Optimization Landscape and Expressivity of DeepCNNs
Nguyen Q C, Hein M. Optimization Landscape and Expressivity of Deep CNNs[J]. arXiv: Learning, 2017.
BibTex
@article{nguyen2017optimization,
title={Optimization Landscape and Expressivity of Deep CNNs},
author={Nguyen, Quynh C and Hein, Matthias},
journal={arXiv: Learning},
year={2017}}
引
这篇文章,主要证明,在某些不算很强的假设下,CNN的最后的损失(文中是MSE)能够达到零,而且能够满足其的网络参数的无穷多的. 另外,还有"局部"最优解都是全局最优解的特性. 证明主要用到了勒贝格积分的知识(实际上,这一部分应该算在另一篇论文上,没去看),以及更多的代数的知识.
主要内容
基本的一些定义
\(X=[x_1, \ldots, x_N]^T \in \R^{N \times d}\)为输入的N个样本,而\(Y=[y_1, \ldots, y_N]^T \in \R^{N \times m}\)为对应的N个标签.
假设网络共有\(L\)层,\(n_k\)为第\(k=0, 1, \ldots, L\)层的宽度,也即神经元的个数. 用\(f_k: \R^d \rightarrow \R^{n_k}\)表示由样本\(x\)到第\(k\)层的输出的映射.
patches: 我们将每一层的神经元分成若干份,每一份的长度相同,且是包含所有神经元,并且没有俩个patch是完全相同的. 假设,每一层被分成\(P_k\)份,长度为\(l_k\). 则,可以表示为
\{x^1, \ldots, x^{P_0}\} \subset \R^{l_0}, & k=0, \\
\{f_k^1(x), \ldots, f_k^{P_k}(x)\} \subset \R^{l_k}, & k = 1, 2, \ldots, L-1.
\end{array} \right.
\]
filter: 假设每一层有\(T_k\)个filters,则 \(W_k = [w_k^1, \ldots,w_k^{T_k}] \in \R^{l_{k-1} \times T_k}, 1 \le k < L\) . 容易知道\(n_k=P_{k-1}T_k\), 并假设第k层的偏执为\(b_k \in \R^{n_k}\). 如果是全连接层,很明显,\(n_k=T_k\).
激活函数: 用\(\sigma_k\)表示第\(k\)层的激活函数, entry-wise.
卷积层

其中\([a] = \{1, 2, \ldots, a\}\).
上面的定义可以这么理解,先拿出第一个patch,用所有的filters操作一遍,并加上偏置,再通过激活函数为最后的输出,然后再拿下一个patch... 一般的卷积层,其实就是相当先分patch,再利用卷积核处理,当然这里可能存在一个排序的问题,但是作者证明的结论的过程中不需要排序.
全连接层

池化层
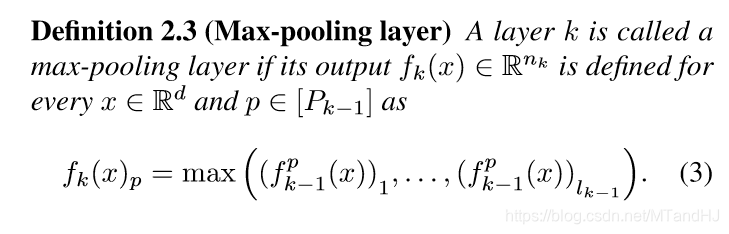
改写卷积层
为了更形象的表示,作者弄了一个线性映射\(\mathcal{M}_k: \R^{l_{k-1} \times T_k} \rightarrow \R^{n_{k-1} \times n_k}\). 看如下的例子:
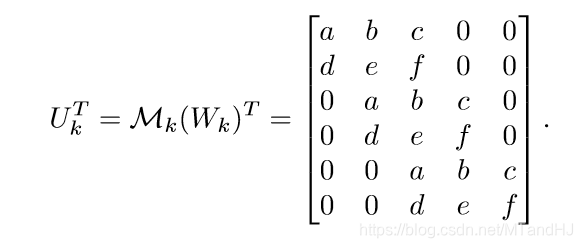
其中:
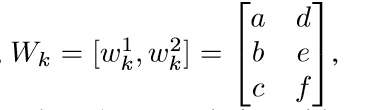
\(n_{k-1}=5\), 也就是说,输入是5维的向量,卷积核是3维的,滑动为1. 相当于把\(w\)扩充至\(n_{k-1}\),且只有所作用的patch的对应位置不为0. 这样就能用一种全连接层的是视角去看待了,而全连接层的\(U_k=W_k\). 所以,我们不需要再管patch了,来了一个输入\(x\),只需\(U_k^Tx\),然后进行加偏执和激活函数的操作即可,具体如下:
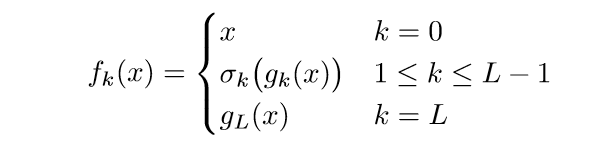
其中\(g_k(x)=U_k^Tf_{k-1}(x)+b_k\). 定义:
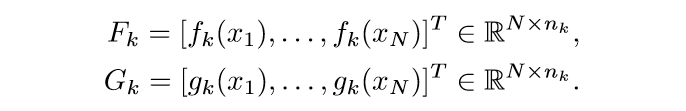
则:
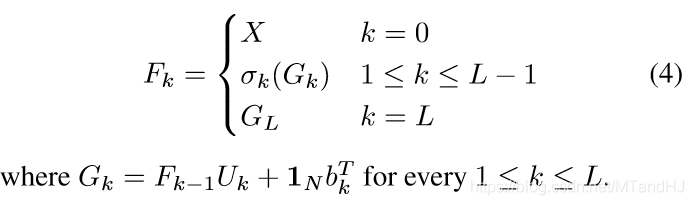
定义损失函数:
\]
假设2.4

对于第k个卷积层,存在\(W_k\)使得\(U_k\)是满秩的. 并且从下面的话中可以发现,只要patches满足之前讲的那些假设,那么这个假设便能够成立. 问题是,我不知道这个假设如何证明.
引理2.5

引理2.5告诉我们,让\(U_k\)满秩的\(W_k\)不仅存在,而且很多,多到让\(U_k\)不满秩的\(W_k\)的勒贝格测度为0. 也就是随便走两步都能满足假设.
假设3.1

这个假设看似很强,但是作者指出,可以通过对样本添加一个噪声来满足.
假设3.2

激活函数是连续非常数,且有一些极限性质.
引理3.3
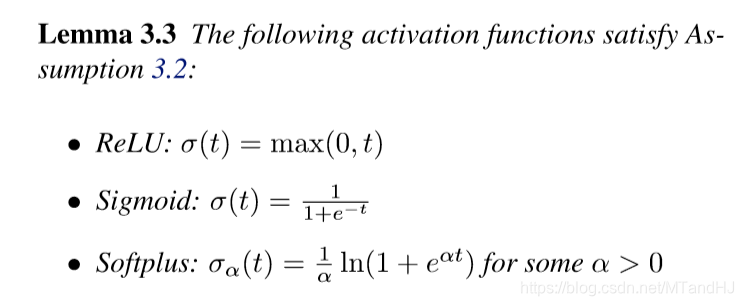
ReLU, Sigmoid, Softplus等一些常见的激活函数都是满足上面的假设的.
定理3.4

注意, 条件1是第一层和第k层为卷积或者全连接层. 满足这些条件,则有\(\{f_k(x_1), \ldots, f_k(x_N)\}\)线性独立,也即\(F_k\)满秩.
定理3.5


注意,这里的条件1是第一层到第k层均为全连接层或卷积层. 则令\(F_k\)不满秩的网络参数的勒贝格测度为0,也就是说,\(F_k\)满秩是平凡的.
推论3.6

也就是说,我们能够找到网络参数,满足训练0误差.
假设4.1

注意,这里假设整个网络不包括池化层,且最后的输出层是全连接层.
并定义:
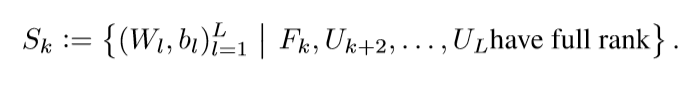
引理4.2

关于解析函数,这是复变函数里的东西,不同的版本有出入,

至少是无穷次可导的, 所以ReLU自然不列入考虑范围之内.
引理4.2说明\(F_k, U_{k+2}, \ldots, U_L\)满秩是很容易满足的.
引理4.3
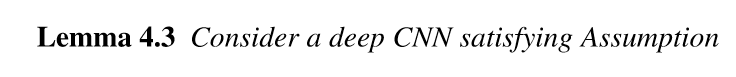
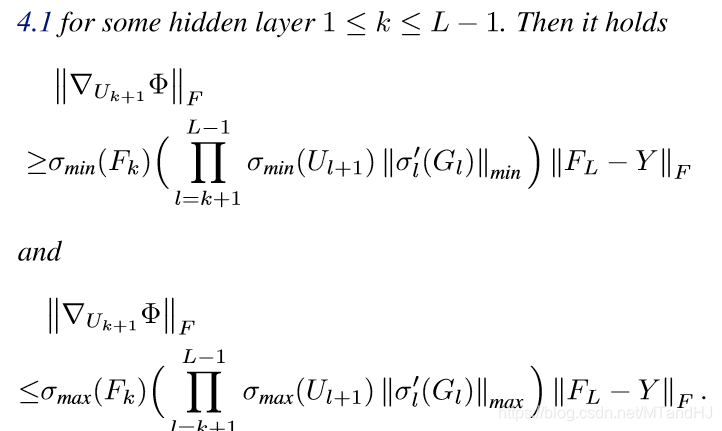
定理4.4

定理4.4告诉我们,\(S_k\)中的所有的驻点(关于\(U_{k+1}\))都是最小值点.
定理4.5
作者考虑一个具体的分类问题,则CNN最后的输出应该为\(Z \in \R^{m \times m}\),即有m类,如果样本\(x_i\)属于第j类,则\(Y\)的第i行为\(Z\)的第j行. 所以,一般情况下,\(Z\)为单位矩阵?

注意第\(k+1\)层为全连接层.
Proof
引理A.1
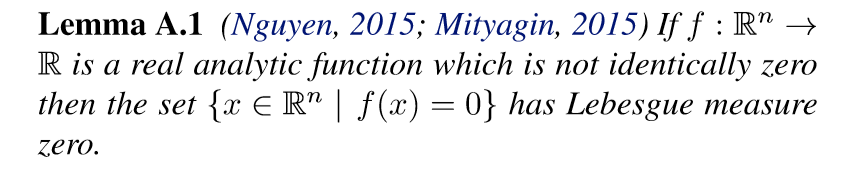
实解析函数,如果不恒为0,则\(\{x \in \R^n| f(x)=0\}\)的勒贝格测度为0, 也就是几乎处处不为0呗.
引理2.5 证明
\(U_k = \mathcal{M}_k (W_k) \in \R^{n_{k-1} \times n_k}\), 因为\(\mathcal{M_k}\)是一个线性映射,所以\(U_k\)的每一个元素都是\(W_k\)的一个线性函数的像. 又\(U_k\)的每一个\(m \times m, m = \min \{n_{k-1}, n_k\}\)行列式是一个多项式函数,所以是解析函数,而解析函数的复合依旧是解析函数,所以每一个行列式都是关于\(W_k\)的一个解析函数. 而根据假设2.4,我们知道,存在一行列式不恒等于0,所以根据引理A.1, 引理2.5可得.
引理3.3

定理3.4
引理D.1

就是,我们能找到一些网络参数,使得不同的样本\(f_k\)的各元素不同.
证明: 这个证明可以通过归纳法证明,只要我们找到\(W_1, b_1\)使得\(f_1^p(x_i) \not = f_1^q(x_j)\)成立,后面的结果也就可类似推导成立了. 且因为全连接层是卷积层的一个特例,所以只需证明是卷积层的时候成立即可.
用\(Q=[a^1, \ldots, a^{T_1}] \in \R^{l_0 \times T_1}\)表示,其中每一列都是一个filters. 定义:
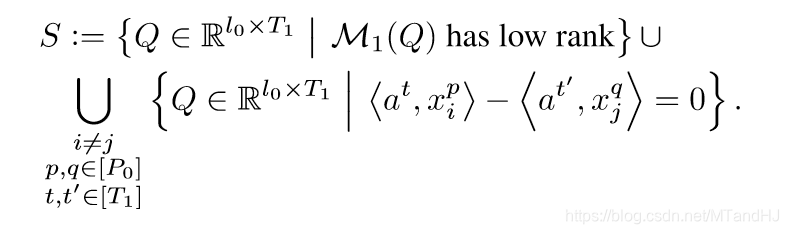
显然,属于\(S\)的元素,要么使得\(U_k\)不满秩,要么使得\(f_1(x_i),f_1(x_j)\)有俩个元素相同,则其补集一定满足引理D.1的结论. 所以我们只要证明这个补集不是空集即可.
根据假设3.1,\(x_i^p \not = x_j^q, i \not = j\), 所以\(\langle a^t, x_i^p \rangle-\langle a^{t'},x_j^q \rangle=0\)是一个超平面,显然,其测度为0,而有限个这样的超平面的并依旧是零测集, 所以\(S\)的后半部分的测度为0. 而前半部分,根据引理2.5可知,其测度也为0,所以\(S\)的测度也为0.
如果,我们证明\(g\)穿过激活函数依旧保持那些性质的话,关于卷积层和全连接层的证明就结束了.
既然\(\sigma_1\)是个连续的非常数函数,那么存在一个区间\((\mu_1, \mu_2)\)使得\(\sigma_1\)在其上存在双射(这个存疑,不是有一个处处连续但处处不可导的函数吗,那个也能满足?).
我们先固定\(Q \in \R^{l_0 \times T_1} \setminus S\), 令\(\beta \in (\mu_1, \mu_2)\). 并令\(\alpha >0\) 以及\(W_1 = \alpha Q, (b_1)_h=\beta.\)
既然\(\beta \in (\mu_1, \mu_2)\), 我们只需要选择足够小的\(\alpha\), 就能满足\(\alpha \langle a, x_i^p \rangle+ \beta \in (\mu_1, \mu_2)\).
对于任意的\(h,v, h=(p-1)T_1+t, v=(q-1)T_1+t'\),
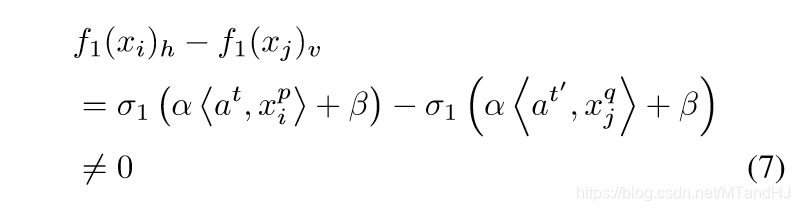
对于任意的\(i \not =j\) 以及足够小的\(\alpha\)(注意,因为对于足够小的\(\alpha\), \(\sigma_1\)单调,所以若为0,则需要原像相同,而这由\(Q\)的选择保证不可能).
于是:
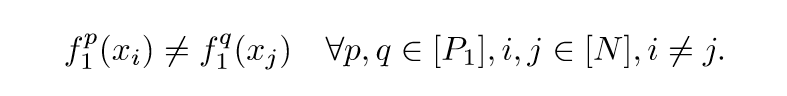
实际上,结果还要更加强一些.
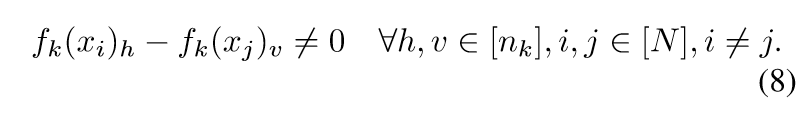
最后只要再证明对池化层也成立即可.
假设对前\(k\)层都成立,第\(k+1\)层为池化层. 于是\(n_{k+1}=P_{k}\), 且对于\(p \in [P_k]\):
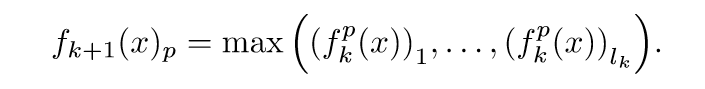
既然(8)成立,所以\((f_{k}(x_i))_r \not = (f_{k}(x_j))_s, i\not= j\), 自然,其最大值也不同,即
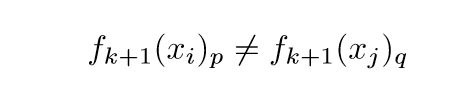
所以,结论对于池化层也成立.
定理3.4的证明, 仅说明其证明思路. 根据引理D.1,我们可以找到网络参数,使得第\(k-1\)层满足:\(f_{k-1}^p(x_i) \not = f_{k-1}^q(x_j), i \not = j\). 所以,接下来,只要找到\(W_k, b_k\)使得最后的\(A:=F_k \in \R^{N \times n_k}\)满秩就可以了.
先定义\(Q=[a^1, a^2, \ldots, a^{T_k}] \in \R^{l_{k-1} \times T_k}\)以及:
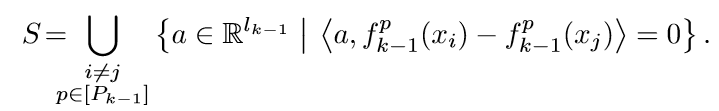
和引理D.1的证明类似,\(S\)的测度为0,\(Q\)的列可以取到\(\R^{l_{k-1}} \setminus S\),并且满足\(\mathcal{M_k}(Q)\)满秩(因为满秩的集合测度不为0).
既然激活函数\(\sigma_k\)连续非常数,一定存在\(\beta, \sigma_k(\beta) \not = 0\). 则定义\(W_k = [w_k^1, \ldots, w_k^{T_k}]\)和偏执\(b_k\), 且有:
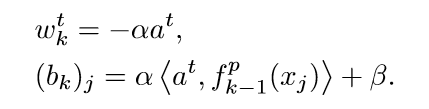
相应的,有
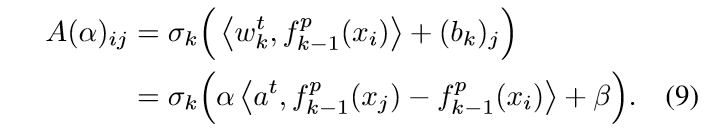
我们可以调整\(x_i,x_j\)的顺序,使得下列式子满足:
\]
接下来,根据对激活函数的假设(假设3.2),可以分成俩种情况来证明:
首先是
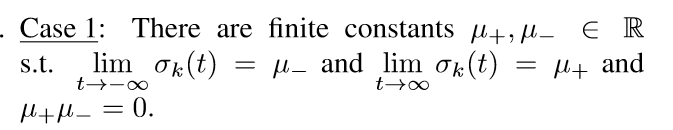
不妨设\(\mu_-=0\), 则
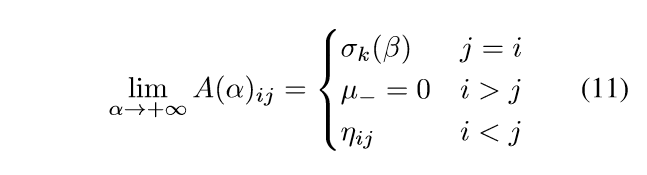
所以收敛到最后是一个上三角矩阵. 再看一般的\(A(\alpha)\)的前N行N列(我们只要证明这个行列不为0,则\(A(\alpha)\)就满秩).
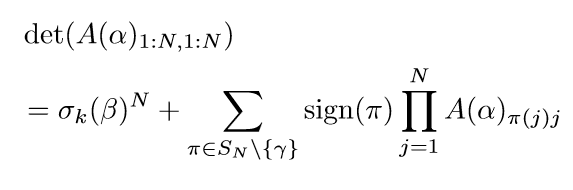
这个分解,就是最开始的行列式的定义,取不同行不同列的乘积的和(还有相应的符号). 易知:
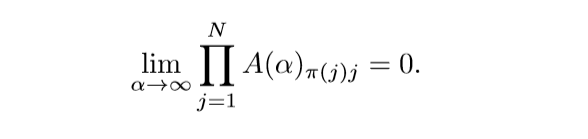
对于\(\pi \not = \gamma\), \(\gamma\)就是\(12345...N\)的序. 所以\(\mathrm{det}(A(\alpha)_{1:N, 1:N}) \rightarrow \sigma_k(\beta)^N \not = 0\).
既然行列式关于\(\alpha\)的连续函数,一定存在足够小的\(\alpha\)使得行列式不为0,即\(A(\alpha)\)满秩, 这样,\(W_k, b_k\)就找到了. \(\mu_+=0\)的证明是类似的.
另一种情况是:
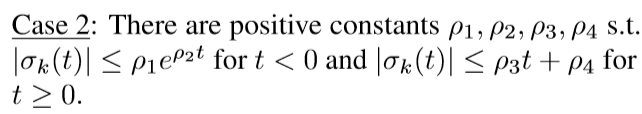
其证明也是类似的,只是取充分大的\(\alpha\).
定理3.5
定理3.5的条件更强,能够保证\(f_k\)是关于\(W_l,b_l\)的一个解析函数,那么\(F_k = [f_k(x_1), \ldots, f_k(x_N)]^T \in \R^{N \times n_k}\)的\(N \times N\)的子矩阵的行列式也为解析函数,既然我们以及找到了这样的\(W_l,b_l\)使得某个子矩阵的行列式不为0,根据引理A.1可知,令\(F_k\)不满秩的\(W_l, b_l\)的参数的集合的测度为0.
推论3.6
既然,我们能够找到参数\((W_l, b_l)_{l=1}^{L-1}\)使得\(rank(F_{L-1})=N\), 我们的任务就是找一个\(\lambda \in \R^{n_{L-1}}\)使得\(F_{L-1}\lambda=F_L\), 显然
\]
满足这个条件.
引理4.2
\]
显然:
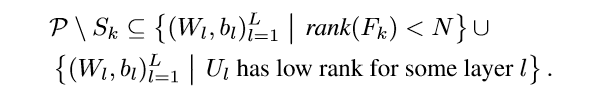
其中\(\mathcal{P}\)表全集.
后面的第一部分根据定理3.5可知测度为0,第二部分根据引理2.5可知测度亦为0,所以后面的部分测度为0. 所以\(\mathcal{P} \setminus S_k\)的测度自然也为0.
引理4.3
首先,介绍一下 Hadamard product (阿达玛积), \(\circ\),
\]
即矩阵对应元素相乘,当然这要求\(A, B\)行列相同. 阿达玛积满足交换律,结合律:
A \circ (B \circ C) = A \circ B \circ C, \\
A \circ (B + C) = A \circ B + A \circ C.
\]
另外, \((A \circ B)^T = A^T \circ B^T\)是显然的,以及
\mathbf{Tr}(A \cdot (B \circ C)) & = |A^T \circ B \circ C| \\
&= \mathbf{Tr}(A^T \circ B \cdot C^T) \\
& = \mathbf{Tr}(A \circ B^T \cdot C).
\end{array}
\]
再证明引理4.3之前,我们需要先推导出损失函数与\(U\)的梯度关系,我们先整理一下:
损失函数:
\]
第\(L\)层为全连接层,所以:
\]
F_k = \sigma_k(G_k) \in \R^{N \times n_k}, \\
k = 1, 2, \ldots, L-1.
\]
\]
定义\(\Delta_k\), 其中的(i, j)元素为\(\partial \Phi/ \partial (G_{k})_{ij}\).
\mathrm{d} \Phi & = \mathbf{Tr}((F_L-Y)^T\mathrm{d}F_L) = \mathbf{Tr}((F_L-Y)^T\mathrm{d}G_L) \\
& = \mathbf{Tr}(\Delta_L^T \mathrm{d}G_L) = \mathbf{Tr}(\Delta_L^T(\mathrm{d}F_{L-1})U_L+\Delta_L^T F_{L-1} \mathrm{d} U_L) \\
&= \mathbf{Tr}(\Delta_L^T F_{L-1} \mathrm{d} U_L) + \mathbf{Tr}(U_L\Delta_L^T\mathrm{d}\sigma_{L-1}(G_{L-1})) \\
&=\mathbf{Tr}(\Delta_L^T F_{L-1} \mathrm{d} U_L) + \mathbf{Tr}(U_L\Delta_L^T\sigma_{L-1}'(G_{L-1}) \circ \mathrm{d}G_{L-1}) \\
&=\mathbf{Tr}(\Delta_L^T F_{L-1} \mathrm{d} U_L) + \mathbf{Tr}(U_L\Delta_L^T \circ {\sigma_{L-1}'}^T \cdot\mathrm{d}G_{L-1})
\end{array}
\]
所以:
\Delta_{L-1} = \Delta_LU_L^ T \circ {\sigma_{L-1}'}(G_{L-1}), \\
\nabla_{U_L} \Phi = F_{L-1}^T \Delta_L.
\]
类似可证明:
\nabla_{U_l} \Phi = F_{l-1}^T \Delta_l, \quad k+1 \le l \le L.
\]
再引入俩个引理,比较简单便不给出证明了.
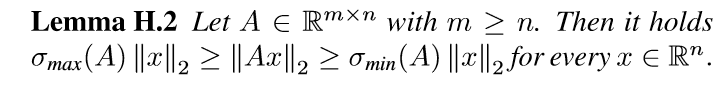
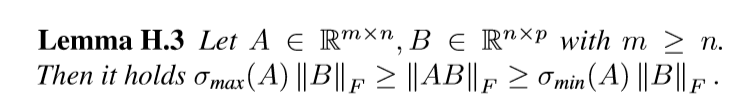
我们已经知道\(\nabla_{U_{k+1}} \Phi = F_k^T \Delta_{k+1}\), 并用\(\otimes\) 表示克罗内克积, 有
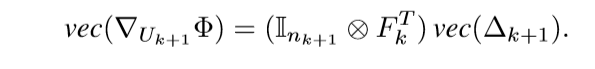
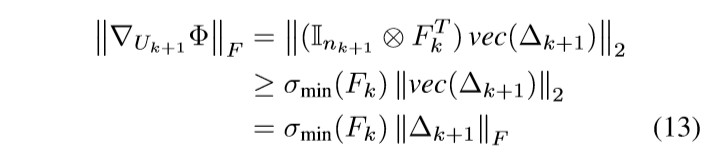
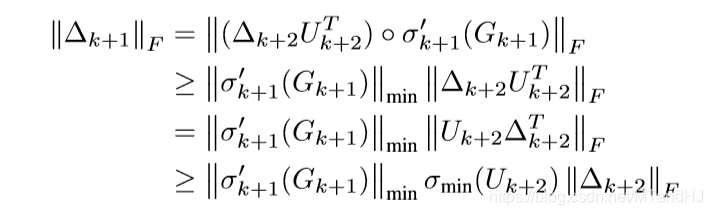
故
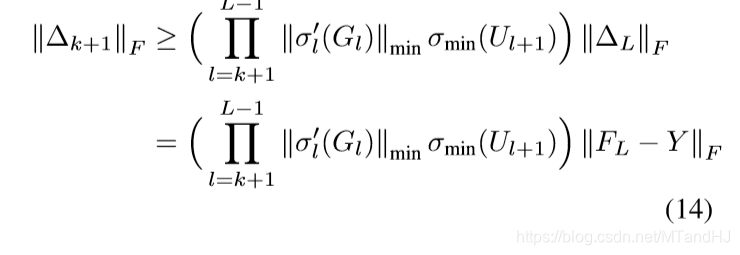
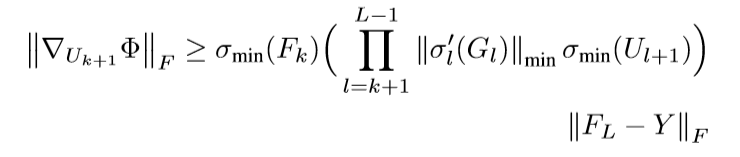
上界的证明是类似的,
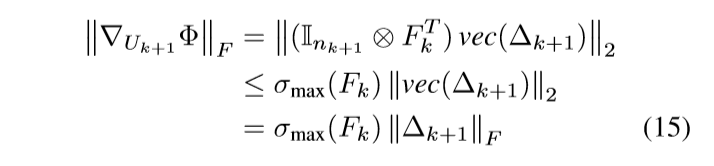
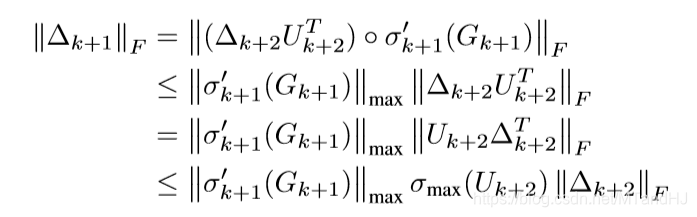
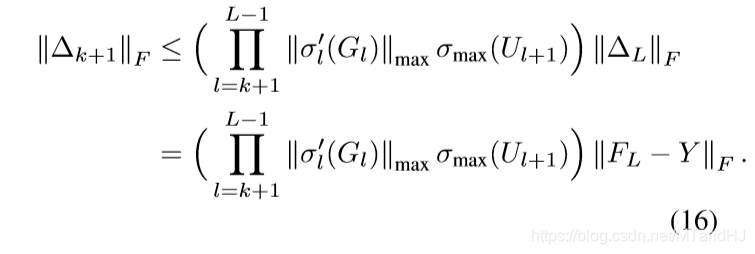
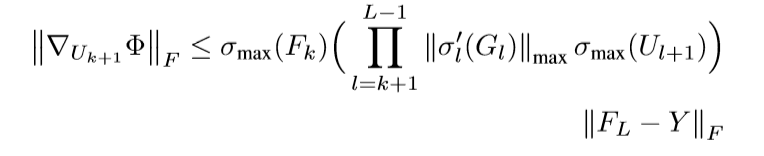
定理4.5
定理4.5前半部分的证明,既然第k+1层为全连接层,对于驻点,我们有\(\Delta_{W_{k+1}} \Phi = 0 = \nabla_{U_{k+1}} \Phi\), 再根据定理4.4即可证明.
后半部分的证明,首先,我们证明我们能够找到\(W_{k+1}\)使得\(F_{k+1}\)的秩为\(m\), 且对应相同标签的样本,比如样本i, j对应同一个标签,那么\(F_{k+1}\)的第i,j行是相同的. 在k+1层之前,我们可以找到\(\{W_l, b_l\}_{l=1}^k\)使得\(range(F_k)=N\).
Case1:k=L-1
那么\(rank(F_{L-1})=N\), 直接令\(W_L=F_{L-1}^T(F_{L-1}F_{L-1}^T)^{-1}Z\)就能使得\(\Phi=0\), 且\(W_L\)满秩.
Case2: k=L-2
那么\(rank(F_{L-2})=N\), 令\(A\in \R^{m \times n_{L-1}}\)为行满秩矩阵,且\(A_{ij}\in range(\sigma_{L-1})\). 再定义\(D \in \R^{N \times n_{L-1}}\), 并且
\]
如果第i个样本的标签为j. \(D_{i:}\)表示\(D\)的第i行.
只需要令\(W_{L-1}=F_{L-2}^T(F_{L-2}F_{L-2}^T)^{-1}\sigma_{L-1}^{-1}(D)\), 于是
\]
其中令\(b_{L-1}=0\).
接着,我们只需要令
\]
便能得到\(\Phi=0\).
注意,\(W_{L-1}\)并非满秩的.
Case 3: \(k \le L-3\)
类似的,取\(E\in \R^{m \times n_{k+1}}\), 且\(E\)的元素无一相同, \(E_{ij} \in range(\sigma_{k+1})\).
定义\(D \in \R^{N \times n_{k+1}}\):
\]
如果样本i标签为j.
构建
\]
取\(b_{k+1}=0\), 则\(F_{k+1}=\sigma_{k+1}(F_kW_{k+1}+\mathbf{1_N}b_{k+1}^T)=D\), 于是我们的目的也达到了.
此时,把\(k+1\)到\(L\)看成一个新的网络,我们相当于输入\(m\)个样本,我们只要构建\(\{W_l\}_{l=k+2}^L\)使得\(\Phi=0\), 根据Case 1可知,只要在第L-1层保持满秩即可.
首先,因为\(E\)的各元素都不同,所以\(F_{k+1}\)的各元素亦不同,这就满足了假设3.1;
其次,\(k+1\)到\(L-1\)都是卷积层和全连接层;
第L-1层的宽度大于样本个数m,这个来源于假设4.1的金字塔型的结构;
激活函数满足假设3.2.
所以,根据定理3.4,我们可以知道,存在\(\{W_l\}_{l=k+2}^L\)能够使得L-1层满秩,而且这样的参数是很多很多的.
最后选择\(W_L=F_{L-1}^T(F_{L-1}F_{L-1}^T)^{-1}Z\)即可. \((W_l, b_l)_{l=1}^L \in S_k\).
Optimization Landscape and Expressivity of DeepCNNs的更多相关文章
- 『计算机视觉』各种Normalization层辨析
『教程』Batch Normalization 层介绍 知乎:详解深度学习中的Normalization,BN/LN/WN 一.两个概念 独立同分布(independent and identical ...
- zz姚班天才少年鬲融凭非凸优化研究成果获得斯隆研究奖
姚班天才少年鬲融凭非凸优化研究成果获得斯隆研究奖 近日,美国艾尔弗·斯隆基金会(The Alfred P. Sloan Foundation)公布了2019年斯隆研究奖(Sloan Research ...
- Gradient Centralization: 简单的梯度中心化,一行代码加速训练并提升泛化能力 | ECCV 2020 Oral
梯度中心化GC对权值梯度进行零均值化,能够使得网络的训练更加稳定,并且能提高网络的泛化能力,算法思路简单,论文的理论分析十分充分,能够很好地解释GC的作用原理 来源:晓飞的算法工程笔记 公众号 论 ...
- 第七章:网络优化与正则化(Part2)
文章相关 1 第七章:网络优化与正则化(Part1) 2 第七章:网络优化与正则化(Part2) 7.3 参数初始化 神经网络的参数学习是一个非凸优化问题.当使用梯度下降法来进行优化网络参数时,参数初 ...
- 第七章:网络优化与正则化(Part1)
任何数学技巧都不能弥补信息的缺失. --科尼利厄斯·兰佐斯(Cornelius Lanczos) 匈牙利数学家.物理学家 文章相关 1 第七章:网络优化与正则化(Part1) 2 第七章:网络优化与正 ...
- Loss Landscape Sightseeing with Multi-Point Optimization
目录 概 主要内容 代码 Skorokhodov I, Burtsev M. Loss Landscape Sightseeing with Multi-Point Optimization.[J]. ...
- Coursera Deep Learning 2 Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week2, Assignment(Optimization Methods)
声明:所有内容来自coursera,作为个人学习笔记记录在这里. 请不要ctrl+c/ctrl+v作业. Optimization Methods Until now, you've always u ...
- 课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第二周(Optimization algorithms) —— 2.Programming assignments:Optimization
Optimization Welcome to the optimization's programming assignment of the hyper-parameters tuning spe ...
- 改善深层神经网络-week2编程题(Optimization Methods)
1. Optimization Methods Gradient descent goes "downhill" on a cost function \(J\). Think o ...
随机推荐
- A Child's History of England.25
It was a September morning, and the sun was rising, when the King was awakened from slumber by the s ...
- nodeJs-process对象
JavaScript 标准参考教程(alpha) 草稿二:Node.js process对象 GitHub TOP process对象 来自<JavaScript 标准参考教程(alpha)&g ...
- iOS11&IPhoneX适配
1.在iOS 11中,会默认开启获取的一个估算值来获取一个大体的空间大小,导致不能正常显示,可以选择关闭.目前尝试在delegate中处理不能很好的解决,不过可以直接设置: Swift if #ava ...
- 链式栈——Java实现
1 package struct; 2 3 //接口 4 interface ILinkStack{ 5 //栈中元素个数(栈大小) 6 int size(); 7 //取栈顶元素 8 Object ...
- Shell脚本实现自动修改IP地址
作为一名Linux SA,日常运维中很多地方都会用到脚本,而服务器的ip一般采用静态ip或者MAC绑定,当然后者比较操作起来相对繁琐,而前者我们可以设置主机名.ip信息.网关等配置.修改成特定的主机名 ...
- Spring Cloud 和dubbo
一.SpringCloud微服务技术简介 Spring Cloud 作为Java 语言的微服务框架,它依赖于Spring Boot,有快速开发.持续交付和容易部署等特点.Spring Cloud 的组 ...
- 匿名内部类与lamda表达式
1.为什么要使用lamda表达式 从JDK1.8开始为了简化使用者进行代码开发,专门提供有Lambda表达式的支持,利用此操作形式可以实现函数式的编程,对于函数式编程比较著名的语言:haskell,S ...
- 07-Spring5 WebFlux响应式编程
SpringWebFlux介绍 简介 SpringWebFlux是Spring5添加的新模块,用于Web开发,功能和SpringMvc类似的,WebFlux使用当前一种比较流行的响应式编程框架 使用传 ...
- 3、Spring的DI依赖注入
一.DI介绍 1.DI介绍 依赖注入,应用程序运行依赖的资源由Spring为其提供,资源进入应用程序的方式称为注入. Spring容器管理容器中Bean之间的依赖关系,Spring使用一种被称为&qu ...
- 为什么在集合中不能使用int关键字作为类型
解释: 1.Int是基本数据类型,Integer是Int的引用类型,定义集合的时候不能使用基本数据类型,需要使用对应的引用类型 2.int是基本数据类型,Integer是他的包装类,包装类主要用在类型 ...