利用OpenCV检测图像中的长方形画布或纸张并提取图像内容

纸张四角的坐标(图中红点)已知的情况

右上:295.6, 118.4
右下:172.4, 311.3
左下:2.4, 202.4
右上:300, 0
右下:300, 400
左下:0, 400
M = cv2.getPerspectiveTransform(corners, canvas)
result = cv2.warpPerspective(image, M, (0, 0))

纸张四角的坐标未知或难以准确标注的情况


image = cv2.pyrMeanShiftFiltering(image, 25, 10)
因为主要目的是预处理降噪,windows size和color distance都不用太大,避免浪费计算时间还有过度降噪。降噪后可以看到桌面上的纹理都被抹去了,纸张边缘附近干净了很多。然而这还远远不够,图案本身,和图像里的其他物体都有很多明显的边缘,而且都是直线边缘。
2) 纸张边缘检测






3) 直线检测


4) 判断纸张边缘
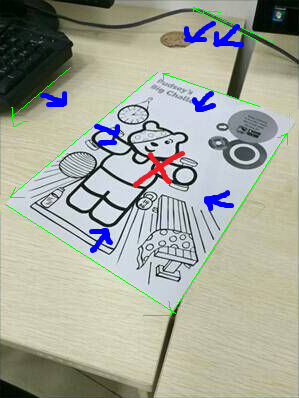

正是要的结果。
5) 计算四角的坐标
接下来计算四条线的交点,方法点这里。因为有4条线,会得到6个结果,因为在这种应用场景中,方形的物体在透视变换下不会出现凹角,所以直接舍弃离纸张中心最远的两个交点就得到了四个角的坐标,结果如下:
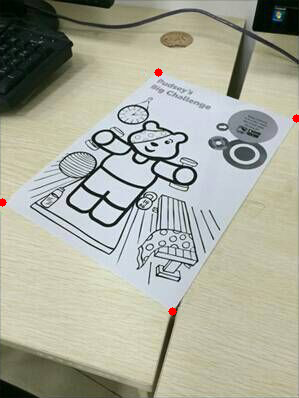
这样就回到了一开始四角坐标已经得到的情况,直接进行透视变换就行了。
Camera Calibration?
写了这么多,其实有一条至关重要的假设,甚至可以说是最关键的步骤之一我一直没提,那就是Camera Calibration,如果有相机的情况下,meta data都知道,那么需要先坐Camera Calibration才能知道纸张或者画布的原始尺寸。我这里试的例子当然是没有的,也可以有,相应的算法OpenCV里也有现成的,但准确度未必够,而且还是非常麻烦,所以我的所有流程都是默认原始尺寸已经获得了。再说了,就算没有,变换回方形之后使用者凭感觉进行简单轴缩放都比Camera Calibration方便得多。。
印象派
我用的例子算是略微有些极端的,因为背景和图案非常接近,另一方面分辨率还巨低。在网上搜搜,我找了幅少年画家的印象派作品来试试:
原图

手动标注

GrabCut

检测到的边缘

结果

看上去还不错~
利用OpenCV检测图像中的长方形画布或纸张并提取图像内容的更多相关文章
- matlab在图像中画长方形(框)
function [state,result]=draw_rect(data,pointAll,windSize,showOrNot) % 函数调用:[state,result]=draw_rect( ...
- 在图像中隐藏数据:用 Python 来实现图像隐写术
什么是“隐写术”? 隐写术是将机密信息隐藏在更大的信息中,使别人无法知道隐藏信息的存在以及隐藏信息内容的过程.隐写术的目的是保证双方之间的机密交流.与隐藏机密信息内容的密码学不同,隐写术隐瞒了传达消息 ...
- 利用OpenCV检测手掌(palm)和拳头(fist)
思路:利用训练好的palm.xml和fist.xml文件,用OpenCV的CascadeClassifier对每一帧图像检测palm和fist,之后对多帧中检测到的palm和fist进行聚类分组,满足 ...
- 图像中的掩膜(Mask)是什么
在图像处理中,经常会碰到掩膜(Mask)这个词.那么这个词到底是什么意思呢?下面来简单解释一下. 1.什么是掩膜 首先我们从物理的角度来看看mask到底是什么过程. 在半导体制造中,许多芯片工艺步骤采 ...
- 从单一图像中提取文档图像:ICCV2019论文解读
从单一图像中提取文档图像:ICCV2019论文解读 DewarpNet: Single-Image Document Unwarping With Stacked 3D and 2D Regressi ...
- python+opencv选出视频中一帧再利用鼠标回调实现图像上画矩形框
最近因为要实现模板匹配,需要在视频中选中一个目标,然后框出(即作为模板),对其利用模板匹配的方法进行检测.于是需要首先选出视频中的一帧,但是在利用摄像头读视频的过程中我唯一能想到的方法就是: 1.在视 ...
- (转)使用Python和OpenCV检测图像中的物体并将物体裁剪下来
原文链接:https://blog.csdn.net/liqiancao/article/details/55670749 介绍 硕士阶段的毕设是关于昆虫图像分类的,代码写到一半,上周五导师又给我新的 ...
- 访问图像中的像素[OpenCV 笔记16]
再更一发好久没更过的OpenCV,不过其实写到这个部分对计算机视觉算法有所了解的应该可以做到用什么查什么了,所以后面可能会更的慢一点吧,既然开了新坑,还是机器学习更有研究价值吧... 图像在内存中的存 ...
- 利用OpenCV给图像添加中文标注
利用OpenCV给图像添加中文标注 : 参考:http://blog.sina.com.cn/s/blog_6bbd2dd101012dbh.html 和https://blog.csdn.net/ ...
随机推荐
- 回文串---Best Reward
HDU 3613 Description After an uphill battle, General Li won a great victory. Now the head of state ...
- Docker on CentOS for beginners
Introduction The article will introduce Docker on CentOS. Key concepts Docker Docker is the world's ...
- 机器学习实战 - 读书笔记(14) - 利用SVD简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第14章 - 利用SVD简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. 基 ...
- FAQ_1_陌生的VERSION.SDK_INT
看到VERSION.SDK_INT不禁诧异,这是何物?! 看API的定义,如下: 原来是一个常量值.但是这个常量值可以根据系统的不同而不同哟!为了揭开其神秘的面纱,将源码ctrl如下: 可以看出,获取 ...
- CSS3中的box-shadow
语法: box-shadow: h-shadow v-shadow blur spread color inset; box-shadow 向框添加一个或多个阴影.该属性是由逗号分隔的阴影列表,每个阴 ...
- SharePoint 使用代码为页面添加WebPart
传统的SharePoint实施中,我们通常会创建SharePoint页面,然后添加webpartzone,而后在上面添加webpart:但是有些情况下,也要求我们使用代码,将webpart添加到相应w ...
- Device Channels in SharePoint 2013
[FROM:http://blog.mastykarz.nl/device-channels-sharepoint-2013/] One of the new features of SharePoi ...
- android XMl 解析神奇xstream 一: 解析android项目中 asset 文件夹 下的 aa.xml 文件
简介 XStream 是一个开源项目,一套简单实用的类库,用于序列化对象与 XML 对象之间的相互转换. 将 XML 文件内容解析为一个对象或将一个对象序列化为 XML 文件. 1.下载工具 xstr ...
- Objective-C中@encode的使用
今天看Mansonry的代码时,碰到一个生僻的关键字(也许只是自己没用过).:-) @encode => 将给定类型编码为内部表示的字符串. 为了方便自己查阅,顺便也写个小例子,贴在这里,实践 ...
- 【转】IOS高级教程1:处理1000张图片的内存优化
转载请保留以下原文链接: http://my.oschina.net/taptale/blog/91894 一.项目需求 在实际项目中,用户在上传图片时,有时会一次性上传大量的图片.在上传图片前,我们 ...