Linux探秘之I/O效率
一、文章来由
最近看了《UNIX环境高级编程》,对以前比较模糊的一些知识结构又做了进一步的加强,特别是前两章讲到不带缓冲的文件I/O和带缓冲的标准I/O,对read、write、fread、fwrite、printf等等这些函数又有了新的认识。一个很大的感受是我们很多时候编程开发都只注重上层逻辑,虽然一个项目接一下项目,看上去做了不少事,但是夜深人静时仔细一想,究竟我们是否真正掌握了这些知识点,对于每一个知识点实现的机制我们是否能完整地说出来。这些东西最能体现一个人的基础知识是否扎实,我发现互联网公司的面试中最喜欢问这些基础知识,由一个很基本的函数都会层层递进引申出很多的问题。很多时候我们内心可能会很排斥,甚至不屑于这些基础知识,想着等用到的时候,我再来查,我就专注上层逻辑就好了,这样有助于提升我的开发效率。这样的想法貌似也没什么错,但是往往这就是瓶颈的来源,程序员最可怕的就是遇到瓶颈了。因为瓶颈这个东西是很难意识到的,一味追求实践而放弃理论学习,很容易就遇到瓶颈。(个人见解,不喜勿喷)
本文算是自己看完《UNIX环境高级编程》文件I/O和标准I/O两章的读书笔记,文件I/O一章说不带缓冲,但后面又出现可带缓冲,搞得我有点晕,特意记下自己对此的理解。如果有什么不对的,欢迎指出,如果你觉得本文对你有帮助,就动动手指推荐下,或者是粉我下,你的关注是我写作的最大动力。^_^
二、缓冲机制
众所周知,CPU和内存的数据交换要远大于磁盘操作,通过缓存机制,可以减少磁盘读写的次数,提高并发处理程序的效率,因此,缓存是一种提高任务存储和处理效率的有效方法。我们很多时候可以看到,缓存不单单在操作系统方面被采用,更是在Web技术、服务器端、分布式系统等领域发挥着及其重要的作用。
从宏观上看,Linux操作系统分为用户态和内核态,在处理I/O操作的时候,两者都提供了缓存。用户态的称为标准I/O缓存,也称为用户空间缓存,而内核态的称为缓冲区高速缓存,也叫页面高速缓存。既然都提供了缓存,那为什么这本书上却分不带I/O的缓存和带I/O的缓存,原因其实是“不带I/O缓存”指的是用户空间中不为这些I/O操作设有缓冲,而内核是带缓冲的,这样来看,就不会糊涂了。
三、系统I/O和标准I/O
系统I/O,又称文件I/O,或是内核态I/O,引用文件的方式是通过文件描述符,一个文件对应一个文件描述符。一个文件描述符用一个非负整数表示,0、1、2系统默认表示标准输入、标准输出、标准错误,某些UNIX系统规定了描述符的上限值OPEN_MAX,这些常量都定义在头文件<unistd.h>中。当读或写一个文件时,使用open或create系统调用返回的文件描述符标识该文件,并将其作为参数传递给read或write系统调用。
#include <unistd.h>
ssize_t read(int filedes, void *buf, size_t nbytes);
ssize_t write(int filedes, const void *buf, size_t nbytes);
标准I/O,又叫用户态I/O,引用文件的方式则是通过文件流(stream),一般用fopen和freopen函数打开一个流,返回一个指向FILE对象的指针,其他函数如果要引用这个流,则将FILE指针作为参数传递。一个进程预定义了三个流,并且这三个流自动被进程使用,它们是标准输入流、标准输出流和标准出错流,这三个流和系统I/O所规定的三个文件描述符所引用的文件相同。当读或写一个文件时,不像系统I/O,仅定义了read和write两个系统调用函数,标准I/O定义了多个函数,程序员可以根据自己的需求灵活使用。这些函数可以分为每次一个字符的I/O,每次一行的I/O和直接I/O(或者二进制I/O、一次一个对象I/O、面向记录的I/O、面向结构的I/O)。
1)每次一个字符的I/O
#include<sdio.h> /* 输入函数 */
int getc(FILE *fp) -> 宏
int fgetc(FILE *fp) -> 函数
int getchar(void) 等价于getc(stdin) /* 输出函数 */
int putc(int c, FILE *fp)
int fputc(int c, FILE *fp)
int putchar(int c) 等效于putc(c, stdout)
2)每次一行I/O
#include <stdio.h> /* 输入函数 */
char *fgets(char *restrict buf, int n, FILE *restrict fp)
char *gets(char *buf) /* 输出函数 */
int fputs(cont char *restrict str, FILE *restrict fp)
int puts(const char *str)
3)直接I/O
#include <stdio.h> size_t fread(void *restrict ptr, size_t size, size_t nobj, FILE *restrict fp) size_t fwrite(const void *restrict ptr, size_t size, size_t nobj, FILE *restrict fp)
到此,我们大概了解了系统I/O和标准I/O引用文件的方法,以及一些常用的I/O函数。下面通过一个图来详细看下当用户调用一个I/O函数时,用户态和内核态的一个执行流程是什么样的,进一步了解缓存在I/O操作中的作用,以及用户态I/O和内核态I/O在执行效率上的区别。
四、I/O操作的流程
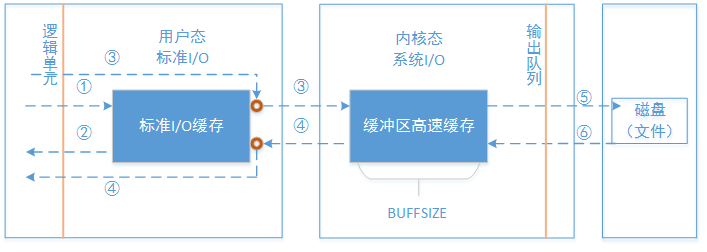
如上图所示,用户进程空间和内核进程空间读写磁盘的操作都要经过缓冲区缓存,缓存的作用前面也提到过,是为了减少磁盘读写的次数,提高I/O的效率。当读写一个文件时,首先看系统I/O的操作流程。
1、系统I/O: 属于内核系统调用,没有涉及用户态的参与。以图中标号为例:
(3) 调用write函数向文件中写数据,buf中存放的就是要写入的数据,如write(fd, 'abc', 3)。调用前需要先设置BUFFSIZE。不同的BUFFSIZE会影响I/O效率,下面再来说这个问题。
(5) 延迟写:当缓存区高速缓存满或者内核要重写缓冲区的时候,才将数据写入输出队列,等数据到队列首部的时候,才真正触发磁盘的写操作。
(6) 预读:当检测到正进行顺序读取时,内核就试图读入比应用程序所要求更多的数据,并假想应用程序很快就会读到这些数据。这样,当缓冲区没有数据时,能够快速填充下次要读取的数据。
(4) 调用read从缓冲区高速缓存读取所需数据到逻辑单元中进行处理。
以上,就是系统I/O所涉及到的四步操作。
2、标准I/O:属于ISO C实现的标准库函数,调用的是底层的系统调用。
(1) 将逻辑单元中的数据写入文件,根据需求,有三种函数类型可以调用,以fputc、fputs、fwrite为例,这些函数不用人为去控制缓冲区的大小,而是系统自动申请的,当用户定义了相应的I/O函数之后,根据不同的缓存类型(是全缓冲、行缓冲还是无缓冲),系统自动调用malloc等函数申请缓冲区,即标准I/O缓存。
(3)(5) 当用户缓冲区满了之后,如系统I/O操作一般,此时调用write从标准I/O缓存中复制数据到内核缓冲区,再写入磁盘。
(4)(6) 同系统I/O操作,从内核缓冲区调用read读入到用户缓冲区。
(2) 同样有三种函数类型可以调用,以fgetc、fgets、fread为例,读入逻辑单元进行后续的处理。
可见,标准I/O实现的机制就是基于系统I/O,这样看来,标准I/O在效率上肯定不如系统I/O,但事实是标准I/O与系统I/O相比并不慢很多,而且还有很多其他的优点,下面一一述说(本篇文章最重要的就是下一小节)。
五、I/O效率

系统I/O效率受限于read、write系统调用的次数,而系统调用次数则又受限于内核缓冲区的大小,即BUFFSIZE,通过设置不同的BUFFSIZE,系统CPU时间是不同的,其最小值出现在BUFFSIZE=4096处,原因是该测试所采用的是Linux ext2文件系统,其块长为4096字节,也即缓冲区所能申请到的最大缓冲区大小,我们把4096字节看做是本次最佳I/O长度。如果继续扩大缓冲区大小,对此时间几乎没有影响。所以,对于系统I/O操作,一个最大的问题就是:需要人为控制缓存的大小及最佳I/O长度的选择,另外就是系统调用与普通函数调用相比通常需要花费更多的时间,因为系统调用具体内核要执行这样的操作:1)内核捕获调用,2)检查系统调用参数的有效性,3)在用户空间和内核空间之间传输数据。
因此,引入标准I/O的目的就是为了通过标准I/O缓存来避免BUFFSIZE选择不当而带来的频繁的系统调用。根据用户不同的需求,选择不同的I/O函数,然后根据不同的缓存类型,自动调用malloc等缓存分配函数分配合适的缓存,等分配的缓存满之后,再调用系统I/O从标准I/O缓存向内核缓存拷贝数据,这样就进一步减少了系统调用的次数。

但是不同的标准I/O函数,不同的缓存类型也会带来不同的效率。如上图,当选择系统最佳I/O长度,即BUFFSIZE的大小和文件系统的块长一致,可以得到最佳的时间。当选用标准I/O函数时,每次一个字符函数fgetc、fputc和每次一行函数fgets、fputs函数相比要花费较多的CPU时间,而每次单个字节调用系统I/O则花费更多的时间,如果是一个100M的文件,则要执行大概2亿次函数调用,也就引起2亿次系统调用(从用户缓冲区到内核缓冲区,再到磁盘),而fgetc版本也执行了2亿次函数调用,但只引起了大约25222次系统调用,所以,时间就大大减少了。
综合以上,标准I/O函数虽然基于系统I/O实现,但很大程度上减少了系统调用的次数,而且不用人为关心缓冲区大小的选择,整体上提高了I/O的效率。另外,标准I/O提供了多种缓存类型,方便程序员根据不同的应用需求选择不同的缓存要求,提高了编程的灵活性,当选择无缓存时,就相当于直接调用系统I/O。
OK,大概的内容就以上这些,当然关于I/O操作这块还有很多需要注意的点,而且还有很多更加高级的I/O函数,这些在后面遇到再来做总结。最后,如果您觉得这篇文章对您有帮助就粉我吧,还是那句话,你的关注是我写作的最大动力。
更多干货请移步我的公众号「aCloudDeveloper」,专注技术干货分享,期待与你相遇。

Linux探秘之I/O效率的更多相关文章
- 使用Tmux提高linux终端环境下的效率
最近转移到linux下开发,同事告诉我一个工具tmux.关于tmux的工具的使用参考以下文章 如何使用Tmux提高终端环境下的效率 tmux的使用和快捷键 tmux简明教程 tmux使用大全
- 【Linux 系统】Linux探秘之用户态与内核态
一. Unix/Linux的体系架构 如上图所示,从宏观上来看,Linux操作系统的体系架构分为用户态和内核态(或者用户空间和内核).内核从本质上看是一种软件——控制计算机的硬件资源,并提供上层应用程 ...
- Linux下删除大量文件效率对比
来自公众号:马哥Linux运维 今天我们来测试一下Linux下面删除大量文件的效率. 首先建立50万个文件 $ test for i in $(seq 1 500000);do echo text ...
- Linux探秘之用户态与内核态
一. Unix/Linux的体系架构 如上图所示,从宏观上来看,Linux操作系统的体系架构分为用户态和内核态(或者用户空间和内核).内核从本质上看是一种软件——控制计算机的硬件资源,并提供上层应用程 ...
- Linux交叉开发环境搭建 —— 效率之源
楼主今天终于把所有Linux开发环境需要的软件下载完毕了.虽然以前也是搭建过的,时间久了又折腾了一晚上. 交叉环境: Windows.Linux文件共享 SecureCRT 连接虚拟机终端 工具: V ...
- Linux系统调用及其效率
操作系统相关概念: 操作系统---管理计算机硬件与软件资源的软件,是用户与系统操作交互的接口,为在它上面运行的程序提供服务. 操作系统内核 ----操作系统的核心.负责管理系统的进程.内核.设备驱动程 ...
- [转自王垠]完全用GNU/Linux工作,摈弃Windows低效率的工作方式
ZT (a qinghua student's article) 我已经半年没有使用 Windows 的方式工作了.Linux 高效的完成了我所有的工作. GNU/Linux 不是每个人都想用的.如果 ...
- Linux监控工具介绍系列——free
在Linux系统中,我们查看.监控系统内存使用情况,一般最常用的命令就是free.free命令其实非常简单,参数也非常简单,但是里面很多知识点未必你都掌握了.下面总结一下我所了解的free命令.如有不 ...
- Linux手动释放缓存的方法
Linux释放内存的命令:syncecho 1 > /proc/sys/vm/drop_caches drop_caches的值可以是0-3之间的数字,代表不同的含义:0:不释放(系统默认值)1 ...
随机推荐
- 升级ruby版本那"不堪回首的经历"
前段时间在玩Chef-一个IT基础设施自动化工具.由于Chef是由Ruby写的一个gem,那么就需要安装Ruby.当然Ruby我早就安装了,并且使用rvm来管理Ruby及Gem.本来一切看似正常,但是 ...
- 我们可以用SharePoint做什么
前言 不知不觉作为一个SharePoint的开发人员若干年了,从SharePoint api 开始学习,到了解SharePoint的结构,逐渐一点点了解sharepoint的体系:从SharePoin ...
- C/C++文件操作1
在C语言中,文件操作都是由库函数来完成的. 在本章内将介绍主要的文件操作函数. 文件打开函数fopen fopen函数用来打开一个文件,其调用的一般形式为:文件指针名=fopen(文件名,使用文件方式 ...
- windows本地自动集成代码+SSH服务器配置
在windows环境下使用Jenkins自动集成代码 描述: 局域网电脑A是本地服务器,安全win7系统,安装了Jenkins:现在想让A成为测试服务器,需要隔一段时间从SVN里同步出最新的代码,供客 ...
- 安装Vmware workstation虚拟机(含软件和注册码)
1:虚拟机的安装步骤,包含软件包和注册码.本博客所使用的虚拟机版本是vmware-workstation_11.1.0版本,注意不是最新版本, 软件包:http://pan.baidu.com/s/1 ...
- 关于年终奖励的扣税算法BUG
这么多年,第一次拿年终奖,于是查一下年终奖是怎么扣税的,根据 国税发[2005]9号 适用公式为: 应纳税额=雇员当月取得全年一次性奖金×适用税率一速算扣除数 年终奖: /= 的税率是3% 按照网上说 ...
- HOWTO - Basic MSI安装包在安装运行过程中如何获取完整源路径
有朋友问到如何在一个Windows Installer安装包中获取安装包源路径,就是在安装包运行过程中动态获取*.msi所在完整路径. 这个问题分两类,如果我们的安装包只是一个*.msi安装文件,那么 ...
- 诚聘:全栈开发人员,三线城市10-16K
北京快鸽联盟信息技术有限公司成立于2013年,专注于校园及社区快递和增值服务.目前已有十余家各地分部,并与上百所大学,各大快递和电商公司有密切合作,年处理快件量超千万,长期处于行业领先地位. 诚聘全栈 ...
- js 日期有效性验证 的一点思考
在日常项目中经常遇到日期输入验证,以前我遇到的项目是日期只能通过日历控件来选择,最近我同事遇到一个问题是日期除了可以通过日历控件来输入也可以手动来输入,可是我们项目中居然没有日期格式的验证方法(备注: ...
- 分布式的任务分发框架-Gearman
官方文档:http://gearman.org/getting-started/ 安装方法和示例都有,可以详细看一下. Gearman是一个分发任务的程序框架,可以用在各种场合,与Hadoop相比,G ...