linux或者windows下的文件拷贝

# 上代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import os
import shutil
import tarfile base_dir = os.path.abspath(os.path.dirname(__file__))
print(base_dir)
# 文件拷贝
def CopyFiles(source_dir, target_dir):
for file in os.listdir(source_dir):
source_file = os.path.join(source_dir, file)
target_file = os.path.join(target_dir,file)
if os.path.isfile(source_file):
if not os.path.exists(target_dir):
os.mkdir(target_dir)
if not os.path.exists(target_file) or (os.path.exists(target_file) and (os.path.getsize(target_file) != os.path.getsize(source_file))):
#读文件 写文件的 方式可能会由于编码问题导致错误 这里选择文件拷贝的方式
#open(target_file,'wb').write(open(source_file,'rb').read())
shutil.copy2(source_file, target_dir) if os.path.isdir(source_file):
First_Directory = False
CopyFiles(source_file,target_file)
# 文件打包
def make_targz(output_filename, source_dir):
with tarfile.open(output_filename, 'w:gz') as tar:
tar.add(source_dir,arcname=os.path.basename(source_dir) ) if __name__ == '__main__':
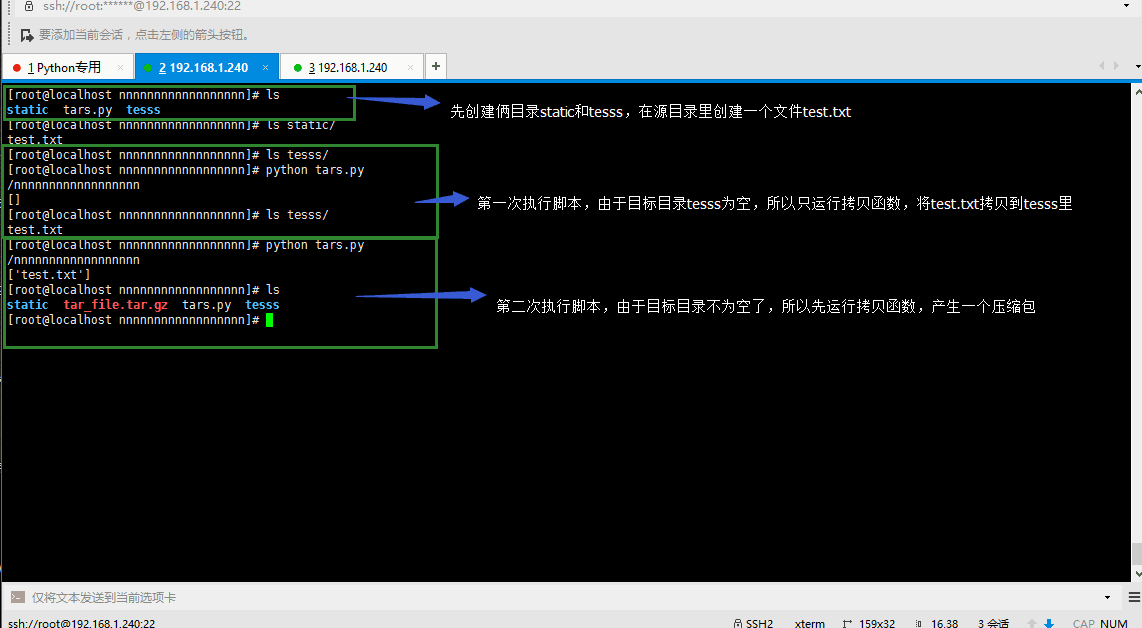
source_dir = os.path.join(base_dir,'static')
target_dir = os.path.join(base_dir,'tesss')
# 判断目标文件是否为空
# 目标文件为空直接 拷贝
print os.listdir(target_dir) #这里最好先判断目标目录是否存在,如果不存在就会报错,如果不加判断语句的话,就在当前目录里先创建好static和tesss这两个目录
if len(os.listdir(target_dir)) == 0:
CopyFiles(source_dir,target_dir)
else:
# 目标文件不为空 先打包 再删除 然后在拷贝
#打包
make_targz('tar_file.tar.gz',target_dir) #为了容易识别,这里给压缩包加上格式'.tar.gz'
shutil.rmtree(target_dir)
os.mkdir(target_dir)
CopyFiles(source_dir,target_dir)

文件打包
1、zip
import os, zipfile #打包目录为zip文件(未压缩)
def make_zip(source_dir, output_filename):
zipf = zipfile.ZipFile(output_filename, 'w')
pre_len = len(os.path.dirname(source_dir))
for parent, dirnames, filenames in os.walk(source_dir):
for filename in filenames:
pathfile = os.path.join(parent, filename)
arcname = pathfile[pre_len:].strip(os.path.sep) #相对路径
zipf.write(pathfile, arcname)
zipf.close()
2、tar/tar.gz
import os, tarfile #一次性打包整个根目录。空子目录会被打包。
#如果只打包不压缩,将"w:gz"参数改为"w:"或"w"即可。
def make_targz(output_filename, source_dir):
with tarfile.open(output_filename, "w:gz") as tar:
tar.add(source_dir, arcname=os.path.basename(source_dir)) #逐个添加文件打包,未打包空子目录。可过滤文件。
#如果只打包不压缩,将"w:gz"参数改为"w:"或"w"即可。
def make_targz_one_by_one(output_filename, source_dir):
tar = tarfile.open(output_filename,"w:gz")
for root,dir,files in os.walk(source_dir):
for file in files:
pathfile = os.path.join(root, file)
tar.add(pathfile)
tar.close()
文件拷贝 网上不错的例子:
import os
import shutil
yuanD = "F:\scripts\monitor"
mubiaoD = "F:\scripts\CheungSSH\web"
#递归复制文件夹内的文件
def copyFiles(sourceDir,targetDir):
#忽略某些特定的子文件夹
if sourceDir.find("exceptionfolder")>0:
return
#列出源目录文件和文件夹
for file in os.listdir(sourceDir):
#拼接完整路径
sourceFile = os.path.join(sourceDir,file)
targetFile = os.path.join(targetDir,file)
#如果是文件则处理
if os.path.isfile(sourceFile):
#如果目的路径不存在该文件就创建空文件,并保持目录层级结构
if not os.path.exists(targetDir):
os.makedirs(targetDir)
#如果目的路径里面不存在某个文件或者存在那个同名文件但是文件有残缺,则复制,否则跳过
if not os.path.exists(targetFile) or (os.path.exists(targetFile) and (os.path.getsize(targetFile) != os.path.getsize(sourceFile))):
open(targetFile, "wb").write(open(sourceFile, "rb").read())
print targetFile+" copy succeeded"
#如果是文件夹则递归
if os.path.isdir(sourceFile):
copyFiles(sourceFile, targetFile)
#遍历某个目录及其子目录下所有文件拷贝到某个目录中
def copyFiles2(srcPath,dstPath):
if not os.path.exists(srcPath):
print "src path not exist!"
if not os.path.exists(dstPath):
os.makedirs(dstPath)
#递归遍历文件夹下的文件,用os.walk函数返回一个三元组
for root,dirs,files in os.walk(srcPath):
for eachfile in files:
shutil.copy(os.path.join(root,eachfile),dstPath)
print eachfile+" copy succeeded" #删除某目录下特定文件
def removeFileInDir(sourceDir):
for file in os.listdir(sourceDir):
file=os.path.join(sourceDir,file) #必须拼接完整文件名
if os.path.isfile(file) and file.find(".jpg")>0:
os.remove(file)
print file+" remove succeeded"
if __name__ =="__main__":
copyFiles(yuanD,mubiaoD)
#removeFileInDir("./dir2")
#copyFiles2("./dir1","./dir2")
linux或者windows下的文件拷贝的更多相关文章
- Tomcat日志文件的输出在Linux和Windows下的差异
前言 最近老大发现Tomcat的日志文件catalina.out里存在着大量的和公司项目相关的log信息,因为一般都是会使用日志框架并另外将log信息输出到另外的文件里的,catalina.out文件 ...
- 将Windows下的文件同步到Linux下
需求:把Windows下的某些文件自动传送到Linux指定目录下 实现: 1. Windows下安装 WinSCP工具,并把Liunx服务器信息保存 2. 编写脚本,实现双击工具就把Windows下的 ...
- 【转】linux和windows下安装python集成开发环境及其python包
本系列分为两篇: 1.[转]windows和linux中搭建python集成开发环境IDE 2.[转]linux和windows下安装python集成开发环境及其python包 3.windows和l ...
- 关于Windows下的文件后缀名问题
一.背景说明 有很多的小伙伴对windows下的文件后缀名不能很好地理解作用和区别,更不用说高深的使用了,在这里给大家说一下这些文件后缀名到底有什么区别,有什么作用呢? 二.说明 简单的说来,wind ...
- Linux和Windows之间传递文件
由于自己的计算机的性能不足,代码只能在服务器上运行,要把代码搬到服务器上运行在没有root权限的情况下,本身就是一件不太容易的事情,我准备下次再写一下这方面的技巧.这篇博客,我只说比较一下几种在不同操 ...
- tar.xz如何解压:linux和windows下tar.xz解压命令介绍
在linux下怎么解压和压缩tar.xz文件? (本文由www.169it.com搜集整理) 在linux下解压tar.xz文件步骤 1 2 # xz -d ***.tar.xz //先解压xz # ...
- 在本机eclipse中创建maven项目,查看linux中hadoop下的文件、在本机搭建hadoop环境
注意 第一次建立maven项目时需要在联网情况下,因为他会自动下载一些东西,不然突然终止 需要手动删除断网前建立的文件 在eclipse里新建maven项目步骤 直接新建maven项目出了错 ...
- linux和windows互传文件/用户配置文件和密码配置文件/用户组管理/用户管理
2.27linux和windows互传文件 3.1 用户配置文件和密码配置文件 3.2 用户组管理 3.3 用户管理 linux和windows互传文件 显示日期date [root@centos_1 ...
- Find命令、文件名后缀、Linux和Windows互传文件 使用介绍
第2周第5次课(3月30日) 课程内容: 2.23/2.24/2.25 find命令2.26 文件名后缀 2.27 Linux和Windows互传文件 find命令 文件查找: 1.which(一般用 ...
随机推荐
- 清华申请退学博士作品:完全用Linux工作
http://www.cnblogs.com/cbscan/articles/3252872.html 下文地址 http://blog.oldboyedu.com/use-linux/ 按: 尽管我 ...
- MyEclipse Spring 学习总结二 Bean的生命周期
文件结构可以参考上一节 Bean的生命周期有方法有:init-method,destroy-method ApplicationContext.xml 文件配置如下: <?xml version ...
- for xml path(''),root('')
,,'') SELECT top 10 ROW_NUMBER()OVER(ORDER BY OperationID) as 'Message/MessageId', OperationID as 'I ...
- 动态加载、移除、替换JS和CSS
//动态加载一个js/css文件 function loadjscssfile(filename, filetype) { if (filetype == "js") { var ...
- 千里积于跬步——流,向量场,和微分方程[转载]
在很多不同的科学领域里面,对于运动或者变化的描述和建模,都具有非常根本性的地位--我个人认为,在计算机视觉里面,这也是非常重要的. 什么是"流"? 在我接触过的各种数学体系中,对于 ...
- java事件监听
获取事件监听需要获取实现ActionListener接口的方法, public class SimpleEvent extends JFrame{ private JButton jb=new ...
- UNIX网络编程-基本API介绍(二)
参考链接:http://www.cnblogs.com/riky/archive/2006/11/24/570713.aspx 1.getsockname和getpeername getsocknam ...
- C++引用与指针
在做函数参数时, 引用不可以设置默认值, 指针可以 void fun(const string& url, string* domain = NULL); 另const放在函数后面, 表示这 ...
- 初识UML
最近的学习中,遇到几次UML图,很是迷糊,确切的说,看不太懂.查阅UML相关资料,基本解决了这个问题.UML看起来还是相当深奥,这里只提一下解决问题的部分知识.(以下知识来自网络) Unified M ...
- DOCTYPE 中xhtml 1.0和 html 4.01区别分析
前者相对于后者有以下特性: 1.所有的标记都都要闭合 所有的标记都要闭合,如果是单独不成对的标签,在标签最后加一个"/"来关闭它.例如: <h6>close tag & ...