[DB] Spark Streaming
概述
- 流式计算框架,类似Storm
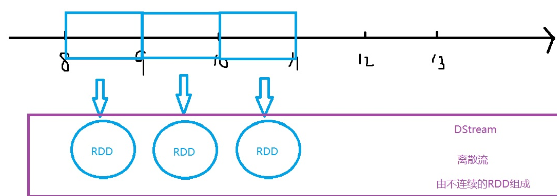
- 严格来说不是真正的流式计算(实时计算),而是把连续的数据当做不连续的RDD处理,本质是离散计算
- Flink:和 Spark Streaming 相反,把离散数据当成流式数据处理
基础
- 易用,已经集成在Spark中
- 容错性,底层也是RDD
- 支持Java、Scala、Python

WordCount
- nc -l -p 1234
- bin/run-example streaming.NetworkWordCount localhost 1234
- cpu核心数必须>1,不记录之前的状态


- 1 import org.apache.spark.SparkConf
- 2 import org.apache.spark.storage.StorageLevel
- 3 import org.apache.spark.streaming.{Seconds, StreamingContext}
- 4
- 5 // 创建一个StreamingContext,创建一个DSteam(离散流)
- 6 // DStream表现形式:RDD
- 7 // 使用DStream把连续的数据流变成不连续的RDD
- 8 object MyNetworkWordCount {
- 9 def main(args: Array[String]): Unit = {
- 10 // 创建一个StreamingContext对象,以local模式为例
- 11 // 保证CPU核心>=2,setMaster("[2]"),开启两个线程
- 12 val conf = new SparkConf().setAppName("MyNetworkWordCount").setMaster("local[2]")
- 13
- 14 // 两个参数:1.conf 和 2.采样时间间隔:每隔3s
- 15 val ssc = new StreamingContext(conf,Seconds(3))
- 16
- 17 // 创建DStream,从netcat服务器接收数据
- 18 val lines = ssc.socketTextStream("192.168.174.111",1234,StorageLevel .MEMORY_ONLY)
- 19
- 20 // 进行单词计数
- 21 val words = lines.flatMap(_.split(" "))
- 22
- 23 // 计数
- 24 val wordCount = words.map((_,1)).reduceByKey(_+_)
- 25
- 26 // 打印结果
- 27 wordCount.print()
- 28
- 29 // 启动StreamingContext,进行计算
- 30 ssc.start()
- 31
- 32 // 等待任务结束
- 33 ssc.awaitTermination()
- 34 }
- 35 }

高级特性
- 什么是DStream:离散流,把连续的数据流变成不连续的RDD
- transform
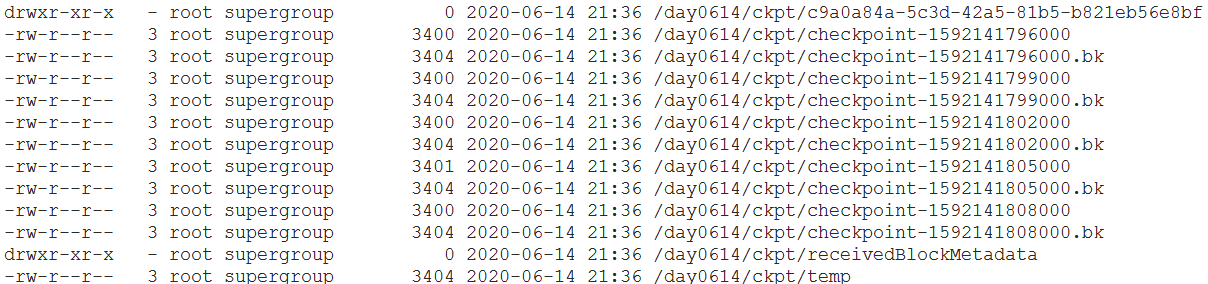
- updateStateByKey(func):累加之前的结果,设置检查点,把之前的结果保存到检查点目录下
- hdfs dfs -mkdir -p /day0614/ckpt
- hdfs dfs -ls /day0614/ckpt
- 1 import org.apache.spark.SparkConf
- 2 import org.apache.spark.storage.StorageLevel
- 3 import org.apache.spark.streaming.{Seconds, StreamingContext}
- 4
- 5 // 创建一个StreamingContext,创建一个DSteam(离散流)
- 6 // DStream表现形式:RDD
- 7 // 使用DStream把连续的数据流变成不连续的RDD
- 8 object MyTotalNetworkWordCount {
- 9 def main(args: Array[String]): Unit = {
- 10 // 创建一个StreamingContext对象,以local模式为例
- 11 // 保证CPU核心>=2,setMaster("[2]"),开启两个线程
- 12 val conf = new SparkConf().setAppName("MyNetworkWordCount").setMaster("local[2]")
- 13
- 14 // 两个参数:1.conf 和 2.采样时间间隔:每隔3s
- 15 val ssc = new StreamingContext(conf,Seconds(3))
- 16
- 17 // 设置检查点目录,保存之前状态
- 18 ssc.checkpoint("hdfs://192.168.174.111:9000/day0614/ckpt")
- 19
- 20 // 创建DStream,从netcat服务器接收数据
- 21 val lines = ssc.socketTextStream("192.168.174.111",1234,StorageLevel .MEMORY_ONLY)
- 22
- 23 // 进行单词计数
- 24 val words = lines.flatMap(_.split(" "))
- 25
- 26 // 计数
- 27 val wordPair = words.map(w => (w,1))
- 28
- 29 // 定义值函数
- 30 // 两个参数:1.当前的值 2.之前的结果
- 31 val addFunc = (curreValues:Seq[Int],previousValues:Option[Int])=>{
- 32 // 把当前序列进行累加
- 33 val currentTotal = curreValues.sum
- 34
- 35 // 在之前的值上再累加
- 36 // 如果之前没有值,返回0
- 37 Some(currentTotal + previousValues.getOrElse(0))
- 38 }
- 39
- 40 // 累加计算
- 41 val total = wordPair.updateStateByKey(addFunc)
- 42
- 43 total.print()
- 44
- 45 ssc.start()
- 46
- 47 ssc.awaitTermination()
- 48
- 49 }
- 50 }

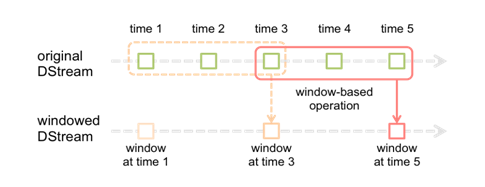
- 窗口操作
- 只统计在窗口中的数据
- Exception in thread "main" java.lang.Exception: The slide duration of windowed DStream (10000 ms) must be a multiple of the slide duration of parent DStream (3000 ms)
- 滑动距离必须是采样频率的整数倍
- 1 package day0614
- 2
- 3 import org.apache.log4j.{Level, Logger}
- 4 import org.apache.spark.SparkConf
- 5 import org.apache.spark.storage.StorageLevel
- 6 import org.apache.spark.streaming.{Seconds, StreamingContext}
- 7
- 8
- 9 object MyNetworkWordCountByWindow {
- 10 def main(args: Array[String]): Unit = {
- 11 // 不打印日志
- 12 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
- 13 Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
- 14 // 创建一个StreamingContext对象,以local模式为例
- 15 // 保证CPU核心>=2,setMaster("[2]"),开启两个线程
- 16 val conf = new SparkConf().setAppName("MyNetworkWordCount").setMaster("local[2]")
- 17
- 18 // 两个参数:1.conf 和 2.采样时间间隔:每隔3s
- 19 val ssc = new StreamingContext(conf,Seconds(3))
- 20
- 21 // 创建DStream,从netcat服务器接收数据
- 22 val lines = ssc.socketTextStream("192.168.174.111",1234,StorageLevel .MEMORY_ONLY)
- 23
- 24 // 进行单词计数
- 25 val words = lines.flatMap(_.split(" ")).map((_,1))
- 26
- 27 // 每9s,把过去30s的数据进行WordCount
- 28 // 参数:1.操作 2.窗口大小 3.窗口滑动距离
- 29 val result = words.reduceByKeyAndWindow((x:Int,y:Int)=>(x+y),Seconds(30),Seconds(9))
- 30
- 31 result.print()
- 32 ssc.start()
- 33 ssc.awaitTermination()
- 34 }
- 35 }
- 集成Spark SQL
- 使用SQL语句分析流式数据
- 1 package day0614
- 2
- 3 import org.apache.log4j.{Level, Logger}
- 4 import org.apache.spark.SparkConf
- 5 import org.apache.spark.sql.SparkSession
- 6 import org.apache.spark.storage.StorageLevel
- 7 import org.apache.spark.streaming.{Seconds, StreamingContext}
- 8
- 9 object MyNetworkWordCountWithSQL {
- 10 def main(args: Array[String]): Unit = {
- 11 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
- 12 Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
- 13 // 创建一个StreamingContext对象,以local模式为例
- 14 // 保证CPU核心>=2,setMaster("[2]"),开启两个线程
- 15 val conf = new SparkConf().setAppName("MyNetworkWordCount").setMaster("local[2]")
- 16
- 17 // 两个参数:1.conf 和 2.采样时间间隔:每隔3s
- 18 val ssc = new StreamingContext(conf,Seconds(3))
- 19
- 20 // 创建DStream,从netcat服务器接收数据
- 21 val lines = ssc.socketTextStream("192.168.174.111",1234,StorageLevel .MEMORY_ONLY)
- 22
- 23 // 进行单词计数
- 24 val words = lines.flatMap(_.split(" "))
- 25
- 26 // 集成Spark SQL,使用SQL语句进行WordCount
- 27 words.foreachRDD(rdd=> {
- 28 // 创建SparkSession对象
- 29 val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
- 30
- 31 // 把rdd转成DataFrame
- 32 import spark.implicits._
- 33 val df1 = rdd.toDF("word") // 表df1:只有一个列"word"
- 34
- 35 // 创建视图
- 36 df1.createOrReplaceTempView("words")
- 37
- 38 // 执行SQL,通过SQL执行WordCount
- 39 spark.sql("select word,count(*) from words group by word").show
- 40 })
- 41
- 42 ssc.start()
- 43 ssc.awaitTermination()
- 44 }
- 45 }

数据源
- 基本数据源
- 文件流
- 1 import org.apache.log4j.{Level, Logger}
- 2 import org.apache.spark.SparkConf
- 3 import org.apache.spark.storage.StorageLevel
- 4 import org.apache.spark.streaming.{Seconds, StreamingContext}
- 5
- 6 object FileStreaming {
- 7 def main(args: Array[String]): Unit = {
- 8 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
- 9 Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
- 10 // 创建一个StreamingContext对象,以local模式为例
- 11 // 保证CPU核心>=2,setMaster("[2]"),开启两个线程
- 12 val conf = new SparkConf().setAppName("MyNetworkWordCount").setMaster("local[2]")
- 13
- 14 // 两个参数:1.conf 和 2.采样时间间隔:每隔3s
- 15 val ssc = new StreamingContext(conf,Seconds(3))
- 16
- 17 // 直接监控本地的某个目录,如果有新的文件产生,就读取进来
- 18 val lines = ssc.textFileStream("F:\\idea-workspace\\temp")
- 19
- 20 lines.print()
- 21 ssc.start()
- 22 ssc.awaitTermination()
- 23 }
- 24 }
- RDD队列流
- 1 import org.apache.log4j.{Level, Logger}
- 2 import org.apache.spark.SparkConf
- 3 import org.apache.spark.rdd.RDD
- 4 import org.apache.spark.storage.StorageLevel
- 5 import org.apache.spark.streaming.{Seconds, StreamingContext}
- 6 import scala.collection.mutable.Queue
- 7
- 8 object RDDQueueStream {
- 9 def main(args: Array[String]): Unit = {
- 10 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
- 11 Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
- 12 // 创建一个StreamingContext对象,以local模式为例
- 13 // 保证CPU核心>=2,setMaster("[2]"),开启两个线程
- 14 val conf = new SparkConf().setAppName("MyNetworkWordCount").setMaster("local[2]")
- 15
- 16 // 两个参数:1.conf 和 2.采样时间间隔:每隔1s
- 17 val ssc = new StreamingContext(conf,Seconds(1))
- 18
- 19 // 创建队列,作为数据源
- 20 val rddQueue = new Queue[RDD[Int]]()
- 21 for(i<-1 to 3){
- 22 rddQueue += ssc.sparkContext.makeRDD(1 to 10)
- 23 // 睡1s
- 24 Thread.sleep(1000)
- 25 }
- 26
- 27 // 从队列中接收数据,创建DStream
- 28 val inputDStream = ssc.queueStream(rddQueue)
- 29
- 30 // 处理数据
- 31 val result = inputDStream.map(x=>(x,x*2))
- 32 result.print()
- 33
- 34 ssc.start()
- 35 ssc.awaitTermination()
- 36 }
- 37 }
- 套接字流(socketTextStream)
- 高级数据源
- Flume
- 基于Flume的Push模式
- 依赖jar包:Flume的lib目录,spark-streaming-flume_2.10-2.1.0
- 启动Flume:bin/flume-ng agent -n a4 -f myagent/a4.conf -c conf Dflume.root.logger=INFO,console
- 基于Flume的Push模式
- Flume
- 1 import org.apache.log4j.Logger
- 2 import org.apache.log4j.Level
- 3 import org.apache.spark.SparkConf
- 4 import org.apache.spark.streaming.StreamingContext
- 5 import org.apache.spark.streaming.Seconds
- 6 import org.apache.spark.streaming.flume.FlumeUtils
- 7
- 8 object MyFlumeStreaming {
- 9 def main(args: Array[String]): Unit = {
- 10 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
- 11 Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
- 12
- 13 val conf = new SparkConf().setAppName("MyFlumeStreaming").setMaster("local[2]")
- 14
- 15 val ssc = new StreamingContext(conf,Seconds(3))
- 16
- 17 //创建 flume event 从 flume中接收push来的数据 ---> 也是DStream
- 18 //flume将数据push到了 ip 和 端口中
- 19 val flumeEventDstream = FlumeUtils.createStream(ssc, "192.168.174.1", 1234)
- 20
- 21 val lineDStream = flumeEventDstream.map( e => {
- 22 new String(e.event.getBody.array)
- 23 })
- 24
- 25 lineDStream.print()
- 26
- 27 ssc.start()
- 28 ssc.awaitTermination()
- 29 }
- 30 }
- 基于Customer Sink的Pull模式()
- /logs-->source-->sink-->程序从sink中pull数据-->打印
- 需要定义sink组件
- 把spark的jar包拷贝到Flume下:cp *.jar ~/training/apache-flume-1.7.0-bin/
- 把spark-streaming-flume-sink_2.10-2.1.0.jar放到Flume/lib下
- 清空training/logs:rm -rf *
- 基于Customer Sink的Pull模式()
- 1 package day0615
- 2
- 3 import org.apache.log4j.{Level, Logger}
- 4 import org.apache.spark.SparkConf
- 5 import org.apache.spark.storage.StorageLevel
- 6 import org.apache.spark.streaming.{Seconds, StreamingContext}
- 7 import org.apache.spark.streaming.flume.FlumeUtils
- 8
- 9 object MyFlumePullStreaming {
- 10 def main(args: Array[String]): Unit = {
- 11 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
- 12 Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
- 13
- 14 val conf = new SparkConf().setAppName("MyFlumeStreaming").setMaster("local[2]")
- 15
- 16 val ssc = new StreamingContext(conf, Seconds(3))
- 17
- 18 // 创建 DStream,从Flume中接收事件(Event),采用Pull方式
- 19 val flumeEventStream = FlumeUtils.createPollingStream(ssc,"192.168.174.111",1234,StorageLevel.MEMORY_ONLY)
- 20
- 21 // 从Event事件中接收字符串
- 22 val stringDStream = flumeEventStream.map(e =>{
- 23 new String(e.event.getBody.array())
- 24 })
- 25
- 26 stringDStream.print()
- 27
- 28 ssc.start()
- 29 ssc.awaitTermination()
- 30 }
- 31 }
- Kafka
- 基于Receiver:接收到的数据保存在Spark executors中,然后由Spark Streaming启动Job来处理数据
- 启动Kafka服务:bin/kafka-server-start.sh config/server.properties &
- 启动Kafka生产者:bin/kafka-console-producer.sh --broker-list bigdata111:9092 --topic mydemo1
- 在IDEA中启动任务,接收Kafka消息
- 1 import org.apache.log4j.{Level, Logger}
- 2 import org.apache.spark.SparkConf
- 3 import org.apache.spark.streaming.kafka.KafkaUtils
- 4 import org.apache.spark.streaming.{Seconds, StreamingContext}
- 5
- 6 object KafkaReceiveDemo {
- 7 def main(args: Array[String]): Unit = {
- 8 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
- 9 Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
- 10
- 11 val conf = new SparkConf().setAppName("SparkKafkaReciever").setMaster("local[2]")
- 12 val ssc = new StreamingContext(conf, Seconds(10))
- 13
- 14 // 从mydemo1中每次获取一条数据
- 15 val topics = Map("mydemo1" -> 1)
- 16 // 从Kafka接收数据
- 17 // ssc是Spark Streaming Context
- 18 // 192.168.174.111:2181是ZK地址
- 19 // MyGroup:Kafka的消费者组,同一个组的消费者只能消费一次消息
- 20 // topics:Kafka的Toipc(频道)
- 21 val kafkaDStream = KafkaUtils.createStream(ssc, "192.168.174.111:2181", "MyGroup", topics)
- 22
- 23 val stringDStream = kafkaDStream.map(e => {
- 24 new String(e.toString())
- 25 })
- 26
- 27 stringDStream.print()
- 28
- 29 ssc.start()
- 30 ssc.awaitTermination()
- 31 }
- 32 }
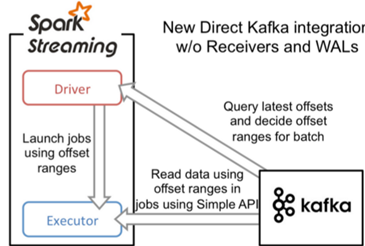
- 直接读取:定期从Kafka的topic+partition中查询最新的偏移量,再根据定义的偏移量范围在每个batch里处理数据
- 效率更高
- 直接读取:定期从Kafka的topic+partition中查询最新的偏移量,再根据定义的偏移量范围在每个batch里处理数据
- 1 import kafka.serializer.StringDecoder
- 2 import org.apache.log4j.{Level, Logger}
- 3 import org.apache.spark.SparkConf
- 4 import org.apache.spark.streaming.kafka.KafkaUtils
- 5 import org.apache.spark.streaming.{Seconds, StreamingContext}
- 6
- 7 object KafkaDirectDemo {
- 8 def main(args: Array[String]): Unit = {
- 9 Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
- 10 Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
- 11
- 12 val conf = new SparkConf().setAppName("SparkKafkaReciever").setMaster("local[2]")
- 13 val ssc = new StreamingContext(conf, Seconds(3))
- 14
- 15 // 参数
- 16 val topics = Set("mydemo1")
- 17 // broker地址
- 18 val kafkaParam = Map[String,String]("metadata.broker.list"->"192.168.174.111:9092")
- 19
- 20 // 从Kafka的Broker中直接读取数据
- 21 // StringDecoder:字符串解码器
- 22 val kafkaDirectStream = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParam,topics)
- 23
- 24 // 处理数据
- 25 val StringDStream = kafkaDirectStream.map(e=>{
- 26 new String(e.toString())
- 27 })
- 28
- 29 StringDStream.print()
- 30
- 31 ssc.start()
- 32 ssc.awaitTermination()
- 33 }
- 34 }

参考
IDEA Maven scala
https://www.jianshu.com/p/ecc6eb298b8f
kafka分区
https://www.cnblogs.com/qmfsun/p/10951282.html
与kafka整合
https://blog.csdn.net/drl_blogs/article/details/94721434
https://www.cnblogs.com/bonelee/p/7435506.html
http://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html
https://www.jianshu.com/p/667e0f58b7b9
[DB] Spark Streaming的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark Streaming+Kafka
Spark Streaming+Kafka 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端, ...
- Spark streaming消费Kafka的正确姿势
前言 在游戏项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark streaming从kafka中不 ...
- 基于Spark Streaming + Canal + Kafka对Mysql增量数据实时进行监测分析
Spark Streaming可以用于实时流项目的开发,实时流项目的数据源除了可以来源于日志.文件.网络端口等,常常也有这种需求,那就是实时分析处理MySQL中的增量数据.面对这种需求当然我们可以通过 ...
- Spark Streaming 002 统计单词的例子
1.准备 事先在hdfs上创建两个目录: 保存上传数据的目录:hdfs://alamps:9000/library/SparkStreaming/data checkpoint的目录:hdfs://a ...
- Spark Streaming updateStateByKey案例实战和内幕源码解密
本节课程主要分二个部分: 一.Spark Streaming updateStateByKey案例实战二.Spark Streaming updateStateByKey源码解密 第一部分: upda ...
- spark streaming 使用geoIP解析IP
1.首先将GEOIP放到服务器上,如,/opt/db/geo/GeoLite2-City.mmdb 2.新建scala sbt工程,测试是否可以顺利解析 import java.io.Fileimpo ...
- Spark踩坑记:Spark Streaming+kafka应用及调优
前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark streaming从k ...
- Spark Streaming从Flume Poll数据案例实战和内幕源码解密
本节课分成二部分讲解: 一.Spark Streaming on Polling from Flume实战 二.Spark Streaming on Polling from Flume源码 第一部分 ...
随机推荐
- 使用 Android Studio 开发 widget 安卓桌面插件
•What AppWidget 即桌面小部件,也叫桌面控件,就是能直接显示在Android系统桌面上的小程序: 这么说可能有点抽象,看图: 像这种,桌面上的天气.时钟.搜索框等等,都属于 APP Wi ...
- SQL 存储过程里调用另一个存储过程
由于创建了一个存储过程,并且要在另一个存储过程里调用这个存储过程所以在网上找了一下相关的代码,现在总结一下,防止以后还会用到 由于这次我写的存储过程只需要返回一个求和的结果,所以我使用了output ...
- HTML特殊标签
一,HTML特殊标签 二,换行标签 <br>标签用来将内容换行,其在HTML网页上的效果相当于我们平时使用word编辑文档时使用回车换行. 三,分割线 <hr>标签用来在HTM ...
- Java利用线程工厂监控线程池
目录 ThreadFactory 监控线程池 扩展线程池 扩展线程池示例 优化线程池大小 线程池死锁 线程池异常信息捕获 ThreadFactory 线程池中的线程从哪里来呢?就是ThreadFoct ...
- DBeaver、Navicat、MySQL高频报错及解决方法,此文持续更新
目录 第一坑,没有用管理员身份 第二坑,MySQL 服务无法启动 第三坑,报错:ERROR 1045 (28000): Access denied for user 'root'@'localhost ...
- java面试-G1垃圾收集器
一.以前收集器的特点 年轻代和老年代是各自独立且连续的内存块 年轻代收集器使用 eden + S0 + S1 进行复制算法 老年代收集必须扫描整个老年代区域 都是以尽可能的少而快速地执行 GC 为设计 ...
- 【PHP】用了这么久的Laravel框架,你分析过核心架构了没
Laravel最初的设计是为了面向MVC架构的,它可以满足如事件处理.用户身份验证等各种需求.另外它还有一个由管理数据库强力支持,用于管理模块化和可扩展性代码的软件包管理器. Laravel以其简洁. ...
- Webpack的基本配置和打包与介绍(二)
1. 前言 在上一章中我们学习到了webpack的基本安装配置和打包,我们这一章来学学如何使用loader和plugins 如果没看第一章的这里有传送门 2. Loader 2.1 什么是loader ...
- c# 定时启动一个操作、任务
// 定时启动一个操作.任务 using System; using System.Collections.Generic; using System.Collections.ObjectModel; ...
- 请使用管理员权限执行pip install命令
重要的事情说三遍! 请使用管理员权限执行pip install命令 请使用管理员权限执行pip install命令 请使用管理员权限执行pip install命令 踩坑记录 当时一切还是从一题Misc ...