聚类算法之MeanShift
机器学习的研究方向主要分为三大类:聚类,分类与回归。
MeanShift作为聚类方法之一,在视觉领域有着广泛的应用,尤其是作为深度学习回归后的后处理模块而存在着。
接下来,我们先介绍下基本功能流程,然后会用代码的形式来分析。
一、算法原理:
MeanShift,顾名思义,由Mean(均值)和shift(偏移)组成。也就是有一个点x,周围有很多点xi,我们计算点x移动到每个点所需要的偏移量之和,求平均,就得到平均偏移量。该偏移量包含大小和方向 ,方向就是周围分布密集的方向。然后点x往平均偏移量方向移动,再以此为新起点,不断迭代直到满足一定条件结束。
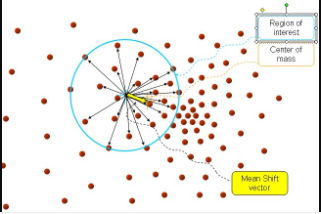
中心点就是我们上面所说的 周围的小红点就是
黄色的箭头就是我们求解得到的平均偏移向量。那么图中“大圆圈”是什么东西呢?我们上面所说的周围的点
周围是个什么概念?总的有个东西来限制一下吧。那个“圆圈”就是我们的限制条件,或者说在图像处理中,就是我们搜索迭代时的窗口大小。
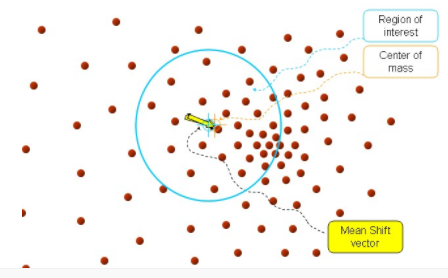
步骤1、首先设定起始点 ,我们说了,是球,所以有半径 , 所有在球内的点就是 , 黑色箭头就是我们计算出来的向量 , 将所有的向量 进行求和计算平均就得到我们的meanshift 向量,也就是图中黄色的向量。
接着,再以meanshift向量的重点为圆心,再做一个高维的球,如下图所示,重复上面的步骤,最终就可以收敛到点的分布中密度最大的地方
最后得到结果如下:
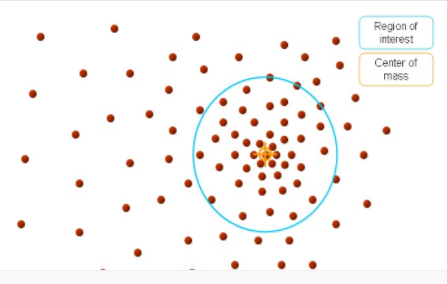
通过在数据集中寻找被低密度区域分离的高密度区域,将分离出的高密度区域作为一个独立的类别。
优点:可自动决定类别的数目。
二、数学推导
给定d维空间Rd的n个样本点 ,i=1,…,n,在空间中任选一点x,那么 meanshift 向量的基本定义如下:
其中 是一个半径为
的高维度区域。定义如下:
表示在这n个样本点xi中,有k个点落入
区域中.
然后,我们对meanshift向量进行升级,加入核函数(比如高斯核),则meanshift算法变为:
高斯核函数是一种应用广泛的核函数:
其中h为bandwidth 带宽,不同带宽的核函数形式也不一样
由上图可以看到,横坐标指的是两变量之间的距离。距离越近(接近于0)则函数值越大,否则越小。h越大,相同距离的情况下 函数值会越小。因此我们可以选取适当的h值,得到满足上述要求的那种权重(两变量距离越近,得到权重越大),故经过核函数改进后的均值漂移为:
其中
就是高斯核函数
核函数K():h为半径, 为单位密度,要使得上式f得到最大,最容易想到的就是对上式进行求导,的确meanshift就是对上式进行求导.

令 , 则我们可以得到:
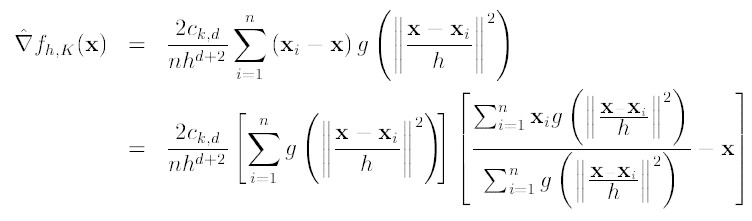
由于我们使用的是高斯核,所以第一项等于
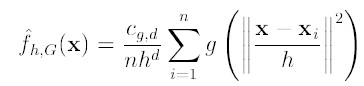
第二项就相当于一个meanshift向量的式子:
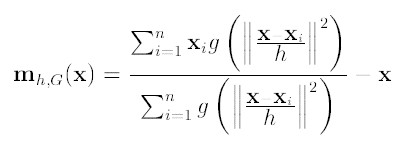
则上述公式可以表示为:
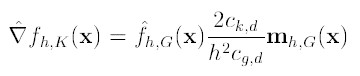
图解公式的结构如下:
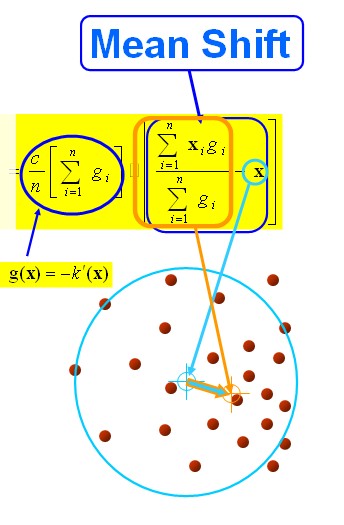
当然,我们求得meanshift向量的时候,其密度最大的地方也就是极值点的地方,此时梯度为0,也就是 ,当且仅当
的时候成立,此时我们就可以得到新的原点坐标:
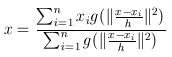
函数推导,参考自链接:https://blog.csdn.net/csdnforyou/article/details/81161840
三、算法步骤:
1)在未被标记的数据点中随机选择一个点作为起始中心点center;
2)找出以center为中心半径为radius的区域中出现的所有数据点,认为这些点同属于一个聚类C,同时在该聚类中记录数据点出现的次数加1;
3)以center为中心点,计算从center开始到集合M中每个元素的向量,将这些向量相加,得到向量shift;
4)center=center+shift,即center沿着shift方向移动,移动距离为||shift||;
5)重复步骤2,3,4,直到shift很小,记得此时的center。注意,这个迭代过程中遇到的点都应该归类到簇C;
6)如果收敛时当前簇C的center与其它已经存在的簇C2中心的距离小于阈值,那么把C2与C合并,数据点出现次数也对应合并。否则把C作为新的聚类;
7)重复1,2,3,4,5直到所有点都被标记为已访问;
8)分类:根据每个类,对每个点的访问频率,取访问频率最大的那个类,作为当前点集的所属类。
四、代码流程:
from sklearn.cluster import MeanShift
@staticmethod
def _cluster(prediction, bandwidth):
ms = MeanShift(bandwidth, bin_seeding=True)
# log.info('开始Mean shift聚类 ...')
tic = time.time()
try:
ms.fit(prediction)
except ValueError as err:
log.error(err)
return 0, [], []
# log.info('Mean Shift耗时: {:.5f}s'.format(time.time() - tic))
labels = ms.labels_
cluster_centers = ms.cluster_centers_
num_clusters = cluster_centers.shape[0]
# log.info('聚类簇个数为: {:d}'.format(num_clusters))
return num_clusters, labels, cluster_centers
五、场景应用
5.1 目标跟踪
opencv中已经有库函数:int cvMeanShift(const CvArr* prob_image,CvRect window,CvTermCriteria criteria,CvConnectedComp* comp )
输入参数需是反向投影图(反向投影图是用输入图像的某一位置上像素值(多维或灰度)对应在直方图的一个bin上的值来代替该像素值,所以得到的反向投影图是单通的。用统计学术语,输出图像象素点的值是观测数组在某个分布(直方图)下的概率),举例:
1)度图像如下
Image=[0 1 2 3
4 5 6 7
8 9 10 11
8 9 14 15]
2)该灰度图的直方图为(bin指定的区间为[0,3),[4,7),[8,11),[12,16))
Histogram= [4 4 6 2]
3)反向投影图
Back_Projection=[4 4 4 4
4 4 4 4
6 6 6 6
6 6 2 2]
例如位置(0,0)上的像素值为0,对应的bin为[0,3),所以反向直方图在该位置上的值这个bin的值4。其实就是一张图像的像素密度分布图.
meanshift算法本身就是依靠密度分布进行工作的
全自动跟踪思路:输入视频,对运动物体进行跟踪。
第一步:运用运动检测算法将运动的物体与背景分割开来。
第二步:提取运动物体的轮廓,并从原图中获取运动图像的信息。
第三步:对这个信息进行反向投影,获取反向投影图。
第四步:根据反向投影图和物体的轮廓(也就是输入的方框)进行meanshift迭代,由于它是向重心移动,即向反向投影图中概率大的地方移动,所以始终会移动到物体上。
第五步:然后下一帧图像时用上一帧输出的方框来迭代即可。
meanShift算法用于视频目标跟踪时,其实就是采用目标的颜色直方图作为搜索特征,通过不断迭代meanShift向量使得算法收敛于目标的真实位置,从而达到跟踪的目的。
meanshift优势:
(1)计算量不大,在目标区域已知情况下可以做到实时跟踪;
(2)采用核函数直方图模型,对边缘遮挡、目标旋转、变形和背景运动不敏感。
meanShift缺点:
(1)缺乏必要的模板更新;
(2)跟踪过程中由于窗口宽度大小保持不变,当目标尺度有所变化时,跟踪就会失败;
(3)当目标速度较快时,跟踪效果不好;
(4)直方图特征在目标颜色特征描述方面略显匮乏,缺少空间信息;
由于其计算速度快,对目标变形和遮挡有一定的鲁棒性,其中一些在工程实际中也可以对其作出一些改进和调整如下:
(1)引入一定的目标位置变化的预测机制,从而更进一步减少meanShift跟踪的搜索时间,降低计算量;
(2)可以采用一定的方式来增加用于目标匹配的“特征”;
(3)将传统meanShift算法中的核函数固定带宽改为动态变化的带宽;
(4)采用一定的方式对整体模板进行学习和更新;
聚类算法之MeanShift的更多相关文章
- 多种聚类算法概述(BIRCH, DBSCAN, K-means, MEAN-SHIFT)
BIRCH:是一种使用树分类的算法,适用的范围是样本数大,特征数小的算法,因为特征数大的话,那么树模型结构就会要复杂很多 DBSCAN:基于概率密度的聚类方法:速度相对较慢,不适用于大型的数据,输入参 ...
- Meanshift,聚类算法(转)
原帖地址:http://www.cnblogs.com/liqizhou/archive/2012/05/12/2497220.html 记得刚读研究生的时候,学习的第一个算法就是meanshif ...
- Meanshift,聚类算法
记得刚读研究生的时候,学习的第一个算法就是meanshift算法,所以一直记忆犹新,今天和大家分享一下Meanshift算法,如有错误,请在线交流. Mean Shift算法,一般是指一个迭代的步骤, ...
- 机器学习:Python实现聚类算法(三)之总结
考虑到学习知识的顺序及效率问题,所以后续的几种聚类方法不再详细讲解原理,也不再写python实现的源代码,只介绍下算法的基本思路,使大家对每种算法有个直观的印象,从而可以更好的理解函数中参数的意义及作 ...
- 机器学习:Mean Shift聚类算法
本文由ChardLau原创,转载请添加原文链接https://www.chardlau.com/mean-shift/ 今天的文章介绍如何利用Mean Shift算法的基本形式对数据进行聚类操作.而有 ...
- mean shift聚类算法的MATLAB程序
mean shift聚类算法的MATLAB程序 凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 1. mean shift 简介 mean shift, 写的 ...
- DBSCAN密度聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-M ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- 挑子学习笔记:两步聚类算法(TwoStep Cluster Algorithm)——改进的BIRCH算法
转载请标明出处:http://www.cnblogs.com/tiaozistudy/p/twostep_cluster_algorithm.html 两步聚类算法是在SPSS Modeler中使用的 ...
随机推荐
- 使用graphviz绘制流程图
转自 http://www.cnblogs.com/CoolJie/archive/2012/07/17/graphviz.html
- Python中bytes与字符串的相互转化
代码: # bytes转字符串方式一 b=b'\xe9\x80\x86\xe7\x81\xab' string=str(b,'utf-8') print(string) # bytes转字符串方式二 ...
- Django:(06)Django模版
一.模版的使用 配置 如果是命令行创建的项目需要手动配置模版文件目录(如果是Pycharm创建的项目则无需配置) 在项目根目录下创建目录templates, 用来存放模版文件 在项目的配置文件夹set ...
- 《剑指offer》树专题 (牛客10.25)
考察的知识点主要在于树的数据结构(BST,AVL).遍历方式(前序,中序,后序,层次).遍历算法(DFS,BFS,回溯)以及遍历时借助的数据结构如队列和栈.由于树本身就是一个递归定义的结构,所以在递归 ...
- VS编译错误._CRT_SECURE_NO_WARNINGS、_WINSOCK_DEPRECATED_NO_WARNINGS
1.不记得原来的情况了,记得大概是这样: 低版本的 VC编译器 使用 strcpy.sprintf 等它不会报错,但是 高版本的 VS编译就会报错,大意是 strcpy.sprintf 等函数 不安全 ...
- 最新 房多多java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.房多多等10家互联网公司的校招Offer,因为某些自身原因最终选择了房多多.6.7月主要是做系统复习.项目复盘.LeetCo ...
- 最新 东方明珠java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.东方明珠等10家互联网公司的校招Offer,因为某些自身原因最终选择了东方明珠.6.7月主要是做系统复习.项目复盘.Leet ...
- SpringBoot整合Redis及Redis工具类
前言 想做一个秒杀项目,问了几个大佬要了项目视频,结果,自己本地实践的时候,发现不太一样,所以写下这篇,为以后做准备. 环境配置 IDE:IDEA 环境:Windows 数据库:Redis Maven ...
- [LuoguP2124]奶牛美容_bfs_floyd_曼哈顿距离
奶牛美容 题目链接:https://www.luogu.org/problem/P2124 数据范围:略. 题解: 发现数据范围只有$50$,显然可以直接$bfs$求出联通块,$floyd$求出相邻两 ...
- [转帖]Mysql binlog 介绍
binlog介绍 1.什么是binlog binlog是一个二进制格式的文件,用于记录用户对数据库更新的SQL语句信息,例如更改数据库表和更改内容的SQL语句都会记录到binlog里,但是对库表等 ...