wordcloud:让你的词语变成黑云
楔子
什么是词云?在网络上我们经常可以看到一张图片,上面有一大堆大小不一的文字,便是词云。词云一般是根据输入的大量词语生成的,如果某个词语出现的次数越多,那么相应的大小就会越大。我们后面演示的时候就知道了
安装
python中有一个专门用来生成词云的模块:wordcloud,如果在linux上直接pip install wordcloud即可,但是在Windows上会失败,我们可以去https://www.lfd.uci.edu/~gohlke/pythonlibs/这个官网下载合适的版本,然后安装即可。
生成词云
我们词云的主要实现是用过 wordcloud 模块中的 WordCloud 类实现的,我们先来了解一下这个 WordCloud 类。
# 导入模块
from wordcloud import WordCloud
# 准备文本数据,是一个字符串,单词之间用空格分割
sentence = "hello satori hello mashiro hello satori"
# 创建词云对象
wc = WordCloud()
# 根据文本生成词云
wc.generate(sentence)
# 保存为图片
wc.to_file("1.png")

我们看到单词就显示在了图片上,如果单词一多就像天空的云彩一样漂浮着,并且如果单词出现的频率越高,那么该单词在图片上大小就越大。
虽然词云生成了,但是风格是固定的,我们可不可以调整呢,显然是可以的。
可以向WordCloud里面传入参数来调整风格,我们先看看这个类里面都支持哪些参数,后面会演示
width:词云的宽,默认是400像素height:词云的高,默认是200像素background_color:词云的背景颜色,默认是黑色font_path:生成的词云所使用的字体,传入一个字体所在的路径mask:词云背景图片,接收一个numpy中的数组。可以使用PIL或者cv2读取图片,然后生成数组stopwords:要屏蔽的词语,接收一个集合,生成词云的时候会忽略掉屏蔽的词语max_font_size:字体的最大大小,默认为Nonemin_font_size:字体的最小大小,默认为Nonemax_words:要显示的词的最大个数,默认为200。比如我们的文本数据有10000个单词不重复单词,肯定不可能全部显示,而是按照出现的频率高低排序,选择出现频率高的N个单词,默认是200个contour_width:轮廓粗细contour_color:轮廓颜色scale:用来控制生成的图片大小的,默认为1。如果我们改成了10,那么生成的图片大小会扩大10倍。这个参数不用管,没太大用,默认为1即可
我们来演示一下这些参数
from wordcloud import WordCloud
sentence = "She is neither heterosexual nor homosexual She is sapiosexual"
wc = WordCloud(
width=500, # 设置宽度为500px
height=300, # 设置高度为300px
background_color='pink', # 设置背景为粉色
stopwords={"heterosexual", "homosexual"}, # 设置禁用词,在生成的词云中不会出现set集合中的词
max_font_size=100, # 设置最大的字体大小,所有词都不会超过100px
min_font_size=10, # 设置最小的字体大小,所有词都会超过10px
max_words=10 # 最多生成10个词,当然这里单词比较少,看不出来什么
)
wc.generate(sentence)
wc.to_file("2.png")
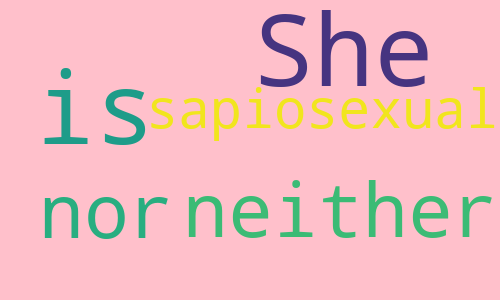
我们看到图片变宽了、变高了,背景变成粉色了,并且也没有出现我们禁用的单词
但是这个图片是正方形的,而我们平常见到词云是有形状的,可以是一个圆形、或者一个人的形状等等。显然那是根据图片生成的,而wordcloud也支持我们这么做,下面来演示一下
from wordcloud import WordCloud
from PIL import Image
import numpy as np
# 一篇英文文章
sentence = open("1.txt").read()
# 加载一张图片,转化成numpy中的数组
mask = np.array(Image.open("哆啦A梦.png"))
# 传入mask
wc = WordCloud(mask=mask)
wc.generate(sentence)
wc.to_file("3.png")

下面是我们原始的图片,"多啦A梦.png"

会自动将周围的白色区域给忽略掉,因此选择的图片建议最好是白底的。
我们目前生成词云所使用的单词都是英文的,那中文可不可以呢?我们来看一下
from wordcloud import WordCloud
wc = WordCloud()
wc.generate("古明地觉真的是世界上最可爱的美少女")
wc.to_file("4.png")
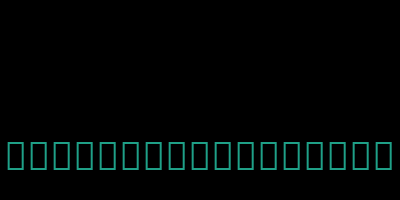
显然默认是不支持的,显示的是一个个的矩形。那怎么解决呢,很简单,指定一个支持中文的字体就可以了
from wordcloud import WordCloud
wc = WordCloud(font_path="msyh.ttc")
wc.generate("古明地觉真的是世界上最可爱的美少女")
wc.to_file("5.png")

但是显示的是一整句话,很正常,因为wordcloud默认是以空格分隔单词的,所以对于英文我们不需要做什么处理,因为英文单词之间就是以空格分隔的。但是中文,则是所有的汉字都连在一起,因此整体被当成了一个词。因此这个时候推荐使用jieba分词,将单词进行分隔,但是jieba怎么使用我们就不细致讲解了,我的其它随笔里面有介绍。
这里以出师表为例,演示一下
from wordcloud import WordCloud
import jieba
sentence = open("1.txt").read()
# 分词得到列表,手动使用空格拼接
sentence = " ".join(jieba.cut(sentence))
wc = WordCloud(font_path="msyh.ttc")
wc.generate(sentence)
wc.to_file("6.png")

wordcloud:让你的词语变成黑云的更多相关文章
- Word Cloud (词云) - Python
>>What's Word Cloud 词云 (Word Cloud)是对文本中出现频率较高的词语给予视觉化展示的图形, 是一种常见的文本挖掘的方法.目前已有多种数据分析工具支持这种图形, ...
- wordcloud:让你的词语像云朵一样美
介绍 对文本中出现频率较高的关键词给予视觉化的显示 使用 python import jieba import codecs import wordcloud file = r"C:\U ...
- python wordcloud 对电影《我不是潘金莲》制作词云
上个星期五(16/11/18)去看了冯小刚的最新电影<我不是潘金莲>,电影很长,有点黑色幽默.看完之后我就去知乎,豆瓣电影等看看大家对于这部电影的评价.果然这是一部很有争议的电影,无论是在 ...
- R语言之词云:wordcloud&wordcloud2安装及参数说明
一.wordcloud安装说明 install.packages("wordcloud"); 二.wordcloud2安装说明 install.packages("dev ...
- python wordcloud
python wordcloud 对电影<我不是潘金莲>制作词云 上个星期五(16/11/18)去看了冯小刚的最新电影<我不是潘金莲>,电影很长,有点黑色幽默.看完之后我就去知 ...
- 爬取豆瓣电影影评,生成wordcloud词云,并利用监督学习根据评论自动打星
本文的完整源码在git位置:https://github.com/OceanBBBBbb/douban-ml 爬取豆瓣影评 爬豆瓣的影评比较简单,豆瓣没有做限制,甚至你都不用登陆就可以看全部,我这里用 ...
- 使用jieba库与wordcloud库第三方库进行词频统计
一.jieba库与wordcloud库的使用 1.jieba库与wordcloud库的介绍 jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最 ...
- 词云wordcloud入门示例
整体简介: 词云图,也叫文字云,是对文本中出现频率较高的“关键词”予以视觉化的展现,词云图过滤掉大量的低频低质的文本信息,使得浏览者只要一眼扫过文本就可领略文本的主旨. 基于Python的词云生成类库 ...
- wordcloud制作logo
准备工作: 1.txt文本(ASCII) 2.参照图(色差大或自行调整扫描参数) 3.pycharm安装wordcloud 源码: from os import path from PIL impor ...
随机推荐
- 依赖注入框架之dagger2
主页: https://github.com/google/dagger 历史 * Dagger1是由Square公司受到Guice(https://github.com/google/guice)启 ...
- FTP\SFTP连接命令
五.ftp连接 输入:ftp 10.18.49.19 2121六.输入账号密码 zhangsan/sdjg34t#七.输入:ls 查看文件是否上传 如上传 输入:bye ...
- python格式化字符串format的用法
填充与对齐 填充常跟对齐一起使用 ^.<.>分别是居中.左对齐.右对齐,后面带宽度 :号后面带填充的字符,只能是一个字符,不指定的话默认是用空格填充 比如 In [15]: '{:> ...
- android手机使用Fiddler
Fiddler是一款免费的抓包.调试工具,比Wireshark要小巧,更简洁,这里介绍如何通过WIFI来抓取Android手机的HTTP和HTTPS包. 一.手机端配置 电脑配置WIFI后,手机需要设 ...
- Java界面程序实现图片的放大缩小
Java界面程序实现图片的放大缩小.这个程序简单地实现了图片的打开.保存.放大一倍.缩小一倍和固定缩放尺寸,但是并没有过多的涵盖对图片的细节处理,只是简单地实现了图片大小的放缩. 思维导图如下: 效果 ...
- 利用python列出当前目录下的所有文件
问题 当一个目录下有很多文件夹或者文件,我们想分析各个文件的名字,这时就可以写一个函数,列出当前目录下所有文件名字. 代码 src_dir = r'./' # 源文件目录地址 def list_all ...
- Docker在windows环境下的安装部署
一.准备 系统环境:Windows 10 64bit Docker安装包:Docker for Windows Installer.exe 二.安装步骤 1.开启系统的hyper-v 2. 重启电脑后 ...
- 渗透测试 - KALI Linux 学习 - kali linux如何启动METASPLOIT服务
kali 2.0 已经没有metasploit 这个服务了,所以service metasploit start 的方式不起作用. 在kali 2.0中启动带数据库支持的MSF方式如下: #1 首先 ...
- JAVA师徒架构班 - 带徒模式
(转: http://www.jeecg.org/forum.php?mod=viewthread&tid=2291&extra=page%3D1&page=1) 一个程序员技 ...
- 网站性能优化(website performance optimization)
提高代码运行速度,或许我们从来没有优化这些页面来提高速度 想要开发优秀的网站,你必须了解你的用户,知道他们想要达到什么目的,同时还要明白浏览器的工作原理,从而能够打造快速良好的体验,我最近在PageS ...