图解大数据 | 海量数据库查询-Hive与HBase详解

作者:韩信子@ShowMeAI
教程地址:http://www.showmeai.tech/tutorials/84
本文地址:http://www.showmeai.tech/article-detail/172
声明:版权所有,转载请联系平台与作者并注明出处
1.大数据与数据库
1) 从Hadoop到数据库
大家知道在计算机领域,关系数据库大量用于数据存储和维护的场景。大数据的出现后,很多公司转而选择像 Hadoop/Spark 的大数据解决方案。
Hadoop使用分布式文件系统,用于存储大数据,并使用MapReduce来处理。Hadoop擅长于存储各种格式的庞大的数据,任意的格式甚至非结构化的处理。
2) Hadoop的限制
Hadoop非常适合批量处理任务,但它只以顺序方式访问数据。这意味着如果要查询,必须搜索整个数据集,即使是最简单的搜索工作。
当处理结果在另一个庞大的数据集,也是按顺序处理一个巨大的数据集。在这一点上,一个新的解决方案,需要访问数据中的任何点(随机访问)单元。
3) HBase与大数据数据库、
HBase是建立在Hadoop文件系统之上的分布式面向列的数据库。
HBase是一个数据模型,类似于谷歌的Bigtable设计,可以提供快速随机访问海量结构化数据。它利用了Hadoop的文件系统(HDFS)提供的容错能力。
它是Hadoop的生态系统,提供对数据的随机实时读/写访问,是Hadoop文件系统的一部分。我们可以直接或通过HBase的存储HDFS数据。使用HBase在HDFS读取消费/随机访问数据。 HBase在Hadoop的文件系统之上,并提供了读写访问。
2.BigTable与HBase
要提到HBase,就要顺带提到google的Bigtable。HBase是在谷歌BigTable的基础之上进行开源实现的,是一个高可靠、高性能、面向列、可伸缩的分布式数据库,可以用来存储非结构化和半结构化的稀疏数据。
1) 结构化数据和非结构化数据
BigTable和HBase存储的都是非结构化数据。

2) BigTable简介
BigTable是一个用于管理结构化数据的分布式存储系统,构建在GFS、Chubby、SSTable等google技术之上。本质上说,BigTable是一个稀疏的、分布式的、持久化的、多维的、排序的键值(key-value)映射。

3) HBase简介
HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌BigTable的开源实现。
HBase主要用来存储非结构化和半结构化的松散数据,目标是处理非常庞大的表,可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行数据和数百万列元素组成的数据表。

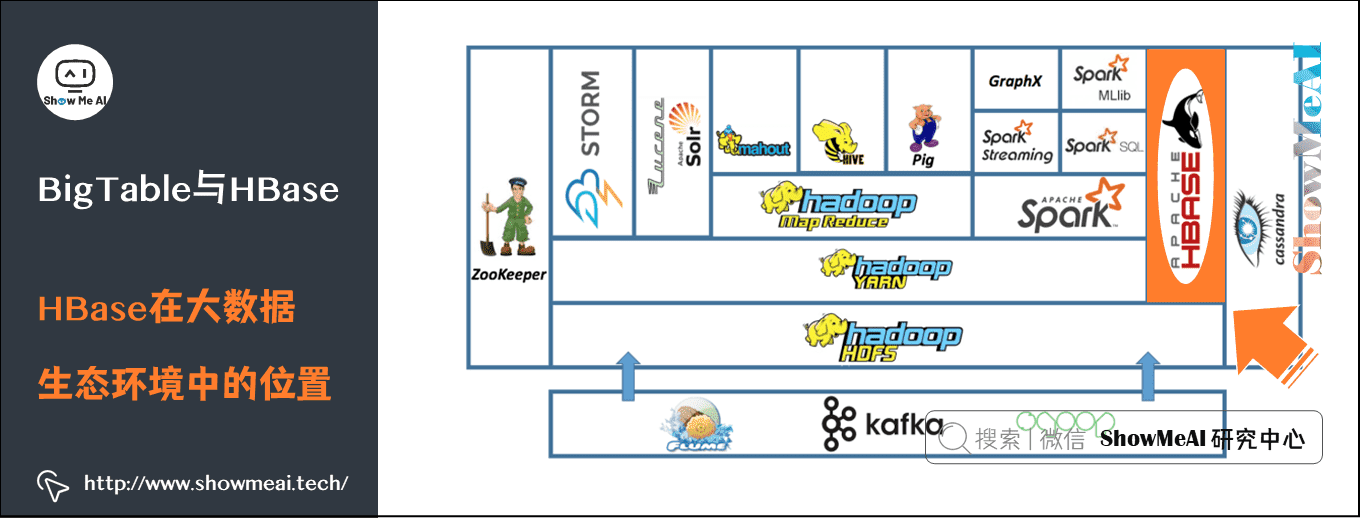
4) HBase在大数据生态环境中的位置
HBase在大数据生态环境中的位置如下图所示,它建立在Hadoop HDFS之上的分布式面向列的数据库。
5) HBase的特点
如下图所示,HBase有以下特点:

- 大:一个表可以有上亿行,上百万列。
- 面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
- 稀疏:对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
- 无模式:每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的列。
- 数据多版本:每个单元的数据有多个版本,默认情况下,版本号是单元格插入时的时间戳。
- 数据类型单一:HBase中的数据都是字符串,没有类型。
6) HBase的访问接口
| 类型 | 特点 | 场合 |
|---|---|---|
| Native Java API | 最常规和高效的访问方式 | 适合Hadoop MapReduce作业并行批处理HBase表数据 |
| HBase Shell | HBase的命令行工具 最简单的接口 | 适合HBase管理使用 |
| Thrift Gateway | 利用Thrift序列化技术 支持C++、PHP、Python等 | 适合其他异构系统在线访问HBase表数据 |
| REST Gateway | 解除了语言限制 | 支持REST风格的Http API访问HBase |
| Pig | 使用Pig Latin流式编程语言来处理HBase中的数据 | 适合做数据统计 |
| Hive | 简单 | 当需要以类似SQL语言方式来访问HBase的时候 |
3.HBase数据模型
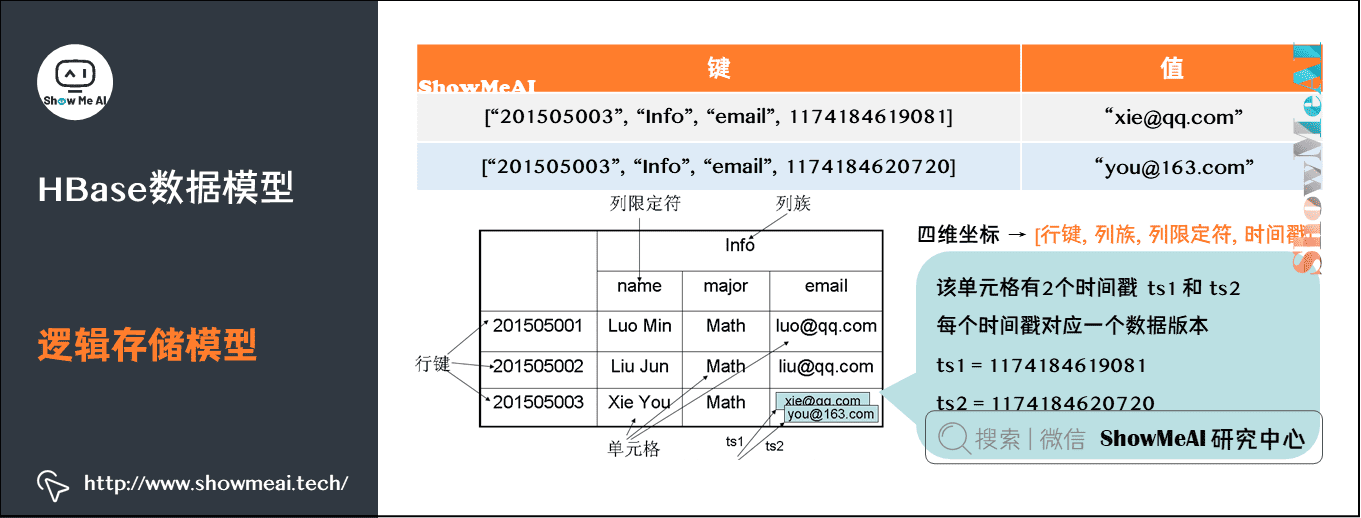
1) 逻辑存储模型
| 组件 | 描述 |
|---|---|
| 表 Table | HBase采用表来组织数据,表由行和列组成,列划分为若干个列族 |
| 行 Row | 每个HBase表都由若干行组成,每个行由行键(row key)来标识 |
| 列族 Column Family | 一个HBase表被分组成许多“列族”(Column Family)的集合 |
| 列限定符Column Qualifier | 列族里的数据通过列限定符(或列)来定位 |
| 单元格 Cell | 通过行、列族和列限定符确定一个单元格,单元格中存储的数据都视为byte |
| 时间戳 Times tamp | 同一份数据的多个版本,时间戳用于索引数据版本 |
HBase中需要根据行键、列族、列限定符和时间戳来确定一个单元格。因此,可以视为一个“四维坐标”,即 [行键, 列族, 列限定符, 时间戳] 。
2) 物理存储模型
Table在行的方向上分割为多个Region,每个Region分散在不同的RegionServer中。

每个HRegion由多个Store构成,每个Store由一个MemStore和0或多个StoreFile组成,每个Store保存一个Columns Family。StoreFile以HFile格式存储在HDFS中。

4.HBase系统架构
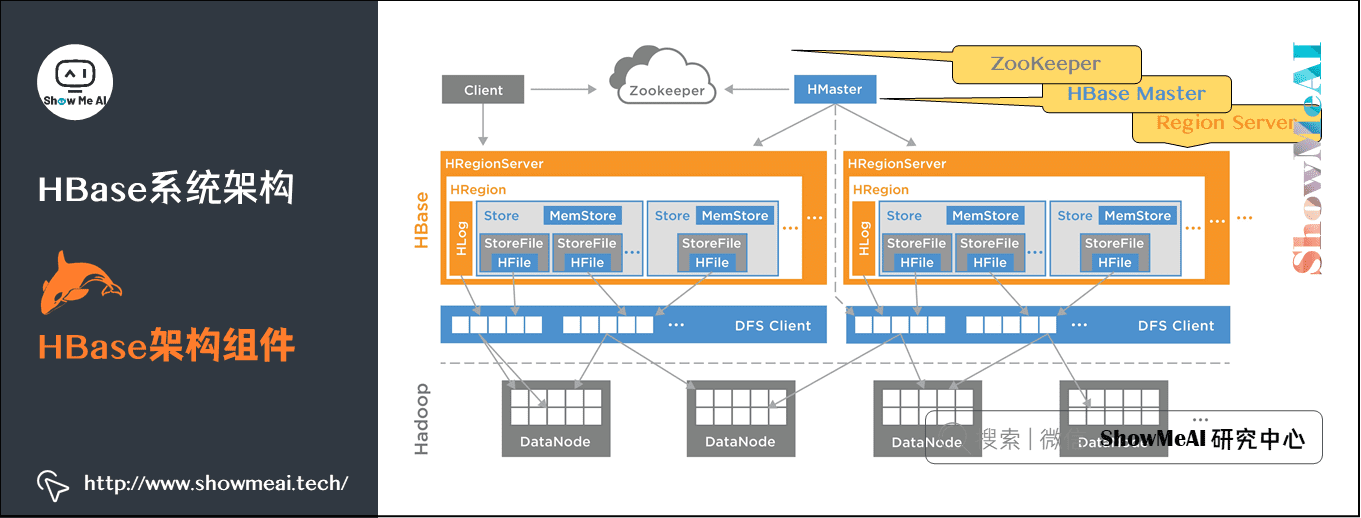
1) HBase架构组件
HBase包含以下三个组件:
- Region Server:提供数据的读写服务,当客户端访问数据时,直接和Region Server通信。
- HBase Master:Region的分配,DDL操作(创建表,删除表)。
- ZooKeeper:是HDFS的一部分,维护一个活跃的集群状态。
2) Region组件
HBase Tables 通过行健的范围(row key range)被水平切分成多个Region。一个Region包含了所有的在Region开始键(startKey)和结束键(endKey)之内的行。
Regions被分配到集群的节点上,成为Region Servers,提供数据的读写服务;一个Region Server可以服务1000个Region。

3) HMaster组件

- 分配Region,DDL操作(创建表, 删除表)。
- 协调各个Reion Server:在启动时分配Region、在恢复或是负载均衡时重新分配Region;监控所有集群当中的Region Server实例,从ZooKeeper中监听通知。
- 提供创建、删除、更新表的接口。
4) ZooKeeper组件

- HBase使用ZooKeeper作为分布式协调服务,来维护集群中的Server状态。
- ZooKeeper维护着哪些Server是活跃或是可用的,提供Server 失败时的通知。
- Zookeeper使用一致性机制来保证公共的共享状态,注意,需要使用奇数的三台或五台机器,保证一致。
5.Hive介绍
1) Hive简介
Hive是基于Hadoop的一个数据仓库工具,用于结构化数据的查询、分析和汇总。Hive提供类SQL查询功能,它将SQL转换为MapReduce程序。
Hive不支持OLTP,Hive无法提供实时查询。
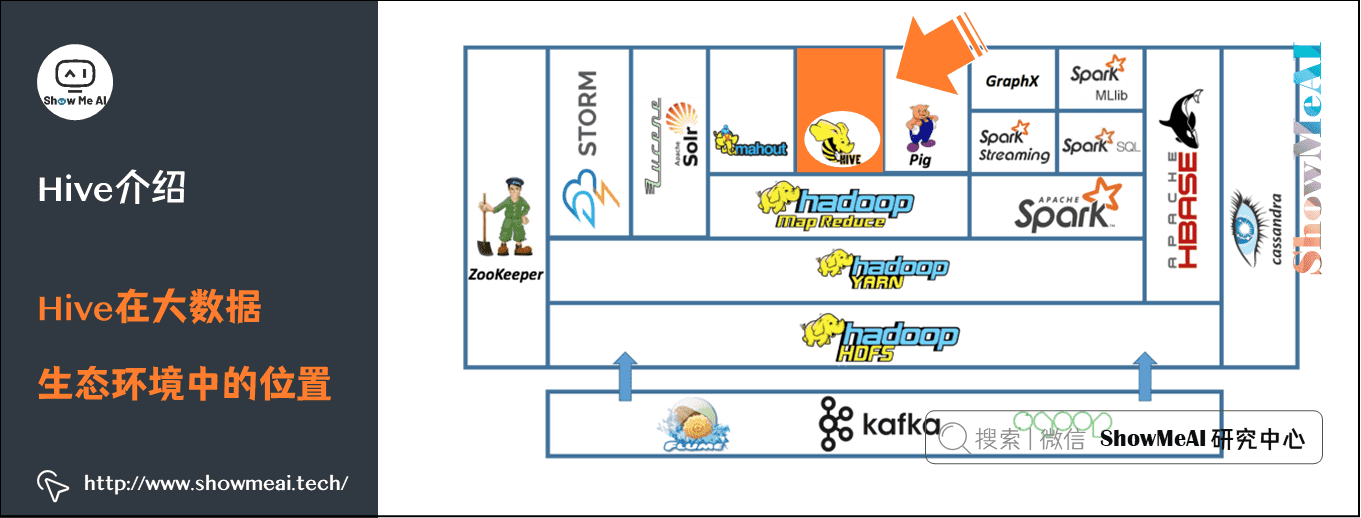
2) Hive在大数据生态环境中的位置
3) Hive特点
Hive的优点
- 简单容易上手:提供了类SQL查询语言HQL。
- 可扩展:一般情况下不需要重启服务Hive可以自由的扩展集群的规模。
- 提供统一的元数据管理。
- 延展性:Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
- 容错:良好的容错性,节点出现问题SQL仍可完成执行。
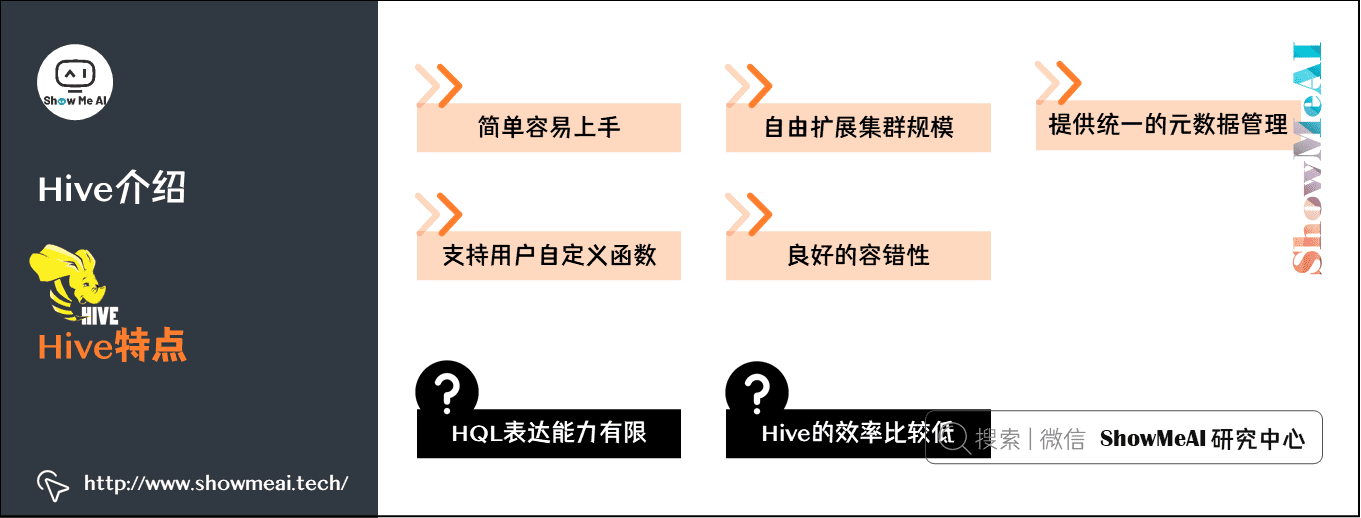
Hive的缺点(局限性)
- Hive的HQL表达能力有限:迭代式算法无法表达,比如pagerank;数据挖掘方面,比如kmeans。
- Hive的效率比较低:Hive自动生成的MapReduce作业,不够智能化;Hive调优比较困难,粒度较粗;Hive可控性差。
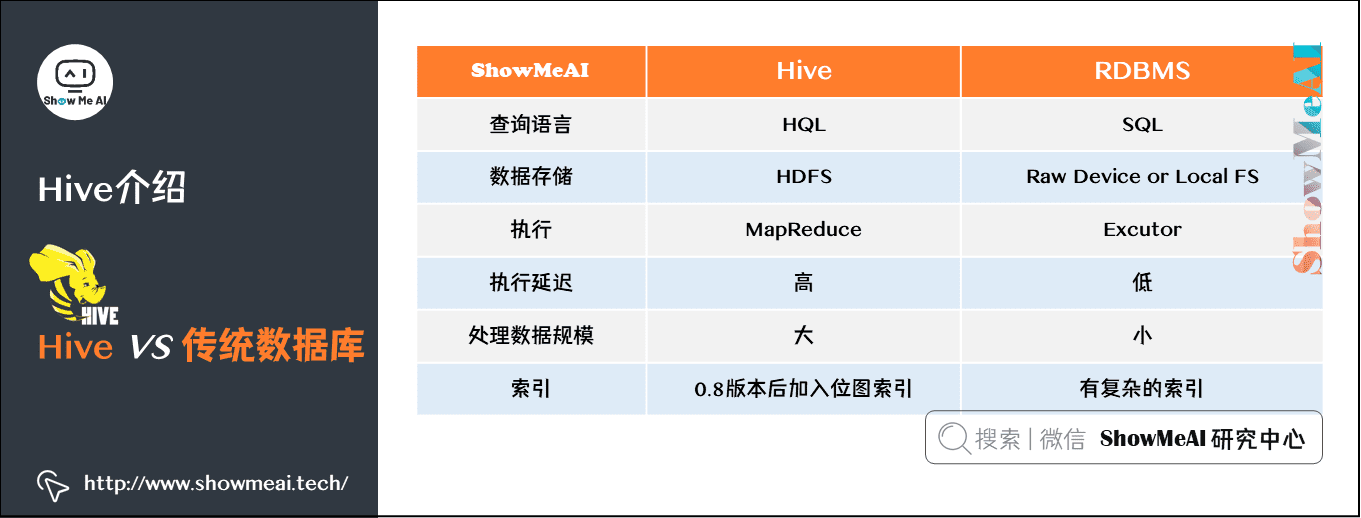
4) Hive与传统数据库对比
5) Hive的体系架构
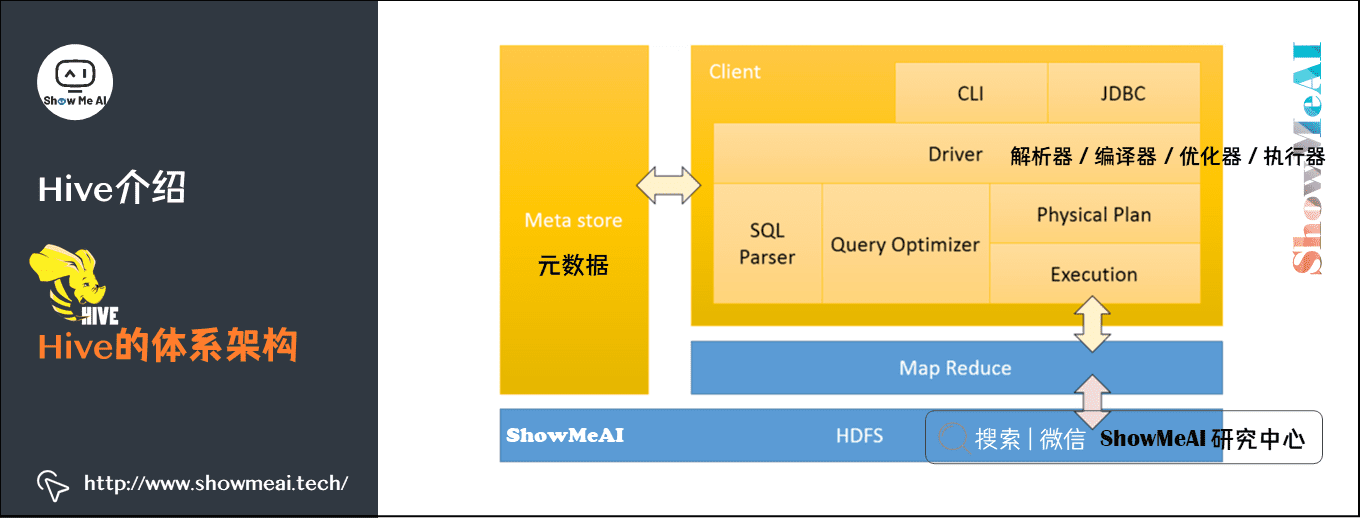
- client 三种访问方式:CLI、JDBC/ODBC、WEBUI。
- Meta store 元数据:表名、表所属数据库、表拥有者、列、分区字段、表类型、表数据所在的目录等,默认存储在自带的derby数据库中。
- Driver:解析器、编译器、优化器、执行器。
6) Hive中的数据模型
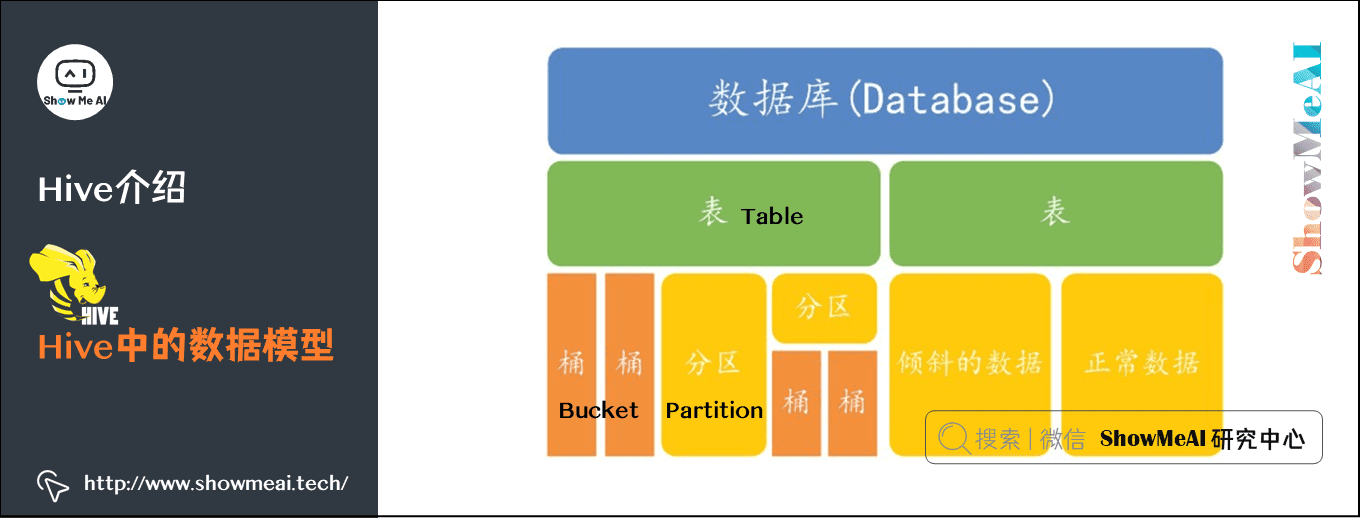
Hive 中所有的数据都存储在 HDFS 中Hive 中包含以下数据模型:
- 表(Table)
- 外部表(External Table)
- 分区(Partition)
- 桶(Bucket)
6.SQL介绍与Hive应用场景
1) 数据库操作和表操作
| 作用 | HiveQL |
|---|---|
| 查看所有数据库 | SHOW DATABASES; |
| 使用指定的数据库 | USE database_name; |
| 创建指定名称的数据库 | CREATE DATABASE database_name; |
| 删除数据库 | DROP DATABASE database_name; |
| 创建表 | CREATE TABLE pokes (foo INT, bar STRING) |
| 查看所有的表 | SHOW TABLES |
| 支持模糊查询 | SHOW TABLES ‘TMP’ |
| 查看表有哪些分区 | SHOW PARTITIONS TMP_TABLE |
| 查看表结构 | DESCRIBE TMP_TABLE |
| 创建表并创建索引ds | CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING) |
| 复制一个空表 | CREATE TABLE empty_key_value_store LIKE key_value_store |
| 表添加一列 | ALTER TABLE pokes ADD COLUMNS (new_col INT) |
| 更改表名 | ALTER TABLE events RENAME TO 3koobecaf |
2) 查询语句
| 作用 | HiveQL |
|---|---|
| 检索信息 | SELECT from_columns FROM table WHERE conditions; |
| 选择所有的数据 | SELECT * FROM table; |
| 行筛选 | SELECT * FROM table WHERE rec_name = “value”; |
| 多个限制条件 | SELECT * FROM TABLE WHERE rec1 = “value1” AND rec2 = “value2”; |
| 选择多个特定的列 | SELECT column_name FROM table; |
| 检索unique输出记录 | SELECT DISTINCT column_name FROM table; |
| 排序 | SELECT col1, col2 FROM table ORDER BY col2; |
| 逆序 | SELECT col1, col2 FROM table ORDER BY col2 DESC; |
| 统计行数 | SELECT COUNT(*) FROM table; |
| 分组统计 | SELECT owner, COUNT(*) FROM table GROUP BY owner; |
| 求某一列最大值 | SELECT MAX(col_name) AS label FROM table; |
| 从多个表中检索信息 | SELECT pet.name, comment FROM pet JOIN event ON (pet.name = event.name); |
3) Hive的应用场景
Hive并不适合需要低延迟的应用,适合于大数据集的批处理作业:
- 日志分析:大部分互联网公司使用hive进行日志分析,包括百度、淘宝等。例如,统计网站一个时间段内的pv、uv,多维度数据分析等。
- 海量结构化数据离线分析。
4) Hive和HBase的区别与联系

7.参考资料
- Lars George 著,代志远 / 刘佳 / 蒋杰 译,《 HBase权威指南》,东南大学出版社,2012
- Edward Capriolo / Dean Wampler)/ Jason Rutherglen 著,曹坤 译,《Hive编程指南》,人民邮电出版社,2013
- 深入了解HBase架构: https://blog.csdn.net/Lic_LiveTime/article/details/79818695
- APACHE HIVE TM:http://hive.apache.org/
- Apache HBase Reference Guide:http://hbase.apache.org/book.html
ShowMeAI相关文章推荐
- 图解大数据 | 导论:大数据生态与应用
- 图解大数据 | 分布式平台:Hadoop与Map-reduce详解
- 图解大数据 | 实操案例:Hadoop系统搭建与环境配置
- 图解大数据 | 实操案例:应用map-reduce进行大数据统计
- 图解大数据 | 实操案例:Hive搭建与应用案例
- 图解大数据 | 海量数据库与查询:Hive与HBase详解
- 图解大数据 | 大数据分析挖掘框架:Spark初步
- 图解大数据 | Spark操作:基于RDD的大数据处理分析
- 图解大数据 | Spark操作:基于Dataframe与SQL的大数据处理分析
- 图解大数据 | 综合案例:使用spark分析美国新冠肺炎疫情数据
- 图解大数据 | 综合案例:使用Spark分析挖掘零售交易数据
- 图解大数据 | 综合案例:使用Spark分析挖掘音乐专辑数据
- 图解大数据 | 流式数据处理:Spark Streaming
- 图解大数据 | Spark机器学习(上)-工作流与特征工程
- 图解大数据 | Spark机器学习(下)-建模与超参调优
- 图解大数据 | Spark GraphFrames:基于图的数据分析挖掘
ShowMeAI系列教程推荐

图解大数据 | 海量数据库查询-Hive与HBase详解的更多相关文章
- 大数据入门第十四天——Hbase详解(三)hbase基本原理与MR操作Hbase
一.基本原理 1.hbase的位置 上图描述了Hadoop 2.0生态系统中的各层结构.其中HBase位于结构化存储层,HDFS为HBase提供了高可靠性的底层存储支持, MapReduce为HBas ...
- 大数据入门第十四天——Hbase详解(二)基本概念与命令、javaAPI
一.hbase数据模型 完整的官方文档的翻译,参考:https://www.cnblogs.com/simple-focus/p/6198329.html 1.rowkey 与nosql数据库们一样, ...
- 大数据入门第十四天——Hbase详解(一)入门与安装配置
一.概述 1.什么是Hbase 根据官网:https://hbase.apache.org/ Apache HBase™ is the Hadoop database, a distributed, ...
- 大数据工具篇之Hive与HBase整合完整教程
大数据工具篇之Hive与HBase整合完整教程 一.引言 最近的一次培训,用户特意提到Hadoop环境下HDFS中存储的文件如何才能导入到HBase,关于这部分基于HBase Java API的写入方 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- Hive集成HBase详解
摘要 Hive提供了与HBase的集成,使得能够在HBase表上使用HQL语句进行查询 插入操作以及进行Join和Union等复杂查询 应用场景 1. 将ETL操作的数据存入HBase 2. HB ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- 大数据-06-Spark之读写Hive数据
简介 Hive中的表是纯逻辑表,就只是表的定义等,即表的元数据.Hive本身不存储数据,它完全依赖HDFS和MapReduce.这样就可以将结构化的数据文件映射为为一张数据库表,并提供完整的SQL查询 ...
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
随机推荐
- Kubeadm部署K8S(kubernetes)集群(测试、学习环境)-单主双从
1. kubernetes介绍 1.1 kubernetes简介 kubernetes的本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器进行管理.目的是实现资源管理的自动 ...
- Java方法内联
一.概念 方法内联就是把调用方函数代码"复制"到调用方函数中,减少因函数调用开销的技术 函数调用过程 1.首先会有个执行栈,存储它们的局部变量.方法名.动态连接 2.当一个方法 ...
- eureka的简单介绍,eureka单节点版的实现?eureka的自我保护?eureka的AP性,和CP性?
注意!!! 这是对上一篇博客 springcloud的延续,整个项目的搭建,来源与上一篇博客.一.什么是eureka? // eureka是一个注册中心,实现了dubbo中zookeeper的效果! ...
- JavaWeb基本概念及web服务器
1.基本概念 1.1.前言 web开发: web,网页的意思,www.baidu.com 静态web html,css 提供给所有人看的数据始终不会发生变化! 动态web 淘宝,几乎是所有的网站: 提 ...
- 关于obj.class.getResource()和obj.getClass().getClassLoader().getResource()的路径问题
感谢原文作者:yejg1212 原文链接:https://www.cnblogs.com/yejg1212/p/3270152.html 注:格式内容与原文有轻微不同. Java中取资源时,经常用到C ...
- element ui图片上传方法
<!--商品图片--> <template v-slot:product_cover> <el-upload list-type="picture-card&q ...
- js实现网页回弹小球效果
直接上效果图 运行页面会首先弹出一个输入框,询问用户想要产生的小球数量,随后后台就会产生指定数量的小球,在页面中来回跳动,触碰到页面边框时,就会回弹,且产生的小球颜色随机,小球在页面中的位置随机,小球 ...
- Spark RDD学习
RDD(弹性分布式数据集)是Spark的核心抽象.它是一组元素,在集群的节点之间进行分区,以便我们可以对其执行各种并行操作. 创建RDD的两种方式: 并行化驱动程序中的现有数据: 引用外部存储系统中的 ...
- tarjan——有向图、无向图
强连通块只存在于有向无环图DAG中 实际上low[i]的理解是:一个强连通块在dfs搜索树中子树的根节点 //把一个点当成根提溜出来,抖搂抖搂成一棵树 void dfs(int u) { //记录df ...
- find 查询命令 & 正则表达式
今日内容 find 正则表达式 Linux 三剑客之 grep 内容详细 一.find 按名称或属性查询文件 按名称查询 find [查找目录] [参数] [] 通配符 : * 表示匹配多个字符 ? ...