论文翻译:2021_DeepFilterNet: A Low Complexity Speech Enhancement Framework for Full-Band Audio based on Deep Filtering
论文地址:DeepFilterNet:基于深度滤波的全频带音频低复杂度语音增强框架
论文代码:https://github.com/ Rikorose/DeepFilterNet
引用:Schröter H, Rosenkranz T, Maier A. DeepFilterNet: A Low Complexity Speech Enhancement Framework for Full-Band Audio based on Deep Filtering[J]. arXiv preprint arXiv:2110.05588, 2021.
摘要
复值处理将基于深度学习的语音增强和信号提取提升到一个新的水平。通常,该过程基于应用于噪声频谱图的时频 (TF) 掩膜,而复数掩模(CM)通常比实值掩模更受青睐,因为它们能够修改相位。最近的工作提出用一个复数的滤波器代替带掩码的逐点乘法。这允许利用每个频带内的局部相关性,合并来自以前和未来时间步长的信息。
在这项工作中,我们提出了DeepFilterNet,一个利用深度过滤的两阶段语音增强框架。首先,我们使用模拟人类频率感知的 ERB 缩放增益来增强频谱包络。第二阶段采用Deep filtering 增强语音的周期性成分。除了利用语音的感知特性之外,我们还通过可分离的卷积和线性和循环层中的广泛分组来强制网络稀疏性,以设计一个低复杂度的架构。
我们进一步表明,我们的两阶段深度过滤方法在各种频率分辨率和延迟上都优于复杂的掩码,并且与其他最先进的模型相比,表现出令人信服的性能。
关键词:复数域
2 DeepfilterNet
2.1 信号模型
设$x(k)$为在嘈杂房间中录制的混合信号。
$$公式1:x(t)=s(t)*h(t)+z(t)$$
式中,$s(t)$为纯语音信号,$h(t)$为扬声器对麦克风的室内脉冲响应,$z(t)$为已包含混响环境的加性噪声信号。通常,降噪是在频域进行的
$$公式2:X(k,f)=S(k,f)·H(k,f)+Z(k,f)$$
其中$X(k,f)$是时域信号$x(t)$的STFT结果,$t$和$f$分别是时间和频率bin。
2.2 Deep Filtering
Deep Filtering被定义为 TF域的 复数滤波器:
$$公式3:Y(k, f)=\sum_{i=0}^{N} C(k, i, f) \cdot X(k-i+l, f)$$
其中$C$为应用于输入频谱$X$的滤波器阶$N$的复数系数,$Y$为增强频谱。在我们的框架中,深度滤波器应用于增益增强频谱$Y^G$。$l$是一个可选的lookahead(前瞻),如果$l\geq 1$,它允许将非因果抽头合并到线性组合中。此外,还可以在频率轴上进行过滤,允许合并相关性,例如 由于重叠频带。
为了进一步保证深度滤波只影响周期部分,我们引入了一个学习的加权因子$\alpha$来生成最终输出频谱。
$$公式4:Y^{D F}(k, f)=\alpha(k) \cdot Y^{D F^{\prime}}(k, f)+(1-\alpha(k)) \cdot Y^{G}(k, f)$$
2.3 框架概述
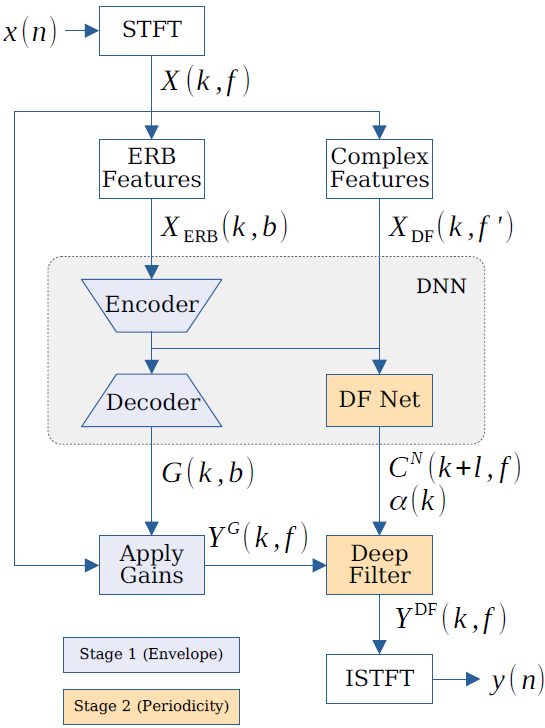
图1所示。DeepFilterNet算法概述。第1阶段用蓝色表示,第2阶段用黄色表示
DeepFilterNet 算法的概述如图 1 所示。给定一个嘈杂(noisy)的音频信号$x(t)$,我们使用短时傅立叶变换 (STFT) 将信号转换到频域。 该框架设计用于高达 48 kHz 的采样率,以支持高分辨率 VoIP 应用程序和介于 4 ms 和 30 ms 之间的 STFT 窗口大小$N_FFT$。 默认情况下,我们使用$N_{ov} = 50%$的重叠,但也支持低延迟场景的更高重叠。 我们为深度神经网络 (DNN) 使用两种输入特征。对于 ERB 编码器/解码器特征$X_{ERB}(k,b)$,$b\in [0, N_{ERB}]$,我们计算对数功率谱,使用衰减为 1 s 的指数均值归一化 [12] 对其进行归一化,并应用一个可配置的频段数$N_{ERB}的矩形 ERB 滤波器组 (FB)$。 对于深度滤波器网络特征$X_{DF}(k,f'), f'\in [0, f_{DF}],我们使用复谱作为输入,并使用具有相同衰减的指数单位归一化 [9] 对其进行归一化。
编码器/解码器体系结构用于预测ERBscale增益。利用逆ERB滤波器组将增益变换回频域,然后与噪声谱进行点向相乘。为了进一步增强周期分量,DeepFilterNet预测每频带滤波器系数CN的阶数。我们只使用频率$f_{DF}$的深度滤波,假设周期分量包含较低频率的大部分能量。
再加上卷积层的DNN前向和深度滤波器前向,得到整体延迟为$l_{N_{FT}}+l_{N_{ov}}+max(l_{DNN}, l_{DF})$导致的最小延迟为5毫秒。
2.4 DNN模型
我们专注于设计一个只使用标准DNN层(如卷积、批处理归一化、ReLU等)的高效DNN,这样我们就可以利用层融合以及推理框架的良好支持。我们采用类似于[13,7]的UNet架构,如图2所示。我们的卷积块包含一个可分离的卷积(深度卷积后是1x1卷积),核大小为(3x2), C = 64个通道,然后是批归一化和ReLU激活。卷积层在时间上对齐,这样第一层可以引入一个整体的lookkaahead $l_{DNN}$。我们在线性和GRU层中大量使用分组[14,13]。也就是说,将层输入分成P = 8组,产生P个较小的GRUs/线性层,隐藏大小为512/P = 64。输出被shuffle以恢复组间相关性,并再次concatenated到完全隐藏的大小。带有addskip的卷积pathways(通路)[13,7]用于保持频率分辨率。我们为DF Net使用了一个全局路径跳过连接,以在输出层提供原始噪声相位的良好表示。
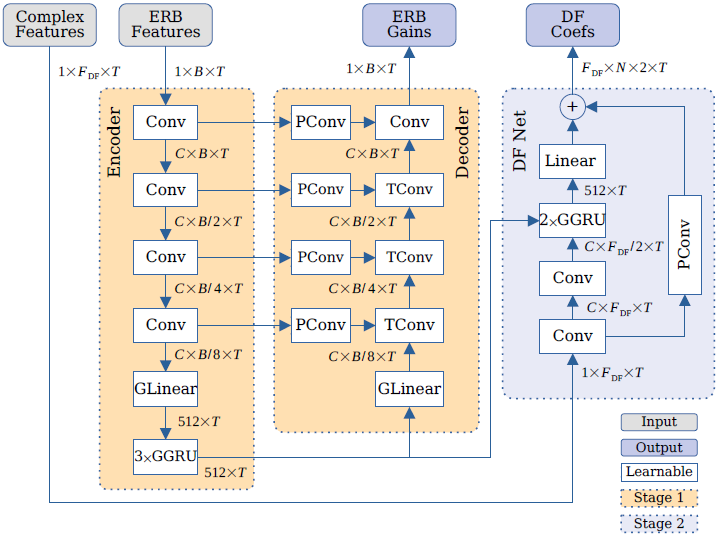
图2所示。DeepFilterNet架构概述
我们使用1x1路径卷积(PConv)作为add-skip连接和转置卷积块(TConv),类似于编码器块
利用分组线性和GRU (GLinear, GGRU)引入稀疏性
2.5 数据处理
DeepFilterNet框架利用了大量的动态增强。我们在信噪比(SNR)为{5,0,5,10,20,40}dB的情况下,将一个纯净的语音信号与多达5个噪声信号混合。为了进一步增加变量,我们使用[1]、EQs和{6,0,6}dB的二阶滤波器增强语音和噪声信号。随机重采样增加了音高的变化,采用室内脉冲响应(RIR)模拟混响环境。如果语音信号的采样率低于当前模型的采样率,则在混合前对噪声信号应用低通滤波器。例如,这也允许在全频带音频(48 kHz)上训练的模型在较低采样率的输入信号上表现同样良好。我们进一步支持训练衰减有限模型。因此,我们生成一个噪声目标信号$s$,它的信噪比 比 噪声信号$x$高6到20 dB。在训练过程中,我们对预测增益G进行钳子,并有一个噪声目标$s$,DF Net将学会不去除比指定更多的噪声。这对可穿戴设备很有用,因为我们想让用户保持一定的环境意识(识别自己身处的环境)。
2.6 损失函数
提供理想的DF系数$C^N$并非易事,因为有无限多的可能性[8]。相反,我们使用压缩谱损失来隐式学习ERB增益$G$和滤波器系数$C^N$[15,13]。相反,我们使用压缩(compressed)频谱损失来隐式学习ERB增益$G$和滤波器系数$C^N$[15,13]。
$$公式5:\mathcal{L}_{s p e c}=\sum_{k, f}\left\||Y|^{c}-|S|^{c}\right\|^{2}+\sum_{k, f}\left\||Y|^{c} e^{j \varphi_{Y}}-|S|^{c} e^{j \varphi_{S}}\right\|^{2}$$
其中,$c=0.6$是建模感知响度的压缩因子[16]。由于具有幅值和相位感知项,使得该损失既适用于建模实值增益,也适用于复数DF系数预测。为了使幅值接近于零的TF bin的梯度变硬(例如,对于采样率较低的输入信号),我们计算φX的向后角度方法,如下所示:
$$公式6:\frac{\delta \varphi}{\delta X}=\delta X \cdot\left(\frac{-\Im\{X\}}{\left|X_{h}\right|^{2}}, \frac{\Re\{X\}}{\left|X_{h}\right|^{2}}\right)$$
式中$\Re\{X\}$和$\Im\{X\}$表示频谱X的实部和虚部,$|X_h|^2=max(\Re\{X\}^2+\Im\{X\}^2,1e^{-12})$平方数量级以避免被0除。
作为额外的损失项,我们强制DF分量只增强信号的周期性部分。动机如下。对于只有噪音的部分,DF不提供任何优于ERB增益的好处。DF甚至可能通过对周期性噪声(如发动机噪声或巴布噪声)进行建模而产生伪影,这在衰减受限模型中最为明显。此外,对于只有随机成分的语音,如摩擦音或爆破音,DF没有任何好处。假设,这些部分包含大部分的高频率能量,我们计算低于$f_{DF}$频率的局部SNR。因此,$L_{\alpha}$由下式给出:
$$公式7:\mathcal{L}_{\alpha}=\sum_{k}\left\|\alpha \cdot \mathbb{1}_{\mathrm{LSNR}<-10 \mathrm{~dB}}\right\|^{2}+\sum_{k}\left\|(1-\alpha) \cdot \mathbb{1}_{\mathrm{LSNR}>-5 \mathrm{~dB}}\right\|^{2},$$
其中,当局部信噪比(LSNR)小于10 dB时,$\mathbb{I}_{\text {LSNR }}<-10 \mathrm{~dB}$为值为1的特征函数;当局部信噪比大于-5 dB时,$\mathbb{I}_{\text {LSNR }}>-5 \mathrm{~dB}$为1。在20ms窗口范围内,在频域中计算LSNR。综合损失由
$$公式8:\mathcal{L}=\lambda_{\text {spec }} \cdot \mathcal{L}_{\text {spec }}(Y, S)+\lambda_{\alpha} \cdot \mathcal{L}_{\alpha}$$
3 实验
3.1 训练步骤
我们基于深度噪声抑制(DNS)挑战数据集[10]训练我们的模型,该数据集包含超过750小时的全频带纯净语音和180小时的各种噪声类型。除了提供的在16 kHz采样的RIR外,我们使用image source模型[17]模拟了另外10 000个在48 kHz采样的RIR。我们将数据集分为train/validation/test(70/15/15%)。根据验证损失应用早期停止,结果在测试集中报告。Voice Bank/DEMAND测试集[18]用于比较DeepFilterNet与相关工作,如DCCRN(+)[11,7]和PercepNet[2]。
所有实验都使用采样率为48khz的全频带信号。我们取$N_{NRB}$= 32,$f_{DF}$ = 5 kHz,DF阶数N = 5,对DF和DNN卷积都取$l=1$帧。我们用一个初始学习率为$1*10^{-3}$的adam优化器,训练我们的模型在3 s样本和32个batch的30个epoch。学习率每3个epoch衰减0.9。损耗参数为$\lambda_{spec} = 1$和$\lambda_\alpha = 0.05$。框架的源代码可以在 https://github.com/Rikorose/DeepFilterNet 获得。
3.2 结果
我们评估了我们的框架在多种FFT大小上的性能,并基于尺度不变的信号失真率(SI-SDR)比较了DF和CRM的性能[19]。CRM是DF的特例,阶数$N=1$,look-ahead $l=0$。DNN前瞻对于CRM模型保持不变。
图3显示,在5 ms到30 ms的所有FFT大小中,DF都优于CRM。由于受到频率分辨率的限制,当FFT窗口大小为20 ms时,CRMs的性能会下降。另一方面,由于相邻帧间的相关性较小,DF相对恒定的性能下降了约30 ms。对于低延迟场景,将FFT重叠提高到75%会使DF和CRM的性能略有提高(输入SNR为0时,性能为+0.6 dB SI-SNR)。这种性能的提高可以解释为更高的帧内相关性,以及DNN更新RNN隐藏状态的步骤增加了一倍,但计算复杂度增加了一倍。图4给出了一个定性的例子,说明了DF重构噪声谱图中难以区分的语音谐波的能力。
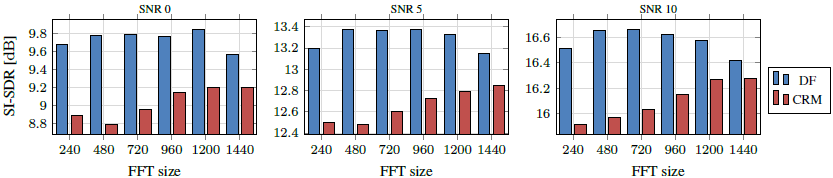
图3所示。深度滤波(DF)和常规复比掩模(CRM)在5 ~ 30 ms的多个FFT尺寸上的比较
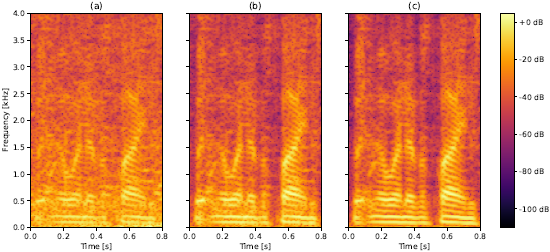
图4所示 来自Voice Bank测试集的样本。噪声(a), CRM增强(b), DF增强(c) (CRM和DF的NFFT = 960)
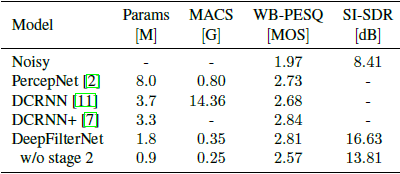
我们比较了使用NFFT=960 (20 ms)的DeepFilterNet和相关的工作,如PercepNet[2],它使用类似的感知方法,以及DCRNN+[7],它也使用深度滤波器。我们使用WB-PESSQ[20]评估语音增强的质量,并比较每秒乘法和累积(MACS)的计算复杂度。表1显示,DeepFilterNet优于PercepNet,性能与DCRNN+相当,同时具有更低的计算复杂度,使DeepFilterNet能够用于实时使用。
表1 Voice Bank/REMAND测试集的客观结果
4 结论
在这项工作中,我们提出了DeepFilterNet,一个低复杂度的语音增强框架。我们证明了深度过滤网的性能与其他算法相当,而计算量要求要低得多。我们进一步提供了深度过滤优于CRM的证据,特别是在较小的STF窗口大小的情况下。
5 参考文献
[1] Jean-Marc Valin, A hybrid DSP/deep learning approach to real-time full-band speech enhancement, in 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP). IEEE, 2018, pp. 1 5.
[2] Jean-Marc Valin, Umut Isik, Neerad Phansalkar, Ritwik Giri, Karim Helwani, and Arvindh Krishnaswamy, A Perceptually-Motivated Approach for Low-Complexity, Real-Time Enhancement of Fullband Speech, in INTERSPEECH 2020, 2020.
[3] Xu Zhang, Xinlei Ren, Xiguang Zheng, Lianwu Chen, Chen Zhang, Liang Guo, and Bing Yu, Low-Delay Speech Enhancement Using Perceptually Motivated Target and Loss, in Proc. Interspeech 2021, 2021, pp. 2826 2830.
[4] Donald S Williamson, Monaural speech separation using a phase-aware deep denoising auto encoder, in 2018 IEEE 28th International Workshop on Machine Learning for Signal Processing (MLSP). IEEE, 2018, pp. 1 6.
[5] Ke Tan and DeLiang Wang, Complex spectral mapping with a convolutional recurrent network for monaural speech enhancement, in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 6865 6869.
[6] Jonathan Le Roux, Gordon Wichern, Shinji Watanabe, Andy Sarroff, and John R Hershey, Phasebook and friends: Leveraging discrete representations for source separation, IEEE Journal of Selected Topics in Signal Processing, vol. 13, no. 2, pp. 370 382, 2019.
[7] Shubo Lv, Yanxin Hu, Shimin Zhang, and Lei Xie, DCCRN+: Channel-wise Subband DCCRN with SNR Estimation for Speech Enhancement, in INTERSPEECH, 2021.
[8] Wolfgang Mack and Emanu el AP Habets, Deep Filtering: Signal Extraction and Reconstruction Using Complex Time-Frequency Filters, IEEE Signal Processing Letters, vol. 27, pp. 61 65, 2020.
[9] Hendrik Schr oter, Tobias Rosenkranz, Alberto Escalante Banuelos, Marc Aubreville, and Andreas Maier, CLCNet: Deep learning-based noise reduction for hearing aids using complex linear coding, in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020.
[10] Chandan KA Reddy, Harishchandra Dubey, Kazuhito Koishida, Arun Nair, Vishak Gopal, Ross Cutler, Sebastian Braun, Hannes Gamper, Robert Aichner, and Sriram Srinivasan, INTERSPEECH 2021 Deep Noise Suppression Challenge, in INTERSPEECH, 2021.
[11] Yanxin Hu, Yun Liu, Shubo Lv, Mengtao Xing, Shimin Zhang, Yihui Fu, Jian Wu, Bihong Zhang, and Lei Xie, DCCRN: Deep complex convolution recurrent network for phase-aware speech enhancement, in INTERSPEECH, 2020.
[12] Hendrik Schr oter, Tobias Rosenkranz, Alberto N. Escalante-B. , Pascal Zobel, and Andreas Maier, Lightweight Online Noise Reduction on Embedded Devices using Hierarchical Recurrent Neural Networks, in INTERSPEECH 2020, 2020.
[13] Sebastian Braun, Hannes Gamper, Chandan KA Reddy, and Ivan Tashev, Towards efficient models for real-time deep noise suppression, in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 656 660.
[14] Ke Tan and DeLiangWang, Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 380 390, 2019.
[15] Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T Freeman, and Michael Rubinstein, Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation, ACM Transactions on Graphics (TOG), vol. 37, no. 4, pp. 1 11, 2018.
[16] Jean-Marc Valin, Srikanth Tenneti, Karim Helwani, Umut Isik, and Arvindh Krishnaswamy, Low- Complexity, Real-Time Joint Neural Echo Control and Speech Enhancement Based On PercepNet, in 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021.
[17] Emanu el AP Habets and Sharon Gannot, Generating sensor signals in isotropic noise fields, The Journal of the Acoustical Society of America, vol. 122, no. 6, pp. 3464 3470, 2007.
[18] Cassia Valentini-Botinhao, Xin Wang, Shinji Takaki, and Junichi Yamagishi, Investigating RNN-based speech enhancement methods for noise-robust Text-to- Speech, in SSW, 2016, pp. 146 152.
[19] Jonathan Le Roux, Scott Wisdom, Hakan Erdogan, and John R Hershey, SDR half-baked or well done? , in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 626 630.
[20] ITU, Wideband extension to Recommendation P.862 for the assessment of wideband telephone networks and speech codecs, ITU-T Recommendation P.862.2, 2007.
论文翻译:2021_DeepFilterNet: A Low Complexity Speech Enhancement Framework for Full-Band Audio based on Deep Filtering的更多相关文章
- 论文翻译:2020_TinyLSTMs: Efficient Neural Speech Enhancement for Hearing Aids
论文地址:TinyLSTMs:助听器的高效神经语音增强 音频地址:https://github.com/Bose/efficient-neural-speech-enhancement 引用格式:Fe ...
- 【论文:麦克风阵列增强】Speech Enhancement Based on the General Transfer Function GSC and Postfiltering
作者:桂. 时间:2017-06-06 16:10:47 链接:http://www.cnblogs.com/xingshansi/p/6951494.html 原文链接:http://pan.ba ...
- 论文翻译:2020_WaveCRN: An efficient convolutional recurrent neural network for end-to-end speech enhancement
论文地址:用于端到端语音增强的卷积递归神经网络 论文代码:https://github.com/aleXiehta/WaveCRN 引用格式:Hsieh T A, Wang H M, Lu X, et ...
- 论文翻译:2020_A Recursive Network with Dynamic Attention for Monaural Speech Enhancement
论文地址:基于动态注意的递归网络单耳语音增强 论文代码:https://github.com/Andong-Li-speech/DARCN 引用格式:Li, A., Zheng, C., Fan, C ...
- 论文翻译:2020_Acoustic Echo Cancellation Challenge Datasets And Testingframework
论文地址:ICASSP 2021声学回声消除挑战:数据集和测试框架 代码地址:https://github.com/microsoft/DNS-Challenge 主页:https://aec-cha ...
- 论文翻译:2021_Acoustic Echo Cancellation with Cross-Domain Learning
论文地址:https://graz.pure.elsevier.com/en/publications/acoustic-echo-cancellation-with-cross-domain-lea ...
- 论文翻译:2021_Performance optimizations on deep noise suppression models
论文地址:深度噪声抑制模型的性能优化 引用格式:Chee J, Braun S, Gopal V, et al. Performance optimizations on deep noise sup ...
- 论文翻译:Fullsubnet: A Full-Band And Sub-Band Fusion Model For Real-Time Single-Channel Speech Enhancement
论文作者:Xiang Hao, Xiangdong Su, Radu Horaud, and Xiaofei Li 翻译作者:凌逆战 论文地址:Fullsubnet:实时单通道语音增强的全频带和子频带 ...
- 论文翻译:Speech Enhancement Based on the General Transfer Function GSC and Postfiltering
论文地址:基于通用传递函数GSC和后置滤波的语音增强 博客作者:凌逆战 博客地址:https://www.cnblogs.com/LXP-Never/p/12232341.html 摘要 在语音增强应 ...
随机推荐
- 【进阶】uniapp复现微信相册功能之【图视频编辑 + 压缩】
基于uniapp + vue实现微信相册,在实现了微信相册的基础上增加以下功能 1: 图片编辑 2: 视频编辑 3: 文件压缩 技术实现 开发环境:HbuilderX + nodejs 技术框架:un ...
- 金智维RPA培训(一)产品基础架构-RPA学习天地
1.产品组成分为:Server,control,agent三个组件,支持CS和BS架构.独有的中继服务器可以解决跨网段的问题,这里应该还是采用了多网卡模式. 其中:Agent负责对流程的执行工作.Co ...
- java源码——计算立体图形的表面积和体积
计算球,圆柱,圆锥的表面积和体积. 利用接口实现. 上代码. Contants.java 常量存储类 package com.fuxuemingzhu.solidgraphics.contants; ...
- 【LeetCode】63. Unique Paths II 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 题目地址:https://leetcode.com/problems/unique-pa ...
- 1248 - Dice (III)
1248 - Dice (III) PDF (English) Statistics Forum Time Limit: 1 second(s) Memory Limit: 32 MB Given ...
- 1119 - Pimp My Ride
1119 - Pimp My Ride PDF (English) Statistics Forum Time Limit: 2 second(s) Memory Limit: 32 MB To ...
- linux系统安装java
1.下载Java压缩包 *.gz 2.解压 3.修改Linux配置文件,配置Java环境变量 4.使用命令source /etc/profile让修改生效 转载 https://www.cnblogs ...
- Zookeeper单机安装(开启kerberos)
安装规划 zookeeper安装到zdh41上面,单机模式 10.43.159.41 zdh41 ZDH.COM 安装用户 zookeeper/zdh1234 useradd -g hadoop -s ...
- Linux-saltstack-2 saltstack的基本使用
@ 目录 一.salt命令的基本使用 1.基本语法 例子: 2.salt的常用参数 (1)-S(大写):通过IP或者是网段匹配被管理主机 (2)-E:通过正则匹配主机 (3)-L: 匹配多个主机 (4 ...
- spring boot pom.xml 提示 ignored 具体解决
1.出现这个情况 2. 进入设置,找到 去掉勾选即可