爬虫之 BeautifulSoup与Xpath
知识预览
BeautifulSoup
一 简介
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
'''
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。
它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
'''
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.你可能在寻找 Beautiful Soup3 的文档,Beautiful Soup 3 目前已经停止开发,官网推荐在现在的项目中使用Beautiful Soup 4。
安装

#安装 Beautiful Soup
pip install beautifulsoup4 #安装解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml .根据操作系统不同,可以选择下列方法来安装lxml: $ apt-get install Python-lxml $ easy_install lxml $ pip install lxml 另一个可供选择的解析器是纯Python实现的 html5lib , html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib: $ apt-get install Python-html5lib $ easy_install html5lib $ pip install html5lib
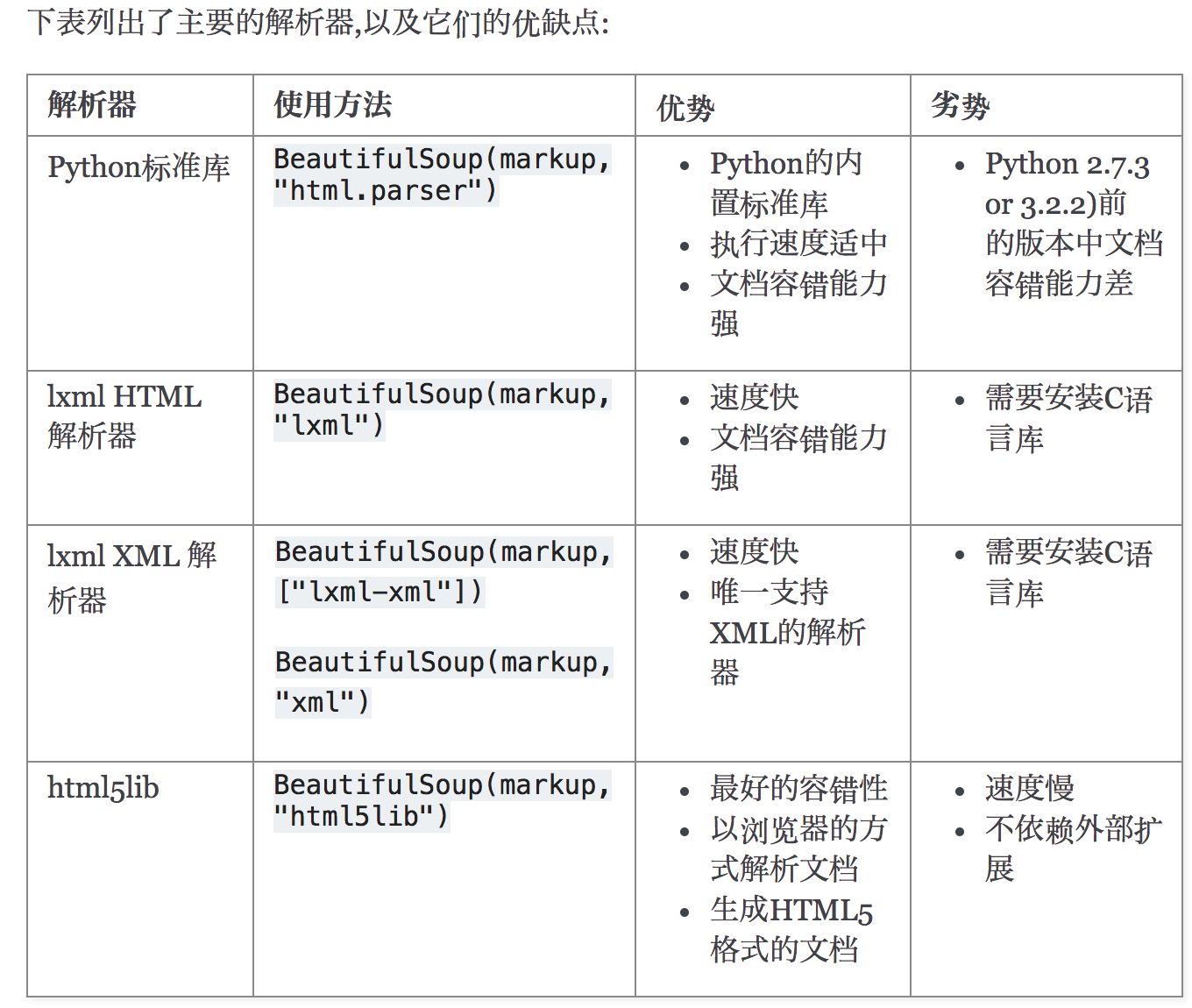
解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装另一个可供选择的解析器是纯Python实现的 html5lib , html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib:
# pip install html5lib
解析器对比:
简单使用
下面的一段HTML代码将作为例子被多次用到.这是 爱丽丝梦游仙境的 的一段内容(以后内容中简称为 爱丽丝 的文档):
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
"""
使用BeautifulSoup解析这段代码,能够得到一个 BeautifulSoup 的对象
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'html.parser')
从文档中找到所有<a>标签的链接:
从文档中获取所有文字内容:
print(soup.get_text())
二 标签对象
通俗点讲就是 HTML 中的一个个标签,Tag 对象与XML或HTML原生文档中的tag相同:
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>')
tag = soup.b
type(tag)
# <class 'bs4.element.Tag'>
Tag的名字
soup对象再以爱丽丝梦游仙境的html_doc为例,操作文档树最简单的方法就是告诉它你想获取的tag的name.如果想获取 <head> 标签,只要用 soup.head :
soup.head
# <head><title>The Dormouse's story</title></head> soup.title
# <title>The Dormouse's story</title>
这是个获取tag的小窍门,可以在文档树的tag中多次调用这个方法.下面的代码可以获取<body>标签中的第一个<b>标签:
soup.body.b
# <b>The Dormouse's story</b>
通过点取属性的方式只能获得当前名字的第一个tag:
soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
如果想要得到所有的<a>标签,或是通过名字得到比一个tag更多的内容的时候,就需要用到 Searching the tree 中描述的方法,比如: find_all()
soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
我们可以利用 soup加标签名轻松地获取这些标签的内容,注意,它查找的是在所有内容中的第一个符合要求的标签。
Tag的name和attributes属性
Tag有很多方法和属性,现在介绍一下tag中最重要的属性: name和attributes
每个tag都有自己的名字,通过 .name 来获取:
tag.name
# u'b' tag['class']
# u'boldest' tag.attrs
# {u'class': u'boldest'}
tag的属性可以被添加,删除或修改. 再说一次, tag的属性操作方法与字典一样
tag['class'] = 'verybold'
tag['id'] = 1
tag
# <blockquote class="verybold" id="1">Extremely bold</blockquote> del tag['class']
del tag['id']
tag
# <blockquote>Extremely bold</blockquote> tag['class']
# KeyError: 'class'
print(tag.get('class'))
# None
三 遍历文档树
'''
1、用法
2、获取标签的名称
3、获取标签的属性
4、获取标签的内容
5、嵌套选择
6、子节点、子孙节点
7、父节点、祖先节点
8、兄弟节点
'''
#遍历文档树:即直接通过标签名字选择,特点是选择速度快,但如果存在多个相同的标签则只返回第一个
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p id="my p" class="title"><b id="bbb" class="boldest">The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
""" #1、用法
from bs4 import BeautifulSoup
soup=BeautifulSoup(html_doc,'lxml')
# soup=BeautifulSoup(open('a.html'),'lxml') print(soup.p) #存在多个相同的标签则只返回第一个
print(soup.a) #存在多个相同的标签则只返回第一个 #2、获取标签的名称
print(soup.p.name) #3、获取标签的属性
print(soup.p.attrs) #4、获取标签的内容
print(soup.p.string) # p下的文本只有一个时,取到,否则为None
print(soup.p.strings) #拿到一个生成器对象, 取到p下所有的文本内容
print(soup.p.text) #取到p下所有的文本内容
for line in soup.stripped_strings: #去掉空白
print(line) '''
如果tag包含了多个子节点,tag就无法确定 .string 方法应该调用哪个子节点的内容, .string 的输出结果是 None,如果只有一个子节点那么就输出该子节点的文本,比如下面的这种结构,soup.p.string 返回为None,但soup.p.strings就可以找到所有文本
<p id='list-1'>
哈哈哈哈
<a class='sss'>
<span>
<h1>aaaa</h1>
</span>
</a>
<b>bbbbb</b>
</p>
''' #5、嵌套选择
print(soup.head.title.string)
print(soup.body.a.string) #6、子节点、子孙节点
print(soup.p.contents) #p下所有子节点
print(soup.p.children) #得到一个迭代器,包含p下所有子节点 for i,child in enumerate(soup.p.children):
print(i,child) print(soup.p.descendants) #获取子孙节点,p下所有的标签都会选择出来
for i,child in enumerate(soup.p.descendants):
print(i,child) #7、父节点、祖先节点
print(soup.a.parent) #获取a标签的父节点
print(soup.a.parents) #找到a标签所有的祖先节点,父亲的父亲,父亲的父亲的父亲... #8、兄弟节点
print('=====>')
print(soup.a.next_sibling) #下一个兄弟
print(soup.a.previous_sibling) #上一个兄弟 print(list(soup.a.next_siblings)) #下面的兄弟们=>生成器对象
print(soup.a.previous_siblings) #上面的兄弟们=>生成器对象
四 搜索文档树
BeautifulSoup定义了很多搜索方法,这里着重介绍2个: find() 和 find_all() .其它方法的参数和用法类似
1、五种过滤器
#搜索文档树:BeautifulSoup定义了很多搜索方法,这里着重介绍2个: find() 和 find_all() .其它方法的参数和用法类似
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p id="my p" class="title"><b id="bbb" class="boldest">The Dormouse's story</b>
</p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
""" from bs4 import BeautifulSoup
soup=BeautifulSoup(html_doc,'lxml') #1、五种过滤器: 字符串、正则表达式、列表、True、方法
#1.1、字符串:即标签名
print(soup.find_all('b')) #1.2、正则表达式
import re
print(soup.find_all(re.compile('^b'))) #找出b开头的标签,结果有body和b标签 #1.3、列表:如果传入列表参数,Beautiful Soup会将与列表中任一元素匹配的内容返回.下面代码找到文档中所有<a>标签和<b>标签:
print(soup.find_all(['a','b'])) #1.4、True:可以匹配任何值,下面代码查找到所有的tag,但是不会返回字符串节点
print(soup.find_all(True))
for tag in soup.find_all(True):
print(tag.name) #1.5、方法:如果没有合适过滤器,那么还可以定义一个方法,方法只接受一个元素参数 ,如果这个方法返回 True 表示当前元素匹配并且被找到,如果不是则反回 False
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id') print(soup.find_all(has_class_but_no_id))
2、find_all()
#2、find_all( name , attrs , recursive , text , **kwargs )
#2.1、name: 搜索name参数的值可以使任一类型的 过滤器 ,字符窜,正则表达式,列表,方法或是 True .
print(soup.find_all(name=re.compile('^t'))) #2.2、keyword: key=value的形式,value可以是过滤器:字符串 , 正则表达式 , 列表, True .
print(soup.find_all(id=re.compile('my')))
print(soup.find_all(href=re.compile('lacie'),id=re.compile('\d'))) #注意类要用class_
print(soup.find_all(id=True)) #查找有id属性的标签 # 有些tag属性在搜索不能使用,比如HTML5中的 data-* 属性:
data_soup = BeautifulSoup('<div data-foo="value">foo!</div>','lxml')
# data_soup.find_all(data-foo="value") #报错:SyntaxError: keyword can't be an expression
# 但是可以通过 find_all() 方法的 attrs 参数定义一个字典参数来搜索包含特殊属性的tag:
print(data_soup.find_all(attrs={"data-foo": "value"}))
# [<div data-foo="value">foo!</div>] #2.3、按照类名查找,注意关键字是class_,class_=value,value可以是五种选择器之一
print(soup.find_all('a',class_='sister')) #查找类为sister的a标签
print(soup.find_all('a',class_='sister ssss')) #查找类为sister和sss的a标签,顺序错误也匹配不成功
print(soup.find_all(class_=re.compile('^sis'))) #查找类为sister的所有标签 #2.4、attrs
print(soup.find_all('p',attrs={'class':'story'})) #2.5、text: 值可以是:字符,列表,True,正则
print(soup.find_all(text='Elsie'))
print(soup.find_all('a',text='Elsie')) #2.6、limit参数:如果文档树很大那么搜索会很慢.如果我们不需要全部结果,可以使用 limit 参数限制返回结果的数量.效果与SQL中的limit关键字类似,当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果
print(soup.find_all('a',limit=2)) #2.7、recursive:调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False .
print(soup.html.find_all('a'))
print(soup.html.find_all('a',recursive=False)) '''
像调用 find_all() 一样调用tag
find_all() 几乎是Beautiful Soup中最常用的搜索方法,所以我们定义了它的简写方法. BeautifulSoup 对象和 tag 对象可以被当作一个方法来使用,这个方法的执行结果与调用这个对象的 find_all() 方法相同,下面两行代码是等价的:
soup.find_all("a")
soup("a")
这两行代码也是等价的:
soup.title.find_all(text=True)
soup.title(text=True)
'''
3、find()
#3、find( name , attrs , recursive , text , **kwargs )
find_all() 方法将返回文档中符合条件的所有tag,尽管有时候我们只想得到一个结果.比如文档中只有一个<body>标签,那么使用 find_all() 方法来查找<body>标签就不太合适, 使用 find_all 方法并设置 limit=1 参数不如直接使用 find() 方法.下面两行代码是等价的: soup.find_all('title', limit=1)
# [<title>The Dormouse's story</title>]
soup.find('title')
# <title>The Dormouse's story</title> 唯一的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果.
find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None .
print(soup.find("nosuchtag"))
# None soup.head.title 是 tag的名字 方法的简写.这个简写的原理就是多次调用当前tag的 find() 方法: soup.head.title
# <title>The Dormouse's story</title>
soup.find("head").find("title")
# <title>The Dormouse's story</title>
4、其他方法
#见官网:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#find-parents-find-parent
5、css选择器
我们在写 CSS 时,标签名不加任何修饰,类名前加点,id名前加 #,在这里我们也可以利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list
(1)通过标签名查找
print(soup.select("title")) # [<title>The Dormouse's story</title>]
print(soup.select("b")) # [<b>The Dormouse's story</b>]
(2)通过类名查找
print(soup.select(".sister"))
'''
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
'''
(3)通过 id 名查找
print(soup.select("#link1"))
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
(4)组合查找
组合查找即和写 class 文件时,标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,二者需要用空格分开
print(soup.select("p #link2"))
#[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
直接子标签查找
print(soup.select("p > #link2"))
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
(5)属性查找
查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。
print(soup.select("a[href='http://example.com/tillie']"))
#[<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
select 方法返回的结果都是列表形式,可以遍历形式输出,然后用 get_text() 方法来获取它的内容:
for title in soup.select('a'):
print (title.get_text())
'''
Elsie
Lacie
Tillie
'''
五 修改文档树
xpath
xpath简介
XPath在Python的爬虫学习中,起着举足轻重的地位,对比正则表达式 re两者可以完成同样的工作,实现的功能也差不多,但XPath明显比re具有优势,在网页分析上使re退居二线。
XPath介绍
是什么? 全称为XML Path Language 一种小型的查询语言
说道XPath是门语言,不得不说它所具备的优点:
- 可在XML中查找信息
- 支持HTML的查找
- 通过元素和属性进行导航
python开发使用XPath条件: 由于XPath属于lxml库模块,所以首先要安装库lxml。
XPath的简单调用方法:
from lxml import etree selector=etree.HTML(源码) #将源码转化为能被XPath匹配的格式 selector.xpath(表达式) #返回为一列表
Xpath语法
查询
html_doc = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body> <div class="d1">
<div class="d2">
<p class="story">
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" id="link3">Tillie</a>
</p>
</div>
<div>
<p id="p1">ALex is dsb</p>
<p id="p2">Egon too</p>
</div>
</div> <div class="d3">
<a href="http://www.baidu.com">baidu</a>
<p>百度</p>
</div> </body>
</html>
""" from lxml import etree
selector=etree.HTML(html_doc) # 将源码转化为能被XPath匹配的格式 '''
一、选取节点 nodename 选取nodename节点的所有子节点 xpath(‘//div’) 选取了所有div节点
/ 从根节点选取 xpath(‘/div’) 从根节点上选取div节点
// 选取所有的当前节点,不考虑他们的位置 xpath(‘//div’) 选取所有的div节点
. 选取当前节点 xpath(‘./div’) 选取当前节点下的div节点
.. 选取当前节点的父节点 xpath(‘..’) 回到上一个节点
@ 选取属性 xpath(’//@calss’) 选取所有的class属性 ''' ret=selector.xpath("//div")
ret=selector.xpath("/div")
ret=selector.xpath("./div")
ret=selector.xpath("//p[@id='p1']")
ret=selector.xpath("//div[@class='d1']/div/p[@class='story']") '''
二、谓语 表达式 结果
xpath(‘/body/div[1]’) 选取body下的第一个div节点
xpath(‘/body/div[last()]’) 选取body下最后一个div节点
xpath(‘/body/div[last()-1]’) 选取body下倒数第二个div节点
xpath(‘/body/div[positon()<3]’) 选取body下前两个div节点
xpath(‘/body/div[@class]’) 选取body下带有class属性的div节点
xpath(‘/body/div[@class=”main”]’) 选取body下class属性为main的div节点
xpath(‘/body/div[price>35.00]’) 选取body下price元素值大于35的div节点 ''' ret=selector.xpath("//p[@class='story']//a[2]")
ret=selector.xpath("//p[@class='story']//a[last()]") '''
通配符 Xpath通过通配符来选取未知的XML元素 表达式 结果
xpath(’/div/*’) 选取div下的所有子节点
xpath(‘/div[@*]’) 选取所有带属性的div节点 ''' ret=selector.xpath("//p[@class='story']/*")
ret=selector.xpath("//p[@class='story']/a[@class]") '''
四、取多个路径
使用“|”运算符可以选取多个路径 表达式 结果
xpath(‘//div|//table’) 选取所有的div和table节点 ''' ret=selector.xpath("//p[@class='story']/a[@class]|//div[@class='d3']")
print(ret) ''' 五、Xpath轴
轴可以定义相对于当前节点的节点集 轴名称 表达式 描述
ancestor xpath(‘./ancestor::*’) 选取当前节点的所有先辈节点(父、祖父)
ancestor-or-self xpath(‘./ancestor-or-self::*’) 选取当前节点的所有先辈节点以及节点本身
attribute xpath(‘./attribute::*’) 选取当前节点的所有属性
child xpath(‘./child::*’) 返回当前节点的所有子节点
descendant xpath(‘./descendant::*’) 返回当前节点的所有后代节点(子节点、孙节点)
following xpath(‘./following::*’) 选取文档中当前节点结束标签后的所有节点
following-sibing xpath(‘./following-sibing::*’) 选取当前节点之后的兄弟节点
parent xpath(‘./parent::*’) 选取当前节点的父节点
preceding xpath(‘./preceding::*’) 选取文档中当前节点开始标签前的所有节点 preceding-sibling xpath(‘./preceding-sibling::*’) 选取当前节点之前的兄弟节点
self xpath(‘./self::*’) 选取当前节点 六、功能函数
使用功能函数能够更好的进行模糊搜索 函数 用法 解释
starts-with xpath(‘//div[starts-with(@id,”ma”)]‘) 选取id值以ma开头的div节点
contains xpath(‘//div[contains(@id,”ma”)]‘) 选取id值包含ma的div节点
and xpath(‘//div[contains(@id,”ma”) and contains(@id,”in”)]‘) 选取id值包含ma和in的div节点
text() xpath(‘//div[contains(text(),”ma”)]‘) 选取节点文本包含ma的div节点
extract() 提取
'''
Element对象
from lxml.etree import _Element
for obj in ret:
print(obj)
print(type(obj)) # from lxml.etree import _Element '''
Element对象 class xml.etree.ElementTree.Element(tag, attrib={}, **extra) tag:string,元素代表的数据种类。
text:string,元素的内容。
tail:string,元素的尾形。
attrib:dictionary,元素的属性字典。
#针对属性的操作
clear():清空元素的后代、属性、text和tail也设置为None。
get(key, default=None):获取key对应的属性值,如该属性不存在则返回default值。
items():根据属性字典返回一个列表,列表元素为(key, value)。
keys():返回包含所有元素属性键的列表。
set(key, value):设置新的属性键与值。 #针对后代的操作
append(subelement):添加直系子元素。
extend(subelements):增加一串元素对象作为子元素。#python2.7新特性
find(match):寻找第一个匹配子元素,匹配对象可以为tag或path。
findall(match):寻找所有匹配子元素,匹配对象可以为tag或path。
findtext(match):寻找第一个匹配子元素,返回其text值。匹配对象可以为tag或path。
insert(index, element):在指定位置插入子元素。
iter(tag=None):生成遍历当前元素所有后代或者给定tag的后代的迭代器。#python2.7新特性
iterfind(match):根据tag或path查找所有的后代。
itertext():遍历所有后代并返回text值。
remove(subelement):删除子元素。 '''
爬虫之 BeautifulSoup与Xpath的更多相关文章
- 爬虫之Beautifulsoup及xpath
1.BeautifulSoup (以 Python 风格的方式来对 HTML 或 XML 进行迭代,搜索和修改) 1.1 介绍 Beautiful Soup提供一些简单的.python式的函数用来处理 ...
- 爬虫模块BeautifulSoup
中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html# 1.1 安装BeautifulSoup模块 ...
- Python爬虫教程-22-lxml-etree和xpath配合使用
Python爬虫教程-22-lxml-etree和xpath配合使用 lxml:python 的HTML/XML的解析器 官网文档:https://lxml.de/ 使用前,需要安装安 lxml 包 ...
- 爬虫解析库:XPath
XPath XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言.最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的 ...
- 使用Python爬虫库BeautifulSoup遍历文档树并对标签进行操作详解(新手必学)
为大家介绍下Python爬虫库BeautifulSoup遍历文档树并对标签进行操作的详细方法与函数下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最 ...
- Python爬虫之lxml-etree和xpath的结合使用
本篇文章给大家介绍的是Python爬虫之lxml-etree和xpath的结合使用(附案例),内容很详细,希望可以帮助到大家. lxml:python的HTML / XML的解析器 官网文档:http ...
- 爬虫——BeautifulSoup和Xpath
爬虫我们大概可以分为三部分:爬取——>解析——>存储 一 Beautiful Soup: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功 ...
- python爬虫之html解析Beautifulsoup和Xpath
Beautiifulsoup Beautiful Soup 是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据.BeautifulSoup 用来解析 HTML 比较简 ...
- Python爬虫利器三之Xpath语法与lxml库的用法
前面我们介绍了 BeautifulSoup 的用法,这个已经是非常强大的库了,不过还有一些比较流行的解析库,例如 lxml,使用的是 Xpath 语法,同样是效率比较高的解析方法.如果大家对 Beau ...
随机推荐
- matlab基本函数find
一起来学演化计算-matlab基本函数find 觉得有用的话,欢迎一起讨论相互学习~Follow Me 找到非零元素的索引和值 语法 k = find(X) k = find(X)返回一个向量,其中包 ...
- Ubuntu18.04 instsall XMind_8 and crack
1.dowload XMind_8 linux install zip wget https://www.xmind.cn/xmind/downloads/xmind-8-update8-linux. ...
- CNN中计算量FLOPs的计算
1.FLOPs的概念:全称是floating point operations per second,意指每秒浮点运算次数,即用来衡量硬件的计算性能:在CNN中用来指浮点运算次数: 2.计算过程: 如 ...
- C# WinForm获取 当前执行程序路径的几种方法(转)
1.获取和设置当前目录的完全限定路径. string str = System.Environment.CurrentDirectory; Result: C:xxxxxx 2.获取启动了应用程序的可 ...
- input 标签鼠标放入输入框补全提示
JSP: <input type="text" placeholder="eventDesc" value="" id="e ...
- 020 Android 常用颜色对应表
1.Android colors.xml常用颜色汇总 <?xml version="1.0" encoding="utf-8"?> <reso ...
- [转帖]Hive学习之路 (一)Hive初识
Hive学习之路 (一)Hive初识 https://www.cnblogs.com/qingyunzong/p/8707885.html 讨论QQ:1586558083 目录 Hive 简介 什么是 ...
- Mybatis笔记4
mybatis中多对多的步骤 示例:用户和角色,一个用户可以有多个角色,一个角色可以赋予多个用户 步骤: 建立两张表:用户表,角色表,让用户表和角色表具有多对多的关系,需要使用中间表,中间表中包含两张 ...
- SQL语言(二)
SQL约束与策略 create table student( id int primary key, //主键约束 name ) not null, //非空约束 idCard ) unique, / ...
- python学习-53 正则表达式
正则表达式 就其本质而言,正则表达式是一种小型的/高度专业化的编程语言,它内嵌在python中,并通过RE模块实现,正则表达式模式被编译成一系列的字节码,然后由用C编写的匹配引擎执行. 1.元字符 - ...