sfmlearner剖析
下面是slam14讲公式5.7
$Z\left(\begin{array}{l}{u} \\ {v} \\ {1}\end{array}\right)=\left(\begin{array}{ccc}{f_{x}} & {0} & {c_{x}} \\ {0} & {f_{y}} & {c_{y}} \\ {0} & {0} & {1}\end{array}\right)\left(\begin{array}{l}{X} \\ {Y} \\ {Z}\end{array}\right) \triangleq \boldsymbol{K P}
$ 公式(0)
就是一个三维点投影到二维点的公式
可以写成:
$ depth*uv = K*XYZ \tag{1}$
这里我 用uv代表图像坐标系里的二维点,XYZ代表三维的空间的点
然后还有一个公式5.8
$Z \boldsymbol{P}_{u v}=Z\left[\begin{array}{l}{u} \\ {v} \\ {1}\end{array}\right]=\boldsymbol{K}\left(\boldsymbol{R} \boldsymbol{P}_{w}+\boldsymbol{t}\right)=\boldsymbol{K} \boldsymbol{T} \boldsymbol{P}_{w}$
这个是考虑有一个变换之后的投影公式,可以写成:
$depth*uv = K*T*XYZ \tag{2}$
因为我们要估计的就是深度,所以不能简单的像slam14讲里头把深度Z或者depth省略掉。
slam14讲随意省略深度值Z的做法在深度估计里不太好。
然后考虑下面这种情况:
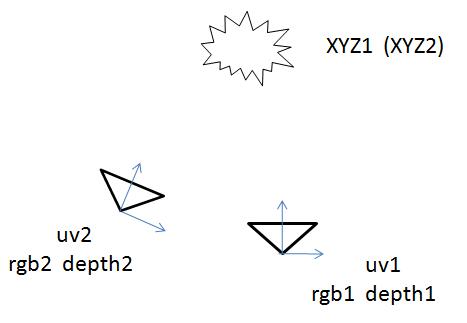
两个相机观测 同一点云
相机1有坐标系1,相机2有坐标系2
在坐标系1下,观测到的点云的坐标为XYZ1
在坐标系2下,观测到的点云的坐标为XYZ2。
在相机1处观测到彩色图像rgb1和深度图像depth1,相机2处类似。
然后两个相机的点云有如下的转换关系:
depth1是标量,所以放在前面
结合公式3得到
$XYZ_2 = \boldsymbol{T}_{21}*depth_1*K^{-1}*uv_1$
再把上式代入公式5得到:
$depth_2*uv_2 = K*\boldsymbol{T}_{21}*depth_1*K^{-1}*uv_1$
下面是sfmlearner论文里头那个公式:
$p_{s} \sim K \hat{T}_{t \rightarrow s} \hat{D}_{t}\left(p_{t}\right) K^{-1} p_{t}$
比较上述两个公式,就知道论文里的公式是怎么来的了,
论文的公式把depth2给省略了,就像slam14讲里头一样。
ps:其实这里可以考虑双目相机的情况,在坐标系1和坐标系2处的两个相机的K不一样,
可以给予双目深度估计更大的灵活性,不需要做双目校正直接训练,
代价就是两个相机有各自的dispnet,参数量更大。灵活性和计算量不能兼得。
上面只是公式,下面开始研究代码
假如你在相机1处有一张彩色图像rgb和一张深度图像depth。
rgb图像是3通道的,长宽为h x w
depth图像是单通道的,每个像素代表深度值Z,长宽和rgb图像一样。
公式0的另一种形式如下:
$ u = fx*X/Z + cx $
$ v = fy*Y/Z + cy $
转换一下得到:
$ X = (u-cx)*Z/fx $
$ Y = (v-cy)*Z/fy $
uv是图像坐标系上的点,因此:
u 的范围为[0, w-1]
v 的范围为[0, h-1]
Z是深度,是depth上每一个像素所代表的值。
u,v,cx,cy,fx,fy,Z都已知,因此我们可以根据上述公式,利用彩色图像rgb和深度图像depth算
出三维坐标XYZ。其实这就是公式6的操作。
当然不应该用for循环去计算每个三维坐标,而应该用meshgrid和矩阵相乘来计算,具体实现如下:
import numpy as np
import cv2 color = cv2.imread('xxx') # 3 channel
depth = cv2.imread('xxx') # 1 channel # 这里假设图片长宽为 640 x 480
h = 480
w = 640 u, v = np.meshgrid(np.arange(0, w), np.arange(0, h)) depthScale = 1 Z = depth/depthScale
X = (u-cx)*Z/fx
Y = (v-cy)*Z/fy X = X.reshape(307200, 1)
Y = Y.reshape(307200, 1)
Z = Z.reshape(307200, 1) XYZ = np.hstack((X, Y, Z))
然后你就得到了一个点云的坐标数据
实现公式3的话,还要考虑齐次、非齐次的问题,就是多增加一行或者一列之类的问题。
在sfmlearner的pytorch代码中:
tgt_img相当于在坐标系1上,ref_img相当于在坐标系2上!!!
ref_img可以有很多张,ref_img的张数加上tgt_img就是sequence length
视差网络 disp_net 生成4个尺度的视差图
print("disp1 size:", disp1.size() ) # torch.Size([1, 1, 128, 416])
print("disp2 size:", disp2.size() ) # torch.Size([1, 1, 64, 208])
print("disp3 size:", disp3.size() ) # torch.Size([1, 1, 32, 104])
print("disp4 size:", disp4.size() ) # torch.Size([1, 1, 16, 52]) 然后将视差图转换成深度图:
depth = [1/disp for disp in disparities] 视差图的倒数就是深度图 对于pose_net
tgt_img = torch.rand([1, 3, 128, 416])
ref_imgs = [torch.rand([1, 3, 128, 416]), torch.rand([1, 3, 128, 416]) ] explainability_mask, pose = pose_exp_net(tgt_img, ref_imgs) print("pose size:", pose.size() ) # torch.Size([1, 2, 6])
tgt_img相当于相机1的图像,ref_img是相机2的图像。
考虑photometric_reconstruction_loss函数中计算的多个scale中的第一个scale,即128 x 416的尺寸:
然后执行了下面这个操作:
for i, ref_img in enumerate(ref_imgs_scaled):
# 遍历ref_imgs
current_pose = pose[:, i] ref_img_warped = \
inverse_warp(ref_img,
depth[:,0], # torch.Size([1, 128, 416])
current_pose, # torch.Size([1, 6])
intrinsics_scaled,
rotation_mode,
padding_mode)
传进去的 depth 和 current_pose
根据inverse_warp函数的说明,前面这个1是留给batchsize的
def set_id_grid(depth):
b, h, w = depth.size()
i_range = torch.arange(0, h).view(1, h, 1).expand(1,h,w).type_as(depth) # [1, H, W]
j_range = torch.arange(0, w).view(1, 1, w).expand(1,h,w).type_as(depth) # [1, H, W]
ones = torch.ones(1,h,w).type_as(depth) pixel_coords = torch.stack((j_range, i_range, ones), dim=1) # [1, 3, H, W]
return pixel_coords
current_pixel_coords = pixel_coords[:,:,:h,:w].expand(b,3,h,w).reshape(b, 3, -1) # [B, 3, H*W]
cam_coords = (intrinsics_inv @ current_pixel_coords).reshape(b, 3, h, w)
return cam_coords * depth.unsqueeze(1)
注意里头的intrinsics_inv,所以上面的代码相当于
$ depth_1*K^{-1}*uv_1 = XYZ_1$
所以pixel2cam是完成了二维反投影到三维的过程
然后是这么一句
proj_cam_to_src_pixel = intrinsics @ pose_mat # [B, 3, 4]
相当于$K*T_{21}$
$K*T_{21}$的另一个名字也叫做投影矩阵P
src_pixel_coords = cam2pixel(cam_coords, # XYZ
proj_cam_to_src_pixel[:,:,:3], # R
proj_cam_to_src_pixel[:,:,-1:], # t
padding_mode) # [B,H,W,2]
所以cam2pixel函数完成 XYZ1转换到XYZ2并投影到uv2的任务
inverse_warp的最后一句:
projected_img = F.grid_sample(img, src_pixel_coords, padding_mode=padding_mode)
以及执行完 inverse_warp后,在one_scale中的一句
diff = (tgt_img_scaled - ref_img_warped) * out_of_bound
inverse_warp函数只传进去了ref_img,即坐标系2的图像,然后最后就用tgt_img去减了ref_img_warped,
所以ref_img_warped其实是ref_img投影到tgt_img所在坐标系的图像,即坐标2的图像投影到坐标1。
考虑上面的公式,所以整个warp过程是:
找到和坐标系1上的每个像素对应的坐标系2上的图像的像素的值,然后计算差值。
如果没有落在整数坐标上,就用F.grid_sample计算出来。
基本上,sfmlearner的photometric_reconstruction_loss差不多就是slam里头直接法的光度差的计算过程。
上面差不多就是sfmlearner代码的难点了。
ssim之类的比较简单,不做解析。
============
所以,根据上述内容,如果想跑自己的数据集,在自己拍的视频上训练,
你需要
1,标定自己的相机,得到内参K
2,把你拍的视频分解的图片resize到128x416,在图片resize的时候,内参也要resize
如果对图片做了其他操作,内参也需要做对应的操作,在custom_tranform.py有相关代码。
其实就是个相机视锥的变化。
所以谷歌后来出的vid2depth算法在点云上做 ICP 就很容易理解了。。。
sfmlearner剖析的更多相关文章
- SfMLearner 记录
2019年3月2日09:29:54 正在看SfMLearner的pytorch源码,意识到无监督的深度估计最重要的是利用实体的一致性 来建立loss. 对于一个不移动的物体,相机从一个pose到另一个 ...
- Depth from Videos in the Wild 解读
2019年7月17日11:37:05 论文 Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unkn ...
- 探索C#之6.0语法糖剖析
阅读目录: 自动属性默认初始化 自动只读属性默认初始化 表达式为主体的函数 表达式为主体的属性(赋值) 静态类导入 Null条件运算符 字符串格式化 索引初始化 异常过滤器when catch和fin ...
- jQuery之Deferred源码剖析
一.前言 大约在夏季,我们谈过ES6的Promise(详见here),其实在ES6前jQuery早就有了Promise,也就是我们所知道的Deferred对象,宗旨当然也和ES6的Promise一样, ...
- [C#] 剖析 AssemblyInfo.cs - 了解常用的特性 Attribute
剖析 AssemblyInfo.cs - 了解常用的特性 Attribute [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5944391.html 序 ...
- Membership三步曲之进阶篇 - 深入剖析Provider Model
Membership 三步曲之进阶篇 - 深入剖析Provider Model 本文的目标是让每一个人都知道Provider Model 是什么,并且能灵活的在自己的项目中使用它. Membershi ...
- 《AngularJS深度剖析与最佳实践》简介
由于年末将至,前阵子一直忙于工作的事务,不得已暂停了微信订阅号的更新,我将会在后续的时间里尽快的继续为大家推送更多的博文.毕竟一个人的力量微薄,精力有限,希望大家能理解,仍然能一如既往的关注和支持sh ...
- 探索c#之Async、Await剖析
阅读目录: 基本介绍 基本原理剖析 内部实现剖析 重点注意的地方 总结 基本介绍 Async.Await是net4.x新增的异步编程方式,其目的是为了简化异步程序编写,和之前APM方式简单对比如下. ...
- ASP.NET Core管道深度剖析(2):创建一个“迷你版”的管道来模拟真实管道请求处理流程
从<ASP.NET Core管道深度剖析(1):采用管道处理HTTP请求>我们知道ASP.NET Core请求处理管道由一个服务器和一组有序的中间件组成,所以从总体设计来讲是非常简单的,但 ...
随机推荐
- 对Python中print函数参数的认识
输出函数是最常用的,对print()参数的准确认识尤为重要. sep='':sep参数表示函数中不同value的分隔符,默认为一个空格. end='':end参数表示函数结尾的处理,默认换行. 例如: ...
- pthread_cond_t
条件锁pthread_cond_t (1)pthread_cond_wait的使用 等待线程1. 使用pthread_cond_wait前要先加锁2. pthread_cond_wait内部会解锁,然 ...
- outlook邮箱备份
- 计算两个坐标点的距离(高德or百度)
/// <summary> /// 获取两个坐标之间的距离 /// </summary> /// <param name="lat1">第一个坐 ...
- Unity上线google商店 用IL2Cpp打包64位版本和Android APP Bundle优化 及产生的bug
ios刚上线,这边着手改成android版本,我开始使用的是unity2017.4.1版本 上传谷歌商店是出现这两个警告: 要支持64位,但是在2017版本上没有找到64位的打包选项,猜测应该是版本的 ...
- [转载]Pytorch详解NLLLoss和CrossEntropyLoss
[转载]Pytorch详解NLLLoss和CrossEntropyLoss 来源:https://blog.csdn.net/qq_22210253/article/details/85229988 ...
- ubuntu目录结构(转)
/:根目录,一般根目录下只存放目录,不要存放文件,/etc./bin./dev./lib./sbin应该和根目录放置在一个分区中 /bin:/usr/bin:可执行二进制文件的目录,如常用的命令ls. ...
- js重点——作用域——简单介绍(一)
一.作用域 定义:在js中,作用域为变量,对象,函数可访问的一个范围. 分类:全局作用域和局部作用域 全局作用域:全局代表了整个文档document,变量或者函数在函数外面声明,那它的就是全局变量和全 ...
- 小程序e.currentTarget与e.target 两个属性的区别
注册事件是获取小程序组件上面的自定义属性值 e.target是获取当前点击的标签上面的自定义属性 e.currentTarget是获取注册点击事件标签内的自定义属性
- centeros7安装mysql
转载自:https://www.linuxidc.com/Linux/2016-09/135288.htm 安装之前先安装基本环境:yum install -y perl perl-Module-Bu ...