python3 scrapy爬虫项目的诞生
前提安装好scrapy模块最好 requests和bs4模块都安装好
可以概括为五个步骤
步骤一:新建一个项目
无论你用windows也好,linux也罢,在cmd或者终端 切换到目标文件夹,然后输入命令
scrapy startproject dingsspider(自定义的项目名)
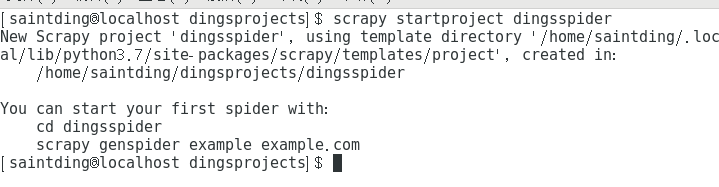
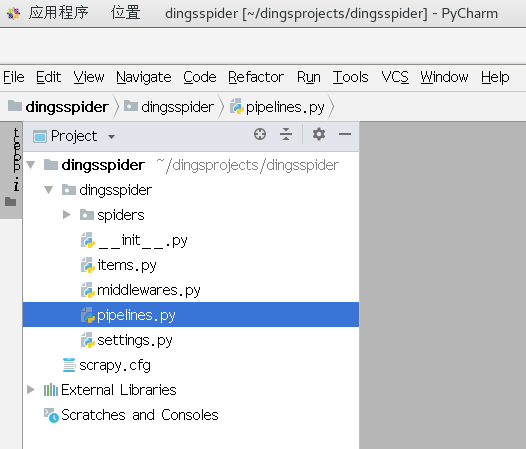
步骤二:生成爬虫
如同shell终端提示的那样,要生成爬虫
重要提示:执行命令时你有可能遇到一个错误,可能不是由于你的代码语法错误,而是来自源代码的错误,请看如下帖子
http://bbs.51cto.com/thread-1547185-1.html
解决方案截图如下:

解决上述问题后,运行命令
scrapy genspider wenwa wenwa.com
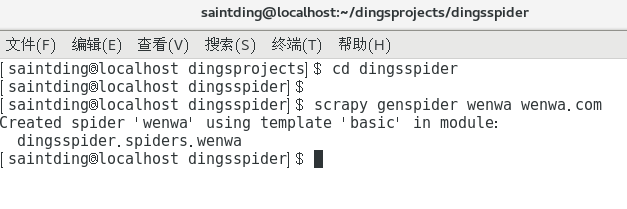
哟比~有了项目架构,我们就可以通过改写相关的爬虫类,实现爬虫的运转了
爬取一个网页,以著名编程知识网站runnoob为例,因为朕要学习php(找个python编程工作怎么就JB那么难,大爷的)
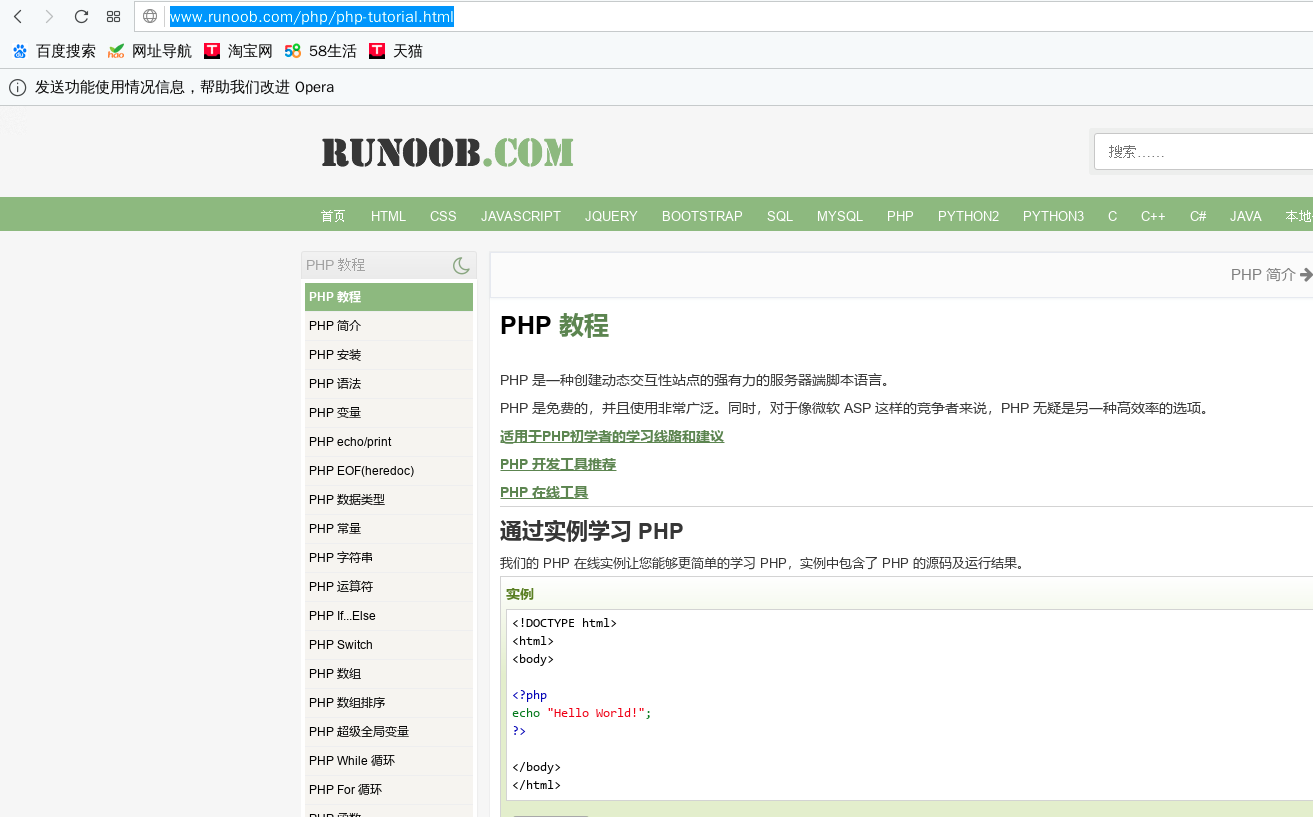
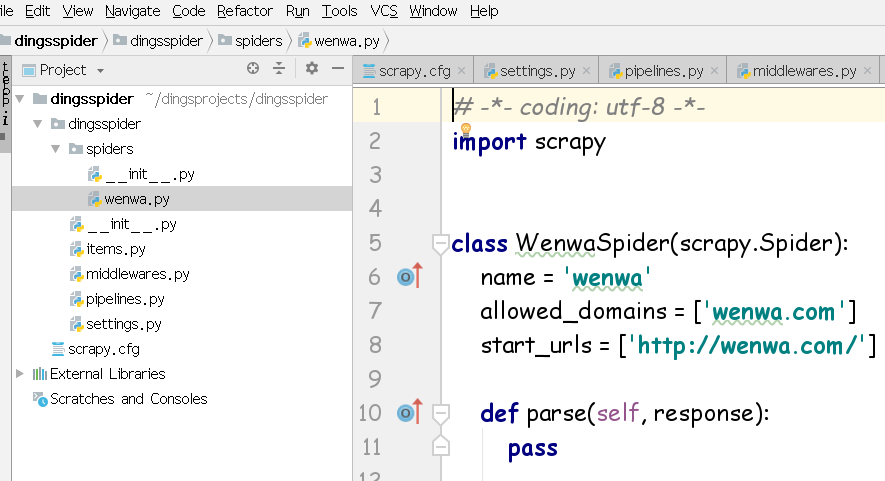
在步骤二中,已经通过genspider 命名了一个文件wenwa,那么在爬虫项目中找到同名文件wenwa.py,修改如下:
import scrapy
class WenwaSpider(scrapy.Spider):
name = 'wenwa'
allowed_domains = ['www.runoob.com']
start_urls = ['http://www.runoob.com/php/php-tutorial.html'] def parse(self, response):
filename = response.url.split("/")[-]+".html"
with open(filename,"wb") as p:
p.write(response.body)
allow_domians显示了要爬去的主域名,start_urls则是我们要爬取的页面,parse中filename完全是拆分start_urls后形成的列表里面,拿出一个元素给装载爬取结果的文件命名,如果觉得晕,随便取个名字就好
成功生成文件php.html,如下图

打开一看,瓦嗷~真tm丑,不过总算成功了,瓦卡卡
python3 scrapy爬虫项目的诞生的更多相关文章
- 在Pycharm中运行Scrapy爬虫项目的基本操作
目标在Win7上建立一个Scrapy爬虫项目,以及对其进行基本操作.运行环境:电脑上已经安装了python(环境变量path已经设置好), 以及scrapy模块,IDE为Pycharm .操作如下: ...
- 关于Scrapy爬虫项目运行和调试的小技巧(下篇)
前几天给大家分享了关于Scrapy爬虫项目运行和调试的小技巧上篇,没来得及上车的小伙伴可以戳超链接看一下.今天小编继续沿着上篇的思路往下延伸,给大家分享更为实用的Scrapy项目调试技巧. 三.设置网 ...
- 关于Scrapy爬虫项目运行和调试的小技巧(上篇)
扫除运行Scrapy爬虫程序的bug之后,现在便可以开始进行编写爬虫逻辑了.在正式开始爬虫编写之前,在这里介绍四种小技巧,可以方便我们操纵和调试爬虫. 一.建立main.py文件,直接在Pycharm ...
- Scrapy 爬虫项目框架
1. Scrapy 简介 2. Scrapy 项目开发介绍 3. Scrapy 项目代码示例 3.1 setting.py:爬虫基本配置 3.2 items.py:定义您想抓取的数据 3.3 spid ...
- python3+Scrapy爬虫使用pipeline数据保存到文本和数据库,数据少或者数据重复问题
爬取的数据结果是没有错的,但是在保存数据的时候出错了,出现重复数据或者数据少问题.那为什么会造成这种结果呢? 其原因是由于Spider的速率比较快,而scapy操作数据库操作比较慢,导致pipelin ...
- 第十六节:Scrapy爬虫框架之项目创建spider文件数据爬取
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取所设计的, 也可以应用在获取API所返回的数据或 ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(下)
前几天小编带大家学会了如何在Scrapy框架下创建属于自己的第一个爬虫项目(上),今天我们进一步深入的了解Scrapy爬虫项目创建,这里以伯乐在线网站的所有文章页为例进行说明. 在我们创建好Scrap ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- Scrapy爬虫框架第一讲(Linux环境)
1.What is Scrapy? 答:Scrapy是一个使用python语言(基于Twistec框架)编写的开源网络爬虫框架,其结构清晰.模块之间的耦合程度低,具有较强的扩张性,能满足各种需求.(前 ...
随机推荐
- 学习笔记:CentOS7学习之二十:shell脚本的基础
目录 学习笔记:CentOS7学习之二十:shell脚本的基础 20.1 shell 基本语法 20.1.1 什么是shell? 20.1.2 编程语言分类 20.1.3 什么是shell脚本 20. ...
- 什么是Java内部类?
如果大家想了解更多的知识和技术,大家可以 搜索我的公众号:理想二旬不止 (尾部有二维码)或者访问我的 个人技术博客 www.ideal-20.cn 这样阅读起来会更加舒适一些 非常高兴与大家交流,学习 ...
- 【AtCoder】ARC061
ARC061 C - たくさんの数式 / Many Formulas 这个其实\(10^5\)也能做.. 就是\(dp[i]\)表示到第i位的方案数,\(sum[i]\)表示延伸到第i位之前的所有方案 ...
- 【深入浅出-JVM】(9): 方法区
概念 方法区是虚拟机规范定义的,是所有线程共享的内存区域,保存系统的类的信息.比如:类的字段.方法.常量池.构造函数的字节码内容.代码.JIT 代码 永久代.metaspace 是对方法区的实现. H ...
- Spring中@Component与@Bean的区别
@Component和@Bean的目的是一样的,都是注册bean到Spring容器中. @Component VS @Bean @Component 和 它的子类型(@Controller, @S ...
- 怎样获取所有的script节点
1. 使用document.scripts; document.scripts instanceof HTMLCollection; // true 2. 使用 document.getElement ...
- ArrayList插入1000w条数据的时间比较分析
一分钟系列: 读懂GC日志 ArrayList插入1000w条数据之后,我怀疑了jvm... Java JIT性能调优 Java性能优化指南系列(三):理解JIT编译器 准备:调试程序加入VM Opt ...
- springboot+eureka+mybatis+mysql环境下报504 Gateway Time-out
1.test环境下的数据库配置的 driver和url有问题, 在工程日志中的表现是不能打印出最新的日志,在部署前的日志能看到报错:
- [NOIP10.4模拟赛]3.z题解--思维
题目链接: 咕咕 闲扯: 哈哈这道T3考场上又敲了5个namespace,300+行,有了前车之鉴还对拍过,本以为子任务分稳了 结果只有30分哈哈,明明用极限数据对拍过不知怎么回事最后数据又是读不全, ...
- UART串口简介
通用异步收发传输器(Universal Asynchronous Receiver Transmitter) 原理 发送数据时,CPU将并行数据写入UART,UART按照一定的格式在一根电线上串行发出 ...