Greenplum实战之查询优化
本文主要分为三部分:
- GP优化需要准备的一些关于优化之外的知识,包括清空缓存、性能监控、执行计划分析。
- 具体优化措施,从以下四个方面考虑:
- 表、字段
- sql
- GP配置、服务器配置
- 硬件及节点资源
- GP的性能极限分析
1. 前置知识
1.1 GP清除缓存
数据库一般都有缓存,所以我们为了测试查询性能,需要将缓存清除。
停止数据库并不能清空缓存,因为缓存是由操作系统创建的,一般只有重启操作系统可以完全清空.
参考思路如下:
#!/usr/bin/sudo bash
gpstop -r
sync //清空高速缓存前尝试将数据刷新至磁盘
//释放linux内存
echo 1 > /proc/sys/vm/drop_caches
echo 2 > /proc/sys/vm/drop_caches
echo 3 > /proc/sys/vm/drop_caches
gpstart
1.2 性能监控Performance Monitor
新一代Greenplum监控管理平台Pivotal Greenplum Command Center (GPCC)。
实际使用过程中发现对于6-8秒的查询(单表亿级数据),GPCC反应比较慢,CPU、IO等信息为0,目前拟采用其他工具,实时监控CPU、内存、IO、网络等信息。
1.3 执行计划分析
- EXPLAIN会为查询显示其查询计划和估算的代价,但是不执行该查询。
- EXPLAIN ANALYZE除了显示查询的查询计划之外,还会执行该查询。EXPLAIN ANALYZE会丢掉任何来自SELECT语句的输出,但是该语句中的其他操作会被执行(例如INSERT、UPDATE或者DELETE)。
https://www.cnblogs.com/arthurqin/p/6243277.html
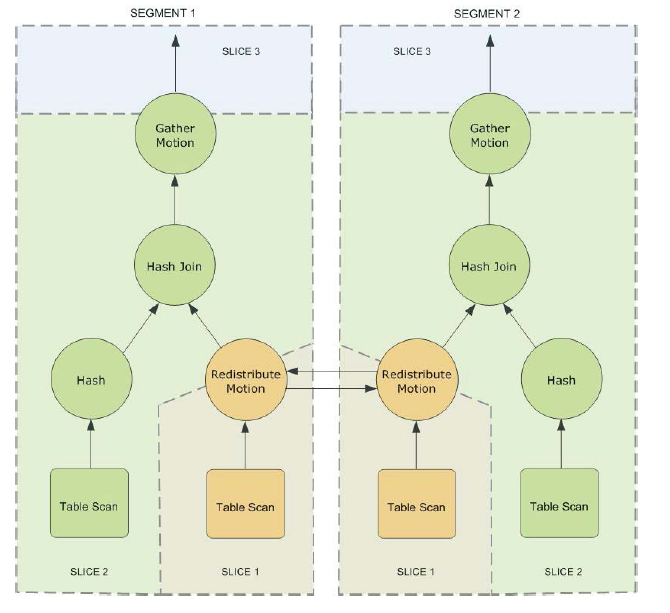
slice、motion
GPDB 有一个特有的算子:移动( motion )。移动操作涉及到查询处理期间在 Segment 之间移动数据。motion 分为广播( broadcast )、重分布( redistribute motion )、Gather motion。正是 motion 算子将查询计划分割为一个个 slice ,上一层 slice 对应的进程会读取下一层各个 slice 进程广播或重分布的数据,然后进行计算。
每一个广播或重分布或gather会产生一个slice。每一个切片在每个数据节点会对应发起一个进程来处理该slice负责的数据。SQL中要控制切片的数量,如果太多,应适当将sql拆分,避免由于进程太多,给数据库、机器带来太多的负担,也容易导致sql失效。
Gather motion的作用就在于将每个节点上面的中间结果集中到主节点上面。
优化
总的思路
- 表、字段
- sql
- GP配置、OS配置
- 硬件及节点资源
1、表字段设计
如上面例子所示,优化某些字段的设计,以提高性能
2、表存储方式
Heap 或 Append-Only存储:GP默认使用堆表。堆表最好用在小表,如:维表(初始化后经常更新)。Append-Only表不能update和delete。一般用来做批量数据导入。 不建议单行插入。
多列查询请求
- 行存储 => 在select或where子句中,查询所有列或大部分列
- 列存储 => 在where或having子句中,查询单列的值汇总或单行过滤
若数据需要频繁地更新或者插入,则使用行存储。
若需要同时访问一个表的很多字段,则使用行存储。
对于通用或者混合型业务,建议使用行存储。
若查询访问的字段数目较少,或者仅在少量字段上进行聚合操作,则使用列存储。
若仅常常修改表的某一字段而不修改其他字段,则使用列存储。
3、压缩
对于大AO表和分区表使用压缩,以提高系统I/O。
在字段级别配置压缩。
考虑压缩比和压缩性能之间的平衡。
压缩的性能取决于硬件、查询调优设置、其它因素。
- QuickLZ - 低压缩率、低cpu消耗、压缩数据块
- zlib - 高压缩率、低速
4、列存储
列存里面可以启动压缩。
只适合append-only表。
5、索引
高基数的列(唯一值多)
一般来说,在Greenplum数据库中索引不是必需的。
对于高基数的列存储表,如果需要遍历且查询选择性较高,则创建单列索引。
频繁更新的列不要建立索引。
在加载大量数据之前删除索引,加载结束后再重新创建索引。
优先使用 B 树索引。
不要为需要频繁更新的字段创建位图索引。
不要为唯一性字段、基数非常高或者非常低的字段创建位图索引。
不要为事务性负载创建位图索引。
一般来说不要索引分区表。如果需要建立索引,则选择与分区键不同的字段。
可优化部分小结果集查询。
6、分布键
7、 分组扩展
Greenplum数据库的GROUP BY扩展可以执行某些常用的计算,且比应用程序或者存储过程效率高。
GROUP BY ROLLUP(col1, col2, col3)
GROUP BY CUBE(col1, col2, col3)
GROUP BY GROUPING SETS((col1, col2), (col1, col3))
8、分区
黄金法则
目前Greenplum支持LIST和RANGE两种分区类型。
分区的目的是尽可能的缩小QUERY需要扫描的数据量,因此必须和查询条件相关联。
只为大表设置分区,不要为小表设置分区。
仅在根据查询条件可以实现分区裁剪时使用分区表。
建议优先使用范围 (Range) 分区,否则使用列表 (List) 分区。
根据查询特点合理设置分区。
不要使用相同的字段既做分区键又做分布键。
不要使用默认分区。
避免使用多级分区;尽量少地创建分区,每个分区的数据会多些。
通过查询计划的 EXPLAIN 结果来确保对分区表执行的查询是选择性扫描(分区裁剪)。
对于列存储的表,不要创建过多的分区,否则会造成物理文件过多:
Physical files = Segments * Columns * Partitions。
9、根据监控定位资源占用较多的情况:
- CPU
- 内存
- IO
- 网络
笔者目前耗费资源比较多的是内存,主要需要优化内存、增加内存。
10、 数据库配置优化
Greenplum企业应用实战第8章
查询缓存
线程数量与内存
gp_statement_mem :单个查询可以使用的内存总量。如果它太大,则并发数越小。所以要有所折衷。
11、硬件选型
- Greenplum企业应用实战第8章
- gp性能管理
硬件考虑因素:
- (1)Segment服务器具有相同的硬件配置;推荐:双核,32GB Mem,高速磁盘阵列,4个以上千兆网口。
- (2)Master服务器具有较高的cpu和内存资源;
- (3)基准性能:3.2GB/s(综合的系统磁盘读写速度)
12、 估值计算
估值计算是统计学的常用手段。因为数据量庞大,求精确数值需要耗费巨大的资源,而统计分析并不要求完全精确的数据,因此估值计算是一种折中的方法,广泛应用于统计分析场景。
秒级任意维度分析1TB级大表 - 通过采样估值满足高效TOP N等统计分析需求
13、 服务器参数调整
- 共享内存
- 网络
- 系统对用户的限制,比如打开文件句柄的数量。
GP的性能极限分析
MPP架构
Greenplum实现了基于数据库的分布式数据存储和并行计算
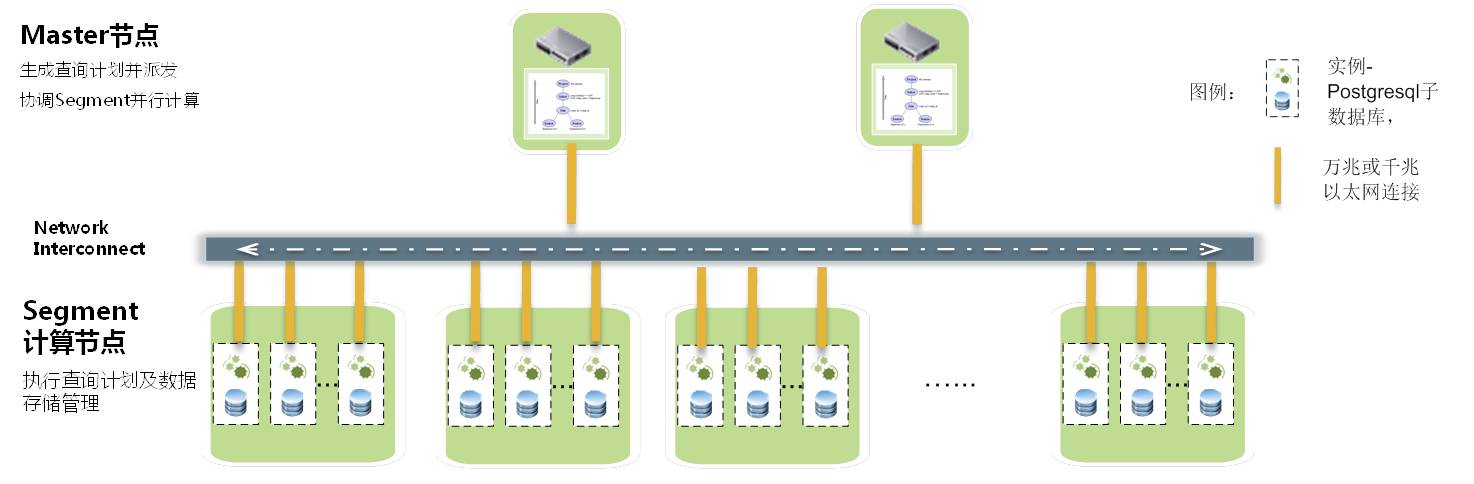
MPP架构的极限思考?
根据木桶原理以及这篇文章(https://clickhouse.yandex/benchmark.html#["100000000",["Greenplum"],["0","1","2"]])的测试结果,segment节点的PG实例的处理速度决定。如果OLAP的处理速度在3秒内,可以计算单segment在3秒以内能处理多少速度,然后再做横向扩展。
参考文献
- Greenplum性能调优
- gp性能管理
- http://greenplum.cn/articles/gpdb-best-practice.html
- 清空postgresql shared_buffers
- https://yq.aliyun.com/articles/73038?utm_campaign=wenzhang&utm_medium=article&utm_source=QQ-qun&201745&utm_content=m_15961
- Greenplum优化--SQL调优篇
- https://github.com/digoal/blog/blob/master/201707/20170725_01.md#greenplum-性能评估公式---阿里云hybriddb-for-postgresql最佳实践
Greenplum实战之查询优化的更多相关文章
- 白日梦的Elasticsearch实战笔记,ES账号免费借用、32个查询案例、15个聚合案例、7个查询优化技巧。
目录 一.导读 二.福利:账号借用 三._search api 搜索api 3.1.什么是query string search? 3.2.什么是query dsl? 3.3.干货!32个查询案例! ...
- 白日梦的Elasticsearch实战笔记,32个查询案例、15个聚合案例、7个查询优化技巧。
目录 一.导读 三._search api 搜索api 3.1.什么是query string search? 3.2.什么是query dsl? 3.3.干货!32个查询案例! 四.聚合分析 4.1 ...
- MongoDB实战指南(二):索引与查询优化
数据库保存记录的机制是建立在文件系统上的,索引也是以文件的形式存储在磁盘上,在数据库中用到最多的索引结构就是B树.尽管索引在数据库领域是不可缺少的,但是对一个表建立过多的索引会带来一些问题,索引的建立 ...
- MySQL 索引原理概述及慢查询优化实战
MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能出色,但所谓“好马配好鞍”,如何能够更好的使用它,已经成为开发工程师的必修课,我们经常会从职位 ...
- mysql实战优化之八:关联查询优化
1. 多表连接类型 1. 笛卡尔积(交叉连接) 在MySQL中可以为CROSS JOIN或者省略CROSS即JOIN,或者使用',' 如: 由于其返回的结果为被连接的两个数据表的乘积,因此当有WHE ...
- PostgreSQL和Greenplum、Npgsql
PostgreSQL和Greenplum.Npgsql 想着要不要写,两个原因“懒”和“空”.其实懒和空也是有联系的,不是因为懒的写,而是因为对PostgreSQL和Npgsql的知识了解匮乏,也就懒 ...
- greenplum和postgresql
想着要不要写,两个原因"懒"和"空".其实懒和空也是有联系的,不是因为懒的写,而是因为对PostgreSQL和Npgsql的知识了解匮乏,也就懒得写.好了,开头 ...
- Greenplum 的分布式框架结构
Greenplum 的分布式框架结构 1.基本架构 Greenplum(以下简称 GPDB)是一款典型的 Shared-Nothing 分布式数据库系统.GPDB 拥有一个中控节点( Master ) ...
- 《开源大数据分析引擎Impala实战》目录
当当网图书信息: http://product.dangdang.com/23648533.html <开源大数据分析引擎Impala实战>目录 第1章 Impala概述.安装与配置.. ...
随机推荐
- 高阶函数 filter map reduce
const app=new Vue({ el:'#app', data:{ books:[{ id:1, name:"算法导论", data: '2006-1', price:39 ...
- vue+element-ui 实现table单元格点击编辑,并且按上下左右键单元格之间切换
通过我的测试我发现两个两种方法来编辑单元格的内容 第一种点击编辑: 我是给td里添加一个input,将值赋值给input,当失去焦点的时候将input的值付给td原来的内容,然后将input删除, 代 ...
- 值得收藏的Python第三方库
网络站点爬取 爬取网络站点的库Scrapy – 一个快速高级的屏幕爬取及网页采集框架.cola – 一个分布式爬虫框架.Demiurge – 基于PyQuery 的爬虫微型框架.feedparser ...
- mysql 中表与表之间的关系
如何找出两张表的对应关系 分析步骤: 1.先找出左表的角度去找 是否左表的多条记录可以对应右表的一条记录,如果是,则证明左表的一个字段foreign key 右表一个字段 (通常是id) 2.再站 ...
- 利用Python进行数据分析_Pandas_数据结构
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 首先,需要导入pandas库的Series和DataFrame In [21] ...
- WUSTOJ 1285: Factors(Java)
1285: Factors 参考 hadis_fukan的博客--wustoj 1285 Factors 题目 输入一个数n,找出1~n之间(包括1,n)的质因子最多的数(x)的质因子个数(f ...
- docker 实践四:仓库管理
本篇我们来了解 docker 仓库的内容. 注:环境为 CentOS7,docker 19.03 仓库(Responsitory)是集中存放镜像的地方,又分公共仓库和私有仓库. 注:有时候容易把仓库与 ...
- 用python将项目中的所有代码(或txt)合并在一个文件中
设计模式开卷考试给的例子代码都是一个类一个java,实在太恶心了,所以写了一个python脚本. import os fileansdir=r'C:\Users\tonyson_in_the_rain ...
- codefroce 854 A.Fraction
题解:贪心,每次从能够出发的飞机中取一个最大的就好啦,用一个队列维护一下~ ac代码: #include <cstdio> #include <iostream> #inclu ...
- HotSpot JVM目录
一.知识结构整理 jvm体系大体分四大块: 类的加载机制 jvm内存结构 GC算法 垃圾回收 GC分析 命令调优 二.运行时JVM结构组成及作用 http://www.cnblogs.com/imxi ...