形的意思,可以理解为对数据的处理),A则是为了获取可操作数据,定了我要什么样的数据。
还有第三类操作,就是persis/cache;用于避免请求相同数据频繁的获取,可以将某次获取的数据RDD进行缓存。cache尽是内存级别缓存,persis则是提供了多种缓存策略。
RDD的最强大的地方其实还是在于PairRDD,一旦RDD是pairRDD,你的数据的想象空间就大了;首先是要把RDD转换为PairRDD,原生的RDD都是单值的;需要通过map来转为PairRDD,将原生单值数据,提取一部分作为key,单值本身或者单值另外一部分作为value(Map是为了改变世界而生,Map函数将会改变RDD的结构和数据);
PairRDD同样有Action和Transformation;但是Transformation的函数明显增多,一大堆在RDD时代是Action的函数,到了PairRDD时代,增加了“ByKey”,之后变成了Transformation,比如reduceByKey,groupByKey等等。PairRDD的action只剩下了:
1. countByKey;
2. collectAsMap;
3. lookup(key);
到了PairRDD最主要的动作之一就是分区;是的分区只能是PairRDD,因为只有PairRDD才有key的概念,分区的依据就是key(无论是Hash还是Range)。注意数据被某些改变key的操作处理后,返回的RDD可能会丢失分区,比如map;但是XXByKey家族的函数都会维持原始PairRDD的分区,因为这些操作并不改变分区。
分区的概念的本质是将数据按照一定规则进行汇聚,汇聚到一个计算节点(一台主机);一个计算节点可以有多个分区;
与分区设置方式,
1.)在调用Transformation函数的在最后一个参数添加为分区数;这个分区默认的应该是大多数都是Hash(Folder是defaultPartition);会造成数据倾斜(数据分布度不够,导致大量数据集中)。parallelize的默认将会根据集群情况来指定分区个数;但是当你想要避免shuffle操作的时候,分区还是需要你来做。
2)在创建的RDD的时候添加
有了Key之后,就可以做以下事情:
1)按照key来进行聚集(aggregation)操作;按照key进行分组,然后对于同组数据进行运算;返回的是[key, handled value];
2)按照key来进行分组(groupping)操作;按照key进行分组,返回[key,items];如果是分组+运算处理,请采用聚集操作
3)按照key来尽心排序(sorting)操作。
什么是spark(二) RDD的更多相关文章
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习之路 (三)Spark之RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- 解读Spark Streaming RDD的全生命周期
本节主要内容: 一.DStream与RDD关系的彻底的研究 二.StreamingRDD的生成彻底研究 Spark Streaming RDD思考三个关键的问题: RDD本身是基本对象,根据一定时间定 ...
- 08、Spark常用RDD变换
08.Spark常用RDD变换 8.1 概述 Spark RDD内部提供了很多变换操作,可以使用对数据的各种处理.同时,针对KV类型的操作,对应的方法封装在PairRDDFunctions trait ...
- Spark之RDD
Spark学习之路Spark之RDD 目录 一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数 ...
- Spark之RDD容错原理及四大核心要点
一.Spark RDD容错原理 RDD不同的依赖关系导致Spark对不同的依赖关系有不同的处理方式. 对于宽依赖而言,由于宽依赖实质是指父RDD的一个分区会对应一个子RDD的多个分区,在此情况下出现部 ...
- Spark RDD :Spark API--Spark RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- [Spark] Spark的RDD编程
本篇博客中的操作都在 ./bin/pyspark 中执行. RDD,即弹性分布式数据集(Resilient Distributed Dataset),是Spark对数据的核心抽象.RDD是分布式元素的 ...
- Spark核心—RDD初探
本文目的 最近在使用Spark进行数据清理的相关工作,初次使用Spark时,遇到了一些挑(da)战(ken).感觉需要记录点什么,才对得起自己.下面的内容主要是关于Spark核心-RDD的相关 ...
- 关于Spark中RDD的设计的一些分析
RDD, Resilient Distributed Dataset,弹性分布式数据集, 是Spark的核心概念. 对于RDD的原理性的知识,可以参阅Resilient Distributed Dat ...
随机推荐
- spring boot 中logback多环境配置
spring boot 配置logback spring boot自带了log打印功能,使用的是Commons logging 具体可以参考spring boot log 因此,我们只需要在resou ...
- css3之calc()
初识calc() 在使用calc()之前,我也只是听说有这么一个东西,但在用过之后我才发现这个功能其实很实用. calc()其实就是英文calculate(计算)的缩写,它看起来像个函数吧? 其实不是 ...
- 【zznu-夏季队内积分赛3-I】逛超市
题目描述 “别人总说我瓜,其实我一点也不瓜,大多数时候我都机智的一批“我宝儿姐背包学的太差了,你们谁能帮我解决这道题,我就让他做我的男朋友!宝儿姐现在在逛超市,超市里的种类实在是太多了,每种都有很多很 ...
- hdu 5800 To My Girlfriend(背包变形)
To My Girlfriend Time Limit: 2000/2000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others) ...
- vue 可编辑表格组件
<template> <div class="table"> <table border="1px" v-dragform> ...
- 2018-2019-2 网络对抗技术 20165202 Exp6 信息搜集与漏洞扫描
博客目录 一.实践目标 二.实践内容 各种搜索技巧的应用 DNS IP注册信息的查询 基本的扫描技术:主机发现.端口扫描.OS及服务版本探测.具体服务的查点 漏洞扫描:会扫,会看报告,会查漏洞说明,会 ...
- LVS模式一:直接路由模式DR(Direct Routing)
(一)LVS 一.LVS的了解 LVS(Linux Virtual Server)可以理解为一个虚拟服务器系统. Internet的飞速发展,网络带宽的增长,Web服务中越来越多地使用CGI.动态主页 ...
- 《Tomcat内核设计剖析》勘误表
<Tomcat内核设计剖析>勘误表 书中第95页图request部分印成了reqiest. 书中第311页两个tomcat3,其中一个应为tomcat4. 书中第5页URL应为URI. 书 ...
- Android内存优化(四)解析Memory Monitor、Allocation Tracker和Heap Dump
相关文章 Android性能优化系列 Java虚拟机系列 前言 要想做好内存优化工作,就要掌握两大部分的知识,一部分是知道并理解内存优化相关的原理,另一部分就是善于运用内存分析的工具.本篇就来介绍内存 ...
- iOS:Core Data 中的简单ORM
我们首先在xcdatamodel文件中设计我们的数据库:例如我建立一个Data的实体,里面有一个String类型的属性name以及一个Integer类型的num: 然后选中Data,添加文件,选择NS ...