[转帖]Greenplum: 基于PostgreSQL的分布式数据库内核揭秘(下篇)
Greenplum: 基于PostgreSQL的分布式数据库内核揭秘(下篇)
http://www.postgres.cn/v2/news/viewone/1/454
原作者:姚延栋 创作时间:2019-05-08 17:25:25+08 采编:wangliyun
发布时间:2019-05-09 08:25:28
欢迎大家踊跃投稿,投稿信箱:press@postgres.cn
评论:0 浏览:1620
作者介绍
姚延栋,山东大学本科,中科院软件所研究生。PostgreSQL中文社区委员,致力于Greenplum/PostgreSQL开源数据库产品、社区和生态的发展。
上篇(链接地址:https://mp.weixin.qq.com/s/DI4U8UoddOHBRiJPzwfr-Q)介绍了集群概述、分布式数据存储和分布式查询优化。本篇继续介绍分布式查询执行、分布式事务、数据洗牌和集群管理等方面。
一、分布式执行器
现在有了分布式数据存储机制,也生成了分布式查询计划,下一步是如何在集群里执行分布式计划,最终返回结果给用户。
Greenplum 执行器相关概念
先看一个 SQL 例子及其计划:
test=# CREATE TABLE students (id int, name text) DISTRIBUTED BY (id);
test=# CREATE TABLE classes(id int, classname text, student_id int) DISTRIBUTED BY (id);
test=# INSERT INTO students VALUES (1, 'steven'), (2, 'changchang'), (3, 'guoguo');
test=# INSERT INTO classes VALUES (1, 'math', 1), (2, 'math', 2), (3, 'physics', 3);
test=# explain SELECT s.name student_name, c.classname
test-# FROM students s, classes c
test-# WHERE s.id=c.student_id;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Gather Motion 2:1 (slice2; segments: 2) (cost=2.07..4.21 rows=4 width=14)
-> Hash Join (cost=2.07..4.21 rows=2 width=14)
Hash Cond: c.student_id = s.id
-> Redistribute Motion 2:2 (slice1; segments: 2) (cost=0.00..2.09 rows=2 width=10)
Hash Key: c.student_id
-> Seq Scan on classes c (cost=0.00..2.03 rows=2 width=10)
-> Hash (cost=2.03..2.03 rows=2 width=12)
-> Seq Scan on students s (cost=0.00..2.03 rows=2 width=12)
Optimizer status: legacy query optimizer
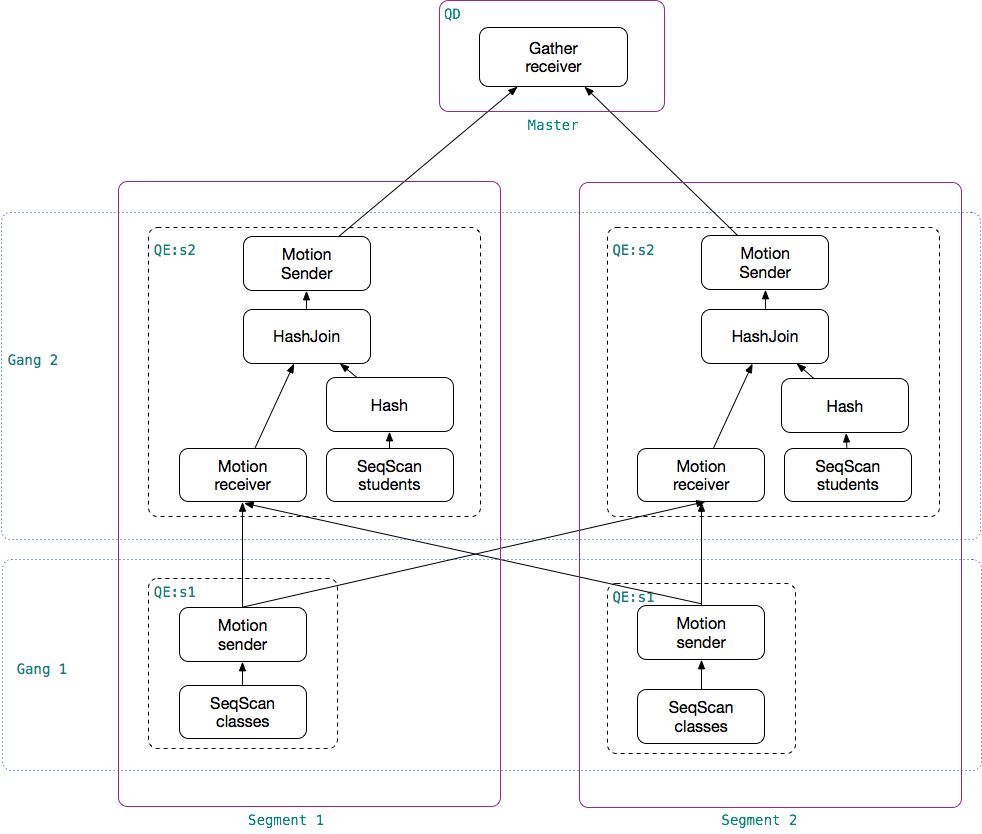
这个图展示了上面例子中的 SQL 在2个segment的Greenplum集群中执行时的示意图。
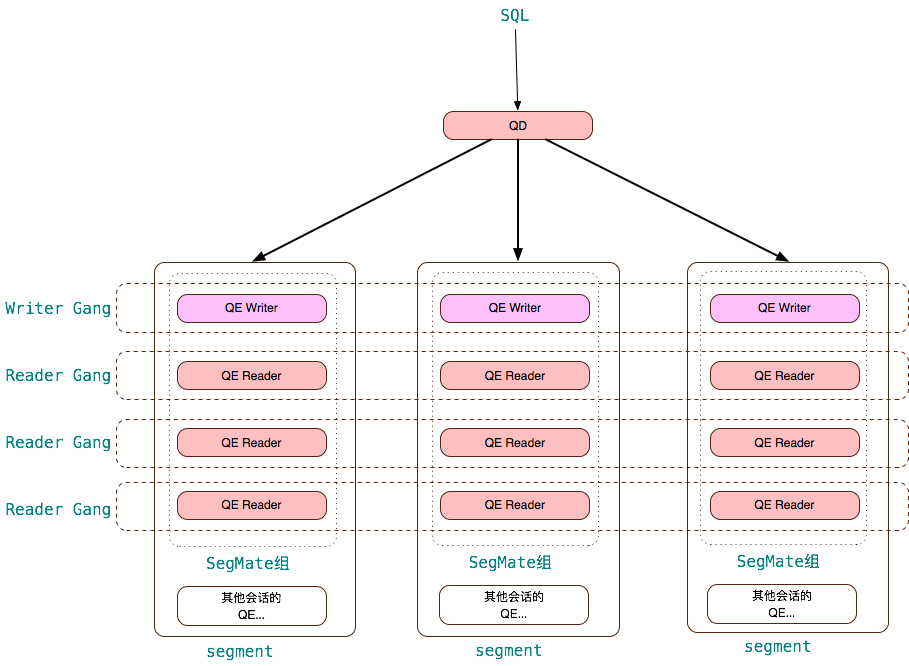
QD(Query Dispatcher、查询调度器):Master 节点上负责处理用户查询请求的进程称为 QD(PostgreSQL 中称之为 Backend 进程)。 QD 收到用户发来的 SQL 请求后,进行解析、重写和优化,将优化后的并行计划分发给每个 segment 上执行,并将最终结果返回给用户。此外还负责整个 SQL 语句涉及到的所有的QE进程间的通讯控制和协调,譬如某个 QE 执行时出现错误时,QD 负责收集错误详细信息,并取消所有其他 QEs;如果 LIMIT n 语句已经满足,则中止所有 QE 的执行等。QD 的入口是 exec_simple_query()。
QE(Query Executor、查询执行器):Segment 上负责执行 QD 分发来的查询任务的进程称为 QE。Segment 实例运行的也是一个 PostgreSQL,所以对于 QE 而言,QD 是一个 PostgreSQL 的客户端,它们之间通过 PostgreSQL 标准的libpq 协议进行通讯。对于 QD 而言,QE 是负责执行其查询请求的PostgreSQL Backend进程。通常 QE 执行整个查询的一部分(称为 Slice)。QE 的入口是 exec_mpp_query()。
Slice:为了提高查询执行并行度和效率,Greenplum 把一个完整的分布式查询计划从下到上分成多个 Slice,每个 Slice 负责计划的一部分。划分slice的边界为 Motion,每遇到 Motion 则一刀将 Motion切成发送方和接收方,得到两颗子树。每个 slice 由一个QE进程处理。上面例子中一共有三个 slice。
Gang:在不同 segments 上执行同一个 slice 的所有 QEs 进程称为 Gang。上例中有两组 Gang,第一组Gang负责在2个segments上分别对表 classes 顺序扫描,并把结果数据重分布发送给第二组Gang;第二组Gang 在2个segments 上分别对表students顺序扫描,与第一组Gang发送到本segment的 classes 数据进行哈希关联,并将最终结果发送给 Master。
并行执行流程
下图展示了查询在 Greenplum 集群中并行执行的流程。该图假设有2个segments,查询计划有两个slices,一共有 4 个 QEs,它们之间通过网络进行通讯。
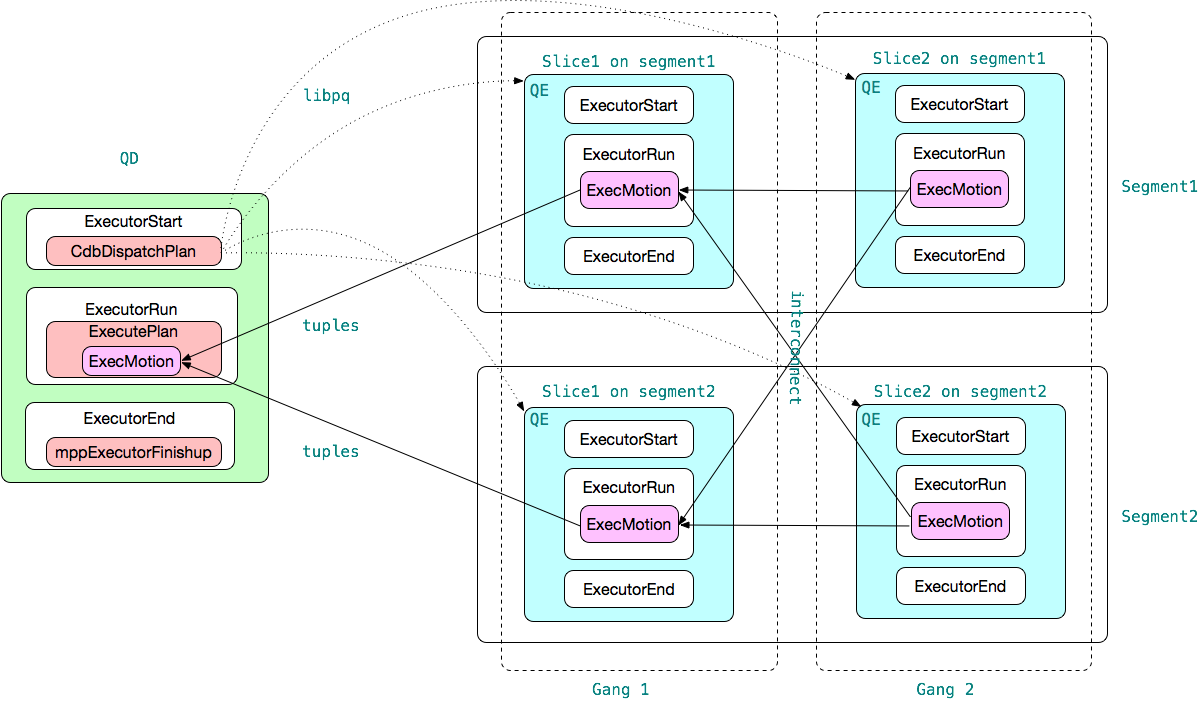
QD 和 QE 都是 PostgreSQL backend 进程,其执行逻辑非常相似。对于数据操作(DML)语句(数据定义语句的执行逻辑更简单),其核心执行逻辑由 ExecutorStart, ExecutorRun, ExecutorEnd 实现。
QD:
●ExecutorStart 负责执行器的初始化和启动。Greenplum 通过 CdbDispatchPlan 把完整的查询计划发送给每个 Gang 中的每个 QE 进程。Greenplum 有两种发送计划给 QE 的方式:1)异步方式,使用 libpq 的异步 API 以非阻塞方式发送查询计划给QE;2)同步多线程方式:使用 libpq 的同步 API,使用多个线程同时发送查询计划给 QE。GUC gp_connections_per_thread 控制使用线程数量,缺省值为0,表示采用异步方式。Greenplum 从6.0开始去掉了异步方式。
●ExecutorRun 启动执行器,执行查询树中每个算子的代码,并以火山模型(volcano)风格返回结果元组给客户端。在 QD 上,ExecutorRun 调用 ExecutePlan 处理查询树,该查询树的最下端的节点是一个 Motion 算子。其对应的函数为 ExecMotion,该函数等待来自于各个 QE 的结果。QD 获得来自于 QE 的元组后,执行某些必要操作(譬如排序)然后返回给最终用户。
●ExecutorEnd 负责执行器的清理工作,包括检查结果,关闭 interconnect 连接等。
QE 上的 ExecutorStart/ExecutorRun/ExecutorEnd 函数和单节点的PostgreSQL代码逻辑类似。主要的区别在 QE 执行的是 Greenplum 分布式计划中的一个 slice,因而其查询树的根节点一定是个 Motion 节点。其对应的执行函数为 ExecMotion,该算子从查询树下部获得元组,并根据 Motion 的类型发送给不同的接收方。低一级的 Gang 的QE把 Motion 节点的结果元组发送给上一级 Gang 的QE,最顶层 Gang 的 QE 的 Motion 会把结果元组发送给 QD。Motion 的 Flow 类型确定了数据传输的方式,有两种:广播和重分布。广播方式将数据发送给上一级 Gang的每一个 QE;重分布方式将数据根据重分布键计算其对应的QE处理节点,并发送给该 QE。
QD 和 QE 之间有两种类型的网络连接:
●libpq:QD 通过 libpq 与各个QE间传输控制信息,包括发送查询计划、收集错误信息、处理取消操作等。libpq 是 PostgreSQL 的标准协议, Greenplum 对该协议进行了增强,譬如新增了 ‘M’ 消息类型 (QD 使用该消息发送查询计划给 QE)。libpq 是基于 TCP 的。
●interconnect:QD 和 QE、QE 和 QE 之间的表元组数据传输通过 interconnect 实现。Greenplum 有两种 interconnect 实现方式,一种基于 TCP,一种基于UDP。缺省方式为 UDP interconnect 连接方式。
Direct Dispatch 优化
有一类特殊的 SQL,执行时只需要单个 segment 执行即可。譬如主键查询:SELECT * FROM tbl WHERE id = 1;
为了提高资源利用率和效率,Greenplum 对这类 SQL 进行了专门的优化,称为 Direct Dispatch 优化:生成查询计划阶段,优化器根据分布键和WHERE子句的条件,判断查询计划是否为 Direct Dispatch 类型查询;在执行阶段,如果计划是 Direct Dispatch,QD 则只会把计划发送给需要执行该计划的单个 segment 执行,而不是发送给所有的 segments 执行。
二. 分布式事务
Greenplum 使用两阶段提交(2PC)协议实现分布式事务。2PC 是数据库经典算法,此处不再赘述。本节概要介绍两个 Greenplum 分布式事务的实现细节:
●分布式事务快照:实现 master和不同segment间一致性
●共享本地快照:实现 segment 内不同 QEs 间的一致性
分布式快照
在分布式环境下,SQL 在不同节点上的执行顺序可能不同。譬如下面例子中 segment1 首先执行SQL1,然后执行 SQL2,所以新插入的数据对 SQL1 不可见;而segment2上先执行 SQL2 后执行 SQL1,因而 SQL1 可以看到新插入的数据。这就造成了数据的不一致。

Greenplum 使用分布式快照和本地映射实现跨节点的数据一致性。Greenplum QD 进程承担分布式事务管理器的角色,在QD开始一个新的事务(StartTransaction)时,它会创建一个新的分布式事务id、设置时间戳及相应的状态信息;在获取快照(GetSnapshotData)时,QD 创建分布式快照并保存在当前快照中。和单节点的快照类似,分布式快照记录了 xmin/xmax/xip 等信息,结构体如下所示:
typedef struct DistributedSnapshot
{
DistributedTransactionTimeStamp distribTransactionTimeStamp;
DistributedTransactionId xminAllDistributedSnapshots;
DistributedSnapshotId distribSnapshotId;
DistributedTransactionId xmin; /* XID < xmin 则可见 */
DistributedTransactionId xmax; /* XID >= xmax 则不可见 */
int32 count; /* inProgressXidArray 数组中分布式事务的个数 */
int32 maxCount;
/* 正在执行的分布式事务数组 */
DistributedTransactionId *inProgressXidArray;
} DistributedSnapshot;
执行查询时,QD 将分布式事务和快照等信息序列化,通过libpq协议发送给 QE。QE 反序列化后,获得 QD 的分布式事务和快照信息。这些信息被用于确定元组的可见性(HeapTupleSatisfiesMVCC)。所有参与查询的 QEs 都使用QD 发送的同一份分布式事务和快照信息判断元组的可见性,因而保证了整个集群数据的一致性,避免前面例子中出现的不一致现象。
在 QE 上判断一个元组对某个快照的可见性流程如下:
●如果创建元组的事务:xid (即元组头中的xmin字段)还没有提交,则不需要使用分布式事务和快照信息;
●否则判断创建元组的事务 xid 对快照是否可见
○首先根据分布式快照信息判断。根据创建元组的 xid 从分布式事务提交日志中找到其对应的分布式事务:distribXid,然后判断 distribXid 对分布式快照是否可见:
■如果 distribXid < distribSnapshot->xmin,则元组可见
■如果 distribXid > distribSnapshot->xmax,则元组不可见
■如果 distribSnapshot->inProgressXidArray 包含 distribXid,则元组不可见
■否则元组可见
○如果不能根据分布式快照判断可见性,或者不需要根据分布式快照判断可见性,则使用本地快照信息判断,这个逻辑和 PostgreSQL 的判断可见性逻辑一样。
和 PostgreSQL 的提交日志 clog 类似,Greenplum 需要保存全局事务的提交日志,以判断某个事务是否已经提交。这些信息保存在共享内存中并持久化存储在 distributedlog 目录下。
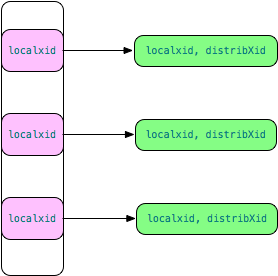
为了提高判断本地 xid 可见性的效率,避免每次访问全局事务提交日志,Greenplum 引入了本地事务-分布式事务提交缓存,如下图所示。每个 QE 都维护了这样一个缓存,通过该缓存,可以快速查到本地 xid 对应的全局事务distribXid 信息,进而根据全局快照判断可见性,避免频繁访问共享内存或磁盘。
共享本地快照(Shared Local Snapshot)
Greenplum 中一个 SQL 查询计划可能含有多个 slices,每个 Slice 对应一个 QE 进程。任一 segment 上,同一会话(处理同一个用户SQL)的不同 QE 必须有相同的可见性。然而每个 QE 进程都是独立的 PostgreSQL backend进程,它们之间互相不知道对方的存在,因而其事务和快照信息都是不一样的。如下图所示。
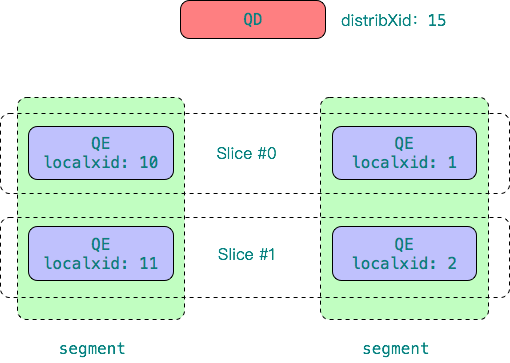
为了保证跨slice可见性的一致性,Greenplum引入了 “共享本地快照(Shared Local Snapshot)” 的概念。每个 segment 上的执行同一个SQL的不同 QEs 通过共享内存数据结构 SharedSnapshotSlot 共享会话和事务信息。这些进程称为 SegMate 进程组。
Greenplum 把 SegMate 进程组中的 QE 分为 QE writer 和 QE reader。QE writer 有且只有一个,QE reader 可以没有或者多个。QE writer 可以修改数据库状态;QE reader 不能修改数据库的状态,且需要使用和 QE writer 一样的快照信息以保持与 QE writer 一致的可见性。如下图所示。
“共享”意味着该快照在 QE writer 和 readers 间共享,“本地” 意味着这个快照是 segment 的本地快照,同一用户会话在不同的 segment 上可以有不同的快照。segment 的共享内存中有一个区域存储共享快照,该区域被分成很多槽(slots)。一个 SegMate 进程组对应一个槽,通过唯一的会话id标志。一个 segment 可能有多个 SegMate 进程组,每个进程组对应一个用户的会话,如下图所示。
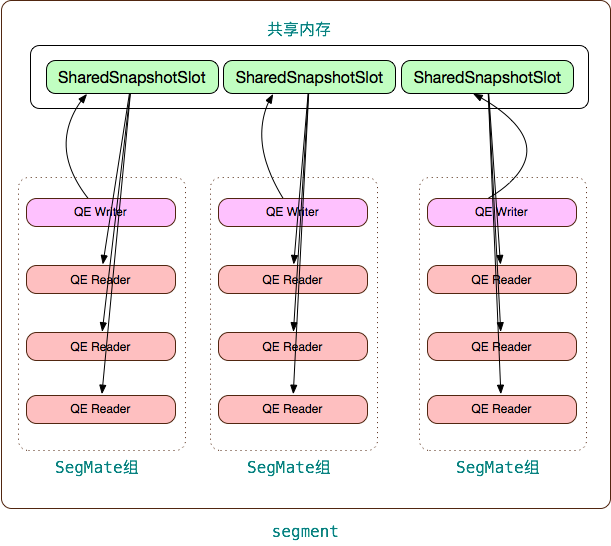
QE Writer 创建本地事务后,在共享内存中获得一个 SharedLocalSnapshot 槽,并它自己的本地事务和快照信息拷贝到共享内存槽中,SegMate 进程组中的其他 QE Reader 从该共享内存中获得事务和快照信息。Reader QEs 会等待 Writer QE 直到 Writer 设置好共享本地快照信息。
只有 QE writer 参与全局事务,也只有该 QE 需要处理 commit/abort 等事务命令。
三、 数据洗牌(Shuffle)
相邻 Gang 之间的数据传输称为数据洗牌(Data Shuffling)。数据洗牌和 Slice 的层次相吻合,从下到上一层一层通过网络进行数据传输,不能跨层传输数据。根据 Motion 类型的不同有不同的实现方式,譬如广播和重分布。
Greenplum 实现数据洗牌的技术称为 interconnect,它为 QEs 提供高速并行的数据传输服务,不需要磁盘IO操作,是Greenplum实现高性能查询执行的重要技术之一。interconnect 只用来传输数据(表单的元组),调度、控制和错误处理等信息通过 QD 和 QE 之间的 libpq 连接传输。
Interconnect 有 TCP 和 UDP 两种实现方式,TCP interconnect 在大规模集群中会占用大量端口资源,因而扩展性较低。Greenplum 默认使用 UDP 方式。UDP interconnect 支持流量控制、网络包重发和确认等特性。
四. 分布式集群管理
分布式集群包含多个物理节点,少则四五台,多则数百台。管理如此多机器的复杂度远远大于单个PostgreSQL数据库。为了简化数据库集群的管理, Greenplum 提供了大量的工具。下面列出一些常用的工具,关于更多工具的信息可以参考 Greenplum 数据库管理员官方文档。
●gpactivatestandby: 激活 standby master,使之成为 Greenplum 数据库集群的主 master。
●gpaddmirrors:为 Greenplum 集群添加镜像节点,以提高高可用性
●gpcheckcat:检查Greenplum数据库的系统表,用以辅助故障分析。
●gpcheckperf:检查 Greenplum 集群的系统性能,包括磁盘、网络和内存的性能。
●gpconfig:为 Greenplum 集群中的所有节点进行参数配置。
●gpdeletesystem:删除整个 Greenplum 集群
●gpexpand:添加新机器到Greenplum集群中,用以扩容。
●gpfdist:Greenplum 的文件分发服务器,是 Greenplum 数据加载和卸载的最主要工具。gpfdist 充分利用并行处理,性能非常高。
●gpload:封装 gpfdist 和外部表等信息,通过配置YAML文件,可以方便的加载数据到 Greenplum 数据库中。支持 INSERT、UPDATE和MERGE三种模式。
●gpinitstandby:为Greenplum集群初始化 standby master
●gpinitsystem:初始化 Greenplum 集群
●gppkg:Greenplum 提供的软件包管理工具,可以方便的在所有节点上安装 Greenplum 软件包,譬如 PostGIS、PLR 等。
●gprecoverseg:恢复出现故障的主 segment 节点或者镜像 segment 节点
●gpssh/gpscp:标准的 ssh/scp 只能针对一个目标机器进行远程命令执行和文件拷贝操作。gpssh 可以同时在一组机器上执行同一个命令;gpscp 同时拷贝一个文件或者目录到多个目标机器上。 很多 Greenplum 命令行工具都使用这两个工具实现集群并行命令执行。
●gpstart:启动一个 Greenplum 集群。
●gpstop:停止一个 Greenplum 集群
●gpstate:显示 Greenplum 集群的状态
●gpcopy:将一个 Greenplum 数据库的数据迁移到另一个 Greenplum 数据库中。
●gp_dump/gp_restore:Greenplum 数据备份恢复工具。从 Greenplum 5.x 开始,推荐使用新的备份恢复工具: gpbackup/gprestore。
●packcore:packcore 可以将一个 core dump 文件及其所有的依赖打成一个包,可以在其他机器上进行调试。非常有用的一个调试用具。
●explain.pl:把 EXPLAIN 的文本结果转换成图片。本节中用的计划树图片都是使用这个工具生成的。
五. 动手实践
上面概要介绍了把单个 PostgreSQL 数据库变成分布式数据库涉及的6个方面的工作。若对更多细节感兴趣,最有效的方式是动手改改代码实现某些新特性。下面几个项目可以作为参考:
●数据存储:实现 partial table,使得一张表或者一个数据库仅仅使用集群的一个子集。譬如集群有200个节点,可以创建只是用10个节点的表或者数据库。
●资源管理:目前的 Gang 只能在一个会话内部共享,实现 Gang 的跨会话共享,或者 Gang 共享池。
●调度:目前 dispatcher 将整个plan发送给每个 QE,可以发送单个slice给负责执行该slice的QE
●性能优化:分析 Greenplum 分布式执行的性能瓶颈,并进行进一步的优化,特别是 OLTP 型查询的性能优化,以实现更高 tps。
●执行器优化:目前 Greenplum 使用 zstd 压缩 AO 数据和临时数据,zstd造成的一个问题是内存消耗较大,如何优化操作大量压缩文件时的内存消耗是一个很有挑战的课题。有关更多细节可以参考这个讨论(最后部分有简单的问题重现方法)。链接地址:https://github.com/greenplum-db/gpdb/pull/6508
对这些项目有兴趣者可以联系yyao AT pivotal DOT io提供更多咨询或帮助。实现以上任何一个功能者,可以走快速通道加入 Greenplum 内核开发团队,共应挑战共享喜悦 :)
六. 后记
想了一会,本想写一点打鸡血的话吸引更多人加入数据库内核开发行列,然觉不合自性,作罢。
Greenplum 酒文化比较浓厚,还是分享一个与酒有关的小故事收尾吧。
13/14年左右有幸和数据库老前辈 Dan Holle(Teradata CTO,第七号员工)有诸多交集。老爷子谈吐优雅而不失幽默,从事MPP数据库已有30余年。每次喝酒至少放两瓶酒于面前,且同时喝两瓶酒,笑谈此为并行处理;若某一瓶喝的多了,必拿起另一瓶再喝一点,以确保两瓶余量保持一致,笑谈此为避免倾斜。经常左瓶喝的多了点,拿起右瓶补一口,补多了,再拿起左瓶补一口。如此左右互补,无需山东人劝酒,自己很快进入状态。
老先生对 MPP 数据库之爱已融入生活中,令人敬佩。而正是许多这样数十年如一日的匠人成就了当今数据库领域的辉煌。期待更多人加入,幕天席地把酒言欢!
[转帖]Greenplum: 基于PostgreSQL的分布式数据库内核揭秘(下篇)的更多相关文章
- [转帖]Greenplum :基于 PostgreSQL 的分布式数据库内核揭秘 (上篇)
Greenplum :基于 PostgreSQL 的分布式数据库内核揭秘 (上篇) https://www.infoq.cn/article/3IJ7L8HVR2MXhqaqI2RA 学长的文章.. ...
- 新浪微博基于MySQL的分布式数据库实践
提起微博,相信大家都是很了解的.但是有谁知道微博的数据库架构是怎样的呢?在今天举行的2011数据库技术大会上,新浪首席DBA杨海潮为我们详细解读了新浪微博的数据库架构——基于MySQL的分布式数据库实 ...
- GreenPlum:基于PostgreSQL的分布式关系型数据库
GreenPlum是一个底层是多台PostgreSQL分表分库的分布式数据库,它有如下特点 支持标准SQL,几乎所有PostgreSQL支持的SQL,greenplum都支持 支持ACID.分布式事务 ...
- 谈谈分布式事务之二:基于DTC的分布式事务管理模型[下篇]
[续上篇] 当基于LTM或者KTM的事务提升到基于DTC的分布式事务后,DTC成为了本机所有事务型资源管理器的管理者:此外,当一个事务型操作超出了本机的范 围,出现了跨机器的调用后,本机的DTC需要于 ...
- PostgreSQL 优势,MySQL 数据库自身的特性并不十分丰富,触发器和存储过程的支持较弱,Greenplum、AWS 的 Redshift 等都是基于 PostgreSQL 开发的
PostgreSQL 优势 2016-10-20 21:36 686人阅读 评论(0) 收藏 举报 分类: MYSQL数据库(5) PostgreSQL 是一个自由的对象-关系数据库服务器(数据库 ...
- Pivotal开源基于PostgreSQL的数据库Greenplum
http://www.infoq.com/cn/news/2015/11/PostgreSQL-Pivotal 近日,Pivotal宣布开源大规模并行处理(MPP)数据库Greenplum,其架构是针 ...
- 打造基于 PostgreSQL/openGauss 的分布式数据库解决方案
在 MySQL ShardingSphere-Proxy 逐渐成熟并被广泛采用的同时,ShardingSphere 团队也在 PostgreSQL ShardingSphere-Proxy 上持续发力 ...
- OpenTSDB介绍——基于Hbase的分布式的,可伸缩的时间序列数据库,而Hbase本质是列存储
原文链接:http://www.jianshu.com/p/0bafd0168647 OpenTSDB介绍 1.1.OpenTSDB是什么?主要用途是什么? 官方文档这样描述:OpenTSDB is ...
- 基于Sql Server 2008的分布式数据库的实践(五)
原文 基于Sql Server 2008的分布式数据库的实践(五) 程序设计 ------------------------------------------------------------- ...
随机推荐
- P2698 [USACO12MAR]花盆Flowerpot——单调队列
记录每天看(抄)题解的日常: https://www.luogu.org/problem/P2698 我们可以把坐标按照x递增的顺序排个序,这样我们就只剩下纵坐标了: 如果横坐标(l,r)区间,纵坐标 ...
- 基于部标1078视频协议和苏标Adas协议构建主动安全平台
苏标本身仍然是基于部标808协议的基础上递增起草的,苏标协议是包容808协议的, 不能脱离808协议而独立存在的, 主要基于<JT/T 796 道路运输车辆卫星定位系统平台技术要求>.&l ...
- 线程池(2)-Executors提供4个线程池
1.为什么不使用Executors提供4个线程池创建线程池 阿里巴巴开放手册这样写: . [强制]线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式, ...
- Spring —— @Async注解的使用
参考文档 Spring Boot使用@Async实现异步调用:自定义线程池 Spring Boot使用@Async实现异步调用:ThreadPoolTaskScheduler线程池的优雅关闭
- Go by Example-常量
Go by Example 中文:常量 在上一节中提到了变量,常用的有两种定义的方式使用var或者短变量的形式进行定义,这节我们来说常量. 常量 常量是指程序运行时不可改变的值,常量必须初始化值,定义 ...
- boost 介绍
简介: Boost库是一个可移植.提供源代码的C++库,作为标准库的后备,是C++标准化进程的开发引擎之一. Boost库由C++标准委员会库工作组成员发起,其中有些内容有望成为下一代C++标准库内容 ...
- PhpStorm 增加Swoole智能提示
下载https://github.com/eaglewu/swoole-ide-helper的源码 git clone https://github.com/eaglewu/swoole-ide-he ...
- Discretized Streams: A Fault-Tolerant Model for Scalable Stream Processing
https://www2.eecs.berkeley.edu/Pubs/TechRpts/2012/EECS-2012-259.pdf Discretized Streams: A Fault-Tol ...
- Redis操作类型
- SpringCloud学习成长之路 五 路由器网关
在微服务架构中,需要几个基础的服务治理组件,包括服务注册与发现.服务消费.负载均衡.断路器.智能路由.配置管理等,由这几个基础组件相互协作,共同组建了一个简单的微服务系统.一个简答的微服务系统如下图: ...