爬 NationalData ,虽然可以直接下,但还是爬一下吧
爬取的是分省月度数据,2017年的,包括:居民消费价格指数,食品烟酒类居民消费价格指数,衣着类居民消费价格指数,居住类居民消费价格指数,生活用品及服务类居民消费价格指数,交通和通信类居民消费价格指数,教育文化和娱乐类居民消费价格指数,医疗保健类居民消费价格指数,其他用品和服务类居民消费价格指数。
打开网站,地区数据-----分省月度数据,如图:
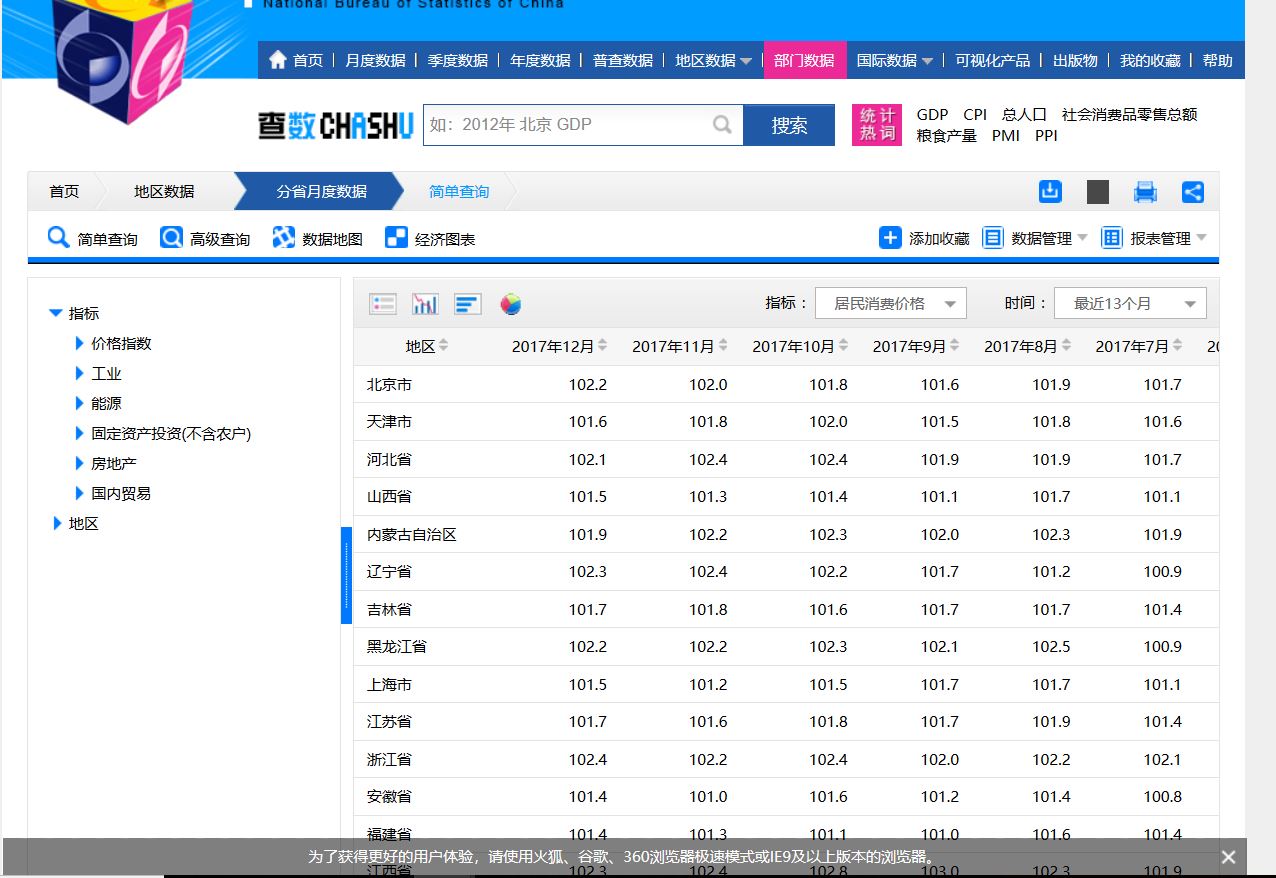
按F12,在按F5会出现3个请求url:
1:http://data.stats.gov.cn/easyquery.htm
2:http://data.stats.gov.cn/easyquery.htm?m=getOtherWds&dbcode=fsyd&rowcode=reg&colcode=sj&wds=[]&k1=1516511359046
3:http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=fsyd&rowcode=reg&colcode=sj&wds=[{"wdcode":"zb","valuecode":"A01010101"}]&dfwds=[]&k1=1516511359249
这三个请求url都有用,但这个爬虫只用了两个:2,3
2的效果图:

3的效果图:

代码如下:
import urllib
from urllib import request
from json import loads
import pymssql # 发起请求
def getRequestBody(url):
return urllib.request.urlopen(url).read().decode('utf8')
# 获取指标类型
def getTarget(url):
body = getRequestBody(url)
print('body', body)
dicts = loads(body)
return dicts['returndata'] url = 'http://data.stats.gov.cn/easyquery.htm?m=getOtherWds&dbcode=fsyd&rowcode=reg&colcode=sj&wds=[]&k1=1516507560165'
targetList_returnData = getTarget(url) # list
print('targetList_returnData',targetList_returnData)
for targetIndex_returnData in range(len(targetList_returnData)):
targetDict_returnData = dict(targetList_returnData[targetIndex_returnData]) # dict
targetList_nodes = targetDict_returnData['nodes'] # list
# 请求无法得到,但却有,只能硬来了
targetList_nodes.append({'code': 'A01010106', 'name': '交通和通信类居民消费价格指数(上年同月=100)', 'sort': '1'})
targetList_nodes.append({'code': 'A01010107', 'name': '教育文化和娱乐类居民消费价格指数(上年同月=100)', 'sort': '1'})
targetList_nodes.append({'code': 'A01010108', 'name': '医疗保健类居民消费价格指数(上年同月=100)', 'sort': '1'})
targetList_nodes.append({'code': 'A01010109', 'name': '其他用品和服务类居民消费价格指数(上年同月=100)', 'sort': '1'})
print('targetList_nodes',targetList_nodes)
for targetIndex_nodes in range(len(targetList_nodes)):
targetDict_nodes = dict(targetList_nodes[targetIndex_nodes]) # dict
print(targetDict_nodes['code'],targetDict_nodes['name'])
#
url1 = 'http://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=fsyd&rowcode=reg&colcode=sj' \
'&wds=[{"wdcode":"zb","valuecode":"%s"}]&dfwds=[]' %(targetDict_nodes['code'])
body1 = getRequestBody(url1)
print('body1',body1)
dictAll = loads(body1)
# 获取wdnodes键的name,以name当表名
dataList2 = dictAll['returndata']['wdnodes']
dataList2.pop()
name = dataList2[0]['nodes'][0]['cname']
if name.find('(') != -1:
name = name[:name.find('(')] + '2017'
print(name)
# 获取wdnodes键的地区
regionList = dataList2[1]['nodes']
# 获取datanodes键的内容
dataList1 = dictAll['returndata']['datanodes']
# 控制遍历,以删除2016年12月的数据,只要2017年的数据
index = 1
# 控制插入的地区
region = 0
# 存储具体数据
data = []
for dataIndex1 in range(len(dataList1)):
if index <= 12:
# 获取‘datanodes’的指数数据
data_f = dataList1[dataIndex1]['data']['data']
print(data_f,index)
data.append(data_f)
conn = pymssql.connect(host='localhost', user='sa', password='123456c', database='NationalData', charset='utf8')
cur = conn.cursor()
if index == 12:
print(regionList[region]['cname'])
sql ='''insert into {} values('{}',{},{},{},{},{},{},{},{},{},{},{},{});'''\
.format(name,regionList[region]['cname'],data[0],data[1],data[2],data[3],data[4],data[5],data[6],data[7],data[8],data[9],data[10],data[11])
region += 1
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
elif index == 13:
data = []
index = 0
index += 1
break
数据库有如下表:
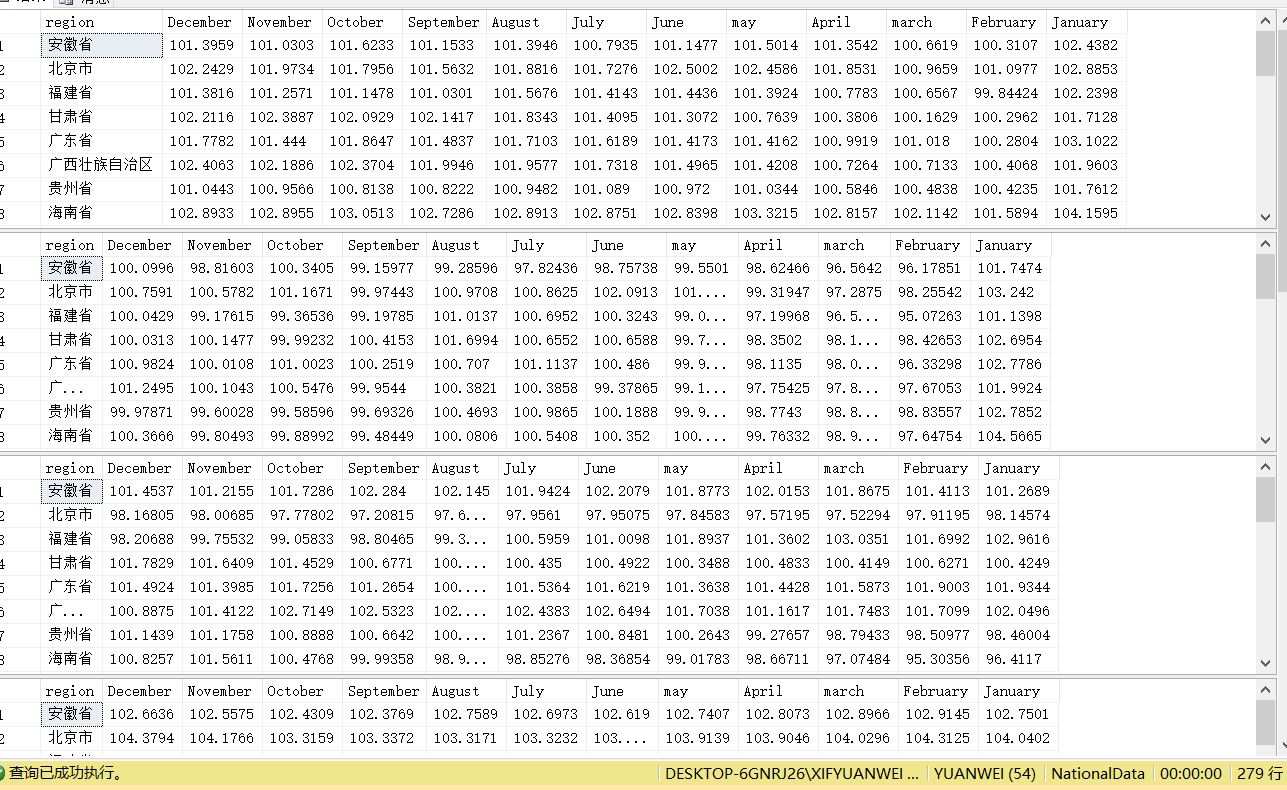
结果:
爬 NationalData ,虽然可以直接下,但还是爬一下吧的更多相关文章
- 安居客scrapy房产信息爬取到数据可视化(下)-可视化代码
接上篇:安居客scrapy房产信息爬取到数据可视化(下)-可视化代码,可视化的实现~ 先看看保存的数据吧~ 本人之前都是习惯把爬到的数据保存到本地json文件, 这次保存到数据库后发现使用mongod ...
- 一个简单的爬取b站up下所有视频的所有评论信息的爬虫
心血来潮搞了一个简单的爬虫,主要是想知道某个人的b站账号,但是你知道,b站在搜索一个用户时,如果这个用户没有投过稿,是搜不到的,,,这时就只能想方法搞到对方的mid,,就是 space.bilibil ...
- MOJITO 发布一周,爬一波弹幕分析下
MOJITO 最近一直啥都没写,追个热点都赶不上热乎的,鄙视自己一下. 周董的新歌 「MOJITO」 发售(6 月 12 日的零点)至今大致过去了一周,翻开 B 站 MV 一看,播放量妥妥破千万,弹幕 ...
- (4)分布式下的爬虫Scrapy应该如何做-规则自动爬取及命令行下传参
本次探讨的主题是规则爬取的实现及命令行下的自定义参数的传递,规则下的爬虫在我看来才是真正意义上的爬虫. 我们选从逻辑上来看,这种爬虫是如何工作的: 我们给定一个起点的url link ,进入页面之后提 ...
- python3爬虫爬取猫眼电影TOP100(含详细爬取思路)
待爬取的网页地址为https://maoyan.com/board/4,本次以requests.BeautifulSoup css selector为路线进行爬取,最终目的是把影片排名.图片.名称.演 ...
- Scrapy 实现爬取多页数据 + 多层url数据爬取
项目需求:爬取https://www.4567tv.tv/frim/index1.html网站前三页的电影名称和电影的导演名称 项目分析:电影名称在初次发的url返回的response中可以获取,可以 ...
- python爬虫---CrawlSpider实现的全站数据的爬取,分布式,增量式,所有的反爬机制
CrawlSpider实现的全站数据的爬取 新建一个工程 cd 工程 创建爬虫文件:scrapy genspider -t crawl spiderName www.xxx.com 连接提取器Link ...
- python爬取实习僧招聘信息字体反爬
参考博客:http://www.cnblogs.com/eastonliu/p/9925652.html 实习僧招聘的网站采用了字体反爬,在页面上显示正常,查看源码关键信息乱码,如下图所示: 查看网页 ...
- Python反爬:利用js逆向和woff文件爬取猫眼电影评分信息
首先:看看运行结果效果如何! 1. 实现思路 小编基本实现思路如下: 利用js逆向模拟请求得到电影评分的页面(就是猫眼电影的评分信息并不是我们上述看到的那个页面上,应该它的实现是在一个页面上插入另外一 ...
随机推荐
- bzoj 3242: [Noi2013]快餐店
Description 小T打算在城市C开设一家外送快餐店.送餐到某一个地点的时间与外卖店到该地点之间最短路径长度是成正比的,小T希望快餐店的地址选在离最远的顾客距离最近的地方. 快餐店的顾客分布在城 ...
- find + xargs + cp 遇到文件名中带空格如何处理
一,需求为查询文件名为ZRSH开头的时间为7月至今的所有文件并打包 1.首先想到的就是find + xargs + cp 格式.. find 2016073* -type f -name *ZRS ...
- Python并发实践_02_通过yield实现协程
python中实现并发的方式有很多种,通过多进程并发可以真正利用多核资源,而多线程并发则实现了进程内资源的共享,然而Python中由于GIL的存在,多线程是没有办法真正实现多核资源的. 对于计算密集型 ...
- js解析xml浏览器兼容性处理
/****************************************************************************** 说明:xml解析类 ********** ...
- 15个超强悍的CSS3圆盘时钟动画赏析
在网页上,特别是个人博客中经常会用到时钟插件,一款个性化的时钟插件不仅可以让页面显得美观,而且可以让访客看到当前的日期和时间.今天我们给大家收集了15个超强悍的圆盘时钟动画,很多都是基于CSS3,也有 ...
- leetcode — copy-list-with-random-pointer
import java.util.*; /** * * Source : https://oj.leetcode.com/problems/copy-list-with-random-pointer/ ...
- 基于web的网上书城系统开发-----登录注册
注册功能实现 signup.jsp //时间实现 function showLocale(objD) { var str,colorhead,colorfoot; var yy = objD.getY ...
- Yarn篇--搭建yran集群
一.前述 有了上次hadoop集群的搭建,搭建yarn就简单多了.废话不多说,直接来 二.规划 三.配置如下 yarn-site.xml配置 <property> <n ...
- css条纹背景
一. 水平条纹 1. 两种颜色: html <div class="stripe"></div> css .stripe{ width: 250px; he ...
- Macbook下安装管理MySQL
下载安装MySQL 1.访问MySQL官网:http://dev.mysql.com/downloads/ 2.下载 MySQL Community Server: 3.Select Platform ...