Set集合学习
Java中的Set主要有:HashSet、TreeSet、LinkedHashSet。
一:HashSet
HashSet 是一个没有重复元素的无序集合。 HashSet由HashMap实现的,不保证元素的顺序,允许使用null元素,一系列操作的实现都是调用其底层的map的方法而已。
1:HashSet元素的存储顺序:由于HashSet底层是用HashMap存储元素的,每组数据都没有索引,很多list可用的方法他都没有,凡是需要通过索引来进行操作的方法都没有,也不能使用普通for循环来进行遍历,只有加强型for和迭代器两种遍历方法
2:HashSet如何保证元素不重复:HashSet在调用add(obj)方法插入元素时,首先调用元素的hashcode()方法,如果map中对应索引位还没有内容,则把元素值储存;如果索引位已有内容,则继续调用 元素的equals()方法把新增元素与已有元素值进行比较,如果是相等的,则新值不插入(因为重复了),如果是不相等的,则把新元素插入到该索引位元素列表的末尾。【原因:哈希码是存在冲突的,我们只规定了相等对象必定有相同哈希码,却没有规定不同对象不能有相同哈希码。当不同对象拥有同一哈希码时,就只能在哈希码索引位上建立链表来存放了。】
主要源码:(基于JDK1.6.0_45)
package java.util;
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{ static final long serialVersionUID = -5024744406713321676L;
// 使用 HashMap 的 key 保存 HashSet 中所有元素
private transient HashMap<E,Object> map;
//定义一个虚拟的 Object 对象作为 HashMap 的 value
private static final Object PRESENT = new Object(); // 默认构造函数
public HashSet() {
// 调用HashMap的默认构造函数,创建map
map = new HashMap<E,Object>();
}
// 带集合的构造函数
public HashSet(Collection<? extends E> c) { // HashMap的加载因子是0.75,(c.size()/.75f) + 1 正好是总的空间大小。
// 指定为16是从性能考虑,2的指数倍,避免重复计算。
map = new HashMap<E,Object>(Math.max((int) (c.size()/.75f) + 1, 16));
// 将集合(c)中的全部元素添加到HashSet中
addAll(c);
}
// 指定HashSet初始容量和加载因子的构造函数
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<E,Object>(initialCapacity, loadFactor);
}
// 指定HashSet初始容量的构造函数
public HashSet(int initialCapacity) {
map = new HashMap<E,Object>(initialCapacity);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<E,Object>(initialCapacity, loadFactor);
}
// 返回HashSet的迭代器
public Iterator<E> iterator() {
// 实际上返回的是HashMap的“key集合的迭代器”
return map.keySet().iterator();
}
public int size() {
return map.size();
}
public boolean isEmpty() {
return map.isEmpty();
}
public boolean contains(Object o) {
return map.containsKey(o);
}
// 将元素(e)添加到HashSet中
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// 删除HashSet中的元素(o)
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public void clear() {
map.clear();
}
// 克隆一个HashSet,并返回Object对象
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
}
// java.io.Serializable的写入函数
// 将HashSet的“总的容量,加载因子,实际容量,所有的元素”都写入到输出流中
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// Write out HashMap capacity and load factor
s.writeInt(map.capacity());
s.writeFloat(map.loadFactor());
// Write out size
s.writeInt(map.size());
// Write out all elements in the proper order.
for (Iterator i=map.keySet().iterator(); i.hasNext(); )
s.writeObject(i.next());
}
// java.io.Serializable的读取函数
// 将HashSet的“总的容量,加载因子,实际容量,所有的元素”依次读出
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject();
// Read in HashMap capacity and load factor and create backing HashMap
int capacity = s.readInt();
float loadFactor = s.readFloat();
map = (((HashSet)this) instanceof LinkedHashSet ?
new LinkedHashMap<E,Object>(capacity, loadFactor) :
new HashMap<E,Object>(capacity, loadFactor));
// Read in size
int size = s.readInt();
// Read in all elements in the proper order.
for (int i=; i<size; i++) {
E e = (E) s.readObject();
map.put(e, PRESENT);
}
}
}
HashSet主要的API
boolean add(E object)
void clear()
Object clone()
boolean contains(Object object)
boolean isEmpty()
Iterator<E> iterator()
boolean remove(Object object)
int size()
HashSet与Map关系如下图:
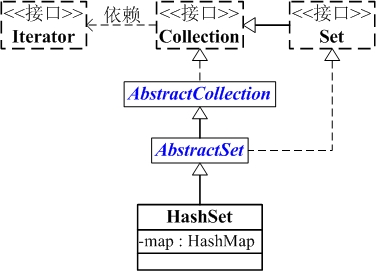
从图中可以看出:
(01) HashSet继承于AbstractSet,并且实现了Set接口。
(02) HashSet的本质是一个"没有重复元素"的集合,它是通过HashMap实现的。HashSet中含有一个"HashMap类型的成员变量"map,HashSet的操作函数,实际上都是通过map实现的。
HashSet遍历方式
遍历实例:
import java.util.Random;
import java.util.Iterator;
import java.util.HashSet; /*
* @desc 介绍HashSet遍历方法
*
* @author hdb
*/
public class HashSetIteratorTest { public static void main(String[] args) {
// 新建HashSet
HashSet set = new HashSet(); // 添加元素 到HashSet中
for (int i=0; i<5; i++){
set.add(""+i);
} // 通过Iterator遍历HashSet
iteratorHashSet(set) ; // 通过for-each遍历HashSet
foreachHashSet(set);
} /*
* 通过Iterator遍历HashSet。推荐方式.
* 第一步:根据iterator()获取HashSet的迭代器
* 第二步:遍历迭代器获取各个元素。
*/
private static void iteratorHashSet(HashSet set) {
for(Iterator iterator = set.iterator();
iterator.hasNext(); ) {
System.out.printf("iterator : %s\n", iterator.next());
}
//另一种写法
//Iterator iterator = set.iterator();
//while (iterator.hasNext()) {
// System.out.printf("iterator : %s\n", iterator.next());
//}
} /* * 通过for-each遍历HashSet。不推荐!此方法需要先将Set转换为数组
* 第一步:根据toArray()获取HashSet的元素集合对应的数组
* 第二步:遍历数组,获取各个元素
*/
private static void foreachHashSet(HashSet set) {
String[] arr = (String[])set.toArray(new String[0]);
for (String str:arr){
System.out.printf("for each : %s\n", str);
}
}
}
实例学习如何使用HashSet
import java.util.Iterator;
import java.util.HashSet; /*
* @desc HashSet常用API的使用。
*
* @author hdb
*/
public class HashSetTest { public static void main(String[] args) {
// HashSet常用API
testHashSetAPIs() ;
} /*
* HashSet除了iterator()和add()之外的其它常用API
*/
private static void testHashSetAPIs() { // 新建HashSet
HashSet set = new HashSet(); // 将元素添加到Set中
set.add("a");
set.add("b");
set.add("c");
set.add("d");
set.add("e"); // 打印HashSet的实际大小
System.out.printf("size : %d\n", set.size()); // 判断HashSet是否包含某个值
System.out.printf("HashSet contains a :%s\n", set.contains("a"));
System.out.printf("HashSet contains g :%s\n", set.contains("g")); // 删除HashSet中的“e”
set.remove("e"); // 新建一个包含b、c、f的HashSet
HashSet otherset = new HashSet();
otherset.add("b");
otherset.add("c");
otherset.add("f"); // 克隆一个removeset,内容和set一模一样
HashSet removeset = (HashSet)set.clone();
// 删除“removeset中,属于otherSet的元素”
removeset.removeAll(otherset);
// 打印removeset
System.out.printf("removeset : %s\n", removeset); // 克隆一个retainset,内容和set一模一样
HashSet retainset = (HashSet)set.clone();
// 保留“retainset中,属于otherSet的元素”
retainset.retainAll(otherset);
// 打印retainset
System.out.printf("retainset : %s\n", retainset); // 遍历HashSet,推荐方式
for(Iterator iterator = set.iterator();
iterator.hasNext(); ) {
System.out.printf("iterator : %s\n", iterator.next());
}
// 将Set转换为数组,遍历HashSet,不推荐
String[] arr = (String[])set.toArray(new String[0]);
for (String str:arr) {
System.out.printf("for each : %s\n", str);
} // 清空HashSet
set.clear(); // 输出HashSet是否为空
System.out.printf("%s\n", set.isEmpty()?"set is empty":"set is not empty");
}
}
HashSet线程同步问题
HashSet是非同步的。如果多个线程同时访问一个HashSet,而其中至少一个线程修改了该HashSet,那么它必须保持外部同步。通常是通过对自然封装该HashSet的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSet 方法来“包装” set。最好在创建时完成这一操作,以防止对该 set 进行意外的不同步访问:
Set s = Collections.synchronizedSet(new HashSet(...));
HashSet通过iterator()返回的迭代器是fail-fast的。
二:TreeSet
TreeSet在保持元素唯一性的基础上,更增加了使插入元素有序的特性。TreeSet的底层实际上是TreeMap,在TreeSet上的操作的实现都是调用了底层的TreeMap的方法。
1:TreeSet的排序规则制定:
1)元素自身具备比较性:元素类实现Comparable接口,重写compareTo方法,这种方式叫做元素的自然排序(默认排序)。
2)在创建TreeSet时指定比较器:定义一个比较器类实现接口Comparator,重写compare方法,在创建TreeSet时把比较器对象传进去。
2:TreeSet中元素的唯一性保证:通过元素的compareTo方法或者treeset创建时的比较器compare方法,如果return 0则说明有相等元素存在,则新元素不插入。
部分主要源码:
package java.util; public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
// NavigableMap对象
private transient NavigableMap<E,Object> m; // TreeSet是通过TreeMap实现的,
// PRESENT是键-值对中的值。
private static final Object PRESENT = new Object(); // 不带参数的构造函数。创建一个空的TreeMap
public TreeSet() {
this(new TreeMap<E,Object>());
} // 将TreeMap赋值给 "NavigableMap对象m"
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
} // 带比较器的构造函数。
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<E,Object>(comparator));
} // 创建TreeSet,并将集合c中的全部元素都添加到TreeSet中
public TreeSet(Collection<? extends E> c) {
this();
// 将集合c中的元素全部添加到TreeSet中
addAll(c);
} // 创建TreeSet,并将s中的全部元素都添加到TreeSet中
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
} // 返回TreeSet的顺序排列的迭代器。
// 因为TreeSet时TreeMap实现的,所以这里实际上时返回TreeMap的“键集”对应的迭代器
public Iterator<E> iterator() {
return m.navigableKeySet().iterator();
} // 返回TreeSet的逆序排列的迭代器。
// 因为TreeSet时TreeMap实现的,所以这里实际上时返回TreeMap的“键集”对应的迭代器
public Iterator<E> descendingIterator() {
return m.descendingKeySet().iterator();
} // 返回TreeSet的大小
public int size() {
return m.size();
} // 返回TreeSet是否为空
public boolean isEmpty() {
return m.isEmpty();
} // 返回TreeSet是否包含对象(o)
public boolean contains(Object o) {
return m.containsKey(o);
} // 添加e到TreeSet中
public boolean add(E e) {
return m.put(e, PRESENT)==null;
} // 删除TreeSet中的对象o
public boolean remove(Object o) {
return m.remove(o)==PRESENT;
} // 清空TreeSet
public void clear() {
m.clear();
} // 将集合c中的全部元素添加到TreeSet中
public boolean addAll(Collection<? extends E> c) {
// Use linear-time version if applicable
if (m.size()==0 && c.size() > 0 &&
c instanceof SortedSet &&
m instanceof TreeMap) {
SortedSet<? extends E> set = (SortedSet<? extends E>) c;
TreeMap<E,Object> map = (TreeMap<E, Object>) m;
Comparator<? super E> cc = (Comparator<? super E>) set.comparator();
Comparator<? super E> mc = map.comparator();
if (cc==mc || (cc != null && cc.equals(mc))) {
map.addAllForTreeSet(set, PRESENT);
return true;
}
}
return super.addAll(c);
} // 返回子Set,实际上是通过TreeMap的subMap()实现的。
public NavigableSet<E> subSet(E fromElement, boolean fromInclusive,
E toElement, boolean toInclusive) {
return new TreeSet<E>(m.subMap(fromElement, fromInclusive,
toElement, toInclusive));
} // 返回Set的头部,范围是:从头部到toElement。
// inclusive是是否包含toElement的标志
public NavigableSet<E> headSet(E toElement, boolean inclusive) {
return new TreeSet<E>(m.headMap(toElement, inclusive));
} // 返回Set的尾部,范围是:从fromElement到结尾。
// inclusive是是否包含fromElement的标志
public NavigableSet<E> tailSet(E fromElement, boolean inclusive) {
return new TreeSet<E>(m.tailMap(fromElement, inclusive));
} // 返回子Set。范围是:从fromElement(包括)到toElement(不包括)。
public SortedSet<E> subSet(E fromElement, E toElement) {
return subSet(fromElement, true, toElement, false);
} // 返回Set的头部,范围是:从头部到toElement(不包括)。
public SortedSet<E> headSet(E toElement) {
return headSet(toElement, false);
} // 返回Set的尾部,范围是:从fromElement到结尾(不包括)。
public SortedSet<E> tailSet(E fromElement) {
return tailSet(fromElement, true);
} // 返回Set的比较器
public Comparator<? super E> comparator() {
return m.comparator();
} // 返回Set的第一个元素
public E first() {
return m.firstKey();
} // 返回Set的最后一个元素
public E first() {
public E last() {
return m.lastKey();
} // 返回Set中小于e的最大元素
public E lower(E e) {
return m.lowerKey(e);
} // 返回Set中小于/等于e的最大元素
public E floor(E e) {
return m.floorKey(e);
} // 返回Set中大于/等于e的最小元素
public E ceiling(E e) {
return m.ceilingKey(e);
} // 返回Set中大于e的最小元素
public E higher(E e) {
return m.higherKey(e);
} // 获取第一个元素,并将该元素从TreeMap中删除。
public E pollFirst() {
Map.Entry<E,?> e = m.pollFirstEntry();
return (e == null)? null : e.getKey();
} // 获取最后一个元素,并将该元素从TreeMap中删除。
public E pollLast() {
Map.Entry<E,?> e = m.pollLastEntry();
return (e == null)? null : e.getKey();
} // 克隆一个TreeSet,并返回Object对象
public Object clone() {
TreeSet<E> clone = null;
try {
clone = (TreeSet<E>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError();
} clone.m = new TreeMap<E,Object>(m);
return clone;
} // java.io.Serializable的写入函数
// 将TreeSet的“比较器、容量,所有的元素值”都写入到输出流中
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
s.defaultWriteObject(); // 写入比较器
s.writeObject(m.comparator()); // 写入容量
s.writeInt(m.size()); // 写入“TreeSet中的每一个元素”
for (Iterator i=m.keySet().iterator(); i.hasNext(); )
s.writeObject(i.next());
} // java.io.Serializable的读取函数:根据写入方式读出
// 先将TreeSet的“比较器、容量、所有的元素值”依次读出
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden stuff
s.defaultReadObject(); // 从输入流中读取TreeSet的“比较器”
Comparator<? super E> c = (Comparator<? super E>) s.readObject(); TreeMap<E,Object> tm;
if (c==null)
tm = new TreeMap<E,Object>();
else
tm = new TreeMap<E,Object>(c);
m = tm; // 从输入流中读取TreeSet的“容量”
int size = s.readInt(); // 从输入流中读取TreeSet的“全部元素”
tm.readTreeSet(size, s, PRESENT);
} // TreeSet的序列版本号
private static final long serialVersionUID = -2479143000061671589L;
}
三:LinkedHashSet
LinkedHashSet的特性是:记录了元素的插入顺序。在遍历时可以按照元素的插入顺序进行遍历。
LinkHashSet维护了一个双向链表,记录元素的插入顺序,然后再根据元素值,采用hashcode()、equals()方法来存储元素值并实现元素的唯一性。
Set集合学习的更多相关文章
- 转:深入Java集合学习系列:HashSet的实现原理
0.参考文献 深入Java集合学习系列:HashSet的实现原理 1.HashSet概述: HashSet实现Set接口,由哈希表(实际上是一个HashMap实例)支持.它不保证set 的迭代顺序:特 ...
- 2019/3/4 java集合学习(二)
java集合学习(二) 在学完ArrayList 和 LinkedList之后,基本已经掌握了最基本的java常用数据结构,但是为了提高程序的效率,还有很多种特点各异的数据结构等着我们去运用,类如可以 ...
- 2019/3/2周末 java集合学习(一)
Java集合学习(一) ArraysList ArraysList集合就像C++中的vector容器,它可以不考虑其容器的长度,就像一个大染缸一 样,无穷无尽的丢进去也没问题.Java的数据结构和C有 ...
- ------------------java collection 集合学习 ----小白学习笔记,,有错,请指出谢谢
<!doctype html>java对象集合学习记录 figure:first-child { margin-top: -20px; } #write ol, #write ul { p ...
- C# Stack 集合学习
Stack 集合学习 学习自:博客园相关文章 Stack<T>集合 这个集合的特点为:后进先出,简单来说就是新元素都放到第一位,而且顺序移除元素也是从第一位开始的. 方法一:Push(T ...
- Java集合学习(9):集合对比
一.HashMap与HashTable的区别 HashMap和Hashtable的比较是Java面试中的常见问题,用来考验程序员是否能够正确使用集合类以及是否可以随机应变使用多种思路解决问题.Hash ...
- java集合学习(2):Map和HashMap
Map接口 java.util 中的集合类包含 Java 中某些最常用的类.最常用的集合类是 List 和 Map. Map 是一种键-值对(key-value)集合,Map 集合中的每一个元素都包含 ...
- Java 集合学习--ArrayList
一.ArrayList 定义 ArrayList 是一个用数组实现的集合,支持随机访问,元素有序且可以重复. ①.实现 List 接口 List接口继承Collection接口,是List类的顶层接口 ...
- Java 集合学习--集合概述
一.集合框架 集合,通常也叫容器,java中有多种方式保存对象,集合是java保存对象(对象的引用)的方式之一,之前学习的数组是保存对象的最有效的方式,但是数组却存在一个缺陷,数组的大小是固定的,但是 ...
- Java集合学习(6):LinkedHashSet
一.概述 首先我们需要知道的是它是一个Set的实现,所以它其中存的肯定不是键值对,而是值.此实现与HashSet的不同之处在于,LinkedHashSet维护着一个运行于所有条目的双重链接列表.此链接 ...
随机推荐
- c++之迭代器失效
1.首先从一到题目开始谈说起迭代器失效.有时我们很自然并且自信地 用下面方法删除vector元素: #include <iostream>#include <stdio.h># ...
- Bigdecimal: Non-terminating decimal expansion; no exact representable decimal result.
做除法没有指定保留小数点后几位,就会抛出此异常. 因为会除不尽 Non-terminating decimal expansion; no exact representable decimal re ...
- cglib动态代理(需导入cglib-nodep-2.1_3.jar)
public interface AnimalInterface { public void cry(); } public class AnimalImpl implements AnimalInt ...
- unity3D用什么语言开发好?
unity3D用什么语言开发好? 一.总结 一句话总结:选c# 同时U3D团队也会把支持的重心转移到C#,也就是说文档和示例以及社区支持的重心都在C#,C#的文档会是最完善的,C#的代码实例会是最详细 ...
- Python面向过程和面向对象基础
总结一下: 面向过程编程:根据业务逻辑从上到下的写代码-----就是一个project写到底,重复利用性比较差 函数式:将某些特定功能代码封装到函数中------方便日后调用 面向对象:对函数进行分类 ...
- java 使用注释校验数据有效性
验证注解 验证的数据类型 说明 空检查 @Null 任意类型 验证注解的元素值是null @NotNull 任意类型 验证注解的元素不是null @NotBlank CharSequence子类型(C ...
- linux入门总结
linux的核心概念知识: linux软件是开源免费的,而linux是由Unix演变而成,Unix是由MINIX演变而成. 2000年以后,linux系统日趋成熟,涌现大量基于linux服务平 ...
- flask学习(九):模板渲染和参数传递
一. 如何渲染模板 1. 模板放在templates文件夹下 2. 从flask中导入render_template函数 3. 在视图函数中,使用render_template函数,渲染模板 注意:只 ...
- 1012: [JSOI2008]最大数maxnumber 线段树
https://www.lydsy.com/JudgeOnline/problem.php?id=1012 现在请求你维护一个数列,要求提供以下两种操作:1. 查询操作.语法:Q L 功能:查询当前数 ...
- Roman Numeral Converter
将给定的数字转换成罗马数字. 所有返回的 罗马数字 都应该是大写形式. 这是一些对你有帮助的资源: Roman Numerals Array.splice() Array.indexOf() Arra ...