透彻网络流-wfx-最大流
前提:
我们想象一下自来水厂到你家的水管网是一个复杂的有向图,每一节水管都有一个最大承载流量。自来水厂不放水,你家就断水了。但是就算自来水厂拼命的往管网里面注水,你家收到的水流量也是上限(毕竟每根水管承载量有限)。你想知道你能够拿到多少水,这就是一种网络流问题。
在网上找了很久资料,虽然讲解网络流的资料很多但是浅显易懂的很少(可能是我太蒻了吧),写这篇文章只希望点进来的人都能学会网络流(都能点赞)
首先
最大流:
何为最大流 简单来说就是水流从一个源点s通过很多路径,经过很多点,到达汇点t,问你最多能有多少水能够到达t点。
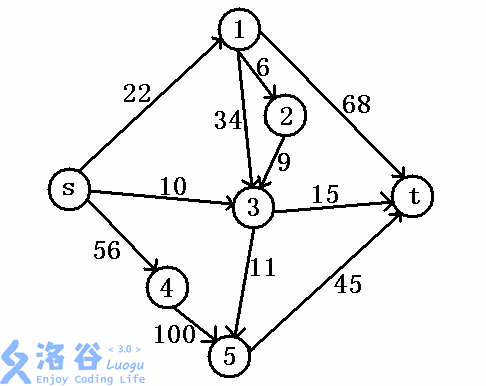
结合图示理解: 从s到t经过若干个点,若干条边,每一条边的水流都不能超过边权值(可以小于等于但不能大于),所以该图的最大流就是10+22+45=77。 如果你还是不能理解,我们就换一种说法,假设s城有inf个人想去t城,但是从s到t要经过一些城市才能到达,(以上图为例)其中s到3城的火车票还剩10张,3到t的火车票还剩15张,其他路以此类推,问最终最多能有多少人能到达t城?
EK:
Edmond—Karp
增广路:
增广路: 增广路是指从s到t的一条路,流过这条路,使得当前的流(可以到达t的人)可以增加。 那么求最大流问题可以转换为不断求解增广路的问题,并且,显然当图中不存在增广路时就达到了最大流。 具体怎么操作呢? 其实很简单,直接从s到t广搜即可,从s开始不断向外广搜,通过权值大于0的边(因为后面会减边权值,所以可能存在边权为0的边),直到找到t为止,然后找到该路径上边权最小的边,记为mi,然后最大流加mi,然后把该路径上的每一条边的边权减去mi,直到找不到一条增广路(从s到t的一条路径)为止。(为什么要用mi呢?你要争取在这条路上多走更多人,但又不能让人停在某个城市)
代码:
#include<cstdio>
#include<cstdlib>
#include<queue>
#include<iostream>
using namespace std;
const int inf = 2147483647;
const int MAXN = 100100;
int head[MAXN],cnt = 1,low[MAXN],pre[MAXN],n,m,S,T;
int maxflow;
bool v[MAXN];
inline int read(){
int res = 0; char ch = getchar(); bool bo = false;
while(ch < '0' || ch > '9') bo = (ch == '-'), ch = getchar();
while(ch >= '0' && ch <= '9') res = (res << 1) + (res << 3) + (ch ^ 48), ch = getchar();
return bo ? -res : res;
}
struct node{int nxt,to,dis;}e[MAXN<<1];
void add(int from,int to,int dis)
{
e[++cnt]= (node){head[from],to,dis};
head[from]=cnt;
}
void EK()
{
int x=T;
while(x!=S)
{
int i=pre[x];
e[i].dis-=low[T];
e[i^1].dis+=low[T];
x=e[i^1].to;
}
maxflow += low[T];
}
queue <int> q;
bool bfs()
{
for(int i=1;i<=n;i++)v[i]=0;
while(q.size()) q.pop();
v[S]=1;
q.push(S);
low[S]=inf;
while(q.size())
{
int x=q.front();
q.pop();
for(int i=head[x];i;i=e[i].nxt)
{
if(e[i].dis > 0)
{
int y=e[i].to;
if(v[y])continue;
low[y]=min(low[x],e[i].dis);
pre[y]=i;
q.push(y);v[y]=1;
if(y==T)return true;
}
}
}
return false;
}
int main()
{
n=read();m=read();S=read();T=read();
int x,y,c;
for(int i=1;i<=m;i++)
{
x=read();y=read();c=read();
add(x,y,c); add(y,x,0);
}
while(bfs()) EK();
printf("%d\n",maxflow);
return 0;
}
Dinic:
Dinic算法分为两个步骤:
- bfs分层(在EK中bfs是用于寻找增广路的)
- dfs增广
(dfs?EK中貌似没有这玩意啊,确定能高效?) 咦!刚才不是说两个步骤吗?重复执行1.2.直到图中无增广路为止
什么意思呢?
与EK一样,我们仍要通过bfs来判断图中是否还存在增广路,但是DInic算法里的bfs略有不同,这次,我们不用记录路径,而是给每一个点分层,对于任意点i,从s到i每多走过一个点,就让层数多一。
其实每次只找层数大一的,认为找最短增广路,为神魔呢:

有了分层,我们就不会选s->1->2->4->5->3->t了
刚才说了的,分完层下一步是dfs增广。
在Dinic中,我们找增广路是用深搜:
代码:
#include<cstdio>
#include<cstdlib>
#include<iostream>
#include<queue>
#include<cstring>
using namespace std;
const int N = 100100;
const int inf = 214748347;
int cnt=1,head[10010],d[10010],n,m,s,t,maxflow;
bool v[N];
struct node{int nxt,to,dis;}e[N<<1];
void add(int from,int to,int dis)
{
e[++cnt] = (node){head[from],to,dis};
head[from]=cnt;
} queue <int> q;
bool bfs()
{
memset(d,0,sizeof d);
while(q.size())q.pop();
q.push(s);
d[s]=1;
while(q.size())
{
int x=q.front();q.pop();
for(int i=head[x];i;i=e[i].nxt)
{
int y=e[i].to;
if(e[i].dis && !d[y])
{
q.push(y);
d[y]=d[x]+1;
if(e[i].to==t)return 1;
}
}
}
return 0;
}
int dinic(int x,int flow)
{
if(x==t)return flow;
int rest=flow,k;
for(int i=head[x];i&&rest;i=e[i].nxt)
{
int y=e[i].to;
if(e[i].dis&&d[y]==d[x]+1)
{
k=dinic(y,min(rest,e[i].dis));
if(!k) d[y]=0;
e[i].dis-=k;
e[i^1].dis+=k;
rest-=k;
}
}
return flow-rest;
}
int main()
{
scanf("%d%d%d%d",&n,&m,&s,&t);
int x,y,c;
for(int i=1;i<=m;i++)
{
scanf("%d%d%d",&x,&y,&c);
add(x,y,c);add(y,x,0);
}
int flow=0;
while(bfs())
{
while(flow=dinic(s,inf)) maxflow+=flow;
}
printf("%d\n",maxflow);
return 0;
}
还有一种超强的优化:当前弧(边)优化:
我们定义一个数组cur记录当前边(弧)(功能类比邻接表中的head数组,只是会随着dfs的进行而修改),
每次我们找过某条边(弧)时,修改cur数组,改成该边(弧)的编号,
那么下次到达该点时,会直接从cur对应的边开始(也就是说从head到cur中间的那一些边(弧)我们就不走了)。
有点抽象啊,感觉并不能加快,然而实际上确实快了很多。
代码:
bool bfs()
{
for(int i=1;i<=n;i++)
{
cur[i]=head[i];///////////////////只修改这几处,让你的代码飞快,相当于节省了dfs
d[i]=0;///////中的链式前向星,因为head【】的边有的已经在前面使用
}
while(q.size())q.pop();
q.push(s);
d[s]=1;
while(q.size())
{
int x=q.front();q.pop();
for(int i=head[x];i;i=e[i].nxt)
{
int y=e[i].to;
if(e[i].dis && !d[y])
{
q.push(y);
d[y]=d[x]+1;
if(e[i].to==t)return 1;
}
}
}
return 0;
}
int dinic(int x,int flow)
{
if(x==t)return flow;
int rest=flow,k;
for(int i=cur[x];i&&rest;i=e[i].nxt)//////////////////
{
cur[x]=i;/////////////////
int y=e[i].to;
if(e[i].dis&&d[y]==d[x]+1)
{
k=dinic(y,min(rest,e[i].dis));
if(!k) d[y]=0;
e[i].dis-=k;
e[i^1].dis+=k;
rest-=k;
}
}
return flow-rest;
}
感谢__wfx 一下午的讲解,自己明白了很多
!!!!!!!!!!!!!!!!!!
缘来是你
透彻网络流-wfx-最大流的更多相关文章
- hdu 4940 Destroy Transportation system( 无源汇上下界网络流的可行流推断 )
题意:有n个点和m条有向边构成的网络.每条边有两个花费: d:毁坏这条边的花费 b:重建一条双向边的花费 寻找这样两个点集,使得点集s到点集t满足 毁坏全部S到T的路径的费用和 > 毁坏全部T到 ...
- 【Luogu2711】小行星(网络流,最大流)
[Luogu2711]小行星(网络流,最大流) 题面 题目描述 星云中有n颗行星,每颗行星的位置是(x,y,z).每次可以消除一个面(即x,y或z坐标相等)的行星,但是由于时间有限,求消除这些行星的最 ...
- 网络流之最大流Dinic算法模版
/* 网络流之最大流Dinic算法模版 */ #include <cstring> #include <cstdio> #include <queue> using ...
- 【BZOJ2324】[ZJOI2011]营救皮卡丘(网络流,费用流)
[BZOJ2324][ZJOI2011]营救皮卡丘(网络流,费用流) 题面 BZOJ 洛谷 题解 如果考虑每个人走的路径,就会很麻烦. 转过来考虑每个人破坏的点集,这样子每个人可以得到一个上升的序列. ...
- HDU 3416 Marriage Match IV (最短路径,网络流,最大流)
HDU 3416 Marriage Match IV (最短路径,网络流,最大流) Description Do not sincere non-interference. Like that sho ...
- HDU 3605 Escape (网络流,最大流,位运算压缩)
HDU 3605 Escape (网络流,最大流,位运算压缩) Description 2012 If this is the end of the world how to do? I do not ...
- HDU 3338 Kakuro Extension (网络流,最大流)
HDU 3338 Kakuro Extension (网络流,最大流) Description If you solved problem like this, forget it.Because y ...
- POJ 2711 Leapin' Lizards / HDU 2732 Leapin' Lizards / BZOJ 1066 [SCOI2007]蜥蜴(网络流,最大流)
POJ 2711 Leapin' Lizards / HDU 2732 Leapin' Lizards / BZOJ 1066 [SCOI2007]蜥蜴(网络流,最大流) Description Yo ...
- UVA 10480 Sabotage (网络流,最大流,最小割)
UVA 10480 Sabotage (网络流,最大流,最小割) Description The regime of a small but wealthy dictatorship has been ...
随机推荐
- Python基础 第四章 字典(1)
通过名称来访问其各个值的数据结构,映射(mapping). 字典,是Python中唯一的内置映射类型,其中的值不按顺序排列,而是存储在键下.(键,可能是数.字符串.元组). 1.1 字典由 键 及其相 ...
- Creating mailbox file: 文件已存在
原来linux下添加用户后,会在系统里自动加一个邮箱(系统邮箱),路径是:/var/spool/mail/用户名.可以直接用命令#rm -rf /var/spool/mail/用户名 这样就可以再次添 ...
- pb菜单详解和MDI
菜单条-MenuBar.菜单项-MenuItem.级联菜单(子菜单)-SubMenu 菜单项(MenuItem)是菜单中最基本的元素,只要有文字内容的就是菜单项.菜单条(MenuBar)是菜单中级别最 ...
- shell习题第19题:最常用的命令
[题目要求] 查看使用最多的10个命令 [核心要点] history 或者 ~/.bash_history sort uniq [脚本] #!/bin/bash # history就是调用cat ~/ ...
- antd做form表单的组件共用,利用mapPropsToFields填写默认值
做单页应用,不管是用Vue还是React,或者其他,有一个重要的原则,就是:组件重用. 既然组件可以重用,那么当添加一个信息,和修改该信息的布局必然是一致的,这时候,最好的方法自然是利用同一个组件,在 ...
- 给postmessage加上callback方法
postmessage双向通信中,是不能使用回调函数的. window.postmessage({msg:'hello',callback:function(e){ do something with ...
- Java API 之 SPI机制
SPI SPI全称是service provider interface,是Java定义的一套服务发现机制,如图: 调用方只需要面向接口,接口的实现由第三方自己去实现,服务启动的时候会自动去发现该服务 ...
- 有趣的"=="与"==="
console.log([]==![]);//true //"=="会进行类型转换,转换成统一类型进行比较 // !符号优于==,[]boolean值为TRUE,所以![]就是FA ...
- Tomcat 输出日志出现中文乱码
Tomcat 输出日志出现中文乱码 解决方案: 打开到tomcat安装目录下的conf/文件夹 修改logging.properties文件,找到 java.util.logging.ConsoleH ...
- time 时间模块的函数调用
时间模块 time 此模块提供了时间相关的函数,且一直可用 时间简介 公元纪年是从公元 0000年1月1日0时开始的 计算机元年是从1970年1月1日0时开始的,此时时间为0,之后每过一秒时间+1 U ...