Hadoop工程包架构解析
Hadoop源码解析 1 --- Hadoop工程包架构解析
1 Hadoop中各工程包依赖简述
Google的核心竞争技术是它的计算平台。Google的大牛们用了下面5篇文章,介绍了它们的计算设施。
GoogleCluster: http://research.google.com/archive/googlecluster.html
Chubby:http://labs.google.com/papers/chubby.html
GFS:http://labs.google.com/papers/gfs.html
BigTable:http://labs.google.com/papers/bigtable.html
MapReduce:http://labs.google.com/papers/mapreduce.html
很快,Apache上就出现了一个类似的解决方案,目前它们都属于Apache的Hadoop项目,对应的分别是:
Chubby-->ZooKeeper
GFS-->HDFS
BigTable-->HBase
MapReduce-->Hadoop
目前,基于类似思想的Open Source项目还很多,如Facebook用于用户分析的Hive。
HDFS作为一个分布式文件系统,是所有这些项目的基础。分析好HDFS,有利于了解其他系统。由于Hadoop的HDFS和MapReduce是同一个项目,我们就把他们放在一块,进行分析。
Hadoop包之间的依赖关系比较复杂,原因是HDFS提供了一个分布式文件系统,
该系统提供API,可以屏蔽本地文件系统和分布式文件系统,甚至象Amazon S3这样的在线存储系统。这就造成了分布式文件系统的实现,或者是分布式
文件系统的底层的实现,依赖于某些貌似高层的功能。功能的相互引用,造成了蜘蛛网型的依赖关系。一个典型的例子就是包conf,conf用于读取系统配
置,它依赖于fs,主要是读取配置文件的时候,需要使用文件系统,而部分的文件系统的功能,在包fs中被抽象了。
2 Hadoop和Google分布式系统对应产品

3 Hadoop工程中各工程包依赖图示
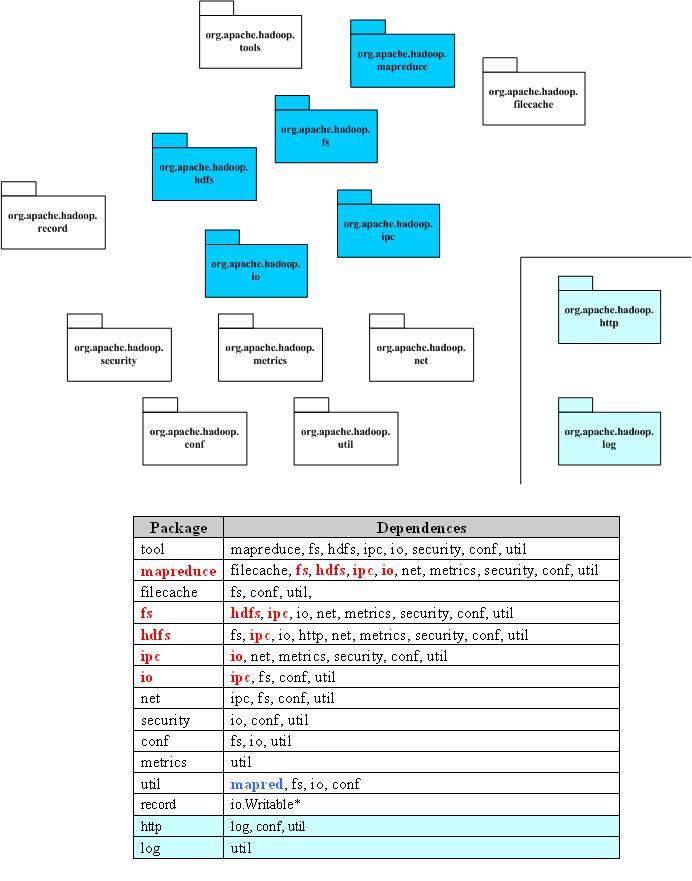
4 Hdoop工程中各工程包文件夹图示

5 各包功能
|
Package |
Dependences |
|
tool |
提供一些命令行工具,如DistCp,archive |
|
mapreduce |
Hadoop的Map/Reduce实现 |
|
filecache |
提供HDFS文件的本地缓存,用于加快Map/Reduce的数据访问速度 |
|
fs |
文件系统的抽象,可以理解为支持多种文件系统实现的统一文件访问接口 |
|
hdfs |
HDFS,Hadoop的分布式文件系统实现 |
|
ipc |
一个简单的IPC的实现,依赖于io提供的编解码功能 参考:http://zhangyu8374.iteye.com/blog/86306 |
|
io |
表示层。将各种数据编码/解码,方便于在网络上传输 |
|
net |
封装部分网络功能,如DNS,socket |
|
security |
用户和用户组信息 |
|
conf |
系统的配置参数 |
|
metrics |
系统统计数据的收集,属于网管范畴 |
|
util |
工具类 |
|
record |
根据DDL(数据描述语言)自动生成他们的编解码函数,目前可以提供C++和Java |
|
http |
基于Jetty的HTTP Servlet,用户通过浏览器可以观察文件系统的一些状态信息和日志 |
|
log |
提供HTTP访问日志的HTTP Servlet |
原创文章欢迎转载,转载时请注明出处。
作者推荐文章:
》如何获取系统信息(包括操作系统、jvm、cpu、内存、硬盘、网络等)
Hadoop工程包架构解析的更多相关文章
- Hadoop源码解析 1 --- Hadoop工程包架构解析
1 Hadoop中各工程包依赖简述 Google的核心竞争技术是它的计算平台.Google的大牛们用了下面5篇文章,介绍了它们的计算设施. GoogleCluster: http:// ...
- IM通信协议逆向分析、Wireshark自定义数据包格式解析插件编程学习
相关学习资料 http://hi.baidu.com/hucyuansheng/item/bf2bfddefd1ee70ad68ed04d http://en.wikipedia.org/wiki/I ...
- Netty原理架构解析
Netty原理架构解析 转载自:http://www.sohu.com/a/272879207_463994本文转载关于Netty的原理架构解析,方便之后巩固复习 Netty是一个异步事件驱动的网络应 ...
- 【Netty】最透彻的Netty原理架构解析
这可能是目前最透彻的Netty原理架构解析 本文基于 Netty 4.1 展开介绍相关理论模型,使用场景,基本组件.整体架构,知其然且知其所以然,希望给大家在实际开发实践.学习开源项目方面提供参考. ...
- HDFS 架构解析
本文以 Hadoop 提供的分布式文件系统(HDFS)为例来进一步展开解析分布式存储服务架构设计的要点. 架构目标 任何一种软件框架或服务都是为了解决特定问题而产生的.还记得我们在 <分布式存储 ...
- 从零自学Hadoop(09):使用Maven构建Hadoop工程
阅读目录 序 Maven 安装 构建 示例下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,Source ...
- OpenStack最新版本Folsom架构解析
OpenStack最新版本Folsom架构解析摘要:OpenStack的第6版,版本代号为Folsom的最新版于今年九月底正式发布,Folsom将支持下一代软件定义网络(SDN)作为其核心组成部分.F ...
- 后端分布式系列:分布式存储-HDFS 架构解析
本文以 Hadoop 提供的分布式文件系统(HDFS)为例来进一步展开解析分布式存储服务架构设计的要点. 架构目标 任何一种软件框架或服务都是为了解决特定问题而产生的.还记得我们在 <分布式存储 ...
- PrismCDN 网络的架构解析,以及低延迟、低成本的奥秘
5 月 19.20 日,行业精英齐聚的 WebRTCon 2018 在上海举办.又拍云 PrismCDN 项目负责人凌建发在大会做了<又拍云低延时的 WebP2P 直播实践>的精彩分享. ...
随机推荐
- Greedy:Cleaning Shifts(POJ 2376)
牛的大扫除 题目大意:农夫有N只牛,这些牛要帮助打扫农舍,这些牛只能打扫固定位置(千万要注意这个位置不是连续的),每一段区间必须至少有一只牛打扫,问你至少需要多少只牛?(如果区间不能完全被覆盖,则 ...
- 【linux】awk的使用
教程来自:http://www.runoob.com/linux/linux-comm-awk.html 教程中的例子很好,可以有助于快速上手awk.但是里面的细节介绍的并不清楚. 问题1:什么时候写 ...
- ACdream 1195 Sudoku Checker (数独)
Sudoku Checker Time Limit:1000MS Memory Limit:64000KB 64bit IO Format:%lld & %llu Submit ...
- java中String类型转换方法
integer to String : int i = 42;String str = Integer.toString(i);orString str = "" + i doub ...
- 案例(用封装的ajax函数检查用户名)
本程序主要功能是检查用户输入的用户名是否在检查的范围之内 CheckUserName.htm代码: <head> <title></title> <scrip ...
- Codeforces Round #321 (Div. 2)C(tree dfs)
题意:给出一棵树,共有n个节点,其中根节点是Kefa的家,叶子是restaurant,a[i]....a[n]表示i节点是否有猫,问:Kefa要去restaurant并且不能连续经过m个有猫的节点有多 ...
- Material Design综合实例
背景知识 drawlayout的使用 recycleView的使用 CardView的使用 一些开源动画库的使用 ImageView的scaleType属性与adjustViewBounds属性 ,参 ...
- rsync 不能同不子级目录的问题
/usr/bin/rsync -vr /alidata/www/pro/mobile/* /alidata/www/crontal/mobile #-r, --recursive 对子目录以递归模式处 ...
- 3.工厂方法模式(Factory Method)
using System; using System.Reflection; namespace ConsoleApplication1 { class Program { static void M ...
- hdu 4003 树形dp+分组背包 2011大连赛区网络赛C
题意:求K个机器人从同一点出发,遍历所有点所需的最小花费 链接:点我 Sample Input 3 1 1 //3个点,从1出发,1个机器人 1 2 1 1 3 1 3 1 2 1 2 1 1 3 1 ...