Representation Learning with Contrastive Predictive Coding
@article{den oord2018representation,
title={Representation Learning with Contrastive Predictive Coding.},
author={Den Oord, Aaron Van and Li, Yazhe and Vinyals, Oriol},
journal={arXiv: Learning},
year={2018}}
@article{henaff2019data-efficient,
title={Data-Efficient Image Recognition with Contrastive Predictive Coding},
author={Henaff, Olivier J and Srinivas, Aravind and De Fauw, Jeffrey and Razavi, Ali and Doersch, Carl and Eslami, S M Ali and Den Oord, Aaron Van},
journal={arXiv: Computer Vision and Pattern Recognition},
year={2019}}
概
与其说是无监督, 不如用表示学习或者特征提取更为贴切. 感觉监督学习的一个瓶颈就是, 你直接告诉了神经网络它应该到达的终点, 那么它就会找一条最容易的路子去, 所以在训练中, 可以发现训练的精度很快就能达到100%, 而在测试集上的精度就差强人意了. 当然, 这错不在网络, 毕竟它已经尽可能地完成了我们交代给他的任务, 困难在于, 我们自己不知道该如何给这种兼顾泛化性的任务下达准确的定义(平移不变, 旋转不变等等只是泛化的冰山一角).
而表示学习的工作实际上就是比简单的分类损失等更具打磨的空间, 不同的先验知识可以融入其中. 这篇论文的观点就是, encoder提取的特征应当具有可预测性, 也就是说, 只有能够预测别的特征的才是好特征. 当然, 这个是对具有序(时域或者空间)的数据有意义, 对于图片可以认为构造这种数据, 个人认为这才是有趣的地方.
主要内容
从具有序的数据讲起
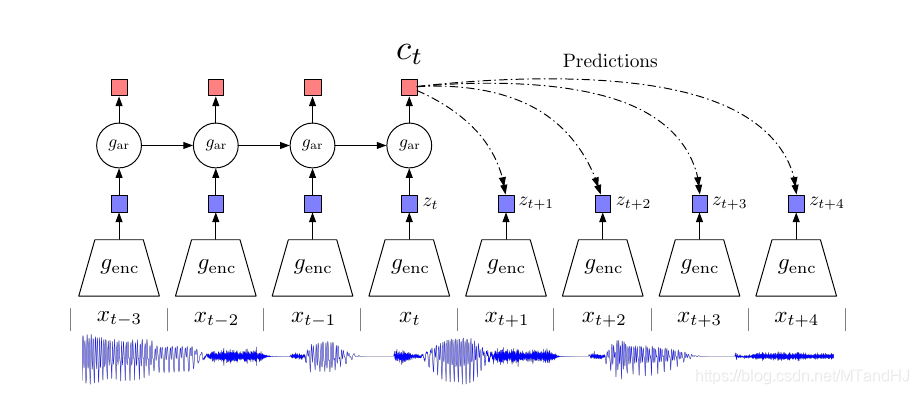
如上图, 在不同的时间点, 有数据\(x_t\), 其经过第一个encoder \(g_{\mathrm{enc}}\)得到隐变量(特征表示)\(z_t\). 到此打住, 如果是以前, 那可能再来一个decoder, 然后希望解码后数据和原始数据能够吻合. 不过作者认为, 这种方式有点太过勉强了, 其实一个好的特征并不是既低维度(高能量密度)又能够藏住大部分的信息, 一个好的特征应该是抓住最最最主要的信息, 如果是用于分类, 那就是抓住最具有区分度的信息(虽然这个很难下准确的定义).
作者的做法是, 将\(z_i, i\le t\)作为输入, 构造一个回归模型\(g_{\mathrm{ar}}\)(比如用RNN), 得到一个实际上具有之前数据信息的一个特征表示\(c_t\). 作者希望利用\(c_t\)来预测之后的\(x_{t+1},\ldots, x_{t+k},\ldots\), 或者\(z_{t+1},\ldots, z_{t+k},\ldots\), 自然最好的是有一个条件概率模型\(p(x_{t+k}|c_t)\), 然后最大化互信息
I(x;c)=\sum_{x,c} p(x,c)\log \frac{p(x|c)}{p(x)}.
\]
Contrastive Predictive Coding (CPC)
作者并没有打算构建条件概率模型(感觉这样就像VAE一样需要超多假设了), 只是用
f_k(x_{t+k}, c_t)=\exp(z_{t+k}^TW_kc_t),
\]
来衡量二者的关系, 可以把\(W_kc_t\)看成是一个预测\(\hat{z}_{t+k}\).
接下来就要用到对比学习的概念了, 文中说是利用了负样本采样, 但是我用负样本采样的那个推导实在推不出来他的函数, 但是是有一点类似的(感觉只是套用了负采样这个思想?). 即从\(p(x_{t+k}|c_t)\)中采样正样本\(x_{t+k}\), 从一般的分布\(p(x)\)中采样N-1个负样本\(x_j\), 然后最小化下式
\mathcal{L}_N=- \mathbb{E}_X [\log \frac{f_k(x_{t+k},c_t)}{\sum_{x_j \in X} f_k(x_j,c_t)}].
\]
其中\(X=\{x_1,\ldots, x_N\}\)(注, 这里\(X\)是固定的, 已知的).
把\(\frac{f_k(x_i,c_t)}{\sum_{x_j \in X} f_k(x_j,c_t)}\)看成是第\(i\)个采样点是正样本的概率\(\hat{p}_i,i=1, \ldots,N\), 则上面的式子实际上就是一个交叉熵
\]
故令损失最小的概率为\(\hat{p}_i=p_i:=p(d=i|X, c_t)\), 即正样本在第\(i\)个位置的概率. 又
p(d=i|X, c_t)
& = \frac{p(x_i|c_t) \prod_{l\not= i} p(x_l)}{\sum_{j=1}^N p(x_j|c_t)\prod_{l\not= j}p(x_j)} \\
&= \frac{\frac{p(x_i|c_t)}{p(x_i)}}{\sum_{j=1}^N\frac{p(x_j|c_t)}{p(x_j)} }.
\end{array}
\]
也就是说, 此时
\]
图片构建序

如图所示, 一张256x256的图片, 均匀分成7x7张, 每张大小为64x64, 两者最多有50%的重叠部分. 从上到下, 从左往右, 依次可以对其排序, 用前几行的patches出来的\(z\)来预测后面的\(z\).
疑问: 这个负样本的采样空间, 是一个图片所有的patches还是一个batch的所以的patches呢?
Representation Learning with Contrastive Predictive Coding的更多相关文章
- 论文解读(SUGRL)《Simple Unsupervised Graph Representation Learning》
Paper Information Title:Simple Unsupervised Graph Representation LearningAuthors: Yujie Mo.Liang Pen ...
- (转)Predictive learning vs. representation learning 预测学习 与 表示学习
Predictive learning vs. representation learning 预测学习 与 表示学习 When you take a machine learning class, ...
- PredNet --- Deep Predictive coding networks for video prediction and unsupervised learning --- 论文笔记
PredNet --- Deep Predictive coding networks for video prediction and unsupervised learning ICLR 20 ...
- 论文解读(MVGRL)Contrastive Multi-View Representation Learning on Graphs
Paper Information 论文标题:Contrastive Multi-View Representation Learning on Graphs论文作者:Kaveh Hassani .A ...
- 论文解读(GRACE)《Deep Graph Contrastive Representation Learning》
Paper Information 论文标题:Deep Graph Contrastive Representation Learning论文作者:Yanqiao Zhu, Yichen Xu, Fe ...
- 论文解读(S^3-CL)《Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learning》
论文信息 论文标题:Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learn ...
- 论文解读(MERIT)《Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning》
论文信息 论文标题:Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning ...
- 翻译 Improved Word Representation Learning with Sememes
翻译 Improved Word Representation Learning with Sememes 题目 Improved Word Representation Learning with ...
- (zhuan) Notes on Representation Learning
this blog from: https://opendatascience.com/blog/notes-on-representation-learning-1/ Notes on Repr ...
随机推荐
- 备忘录:关于.net程序连接Oracle数据库
目录 关于使用MSSM访问Oracle数据库 关于. net 程序中连接Oracle数据库 志铭-2021年12月7日 21:22:15 关于使用MSSM访问Oracle数据库 安装访问接口组件:Or ...
- JuiceFS 性能评估指南
JuiceFS 是一款面向云原生环境设计的高性能 POSIX 文件系统,任何存入 JuiceFS 的数据都会按照一定规则拆分成数据块存入对象存储(如 Amazon S3),相对应的元数据则持久化在独立 ...
- 【leetcode】797. All Paths From Source to Target
Given a directed acyclic graph (DAG) of n nodes labeled from 0 to n - 1, find all possible paths fro ...
- c++string转const char*与char*
#include <iostream> #include <string> #include <memory> using namespace std; const ...
- Linux基础命令---sendmail发送邮件
sendmail sendmail是postfix中的一个发送邮件的代理程序,它负责发送邮件到远程服务器,并且可以接收邮件.sendmail在发送邮件的时候,默认从标砖输入读取内容,以".& ...
- ASP.NET Core中使用滑动窗口限流
滑动窗口算法用于应对请求在时间周期中分布不均匀的情况,能够更精确的应对流量变化,比较著名的应用场景就是TCP协议的流量控制,不过今天要说的是服务限流场景中的应用. 算法原理 这里假设业务需要每秒钟限流 ...
- 全网最详细的AbstractQueuedSynchronizer(AQS)源码剖析(二)资源的获取和释放
上期的<全网最详细的AbstractQueuedSynchronizer(AQS)源码剖析(一)AQS基础>中介绍了什么是AQS,以及AQS的基本结构.有了这些概念做铺垫之后,我们就可以正 ...
- centos源码安装ruby
目录 一.简介 二.程序部署 一.简介 Ruby,一种简单快捷的面向对象(面向对象程序设计)脚本语言.rvm是ruby的管理器,可以切换ruby版本,下载ruby. 二.程序部署 1.下载ruby w ...
- cmd窗口连接mongodb服务端
1----->配置环境变量,将mongodb\bin目录配置到path 2----->打开cmd窗口,进入到bin目录,测试mongodb服务端是否在运行:net start mongod ...
- UCI数据库_鸢尾花数据集的读取方式
1. 读取数据的第一种方式 [attrib1,attrib2,attrib3,attrb4,class] = textread('iris.data','%f%f%f%f%s','delimiter' ...