[Elasticsearch] ES聚合场景下部分结果数据未返回问题分析
背景
在对ES某个筛选字段聚合查询,类似groupBy操作后,发现该字段新增的数据,聚合结果没有展示出来,但是用户在全文检索新增的筛选数据后,又可以查询出来, 针对该问题进行了相关排查。
排查思路
首先要明确我们数据的写入流程, 下图:
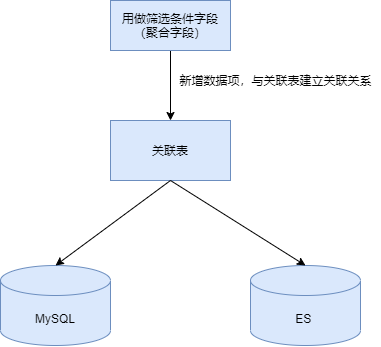
在检查Mysql库的数据没有问题之后,开始检查ES是否有问题,根据现象我们知道既然在全文检索中都能搜索到,说明数据肯定是写入ES里了,但是又如何确定聚合结果呢?
首先添加日志将代码最终生成DSL语句打印出来
LOGGER.info("\n{}", searchRequestBuilder);
这样就很方便地使用curl命令进行调试了
下面是对生成的DSL语句执行查询:
curl -XGET 'http://ip:9200/es_data_index/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query":{
"bool":{
"must":[
{
"term":{
"companyId":{
"value":1,
"boost":1
}
}
},
{
"term":{
"yn":{
"value":1,
"boost":1
}
}
},
{
"match_all":{
"boost":1
}
}
],
"must_not":[
{
"term":{
"table_sentinel":{
"value":2,
"boost":1
}
}
}
],
"disable_coord":false,
"adjust_pure_negative":true,
"boost":1
}
},
"aggregations":{
"group_by_topics":{
"terms":{
"field":"topic",
"size":10,
"min_doc_count":1,
"shard_min_doc_count":0,
"show_term_doc_count_error":false,
"order":[
{
"_count":"desc"
},
{
"_term":"asc"
}
]
}
}
}
}'
上图group_by_topics 就是我们要聚合的字段, 下面是执行该DSL语句的结果:
"aggregations" : {
"group_by_topics" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 14,
"buckets" : [
{
"key" : 1,
"doc_count" : 35
},
{
"key" : 19,
"doc_count" : 25
},
{
"key" : 18,
"doc_count" : 17
},
{
"key" : 29,
"doc_count" : 15
},
{
"key" : 20,
"doc_count" : 12
},
{
"key" : 41,
"doc_count" : 8
},
{
"key" : 161,
"doc_count" : 5
},
{
"key" : 2,
"doc_count" : 3
},
{
"key" : 3,
"doc_count" : 2
},
{
"key" : 21,
"doc_count" : 2
}
]
}
}
经过观察发现聚合结果确实没有我们新增的筛选项, 同时返回的数据只有10条
"sum_other_doc_count" : 14, 这项是关键项,从字面意思看还有有其他的文档,于是查询具体在ES中的意义是什么?
经过查询发现有段描述:
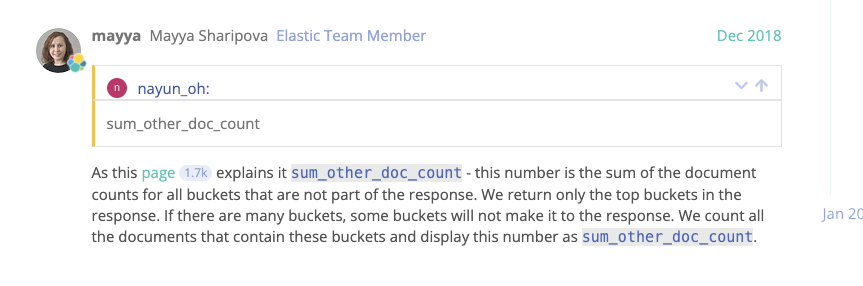
就是只会返回top结果, 部分结果不响应返回
那如何让这部分结果返回呢?
带着问题, 发现使用桶聚合,默认会根据doc_count 降序排序,同时默认只返回10条聚合结果.
可以通过在聚合查询增大属性size来解决,如下
curl -XGET 'http://ip:9200/es_data_index/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query":{
"bool":{
"must":[
{
"term":{
"companyId":{
"value":1,
"boost":1
}
}
},
{
"term":{
"yn":{
"value":1,
"boost":1
}
}
},
{
"match_all":{
"boost":1
}
}
],
"must_not":[
{
"term":{
"table_sentinel":{
"value":2,
"boost":1
}
}
}
],
"disable_coord":false,
"adjust_pure_negative":true,
"boost":1
}
},
"aggregations":{
"group_by_topics":{
"terms":{
"field":"topic",
"size":100,
"min_doc_count":1,
"shard_min_doc_count":0,
"show_term_doc_count_error":false,
"order":[
{
"_count":"desc"
},
{
"_term":"asc"
}
]
}
}
}
}'
下面是查询结果:
"aggregations" : {
"group_by_topics" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 1,
"doc_count" : 35
},
{
"key" : 19,
"doc_count" : 25
},
{
"key" : 18,
"doc_count" : 17
},
{
"key" : 29,
"doc_count" : 15
},
{
"key" : 20,
"doc_count" : 12
},
{
"key" : 41,
"doc_count" : 8
},
{
"key" : 161,
"doc_count" : 5
},
{
"key" : 2,
"doc_count" : 3
},
{
"key" : 3,
"doc_count" : 2
},
{
"key" : 21,
"doc_count" : 2
},
{
"key" : 81,
"doc_count" : 2
},
{
"key" : 801,
"doc_count" : 2
},
{
"key" : 0,
"doc_count" : 1
},
{
"key" : 4,
"doc_count" : 1
},
{
"key" : 5,
"doc_count" : 1
},
{
"key" : 6,
"doc_count" : 1
},
{
"key" : 7,
"doc_count" : 1
},
{
"key" : 11,
"doc_count" : 1
},
{
"key" : 23,
"doc_count" : 1
},
{
"key" : 28,
"doc_count" : 1
},
{
"key" : 201,
"doc_count" : 1
},
{
"key" : 241,
"doc_count" : 1
}
]
}
把ES所有的筛选项数据都统计返回来.
代码里设置size:
TermsAggregationBuilder termAgg1 = AggregationBuilders.terms("group_by_topics")
.field("topic").size(100);
我们解决了问题, 现在思考下ES为什么不一下子返回所有统计项的结果数据呢?
答案是由ES聚合机制决定, ES怎么聚合呢
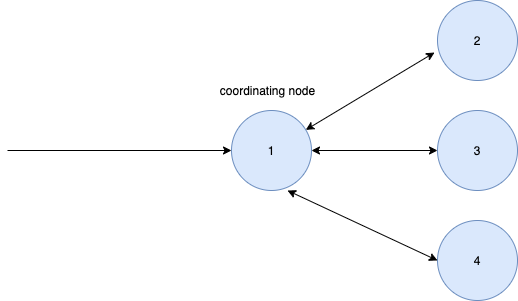
接受客户端的节点是协调节点
协调节点上,搜索任务会被分解成两个阶段: query和fetch
真正搜索或聚合任务的节点为数据节点,如图 2, 3, 4
聚合步骤:
- 客户端发请求到协调节点
- 协调节点将请求推送到各数据节点
- 各数据节点指定分片参与数据汇集工作
- 协调节点进行总结果汇聚
es 出于效率和性能原因等,聚合的结果其实是不精确的.什么意思? 就是以我们上面遇到的场景为例:
默认返回top 10 聚合结果, 首先各节点分片取自己的topic 10 返回给协调节点,然后协调节点进行汇总. 这样会导致全量的实际聚合结果跟预期的不一致.
这里扩展下,虽然有很多办法提高ES聚合精准度,但是对于大数据量的精准聚合,响应速度要快场景,es并不擅长,需要使用类似clickhouse这样的产品来解决这样的场景.
总结
本文主要针对实际工作的应用问题,来排查解决ES聚合数据部分数据未展示问题, 同时对ES的聚合检索原理进行讲解 .在数据量大、聚合精度要求高、响应速度快的业务场景ES并不擅长.
参考
https://discuss.elastic.co/t/what-does-sum-other-doc-count-mean-exactly/159687
[Elasticsearch] ES聚合场景下部分结果数据未返回问题分析的更多相关文章
- mock以及特殊场景下对mock数据的处理
一.为什么要mock 工作中遇到以下问题,我们可以使用mock解决: 无法控制第三方系统某接口的返回,返回的数据不满足要求 某依赖系统还未开发完成,就需要对被测系统进行测试 有些系统不支持重复请求,或 ...
- 记一次高并发场景下.net监控程序数据上报的性能调优
最近在和小伙伴们做充电与通信程序的架构迁移.迁移前的架构是,通信程序负责接收来自充电集控设备的数据实时数据,通过Thrift调用后端的充电服务,充电服务收到响应后放到进程的Queue中,然后在管理线程 ...
- Elasticsearch系列---聚合查询原理
概要 本篇主要介绍聚合查询的内部原理,正排索引是如何建立的和优化的,fielddata的使用,最后简单介绍了聚合分析时如何选用深度优先和广度优先. 正排索引 聚合查询的内部原理是什么,Elastich ...
- Android智能手机中各种音频场景下的audio data path
上一篇文章(Android智能手机上的音频浅析)说本篇将详细讲解Android智能手机中各种音频场景下的音频数据流向,现在我们就开始.智能手机中音频的主要场景有音频播放.音频录制.语音通信等.不同场景 ...
- ES 24 - 如何通过Elasticsearch进行聚合检索 (分组统计)
目录 1 普通聚合分析 1.1 直接聚合统计 1.2 先检索, 再聚合 1.3 扩展: fielddata和keyword的聚合比较 2 嵌套聚合 2.1 先分组, 再聚合统计 2.2 先分组, 再统 ...
- 「Elasticsearch」ES重建索引怎么才能做到数据无缝迁移呢?
背景 众所周知,Elasticsearch是⼀个实时的分布式搜索引擎,为⽤户提供搜索服务.当我们决定存储某种数据,在创建索引的时候就需要将数据结构,即Mapping确定下来,于此同时索引的设定和很多固 ...
- 亿级流量场景下,大型架构设计实现【全文检索高级搜索---ElasticSearch篇】-- 中
1.Elasticsearch的基础分布式架构: 1.Elasticsearch对复杂分布式机制的透明隐藏特性2.Elasticsearch的垂直扩容与水平扩容3.增减或减少节点时的数据rebalan ...
- 浅谈Vue不同场景下组件间的数据交流
浅谈Vue不同场景下组件间的数据“交流” Vue的官方文档可以说是很详细了.在我看来,它和react等其他框架文档一样,讲述的方式的更多的是“方法论”,而不是“场景论”,这也就导致了:我们在阅读完 ...
- HBase指定大量列集合的场景下并发拉取数据时卡住的问题排查
最近遇到一例,HBase 指定大量列集合的场景下,并发拉取数据,应用卡住不响应的情形.记录一下. 问题背景 退款导出中,为了获取商品规格编码,需要从 HBase 表 T 里拉取对应的数据. T 对商品 ...
随机推荐
- C#表头固定
<%@ Control Language="C#" AutoEventWireup="true" CodeFile="info.ascx.cs& ...
- 巩固javaweb的第二十天
巩固内容: 同一个页面中的多个 form 在同一个页面中可以有多个 form 如果存在多个 form,那么提交信息的时候提交哪些信息,提交给哪个文件处理,这都 与提交按钮的位置有关.如果提交按钮在第一 ...
- A Child's History of England.46
As, one hundred years before, the servile [卑躬屈膝的~serve] followers of the Court had abandoned the Con ...
- Python计算期权隐含波动率
更多精彩内容,欢迎关注公众号:数量技术宅,也可添加技术宅个人微信号:sljsz01,与我交流. Black-Scholes 将期权价格描述为标的价格.行权价.无风险利率.到期时间和波动性的函数. V ...
- springboot-使用AOP日志拦截实现
一 前言 借助spring的AOP功能,我们可以将AOP应用至全局异常处理,全局请求拦截等,本篇文章的核心功能就是使用AOP实现日志记录,比如哪些用户进行了哪些操作,对于一个成功的项目这是必须记录的, ...
- Linux学习 - fdisk分区
一.fdisk命令分区过程 系统一旦重启,分区将消失 1 添加新硬盘 直接在虚拟机上添加 2 查看新硬盘 fdisk -l 3 分区 fdisk /dev/sdb fdisk进入/dev/sdb硬件设 ...
- ubuntu基础
下载地址: http://cdimage.ubuntu.com/releases/ #:配置多网卡静态IP地址和路由 root@ubuntu:~# vim /etc/netplan/01-netcfg ...
- 【科研工具】MathType7.2的安装破解与使用
亲测可用,可以嵌入word. [我们为什么要用MathType] tex不香嘛,但是学校给的模板只有word,word输入公式点起来实在是太麻烦了. 有了这个就可以直接输入公式转换啦. [安装破解教程 ...
- 『与善仁』Appium基础 — 20、Appium元素定位
目录 1.by_id定位 2.by_name定位 3.by_class_name定位 4.by_xpath定位 5.by_accessibility_id定位 6.by_android_uiautom ...
- 重新整理 .net core 实践篇——— UseEndpoints中间件[四十八]
前言 前文已经提及到了endponint 是怎么匹配到的,也就是说在UseRouting 之后的中间件都能获取到endpoint了,如果能够匹配到的话,那么UseEndpoints又做了什么呢?它是如 ...