[大数据]-Elasticsearch5.3.1+Kibana5.3.1从单机到分布式的安装与使用<1>
一、Elasticsearch,Kibana简介:
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域, Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。 Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API 来隐藏Lucene的复杂性,从而让全文搜索变得简单。
Elasticsearch支持分布式的实时文件存储以及实时分析搜索,具有高度的可扩展性可扩展至上百台服务器,能够处理PB级的结构化和非结构化数据。
Elasticsearch同时也为各种语言调用提供了接口(Curl,JavaC#,Python,JavaScript PHP,Perl,Ruby),包括hadoop,spark都可以做对接。
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看、交互存放在Elasticsearch索引里的数据,使用各种不同的图表、表格、地图等kibana能够很轻易地展示高级数据分析与可视化。Kibana让我们理解大量数据变得很容易。它简单、基于浏览器的接口使你能快速创建和分享实时展现Elasticsearch查询变化的动态仪表盘。
二、Elasticsearch,Kibana的安装使用:
1、环境准备:
- 安装环境:centos6.5,Jdk1.8,Elasticsearch5.3.1,Kibana5.3.1
- 下载地址:https://www.elastic.co/cn/products可下载ES和Kibana。
- 安装虚拟机centos6.5。
- 安装JDK1.8:解压缩包-》配环境变量。
tar –zxvf jdk-8u121-linux-x64.tar.gz
mv jdk1..0_121 java
sudo vim /etc/profile
export JAVA_HOME=/home/rzxes/java
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
2、默认配置安装Elasticsearch5.3.1,Kibana5.3.1:
- EK安装非常简单,开箱即用,如果只是简单的使用,无需配置,解压两个压缩包之后可直接启动。(默认ES访问:localhost:9200,Kibana访问:localhost:5601,这种配置在虚拟机外无法通过IP访问)kibana启动之后会默认的去连接localhost:9200。
[rzxes@rzxes ~]$ ls
elasticsearch-5.3. kibana [rzxes@rzxes ~]$ elasticsearch-5.3./bin/elasticsearch //启动ES
[rzxes@rzxes ~]$ kibana/bin/kibana //启动kibana
3、编辑配置安装EK(单机单节点):
- 编辑ES配置文件: [rzxes@rzxes ~]$ vim elasticsearch-5.3./config/elasticsearch.yml 修改如下两个即可http.port可改。
network.host:本机IP #也有配置为 0.0.0.0 表示任何一个IP都可以访问到。这种方式在本机可以,但是外部访问的话可能会有问题。
http.port:- 编辑Kibana配置: [rzxes@rzxes ~]$ vim kibana/config/kibana.yml
server.port:
server.host: "本机IP"
elasticsearch.url: "http://本机IP:9200"- 启动EK:
[rzxes@rzxes ~]$ elasticsearch-5.3./bin/elasticsearch //启动ES
[rzxes@rzxes ~]$ kibana/bin/kibana //启动kibana- 访问端口: [rzxes@rzxes elasticsearch-5.3.]$ curl -XGET http://192.168.230.150:9200/ 结果如下则成功。
{
"name" : "node-1",
"cluster_name" : "es",
"cluster_uuid" : "bbCPwel7Tn-1cip2rsFWRQ",
"version" : {
"number" : "5.3.1",
"build_hash" : "5f9cf58",
"build_date" : "2017-04-17T15:52:53.846Z",
"build_snapshot" : false,
"lucene_version" : "6.4.2"
},
"tagline" : "You Know, for Search"
}
- 浏览器访问9200:http://192.168.230.150:9200可得到上一步同样结果。
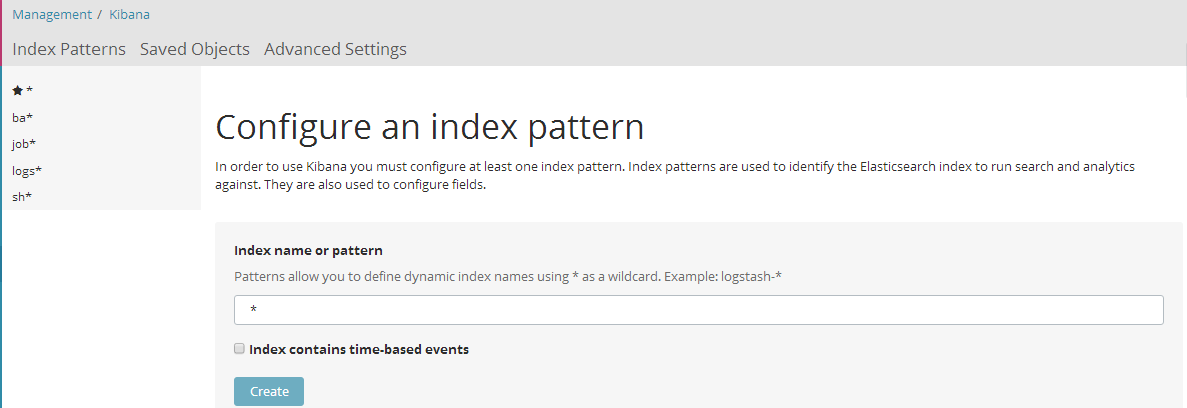
- 浏览器访问5601:http://192.168.230.150:5601.第一次Kibana会进入创建索引的界面,这里创建名为*的索引匹配数据(由于开始没有数据)。(取消掉所有打钩的地方)点击Create成功会显示在左侧。可以看到所有的功能组件。
4、Es-head插件的安装使用:
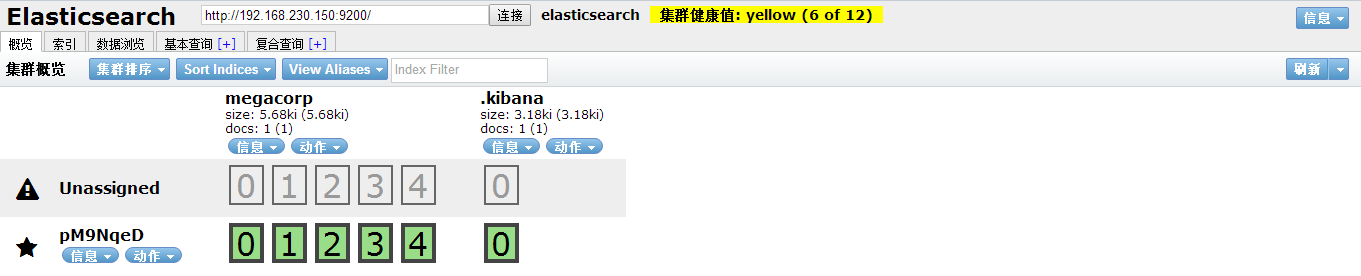
Es-head是一个界面化的集群操作和管理工具 ,可以和ES集成,也可以作为单独的一个app,通过界面可以清楚的看到集群的索引,分片,节点的分布,以及进行各种查询操作。
- 安装node.js:下载编译好的包,解压,配置环境变量
sudo vim /etc/profile
#末尾node添加环境变量
#node bin
export PATH=/home/rzxes/node/bin:$PATH- 保存退出,使其立即生效: source /etc/profile
在node包的bin目录下有两个脚本:node和npm,查看是否配置成功: npm -version , node -v 显示版本号则成功
- 进入ES安装目录,获取ES-head安装包: git clone git://github.com/mobz/elasticsearch-head.git
配置Es-head:
- 编辑Gruntfile.js: [rzxes@rzxes elasticsearch-head]$ vim Gruntfile.js
- 修改监听hostname为:*
connect: {
server: {
options: {
port: 9100,
hostname: '*',
base: '.',
keepalive: true
}
}
}- 修改head的连接地址localhost换为本机IP: [rzxes@rzxes elasticsearch-head]$ vim _site/app.js
- 找到init function(options){ this._super(); }: this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://IP:9200"; localhost换成ip####不过我这里原本并没有这一行,是自己直接添加上的,后面再搭建集群的时候把这一句注释掉了也并没有出现问题。
- 进入Es-head目录:执行以下命令:[grunt是一个很方便的构建工具,可以进行打包压缩、测试、执行等等的工作,5.x里的head插件就是通过grunt启动的。因此需要安装一下grunt]
npm install grunt
npm install -g grunt-cli
npm install每一步执行成功进行下一步,[可能存在以下资源配置不了,是由于网络问题(可以连VPN,或者用天猫镜像)]若出现以下问题:
error: Failed at the phantomjs-prebuilt@2.1. install script ‘node install.js’
解决方法: npm install phantomjs-prebuilt@2.1. --ignore-scripts
若以上nmp install 成功,则直接用 grunt server 启动服务(es要先启动),如下则成功:
[rzxes@rzxes elasticsearch-head]$ grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100访问:http://ip:9100/ 可以看到如下节点则说明成功。
- 到此单机版EK安装完毕。
三、Elasticsearch,Kibana安装中的异常解决:
1、[ WARN]:seccomp unavailable:requires kernel 3.5+ with CONFIG_SECCOMP and CONFIG_SECCOMP_FILTER compiled in。
- 警告内核版本太低!,忽略警告。
2、[ERROR]:max number of threads [1024] for user [rzxes] is too low, increase to at least [2048]。
- sudo vim /etc/security/limits.d/-nproc.conf 把1024改成2048。
3、[ERROR]:max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]。
- Sudo vim /etc/security/limits.conf ,末尾添加如下两行:
- * hard nofile
- * soft nofile
- 查看: ulimit -Hn 结果是65536则修改成功。
4、[ERROR]:system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk。
vim config/elasticsearch.yml 添加如下:
- bootstrap.system_call_filter: false
5、[ERROR]:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]。
- 修改/etc/sysctl.conf sudo vim /etc/sysctl.conf ,最后添加: vm.max_map_count= 。
- 使用 sysctl -p 查看修改后的结果。
四、Elasticsearch,Kibana分布式安装:
ES的分布式和Kibana没什么关系哦,分布式数据分散在各个节点以分片和副本保证安全容灾,Kibana并不参与,仍旧只是做可视化。ES的分布式搭建也非常简单,没有什么复杂的配置,我们只需要将以上单机部署的虚拟机进行克隆分别命名为rzxesn2,rzxesn3。然后稍加配置即可。
1、基本环境配置:
- 虚拟机rzxes克隆(完全克隆)出rzxesn2,rzxesn3,并打开虚拟机。
- 修改hostname:因为克隆后用户名密码hostname完全相同,但是IP不同,所以需要修改hostname将其区分开。修改后如下:
hostname IP user pass
--------------------------------------------
rzxes 192.168.230.150 rzxes
rzxesn2 192.168.230.151 rzxes
rzxesn3 192.168.230.152 rzxes- 修改配置文件:主要是三点:集群名相同,端口号不同,节点名不同。配置如下:红色标记为不同之处。
- rzxes配置: [rzxes@rzxes elasticsearch-5.3.]$ vim config/elasticsearch.yml 详细如下:
#集群名必须统一,否则是不能组成集群的
cluster.name: es
#节点名需不同
node.name: node-1
# IP换成各自本机IP,三个端口号需要修改成不同
network.host: 192.168.230.150
http.port:
#主机请求列表[集群节点自动发现和Master选举的配置],
discovery.zen.ping.unicast.hosts: ["192.168.230.150", "192.168.230.151", "192.168.230.152"]
#这两个路径可以不配,默认es根路径下的data,logs,但是如果单机运行了就需要删除生成的这两个文件夹,否侧会出错,因为启动生成instance的信息会保存,修改配置后再启动出现instance ID不匹配就不能够够形成集群。
path.data: /path/to/data
path.logs: /path/to/logs
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
#配置跨域请求允许
http.cors.enabled : true
http.cors.allow-origin: "*"- rzxesn2配置: [rzxes@rzxesn2 elasticsearch-5.3.1]$ vim config/elasticsearch.yml 详细如下:
cluster.name: es
#节点名需不同
node.name: node-
# IP换成各自本机IP,三个端口号需要修改成不同
network.host: 192.168.230.151
http.port:
discovery.zen.ping.unicast.hosts: ["192.168.230.150", "192.168.230.151", "192.168.230.152"]
path.data: /path/to/data
path.logs: /path/to/logs
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled : true
http.cors.allow-origin: "*"- rzxesn3配置: [rzxes@rzxesn3 elasticsearch-5.3.1]$ vim config/elasticsearch.yml 详细如下:
cluster.name: es
#节点名需不同
node.name: node-3
# IP换成各自本机IP,三个端口号需要修改成不同
network.host: 192.168.230.152
http.port:
discovery.zen.ping.unicast.hosts: ["192.168.230.150", "192.168.230.151", "192.168.230.152"]
path.data: /path/to/data
path.logs: /path/to/logs
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled : true
http.cors.allow-origin: "*"
2、分布式启动:
- 分别启动三个ES: bin/elasticsearch 。正常起动会共同推举一个节点做Master。详情如下:
- node-1最先启动,当node-2启动,node-1 added (node-2)到集群,

- node-2推举master为node-1

- node-3推举master为node-1

- 启动es-head,查看集群状况: [rzxes@rzxes elasticsearch-head]$ grunt server 结果如下:(如下是再导入数据之后,后面会详细写)
- 访问9100端口:http://192.168.230.150:9100/
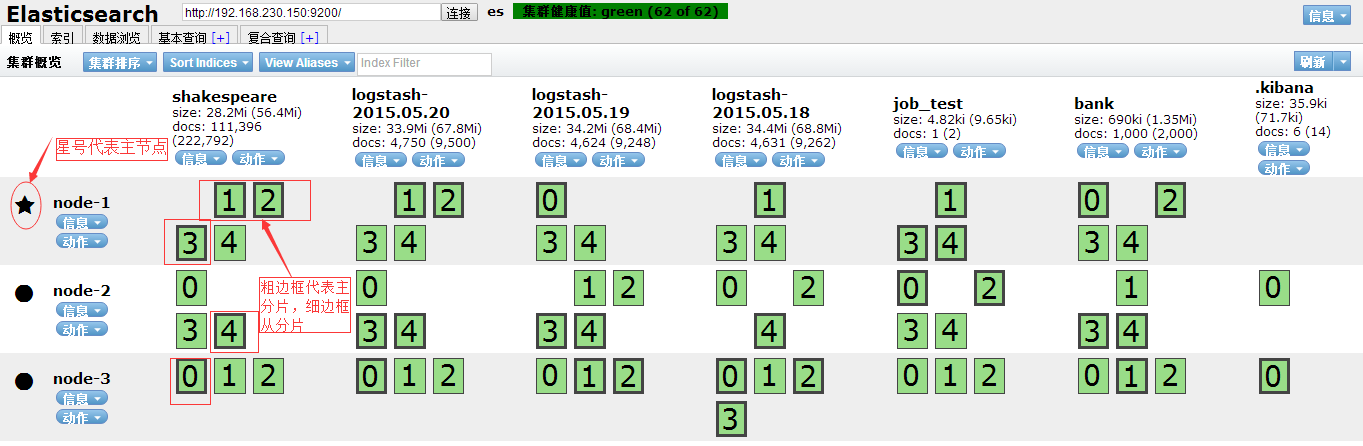
- 如此,分布式就搭建完成了,这里默认的是5个分片(0,1,2,3,4)一个副本。
3、分布式搭建可能遇到的问题:
- [ERROR]:with the same id but is a different node instance
解决:删除data,logs目录(所有节点都要删除)重新启动。(这也是我在前面配置文件中提到的Cluster ID不同造成的问题)
注意:
1、所有复制粘贴的空格重新敲一遍,配置的冒号“:”后面必须跟空格,一旦提示找不到":"则说明是空格有问题。
2、Es不能以root启动,需要创建自己的用户:[因为我是直接在用户目录下操作的,不存在这种问题,所以放在后面写给用root角色启动的用户]
# 创建用户名为 rzxes的用户
useradd rzxes -p
# 设置 rzxes 用户的密码
passwd 123456
# 将es目录的拥有者设置为 es
chown -R rzxes:rzxes /home/rzxes/elasticsearch-5.3.1
下篇:[大数据]-Elasticsearch5.3.1+Kibana5.3.1从单机到分布式的安装与使用<2>
[大数据]-Elasticsearch5.3.1+Kibana5.3.1从单机到分布式的安装与使用<1>的更多相关文章
- [大数据]-Elasticsearch5.3.1+Kibana5.3.1从单机到分布式的安装与使用<2>
前言:上篇[大数据]-Elasticsearch5.3.1+Kibana5.3.1从单机到分布式的安装与使用<1>中介绍了ES ,Kibana的单机到分布式的安装,这里主要是介绍Elast ...
- [大数据]-Elasticsearch5.3.1 IK分词,同义词/联想搜索设置
--题外话:最近发现了一些问题,一些高搜索量的东西相当一部分没有价值.发现大部分是一些问题的错误日志.而我是个比较爱贴图的.搜索引擎的检索会将我们的博文文本分词.所以图片内容一般是检索不到的,也就是说 ...
- 大数据学习系列之二 ----- HBase环境搭建(单机)
引言 在上一篇中搭建了Hadoop的单机环境,这一篇则搭建HBase的单机环境 环境准备 1,服务器选择 阿里云服务器:入门型(按量付费) 操作系统:linux CentOS 6.8 Cpu:1核 内 ...
- [大数据]-Logstash-5.3.1的安装导入数据到Elasticsearch5.3.1并配置同义词过滤
阅读此文请先阅读上文:[大数据]-Elasticsearch5.3.1 IK分词,同义词/联想搜索设置,前面介绍了ES,Kibana5.3.1的安装配置,以及IK分词的安装和同义词设置,这里主要记录L ...
- HP PCS 云监控大数据解决方案
——把数据从分散统一集中到数据中心 基于HP分布式并行计算/存储技术构建的云监控系统即是通过“云高清摄像机”及IaaS和PaaS监控系统平台,根据用户所需(SaaS)将多路监控数据流传送给“云端”,除 ...
- 王家林的81门一站式云计算分布式大数据&移动互联网解决方案课程第14门课程:Android软硬整合设计与框架揭秘: HAL&Framework &Native Service &App&HTML5架构设计与实战开发
掌握Android从底层开发到框架整合技术到上层App开发及HTML5的全部技术: 一次彻底的Android架构.思想和实战技术的洗礼: 彻底掌握Andorid HAL.Android Runtime ...
- 王家林 Spark公开课大讲坛第一期:Spark把云计算大数据速度提高100倍以上
王家林 Spark公开课大讲坛第一期:Spark把云计算大数据速度提高100倍以上 http://edu.51cto.com/lesson/id-30815.html Spark实战高手之路 系列书籍 ...
- 一站式Hadoop&Spark云计算分布式大数据和Android&HTML5移动互联网解决方案课程(Hadoop、Spark、Android、HTML5)V2的第一门课程
Hadoop是云计算的事实标准软件框架,是云计算理念.机制和商业化的具体实现,是整个云计算技术学习中公认的核心和最具有价值内容. 如何从企业级开发实战的角度开始,在实际企业级动手操作中深入浅出并循序渐 ...
- 大数据时代的杀手锏----Tachyon
一.Tachyon系统的简介 Tachyon是一个分布式内存文件系统,可以在集群里以访问内存的速度来访问存在tachyon里的文件.把 Tachyon是架构在最底层的分布式文件存储和上层的各种计算框架 ...
随机推荐
- (转)Linux core 文件介绍与处理
1. core文件的简单介绍 在一个程序崩溃时,它一般会在指定目录下生成一个core文件.core文件仅仅是一个内存映象(同时加上调试信息),主要是用来调试的. 2. 开启或关闭core文件的生成用以 ...
- CentOS7 更换yum源
yum源调整为163wget http://mirrors.163.com/.help/CentOS7-Base-163.repo[root@admin yum.repos.d]# mv CentOS ...
- KMP算法C语言实现。弄了好久才搞好。。。
我的这个算法中数组的第一位没有像教材中那样用来存数组的大小,所以会有些许的不同. ...
- Java基础—JDK环境变量配置
1.安装JDK 下载网址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 注意点 ...
- JPlayer Jquery video视频插件
近日一直在搜关于视频的jquery插件,要求功能全,跨平台,百思不得其解,偶尔找到一个插件JPlayer,国产的,很全.为什么选择JPlayer 简单:几分钟就可以上手编码.部署 可定制:可以方便地用 ...
- 【Egret】里使用iframe标签达到内嵌多个web界面
目的:Egret里使用iframe标签达到内嵌多个web界面,模式相当于主swf调用N个子swf的效果: 目前在做项目过程中,在使用iframe的时候,碰到了一些功能需求,以及解决方法如下: 一..在 ...
- 【Egret】里使用audio标签达到默认播放背景音乐
方法一 <audio id="bgmMusic" style="position:absolute;" src="resource/assets ...
- 原生js实现tab切换
//通过原生js实现table切换<html><head><meta http-equiv="Content-Type" content=" ...
- 简单分析下用yii2的yii\helpers\Html类和yii.js实现的post请求
yii2提供了很多帮助类,比如Html.Url.Json等,可以很方便的实现一些功能,下面简单说下这个Html.用yii2写view时时经常会用到它,今天在改写一个页面时又用到了它.它比较好用的地方就 ...
- 如何掌握并提高linux运维技能
初中级Linux运维人员们系统学习并迅速掌握Linux的运维实战技能.学习路线大纲如下: 入门基础篇 系统运维篇 Web运维篇 数据库运维篇 集群实战篇 运维监控篇 第一篇:Linux入门(安装.配置 ...