聊聊我对 GraphQL 的一些认知

每隔一段时间就能看到一篇 GraphQL 的文章,但是打开文章一看,基本上就是简单的介绍下 GraphQL 的特性。很多文章其实就是 github 上找个 GraphQL 的项目,然后按照对应的 demo 跑起来而已。有些文章明显是没有完整的项目实践经历,却在狂吹 GraphQL 的各种优点,让不熟悉 GraphQL 的同学以为这是神丹妙药,弄不好还要在项目中实践一番。
因为项目的背景(后面会讲到),我有幸参与过 GraphQL 在实际项目中的落地,本篇文章我会谈谈我对 GraphQL 的一些理解,当然这个也仅供读者参考。
GraphQL 优势
不知道大家有没有遇到过这样的一些场景,某个服务有几十个接口,更有甚者上百个也是有可能的。APP 或者其他下游要封装一个功能,需要调用 10 个接口左右,可能这些接口还涉及到不同的团队。不管开发,联调,测试,还是对于调用方,整个链条功能太多了。随着这些功能经过多个版本的迭代升级后,新+旧版本的接口谁也不敢大规模改动了,只能在原来的基础上做代码拼接,这基本就是祖传代码的由来。大部分同学基本的代码素养是有的,但是也只能任由这些祖传代码慢慢腐烂,原因为很简单,谁也不敢保证改动之后功能是不是有遗漏的地方。
有没有这样一个功能,将这些接口做一下聚合,然后将结果的集合返回给前端呢?在目前比较流行微服务架构体系下,有一个专门的中间层专门来处理这个事情,这个中间层叫 BFF(Backend For Frontend)。我曾经工作过的某公司想要将某业务的售卖相关功能给公司其他业务使用,但是接入方一看那么多接口,瞬间就决定不接了,逼不得已该业务平台紧急开发了 BFF 相关功能让其他业务方接入。
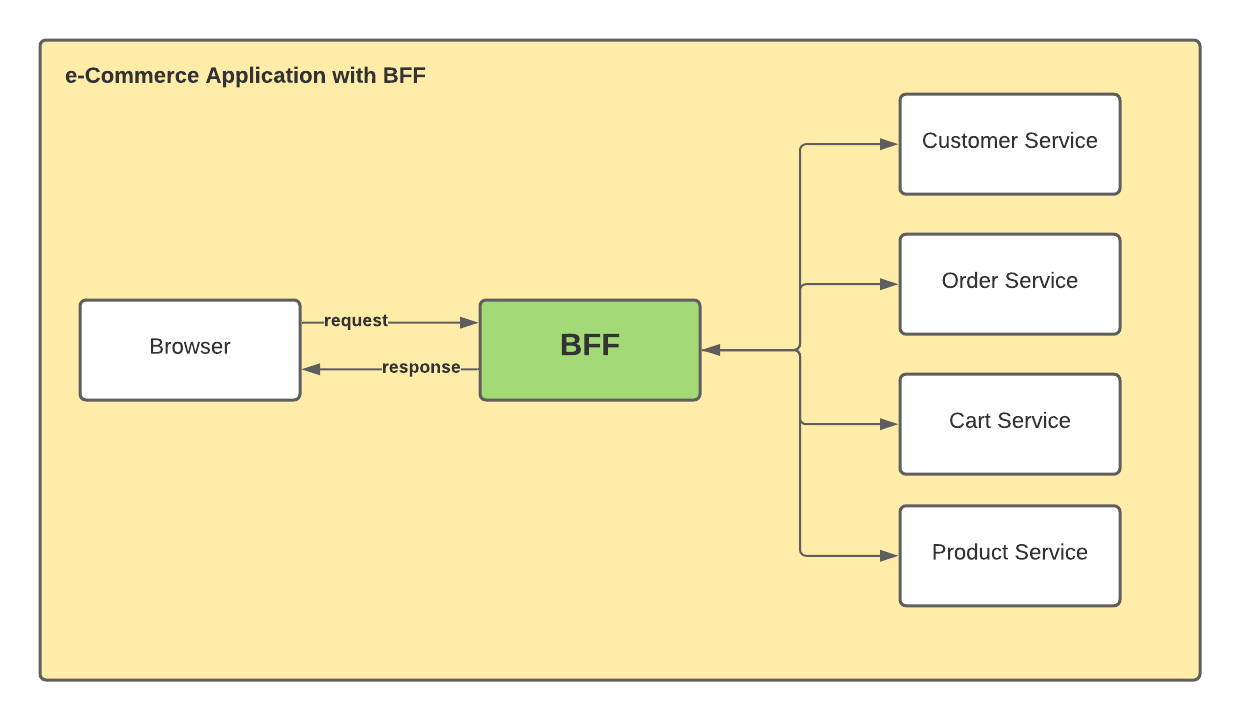
有些同学在稍微大点规模的公司做的工作就是合并各种接口,然后返回给调用方,这基本上就是 BFF 的主要工作内容了。除了类似 BFF 组建接入平台的方式,是否还有其他的方式能够只发出一个请求就能获取到一系列的接口返回值呢?
我在京东 APP 上随便截图了一个商品
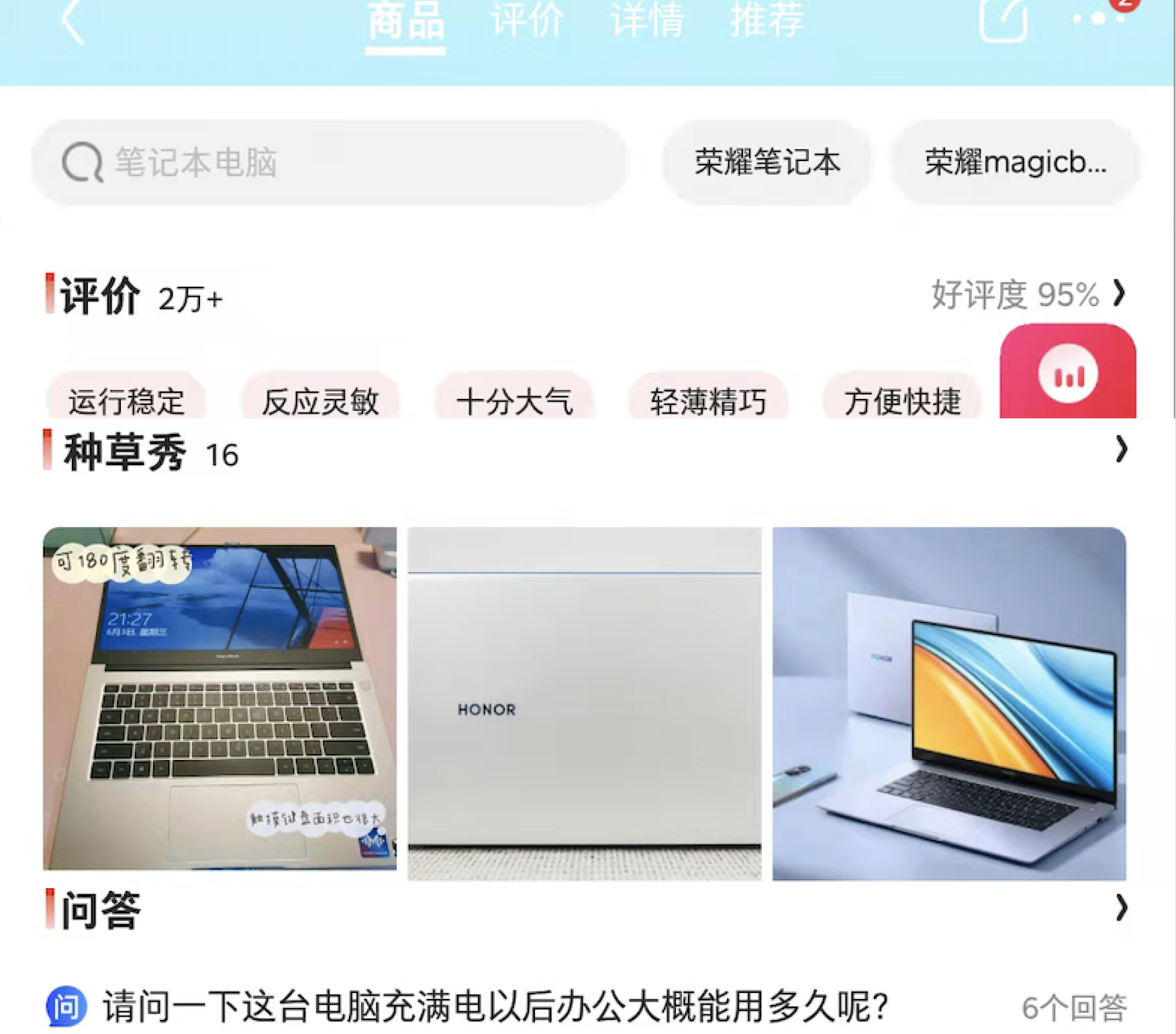
类似这个页面,当用户打开这个页面的时候,按照目前比较流行的 REST 接口,需要 APP 至少发起下面这些请求:
- 获取商品详情接口
- 获取商品价格、优惠相关的接口
- 获取评价接口
- 获取种草秀接口
- 获取问答接口
这些接口一般来说都比较重,里面有很多当前页面并不需要的字段,那有没有一种可能:APP 端发一次请求就能获取这个页面需要的所有字段,同时 APP 还能根据自己的需求只请求自己需要的字段呢?
答案是肯定的,那就是 GraphQL。
query jdGoodsQuery {
goods {
detail {
id
pictures(first: 10) {
pic_id
thumb
}
spec {
name
size
weight
}
}
price {
price
origin_price
market_price
}
comment(first: 10) {
comment_id
topic_id
content
from_uid
}
self_show(first: 10) {
id
pic_id
}
}
}
对于上面京东商品详情的截图,类似这样的一个 Query 就可以把这个页面需要的所有的字段都获取到。
对于 REST 接口还有另外一个比较棘手的问题。当业务升级的时候,接口不可避免的需要升级,一个比较常见的问题,某个字段在新版本升级后不需要了,如何优雅的处理旧接口以及旧字段呢?
可能有些同学说,可以强行推动下游去升级,限定期限进行升级,如果下游不升级概不负责,这种方式基本只能自己欺骗自己了,因为当你接口下线导致业务方报错,这个责任只能你自己负责了。特别的,当某些接口是直接面对消费者时,这个问题会变得更加棘手。
2016 年那会就职过的一家做 AI 产品的公司,上市了一款智能读书的儿童产品,其基本功能就是绘本图书翻一页读一页,这也算是 HomeAI 落地比较成功的产品了,这个产品在天猫、京东的销量还可以。在 AI 风口的那会,最开始的定位的功能就是读书,随着市场的拓展,功能也逐渐变得复杂起来,当时最痛苦的事情莫过于短短 3 个月内,接口版本号从 v1 增加到 v12。由于当时产品的理念认为强制升级是不优美的,不符合产品设计美学,导致这款产品是没有强制升级功能的,于是导致的结果是 v1 到 v12 的接口总是有用户在使用的。你可能会说发公告、短信通知用户在某个期限内升级,如果不升级,出现产品无法使用情况概不负责,这也是行不通的,特别那些用户付费的产品,如果万一不能使用的话,那 12315 是会找上门的。
就在我们被无法下线的 API 接口折磨的时候,经过调研之后发现 GraphQL 正好有一个功能,“API 演进无需划分版本”,这不是瞌睡来了就有枕头吗,于是在技术负责人带领下(GraphQL 改造项目还没上线,他去了 Microsoft),我们开始推进 GraphQL 的改造工作。
说到这里基本上就把 GraphQL 的最容易吸引人的优点介绍完了。我们要知道没有任何技术是“银弹”,当某些人给你狂吹某个技术的优点,而没有说这项技术的缺点限制,或者简略的一笔带过的时候,你就需要小心了,说不定你就是那个小白鼠。
下面就进入我经历的 GraphQL 项目遇到的问题,也许我的处理方式是不正确,以下观点仅供参考。
GraphQL 难题
社区活跃度问题
GraphQL 是由 Facebook 开发,Facebook 也成立了 GraphQL 基金会,但是 Facebook 官方只提供了 JS 版本的开源实现,其他语言的实现都是 GraphQL 对应语言的非官方社区实现的,这就造成不同语言的理解和实现是有差异的。比如 Graphql schema 的合并工具,只有 JS 官方实现有对应的实现。
GraphQL 属于那种大家都觉得很不错,但是经过近 10 年的发展,依然是不温不火。

上面这个图是 GraphQL 官方的 landscape,你仔细看上面公司图标,一眼能看出来的大的公司只有 Github 了。Facebook 虽说是推出了 GraphQL 的规范以及 JS 的相关实现,但是他自己都没有放出有关 GraphQL 的实际接口,让人对这个技术的信任度都大打折扣。
当你遇到 GraphQL 问题的时候,要么搜出来全是 JS 的相关实现,要么干脆就没有人回答,总之 GraphQL 相关社区看着文档很丰富,其实遇到问题时能搜到解决问题的有用的资料并不多。
缓存问题
缓存对于 REST 接口来说是很容解决的,但是在 GraphQL 中却变得非常复杂。由于 GraphQL 的特性,即便它操作的是同一个实体,每次查询可能都各不相同。
举个例子,由于客户端可以自定义其需要的字段,如某次请求只需要某个人的名字,但是在另外一次查询中你可能也想知道他的消费积分。名字可能要查询 user.userProfile 库,而且消费积分可能要查询第三方系统。本次查询输入的是单个 user_id,下次查询输入的可能就是 userId_list 了,为了解决这些查询的缓存问题,你可能会设置很多 key 或者每个用户设置 key-value 放入缓存,这些都不是很优美的解决方案,归根到底还是因为 GraphQL 太多灵活,服务器的缓存如何设计都跟不上客户端的灵活的查询方式。
对于这个问题 Facebook 也有 DataLoader 的解决方案,当然只是 JS 版本的方案,其他语言的社区可能根本都没有对应的实现。按照我当初的调研这个东西真的不好用,还不如自己做缓存来得快。
GraphQL 缓存不只对服务端不友好,同时对客户端也是一个挑战,需要用户自己做客户端的缓存,因为 GraphQL Query 只有一个路由,而且都是 POST 方式。
网关问题
GraphQL 是强类型的,所以必须需要一个 schema 的存在。按照当初的实践经验,客户端有且只能存在一份 schema 文件,于是另外一个比较棘手的问题就出现了。
假如我们的服务是类似下图这个样子:
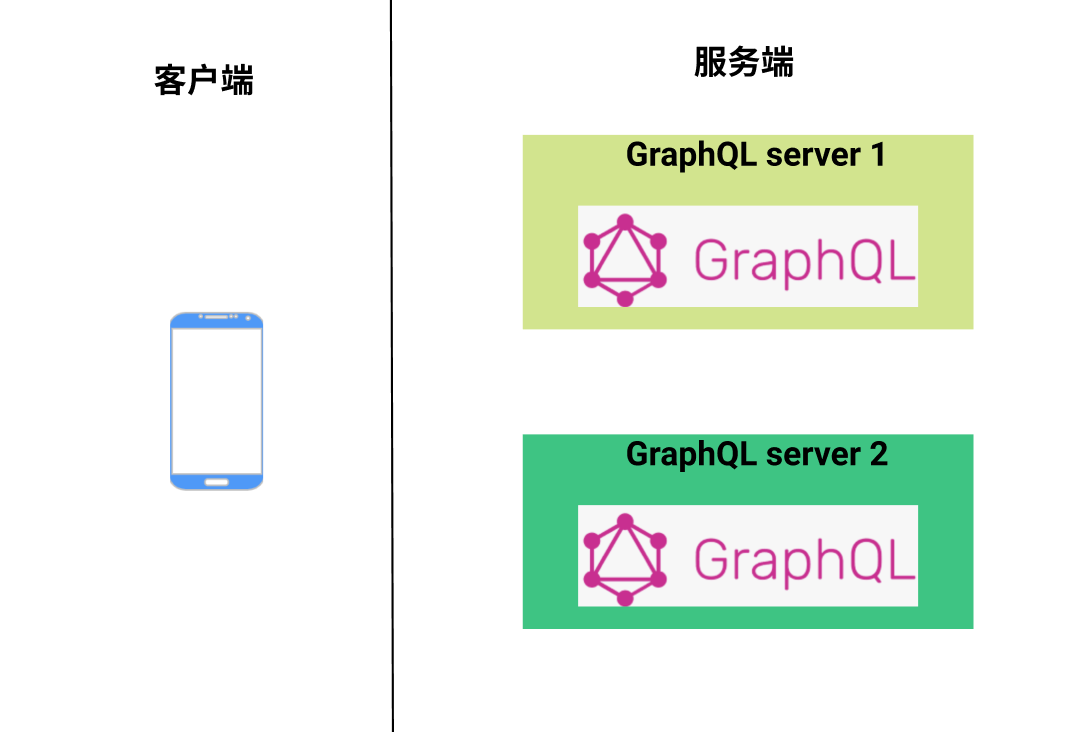
比如 server1 是商品服务,server2 是优惠服务,客户端如果要对接这两个服务的话,直接对接是不行的,因为客户端只能有一个 schema, 但是服务端却有两个 schema 文件。
这种情况该如何处理呢?当初经过调研发现 JS 提供了 schema merge 的工具,而且仅仅是个工具。其他语言压根就没有这个玩意。
这个的设计还会带来另外一个非常严重的问题,目前的 API 网关都是无法使用的。随着业务规模的扩大,走上微服务是迟早的事情,但是如果服务端全是基于 GraphQL 开发的,那么网关该如何处理呢?最近调研了下 APISIX 和 KONG 的最新版本,这两个业界有影响力的网关也仅仅是支持 GraphQL 协议的转发而已。
在我看来,在如今微服务比较流行市场下,GraphQL 唯一比较契合的场景的就是将 BFF 的 REST 换成 GraphQL,该 BFF 即做网关也做业务。其实这样做,也不是很完美,即限定了客户端只能有这一个 BFF,同时也让 BFF 变得不纯粹起来。看到美团有篇介绍 GraphQL 的实践的文章,就是让 GraphQL 做的 BFF 的相关工作,不过他们没有将 GraphQL 暴露给客户端,而是在 GraphQL 之上又包裹了一层 HTTP 接口。
复杂度问题
GraphQL 最大的好处就是客户端能按需查询,是便利了客户端,但是把问题的复杂度都移交给了服务器。服务器也不是想查就能查的,毕竟服务器也是资源限制的,不可能无限制的让客户端去索取。
query deep3 {
viewer {
albums {
songs{
author {
company {
address {
...
}
}
}
}
}
}
}
由于 GraphQL 要追求从一个类型能查到 schema 的任意类型。比如这样的查询,能无限嵌套下去,每个 Type 对服务器来说都是对应的查询,服务器肯定承受不了的。
如何限制呢?GraphQL 提出的有复杂度和深度的相关概念,但是这两个值该如何去计算,只能靠服务器开发人员的估计。于是这样的场景就经常出现,开发初期约定复杂度 1000,过了两天客户端同学找了过来要提高到 3000,全是无尽的扯皮,不管设置多少,由于客户端查询的多样性总有不够用的情形出现。而且这个复杂度、深度是全局的,不是每一个 Query 能单独配置,这样就会造成这两个值最后变得可有可无。
限流问题
限流也是 GraphQL 的最难解决的难题之一,服务端不可能没有限流的,不然服务器稳定性就保障不了。对于 REST 来说接口的路由都是固定不变的,针对于不同的 URI 做限流是很容做到的。但是 GraphQL 限流的难点在哪里呢?
query maliciousQuery {
album(id: "some-id") {
photos(first: 9999) {
album {
photos(first: 9999) {
album {
photos(first: 9999) {
album {
#... Repeat this 10000 times...
}
}
}
}
}
}
}
}
这个请求会导致什么问题呢?客户端会发起一个请求 maliciousQuery,这个请求会去查询 some-id 的 album,这个 album 获取这个相册里的最大 9999 张图片,每个图片又要查询到所属的相册,就这么无限制的嵌套下去。这样的查询,服务器根本就影响不来,上面说到的复杂度和深度其实有点用处,但是用处不大。
曾经遇到这样的真实场景,GraphQL 项目已经部署线上,复杂度和深度也配置了,客户端同学在获取商品分页列表的同时也将对应商品详情以及商品详情的级联内容给取了出来,导致的结果服务器直接 OOM。原因跟上面这个例子很相似,就是嵌套的查询过多导致的。这个问题其实跟复杂度和深度是相关的,但是复杂度和深度真的是很难评估。
所以 GraphQL 限流的难题就在于客户端只发起一次请求,但是在服务器端可能被放大无数倍。如何能够有效的评估某个值能让客户端的嵌套比较合理,根据实践经验来看,这个值不是官方提供的复杂度和深度能解决的。
不过好消息 GraphQL 提供一种评估 GraphQL 限流的方式,另外一个中文版本的理论解析解决 GraphQL 的限流难题。理论是一回事,不过实施起来依然是困难重重。
结论
本文主要介绍了我曾经经历过的 GraphQL 落地的一点感悟,距离如今也有一段时间了,GraphQL 留给我的印象就停留在这些无法解决的问题上。曾经有人咨询我想用 GraphQL 去重构某个服务,被我比较激动的给打消了这个念头。这篇文章可能也有写的不对的地方,欢迎同学们指出。

聊聊我对 GraphQL 的一些认知的更多相关文章
- 迷之自信的Single_User Mode
Alter database Set Single_User 对于任何DBA来说,恐怕都不陌生.在我们需要获取数据库独占访问权来做一些数据库紧急维护的时候,这可能是大多数DBA的首选,但它真的可以实现 ...
- 人人都是 API 设计师:我对 RESTful API、GraphQL、RPC API 的思考
原文地址:梁桂钊的博客 博客地址:http://blog.720ui.com 欢迎关注公众号:「服务端思维」.一群同频者,一起成长,一起精进,打破认知的局限性. 有一段时间没怎么写文章了,今天提笔写一 ...
- 聊聊 Linux 中的五种 IO 模型
本文转载自: http://mp.weixin.qq.com/s?__biz=MzAxODI5ODMwOA==&mid=2666538919&idx=1&sn=6013c451 ...
- 聊聊GISer的职业发展
一.前言 去年写了一篇名为<GISer们还有机会屌丝逆袭吗?>的博文,希望能和广大GISer一起探讨地理信息产业留给小团队和个人的机会.文章发布后,很多GISer通过网络和我进行了交流,其 ...
- 聊聊 iOS 开发中的协议
前言 何为协议,简单来说在OC中我们使用关键字@protocol可以声明一个协议,并在协议中添加多个属性.方法供于遵循者实现,从某个角度上来说,这是一种不同于category机制的category.在 ...
- 聊聊Unity的Gamma校正以及线性工作流
0x00 前言的前言 这篇小文其实是在清明节前后起的头,不过后来一度搁笔.一直到这周末才又想起来起的这个头还没有写完,所以还是直接用一个月前的开头,再将过程和结尾补齐. 0x01 前言 结束了在南方一 ...
- 聊聊数据库~3.SQL基础篇
上篇回顾:聊聊数据库~SQL环境篇 扩展:为用户添加新数据库的权限 PS:先使用root创建数据库,然后再授权grant all privileges on 数据库.* to 用户名@"%& ...
- 聊聊浏览器(webkit)资源加载机制
一些准备 在开始这个话题之前,我们有必要简单回顾一下 浏览器(webkit)的网页渲染过程(如果想要详细了解这个过程,可以戳我几年前写的一篇文章.): 我们知道,浏览器在渲染过程中,如遇到节点需要依赖 ...
- GraphQL学习之原理篇
前言 在上一篇文章基础篇中,我们介绍了GraphQL的语法以及类型系统,算是对GraphQL有个基本的认识.在这一篇中,我们将会介绍GraphQL的实现原理.说到原理,我们就不得不依托于GraphQL ...
随机推荐
- 一、web请求
BS架构(Browser/Server) 客户端使用统一的浏览器(Browser) 服务端(Server)基于统一的HTTP协议 流程:用户浏览器输入URL地址–>DNS域名解析出IP地址–&g ...
- mac下用clion进行sdl2游戏开发de环境搭建
1. 故事背景 想从unity转unreal了,于是要使用c++进行开发.unreal引擎那么大,每次打开,我的小本都嗡嗡嗡的,想着不如用个轻量一些的引擎先开发吧,核心代码独立出来,到时候如果真要移植 ...
- Vue.JS快速上手(指令和实例方法)
1.声明式渲染 首先,我们要知道Vue是声明式渲染,那啥是声明式渲染,我们只需要告诉程序我们想要什么结果,其他的交给程序来做.与声明式渲染相对的是命令式渲染,即命令我们的程序去做什么,程序就会跟着你的 ...
- 使用spring向service里面注入dao不成功。
因为原来的程序没有使用spring.后来加spring的时候action有个地方的new没有改!!! new了个新的实现层 不是spring管理的对象.
- VS C++ C# 混合编程
创建C++ DLL 注意,32bit和64bit之间不兼容 创建普通dll工程 设置Properties -> Configuration Properties -> General -& ...
- Kickstart部署之HTTP架构
原文转自:https://www.cnblogs.com/itzgr/p/10029527.html作者:木二 目录 一 准备 1.1 完整架构:Kickstart+DHCP+HTTP+TFTP+PX ...
- <题解>「LibreOJ NOIP Round #1」序列划分
solutions 题面loj#542 对我来说,这或许已经超出了我的能力,我,只能看题解 不知道我写完这一篇题解之后,会不会对我的构造题有一点点的帮助 让我在这类题的解决上能过有一些提升 直接说明白 ...
- Geode member发现机制
Geode member发现机制 Apache Geode 为集群和客户端服务器间提供了多种member 发现机制,具体如下: Peer Member Discovery Standalone Mem ...
- pycharm 汉化
1.首先进入pycharm,点击file,找到setting. 2.点击 plugins 搜索Chinese,找到Chinese(simplified)Language Pack EAP,点击inst ...
- 20210717 noip18
考前 从小饭桌出来正好遇到雨下到最大,有伞但还是湿透了 路上看到一个猛男搏击暴风雨 到了机房收拾了半天才开始考试 ys 他们小饭桌十分明智地在小饭桌看题,雨下小了才来 考场 状态很差. 开题,一点想法 ...