爬虫之requests库的使用
get基本请求
响应对象的属性:
# 获取响应对象中的内容是str格式
text
# 获取响应对象中的内容是二进制格式的
content
# 获取响应状态码
status_code
# 获取响应头信息
headers
# 获取请求的url
url
import requests
url = "https://www.cnblogs.com/songzhixue/p/10717975.html"
# 获得一个响应对象
response = requests.get(url=url)
# 调用响应对象中的text属性获取请求结果为字符串形式
print(response.text)
带参数的get请求
方式一:
import requests
url = "http://www.baidu.com/s?wd=周杰伦"
# requests模块可以自动将url中的汉字进行转码
response = requests.get(url).text
with open("./zhou.html","w",encoding="utf-8") as fp:
fp.write(response)
方式二:
将参数以字典的形式传给params参数
import requests
choice = input("请输入搜索条件>>>:").strip()
params = {
"wd":choice
}
# https://www.baidu.com/s?wd=周杰伦
url = "http://www.baidu.com/s?"
# 带参数的get请求
response = requests.get(url,params)
# 获取响应状态码
response.status_code
添加请求头信息
请求头以字典的方式传给headers参数
import requests
choice = input("请输入搜索条件>>>:").strip()
params = {
"wd":choice
}
# https://www.baidu.com/s?wd=周杰伦
url = "http://www.baidu.com/s?"
# 封装请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
# 带参数的get请求
response = requests.get(url,params,headers=headers)
# 获取响应状态码
response.status_code
post请求
豆瓣登录
开发者抓包工具抓取post请求的登录信息
基于Ajax的get请求
### 抓取豆瓣影评###
import json
import requests
# url = "https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=20"
# 获取ajax的请求网址(基于ajax的get请求)
url = 'https://movie.douban.com/j/search_subjects?'
# 自定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}
# 构建请求参数
params = {
'type': 'movie',
'tag': '热门',
'sort': 'recommend',
'page_limit': '1', # 显示多少数据
'page_start': '', # 从第几页开始显示
}
# 请求目标url
response = requests.get(url=url,params=params,headers=headers)
# 拿到响应数据,json格式的字符串
json_str = response.text
# 对响应数据反序列化得到字典
code = json.loads(json_str)
# 在字典中取出想要的数据
for dic in code["subjects"]:
rate = dic["rate"]
title = dic["title"]
print(title,rate)
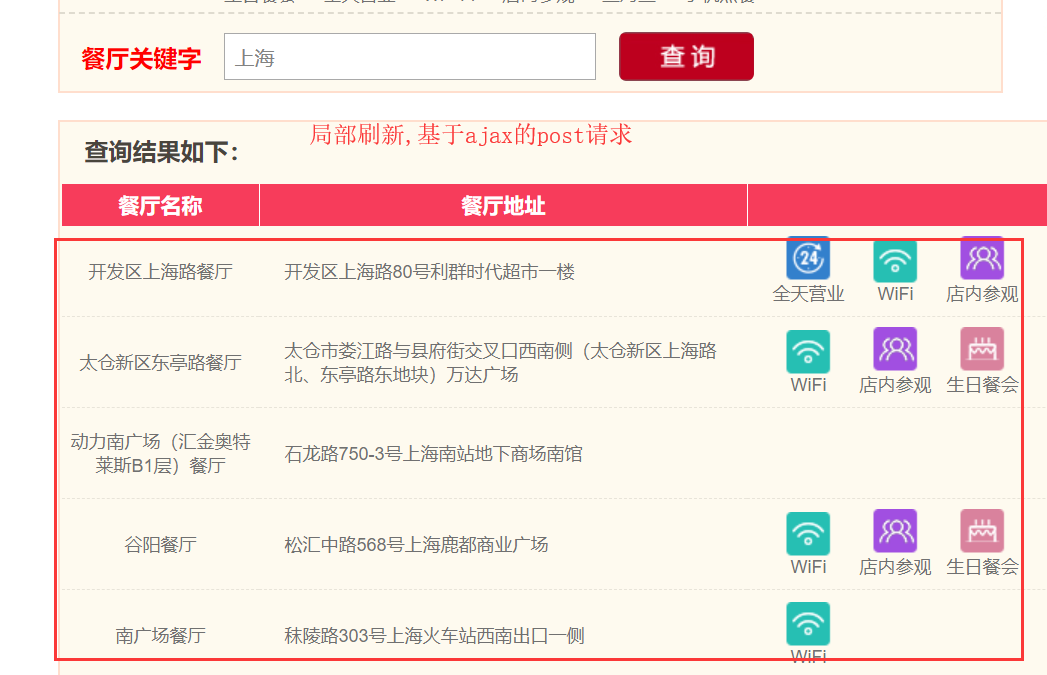
基于Ajax的post请求
### 抓取肯德基餐厅位置信息###
import json
import requests
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
data = {
'cname': '',
'pid': '',
'keyword': '上海',# 查询城市
'pageIndex':'', # 显示第几页的数据
'pageSize': '', # 一页显示多少数据
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
response = requests.post(url=url,data=data,headers=headers)
response.text
使用代理
import requests
# www.goubanjia.com
# 快代理
# 西祠代理
url = "http://www.baidu.com/s?wd=ip"
prox = {
"http":"39.137.69.10:8080",
"http":"111.13.134.22:80",
}
# 参数proxies
response = requests.get(url=url,proxies=prox).text
with open("./daili.html","w",encoding="utf-8") as fp:
fp.write(response)
print("下载成功")
requests上传文件
https://blog.csdn.net/five3/article/details/74913742
爬虫之requests库的使用的更多相关文章
- Python爬虫之requests库介绍(一)
一:Requests: 让 HTTP 服务人类 虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 ...
- python爬虫之requests库
在python爬虫中,要想获取url的原网页,就要用到众所周知的强大好用的requests库,在2018年python文档年度总结中,requests库使用率排行第一,接下来就开始简单的使用reque ...
- 爬虫相关--requests库
requests的理想:HTTP for Humans 一.八个方法 相比较urllib模块,requests模块要简单很多,但是需要单独安装: 在windows系统下只需要在命令行输入命令 pip ...
- Python爬虫:requests 库详解,cookie操作与实战
原文 第三方库 requests是基于urllib编写的.比urllib库强大,非常适合爬虫的编写. 安装: pip install requests 简单的爬百度首页的例子: response.te ...
- Python爬虫之requests库的使用
requests库 虽然Python的标准库中 urllib模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests宣传是 "HTTP for ...
- 【Python爬虫】爬虫利器 requests 库小结
requests库 Requests 是一个 Python 的 HTTP 客户端库. 支持许多 HTTP 特性,可以非常方便地进行网页请求.网页分析和处理网页资源,拥有许多强大的功能. 本文主要介绍 ...
- 爬虫值requests库
requests简介 简介 Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库 ,使用起来比urllib简洁很多 因为是第三方库, ...
- (爬虫)requests库
一.requests库简介 urllib库和request库的作用一样,都是服务器发起请求数据,但是requests库比urllib库用起来更方便,它的接口更简单,选用哪种库看自己. 如果没有安装过这 ...
- 【Python爬虫】Requests库的基本使用
Requests库的基本使用 阅读目录 基本的GET请求 带参数的GET请求 解析Json 获取二进制数据 添加headers 基本的POST请求 response属性 文件上传 获取cookie 会 ...
- python网络爬虫之requests库
Requests库是用Python编写的HTTP客户端.Requests库比urlopen更加方便.可以节约大量的中间处理过程,从而直接抓取网页数据.来看下具体的例子: def request_fun ...
随机推荐
- 基于白名单的Payload
利用 Msiexec 命令DLL反弹 Msiexec是Windows Installer的一部分.用于安装Windows Installer安装包(MSI),一般在运行Microsoft Update ...
- 牛客 216 C 小K的疑惑
大意: 给定树, 求多少个三元组(i,j,k), 满足dis(i,j)=dis(j,k)=dis(k,i). 刚开始想复杂了, 暴力统计了所有的情况. #include <iostream> ...
- 怎样查看或修改网页的标题title
网页的标题一般指的是 <title>标签之间的文本节点值, 它会显示在浏览器的标签页上, 我们可以通过 document.title 来查看或修改它: document.title; // ...
- css鼠标悬浮控制元素隐藏与显示
在网页开发中经常有需求是鼠标移动到一个元素A身上时,另外一个元素B显示. 如下图 当鼠标移到图片上时,相关的描述从下方显示出来. css实现原理与情景: A 是 B 的父元素 B 默认隐藏 B{opa ...
- 许愿墙JQ
<!doctype html> <html> <head> <meta charset="utf-8"> <t ...
- React的性能优化
1. 在constructor中绑定事件函数的this指向 把一个函数赋值给一个变量,然后用那个变量去执行函数会造成this的丢失,所以需要绑定this,把绑定放在构造函数中可以保证只绑定一次函数,如 ...
- Mysql与java对应的类型表
1. 概述 在使用Java JDBC时,你是否有过这样的疑问:MySQL里的数据类型到底该选择哪种Java类型与之对应?本篇将为你揭开这个答案. 2. 类型映射 java.sql.Types定义了常 ...
- CAFFE(三):Ubuntu下Caffe框架安装(仅仅Caffe框架安装)
步骤一. 从github上下载(克隆)安装包 1.1 在你要安装的路径下 clone 此处我直接安装到home目录,执行: ~$ cd ~ 2 :~$ git clone https://github ...
- Linux磁盘及文件系统管理2
创建文件系统: 格式化:低级格式化(分区之前进行,划分磁道).高级格式化(分区之后对分区进行,创建文件系统) 元数据区,数据区 元数据区: 文件元数据:inode(index node) 大小.权限. ...
- 数据结构课后练习题(练习三)7-5 Tree Traversals Again (25 分)
7-5 Tree Traversals Again (25 分) An inorder binary tree traversal can be implemented in a non-recu ...