elasticsearch配合mysql实现全文搜索
之前用了sphinx,发现很多东西很久都没更新过了,之前只是知道有elasticsearch这个东西,还以为是java才能用,所以一直没有去了解过,也许sphinx慢慢会被淘汰了吧。
前置条件:需要安装jdk,并配置了 JAVA_HOME。
需要下载的东西
Elasticsearch:
https://www.elastic.co/products/elasticsearch
Logstash:
https://www.elastic.co/products/logstash
mysql-connector:
https://dev.mysql.com/downloads/connector/j/5.1.html
另外:可以安装 kibana,有更友好的数据展示。
elasticsearch、logstash、kibana 的安装在 mac 下可以 brew install
中文搜索需要安装中文分词插件(需要自己去github下载对应的版本 https://github.com/medcl/elasticsearch-analysis-ik/releases):
bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.1/elasticsearch-analysis-ik-5.5.1.zip
logstash 和 mysql-connector 是用来实现同步 mysql 数据到 elasticsearch 的。
logstash 配置:https://github.com/elastic/logstash/issues/3429
logstash 需要安装 logstash-input-jdbc 插件:(这一步可能会卡很久,可能的原因是,这个插件使用ruby开发,安装过程需要下载 gem,但是国外的源太慢。)
logstash/bin/plugin install logstash-input-jdbc
logstash 的配置使用查看:https://github.com/elastic/logstash/issues/3429
下面是本机测试配置:
input {
jdbc {
jdbc_driver_library => "/usr/local/elasticsearch/plugins/logstash/mysql-connector-java-5.1.44-bin.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.0.200:3306/vegent?characterEncoding=UTF-8&useSSL=false"
jdbc_user => "test"
jdbc_password => "test"
statement => "SELECT * FROM vegent"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
schedule => "* * * * *"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => "192.168.0.200"
index => "vegent"
}
}
2018-06-02 更新:
上面的配置挖了个坑,因为没有限制条件,而且指定了 schedule,所以会一直插入重复索引。
网上有说加以下条件就可以了(没有实践,不指定是否可行):
WHERE id > :sql_last_value
启动Logstash:logstash -f logstash-mysql.conf ,这个logstash-mysql.conf 就是上面的配置。
查看elasticsearch是否同步数据成功:curl '192.168.0.200:9200/_cat/indices?v',如果看到大小在增长则说明同步成功了。
附:解决 gem 下载慢的问题(使用淘宝源)
1、gem sources --add https://ruby.taobao.org/ --remove https://rubygems.org/
2、gem sources -l,确保只有 ruby.taobao.org,
如果 还是显示 https://rubygems.org/ 进入 home的 .gemrc 文件
sudo vim ~/.gemrc
手动删除 https://rubygems.org/
3、修改Gemfile的数据源地址,这个 Gemfile 位于 logstash 目录下,修改 source 的值 为: "https://ruby.taobao.org",修改 Gemfile.jruby-1.9.lock, 找到 remote 修改它的值为: https://ruby.taobao.org (可能有几个 remote 出现,修改后面是 url 那个,替换掉 url)。
4、安装 logstash-input-jdbc,按上面的命令。
5、关于同步的问题,上面设置了一分钟一次,并且无条件同步,实际上是可以只同步那些更新过的数据的,这里还没来得及做深入研究。而且上面的配置还有个问题是,只做插入,而不是更新原有数据,这样其实并不是我们想要的结果。
更新:sql 语句里面可以配置只同步更新过的数据,但是这个更新需要我们去定义,好比如,数据库有一个 update_time 字段,我们更新的时候更新该字段(timestamp类型),这样我们可以把 sql 语句写为 "SELECT * FROM vegent where update_time > :sql_last_value",这个 sql_last_value 在这个时候会是上一次执行该 sql 的时间戳,这样也就实现了更新操作。另外还有一个问题是,elasticsearch 和 logstash 默认使用 UTC 时间戳,这样如果我们保存的是 PRC 时区的时间戳,这样就会有问题,因为这样 logstash 的同步语句中的时间戳是 -8:00 的,所以,还要在配置文件中加上:jdbc_default_timezone => "UTC",最后如下:
最后发现这样虽然 sql 语句时间戳正常了,但是建立的索引里面的时间戳还是 UTC 的时间戳。
最后把 UTC 改为 PRC,最后都正常了,还是和上面一样的情况,索引里面的 @timestamp 还是 UTC 的时间戳。
google 了一下,发现这个好像是不能配置的。这样怎么办呢,也许可以保存 UTC 的时间戳吧,取数据的时候再转 PRC 。(后面证实了这个猜想有点多余,还是应该使用 UTC)
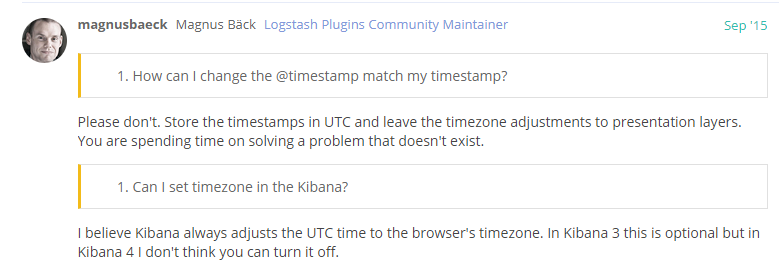
上图链接:https://discuss.elastic.co/t/how-to-set-timestamp-timezone/28401
另外一个猜想是:其实这个@timestamp 对我们的同步更新数据没影响,后来想想发现也是,其实没影响:

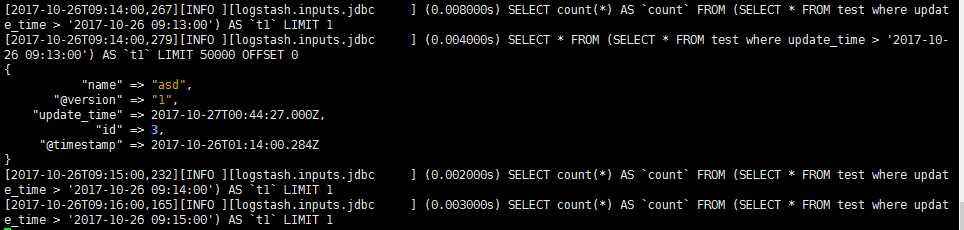
上图中, :sql_last_value 是我们上一次进行 sql 查询的时间。而不是我之前以为的索引里面的 @timestamp 字段,想想也对,如果索引有 100w 数据,那么我应该取那一条记录的 @timestamp 作为 :sql_last_value 呢?
所以结论还是,jdbc_default_timezone 使用 UTC 就可以了。有个需要注意的问题是 时间戳字段要使用 mysql 的timestamp。
jdbc {
jdbc_driver_library => "/home/vagrant/logstash/mysql-connector-java-5.1.44-bin.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.0.200:3306/test?characterEncoding=UTF-8&useSSL=false"
jdbc_user => "test"
jdbc_password => "test"
jdbc_default_timezone => "UTC"
statement => "SELECT * FROM test where update_time > :sql_last_value"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
schedule => "* * * * *"
}
查询例子:
curl 'localhost:9200/vegent/_search?pretty=true' -d '
{
"query" : { "match" : { "type" : "冬瓜" }}
}'
输出(一部分):

查询 type 字段包含了 "冬瓜" 的所有记录。vegent 是索引的名称。?pretty=true 是指定友好输出格式。
返回结果的 took字段表示该操作的耗时(单位为毫秒),timed_out字段表示是否超时,hits字段表示命中的记录,里面子字段的含义如下。
total:返回记录数,本例是487893条。
max_score:最高的匹配程度,本例是5.598418。
hits:返回的记录组成的数组。
logstash 文档地址:https://www.elastic.co/guide/en/logstash/index.html
其他问题:
1、无法远程连接,默认只允许本机连接,可以修改配置文件 elasticsearch/config/elasticsearch.yml
# Set the bind address to a specific IP (IPv4 or IPv6):
#
#network.host: 192.168.0.1
transport.host: localhost
transport.tcp.port: 9300
http.port: 9200
network.host: 0.0.0.0
2、上面的 "同步",并不是真正的同步,当有新数据的时候,上面做的只是把新数据继续加到索引里面,而不是根据对应的 id 去删除原来的数据,这些需要自己做其他操作,目前还没做深入了解。
elasticsearch配合mysql实现全文搜索的更多相关文章
- paip.mysql fulltext 全文搜索.最佳实践.
paip.mysql fulltext 全文搜索.最佳实践. 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://blo ...
- MySQL中文全文搜索
我们在mysql数据中可以使用match against语句解决中文全文搜索的问题 先看一个例句: SELECT * FROM v9_search WHERE `siteid`= '1' AND `t ...
- ElasticSearch利用IK实现全文搜索
要做到中文全文检索还需要按照中文分词库 ,这里就使用 IK来设置 安装中文分词库 相关命令: whereis elasticsearch 找到目录 进入 到/usr/elasticsearch/bin ...
- MySQL 全文搜索支持, mysql 5.6.4支持Innodb的全文检索和类memcache的nosql支持
背景:搞个个人博客的全文搜索得用like啥的,现在mysql版本号已经大于5.6.4了也就支持了innodb的全文搜索了,刚查了下目前版本号都到MySQL Community Server 5.6.1 ...
- mysql 全文搜索的FULLTEXT
FULLTEXT索引 创建FULLTEXT索引语法 创建table的时候创建fullText索引 CREATE TABLE table_name( column1 data_type, column2 ...
- 如何在MySQL中获得更好的全文搜索结果
如何在MySQL中获得更好的全文搜索结果 很多互联网应用程序都提供了全文搜索功能,用户可以使用一个词或者词语片断作为查询项目来定位匹配的记录.在后台,这些程序使用在一个SELECT 查询中的LIKE语 ...
- MySQL全文搜索
http://www.yiibai.com/mysql/full-text-search.html 在本节中,您将学习如何使用MySQL全文搜索功能. MySQL全文搜索提供了一种实现各种高级搜索技术 ...
- 使用ElasticSearch服务从MySQL同步数据实现搜索即时提示与全文搜索功能
最近用了几天时间为公司项目集成了全文搜索引擎,项目初步目标是用于搜索框的即时提示.数据需要从MySQL中同步过来,因为数据不小,因此需要考虑初次同步后进行持续的增量同步.这里用到的开源服务就是Elas ...
- 在 Laravel 项目中使用 Elasticsearch 做引擎,scout 全文搜索(小白出品, 绝对白话)
项目中需要搜索, 所以从零开始学习大家都在用的搜索神器 elasiticsearch. 刚开始 google 的时候, 搜到好多经验贴和视频(中文的, 英文的), 但是由于是第一次接触, 一点概念都没 ...
随机推荐
- SICP读书笔记 1.3
SICP CONCLUSION 让我们举起杯,祝福那些将他们的思想镶嵌在重重括号之间的Lisp程序员 ! 祝我能够突破层层代码,找到住在里计算机的神灵! 目录 1. 构造过程抽象 2. 构造数据抽象 ...
- 《图解 HTTP 》阅读 —— 第二章
第2章 简单的http协议 http 协议用于客户端和服务器端的通信. 请求访问文本或图像等资源的一端称为客户端,提供资源响应的一端称为服务器端. 请求报文: 响应报文: 为了能够处理大量的事务,ht ...
- HP VC模块Shared uplink Sets配置参考
首先配置MAC地址的分配方式 在左侧导航栏中,点解"MAC Addresses" 选择VC分配MAC地址,并且选择一个合适的地址段,点击"Apply"继续 在弹 ...
- Tess4J -4.0.2- Linux 实践 [解决:Tess4J - Native library (linux-x86-64/libtesseract.so) not found in resource path]
[本文编写于2018年7月5日] Tess4J是Tesseract的Java JNA wrapper.本文介绍了在CentOS 7 操作系统中使用Tess4J的步骤及注意事项.在正式开始之前,先花一点 ...
- Python操作摄像头
实践环境: 操作系统:Windows 7(X64) Python版本:python-2.7.13.msi 使用插件:pygame-1.9.1.win32-py2.7.msi 软件下载: python- ...
- 智能客服 利用python运行java代码
因为需要在linux中用python来进行分析,顾需要利用python来运行java中语音转文字和文字转语音代码 在python中运行java代码需要利用jpype
- 团队Alpha冲刺(四)
目录 组员情况 组员1(组长):胡绪佩 组员2:胡青元 组员3:庄卉 组员4:家灿 组员5:凯琳 组员6:丹丹 组员7:何家伟 组员8:政演 组员9:鸿杰 组员10:刘一好 组员:何宇恒 展示组内最新 ...
- jsp取不到值栈的值
是否页面用的重定向? <result name="addsuccess" type="redirect"> ? 去掉type="redi ...
- nodejs 中on 和 emit
首先测试用例: var EventEmitter = require('events').EventEmitter var life = new EventEmitter(); // life.on( ...
- iOS- Autolayout自动布局
1.前言 •在iOS程序中,大部分视图控制器都包含了大量的代码用于设置UI布局,设置控件的水平或垂直位置,以确保组件在不同版本的iOS中都能得到合理的布局 •甚至有些程序员希望在不同的设备使用相同的视 ...