Adaptive gradient descent without descent
概
本文提出了一种自适应步长的梯度下降方法(以及多个变种方法), 并给了收敛性分析.
主要内容
主要问题:
\min_x \: f(x).
\]
局部光滑的定义:
若可微函数\(f(x)\)在任意有界区域内光滑,即
\]
其中\(\mathcal{C}\)有界.
本文的一个基本假设是函数\(f(x)\)凸且局部光滑.
算法1 AdGD

定理1 ADGD-L
定理1. 假设\(f: \mathbb{R}^d \rightarrow \mathbb{R}\) 为凸函数且局部光滑. 则由算法1生成的序列\((x^k)\)收敛到(1)的最优解, 且
\]
其中\(\hat{x}^k := \frac{\sum_{i=1}^k \lambda_i x^i + \lambda_1 \theta_1 x^1}{S_k}\), \(S_k:= \sum_{i=1}^k \lambda_i + \lambda_1 \theta\).
算法2

在\(L\)已知的情况下, 我们可以对算法1进行改进.
定理2
定理2 假设\(f\)凸且\(L\)光滑, 则由算法(2)生成的序列\((x^k)\)同样使得
\]
成立.
算法3 ADGD-accel

这部分没有理论证明, 是作者基于Nesterov中的算法进行的改进.
算法4 Adaptive SGD

这个算法是对SGD的一个改进.
定理4

代码
\(f(x, y) = x^2+50y^2\), 起点为\((30, 15)\).
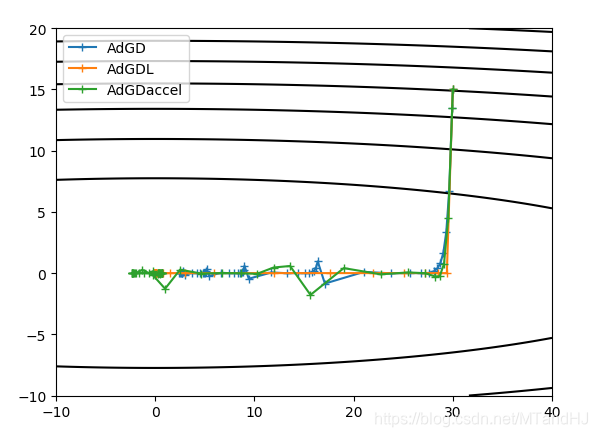
"""
adgd.py
"""
import numpy as np
import matplotlib.pyplot as plt
State = "Test"
class FuncMissingError(Exception): pass
class StateNotMatchError(Exception): pass
class AdGD:
def __init__(self, x0, stepsize0, grad, func=None):
self.func_grad = grad
self.func = func
self.points = [x0]
self.points.append(self.calc_one(x0, self.calc_grad(x0),
stepsize0))
self.prestepsize = stepsize0
self.theta = None
def calc_grad(self, x):
self.pregrad = self.func_grad(x)
return self.pregrad
def calc_one(self, x, grad, stepsize):
return x - stepsize * grad
def calc_stepsize(self, grad, pregrad):
part2 = (
np.linalg.norm(self.points[-1]
- self.points[-2]) /
(np.linalg.norm(grad - pregrad) * 2)
)
if not self.theta:
return part2
else:
part1 = np.sqrt(self.theta + 1) * self.prestepsize
return min(part1, part2)
def update_theta(self, stepsize):
self.theta = stepsize / self.prestepsize
self.prestepsize = stepsize
def step(self):
pregrad = self.pregrad
prex = self.points[-1]
grad = self.calc_grad(prex)
stepsize = self.calc_stepsize(grad, pregrad)
nextx = self.calc_one(prex, grad, stepsize)
self.points.append(nextx)
self.update_theta(stepsize)
def multi_steps(self, times):
for k in range(times):
self.step()
def plot(self):
if self.func is None:
raise FloatingPointError("func is not defined...")
if State != "Test":
raise StateNotMatchError()
xs = np.array(self.points)
x = np.linspace(-40, 40, 1000)
y = np.linspace(-20, 20, 500)
fig, ax = plt.subplots()
X, Y = np.meshgrid(x, y)
ax.contour(X, Y, self.func([X, Y]), colors='black')
ax.plot(xs[:, 0], xs[:, 1], "+-")
plt.show()
class AdGDL(AdGD):
def __init__(self, x0, L, grad, func=None):
super(AdGDL, self).__init__(x0, 1 / L, grad, func)
self.lipschitz = L
def calc_stepsize(self, grad, pregrad):
lk = (
np.linalg.norm(grad - pregrad) /
np.linalg.norm(self.points[-1]
- self.points[-2])
)
part2 = 1 / (self.prestepsize * self.lipschitz ** 2) \
+ 1 / (2 * lk)
if not self.theta:
return part2
else:
part1 = np.sqrt(self.theta + 1) * self.prestepsize
return min(part1, part2)
class AdGDaccel(AdGD):
def __init__(self, x0, stepsize0, convex0, grad, func=None):
super(AdGDaccel, self).__init__(x0, stepsize0, grad, func)
self.preconvex = convex0
self.Theta = None
self.prey = self.points[-1]
def calc_convex(self, grad, pregrad):
part2 = (
(np.linalg.norm(grad - pregrad) * 2) /
np.linalg.norm(self.points[-1]
- self.points[-2])
) / 2
if not self.Theta:
return part2
else:
part1 = np.sqrt(self.Theta + 1) * self.preconvex
return min(part1, part2)
def calc_beta(self, stepsize, convex):
part1 = 1 / stepsize
part2 = convex
return (part1 - part2) / (part1 + part2)
def calc_more(self, y, beta):
nextx = y + beta * (y - self.prey)
self.prey = y
return nextx
def update_Theta(self, convex):
self.Theta = convex / self.preconvex
self.preconvex = convex
def step(self):
pregrad = self.pregrad
prex = self.points[-1]
grad = self.calc_grad(prex)
stepsize = self.calc_stepsize(grad, pregrad)
convex = self.calc_convex(grad, pregrad)
beta = self.calc_beta(stepsize, convex)
y = self.calc_one(prex, grad, stepsize)
nextx = self.calc_more(y, beta)
self.points.append(nextx)
self.update_theta(stepsize)
self.update_Theta(convex)
config.json:
{
"AdGD": {
"stepsize0": 0.001
},
"AdGDL": {
"L": 100
},
"AdGDaccel": {
"stepsize0": 0.001,
"convex0": 2.0
}
}
"""
测试代码
"""
import numpy as np
import matplotlib.pyplot as plt
import json
from adgd import AdGD, AdGDL, AdGDaccel
with open("config.json", encoding="utf-8") as f:
configs = json.load(f)
partial_x = lambda x: 2 * x
partial_y = lambda y: 100 * y
grad = lambda x: np.array([partial_x(x[0]),
partial_y(x[1])])
func = lambda x: x[0] ** 2 + 50 * x[1] ** 2
fig, ax = plt.subplots()
x = np.linspace(-10, 40, 500)
y = np.linspace(-10, 20, 500)
X, Y = np.meshgrid(x, y)
ax.contour(X, Y, func([X, Y]), colors='black')
def process(methods, times=50):
for method in methods:
method.multi_steps(times)
def initial(methods, **kwargs):
instances = []
for method in methods:
config = configs[method.__name__]
config.update(kwargs)
instances.append(method(**config))
return instances
def plot(methods):
for method in methods:
xs = np.array(method.points)
ax.plot(xs[:, 0], xs[:, 1], "+-", label=method.__class__.__name__)
plt.legend()
plt.show()
x0 = np.array([30., 15.])
methods = [AdGD, AdGDL, AdGDaccel]
instances = initial(methods, x0=x0, grad=grad, func=func)
process(instances)
plot(instances)
Adaptive gradient descent without descent的更多相关文章
- 【转】Caffe初试(九)solver及其设置
solver算是caffe的核心的核心,它协调着整个模型的运作.caffe程序运行必带的一个参数就是solver配置文件.运行代码一般为 #caffe train --solver=*_solver. ...
- 【深度学习】之Caffe的solver文件配置(转载自csdn)
原文: http://blog.csdn.net/czp0322/article/details/52161759 今天在做FCN实验的时候,发现solver.prototxt文件一直用的都是mode ...
- Caffe学习系列(7):solver及其配置
solver算是caffe的核心的核心,它协调着整个模型的运作.caffe程序运行必带的一个参数就是solver配置文件.运行代码一般为 # caffe train --solver=*_slover ...
- tensorflow 学习(一)
改系列只为记录我学习 udacity 中深度学习课程!! 1. 整个课程分为四个部分,如上图所示. 第一部分将研究逻辑分类器,随机优化以及实际数据训练. 第二部分我们将学习一个深度网络,和使用正则化技 ...
- caffe中各层的作用:
关于caffe中的solver: cafffe中的sover的方法都有: Stochastic Gradient Descent (type: "SGD"), AdaDelta ( ...
- Caffe学习系列(8):solver优化方法
上文提到,到目前为止,caffe总共提供了六种优化方法: Stochastic Gradient Descent (type: "SGD"), AdaDelta (type: &q ...
- Caffe学习系列(二)Caffe代码结构梳理,及相关知识点归纳
前言: 通过检索论文.书籍.博客,继续学习Caffe,千里之行始于足下,继续努力.将自己学到的一些东西记录下来,方便日后的整理. 正文: 1.代码结构梳理 在终端下运行如下命令,可以查看caffe代码 ...
- 深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
在机器学习.深度学习中使用的优化算法除了常见的梯度下降,还有 Adadelta,Adagrad,RMSProp 等几种优化器,都是什么呢,又该怎么选择呢? 在 Sebastian Ruder 的这篇论 ...
- 【深度学习】深入理解优化器Optimizer算法(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
在机器学习.深度学习中使用的优化算法除了常见的梯度下降,还有 Adadelta,Adagrad,RMSProp 等几种优化器,都是什么呢,又该怎么选择呢? 在 Sebastian Ruder 的这篇论 ...
随机推荐
- npm下载错误解决办法
解决办法:删除npmrc文件. 使用镜像 镜像使用方法(三种办法任意一种都能解决问题,建议使用第三种,将配置写死,下次用的时候配置还在):1.通过config命令12npm config set re ...
- Android实现网络监听
一.Android Wifi常用广播 网络开发中主体会使用到的action: ConnectivityManager.CONNECTIVITY_ACTION WifiManager.WIFI_STAT ...
- tomcat 8 内存优化
在Linux环境下设置Tomcat JVM,在/opt/tomcat/bin/catalina.sh文件中找到"# ----- Execute The Requested Command&q ...
- java中的迭代器的含义
可迭代是Java集合框架下的所有集合类的一种共性,也就是把集合中的所有元素遍历一遍.迭代的过程需要依赖一个迭代器对象,那么什么是迭代器呢? 迭代器(Iterator)模式,又叫做游标模式,它的含义是, ...
- 【阿菜做实践】利用ganache-cli本地fork以太坊主链分叉
前言 Fork主网意思是模拟具有与主网相同的状态的网络,但它将作为本地开发网络工作. 这样你就可以与部署的协议进行交互,并在本地测试复杂的交互.不用担心分叉主网作为测试链会占很多内存.这些方法都不会将 ...
- 『与善仁』Appium基础 — 23、操作滑动的方式
目录 1.swipe滑动 2.scroll滑动 3.drag拖拽事件 4.滑动方法小结 5.拓展:多次滑动 6.综合练习 在Appium中提供了三种滑动的方式,swipe滑动.scroll滑动.dra ...
- collection库更新1.4.0版本
collection库更新1.4.0版本 collection库一直在使用中,周末集合github上的反馈以及contributor的修改,更新了1.4.0版本. 这个版本做了几个事情: 增加了三种类 ...
- HashMap的putAll方法介绍说明
jdk1.8 使用putAll时,新map中的值仅为旧map值所对应对象的引用,并不会产生新对象. 如下,使用for循环赋值! public void putAll(Map<? extends ...
- pf4j及pf4j-spring
什么是PF4J 一个插件框架,用于实现插件的动态加载,支持的插件格式(zip.jar). 核心组件 Plugin:是所有插件类型的基类.每个插件都被加载到一个单独的类加载器中以避免冲突. Plugin ...
- CTF 自动拼图
忘记在哪个群里面看见有师傅说过这样一句加,百度搜索"CTF拼图脚本,有惊喜". 在做JUSTCTF的题时候,看到一道拼图题.就想着试一试. 先百度搜了,看到了fjh1997师傅的一 ...