Lucene基础入门
1. 数据的分类
结构化数据: 查询方法 数据库
非结构化数据: 查询方法 :
(1)顺序扫描法 : 一行一行的看,从头看到尾
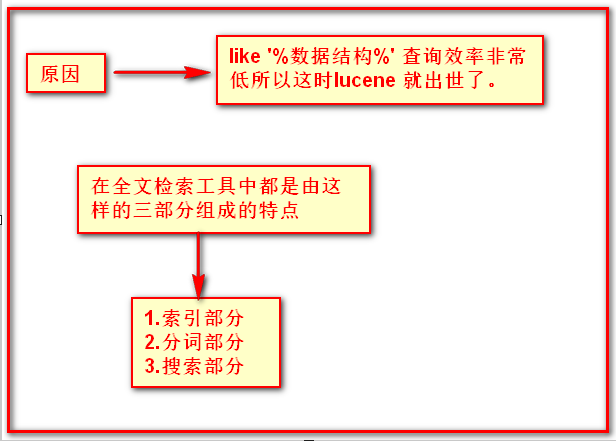
(2)全文检索 : 将一部分信息提取出来,重新组织将其变得有一定结构 然后对其搜索 这部分信息称为索引 例如:字典
这种先建立索引然后再对其扫描的过程就叫全文检索。
虽然创建索引的过程是非常耗时的,但是索引一旦创建可以多次使用,全文检索主要是做查询的所以耗时间创建索引是非常值得的。
2. 应用场景
对于数据量大、数据结构不固定的数据可采用全文检索方式搜索,比如百度、Google等搜索引擎、论坛站内搜索、电商网站站内搜索等。
每个单词叫做一个Term,不同的域中拆分出来的相同的单词是不同的term。term中包含两部分一部分是文档的域名,另一部分是单词的内容。
3. 解释部分
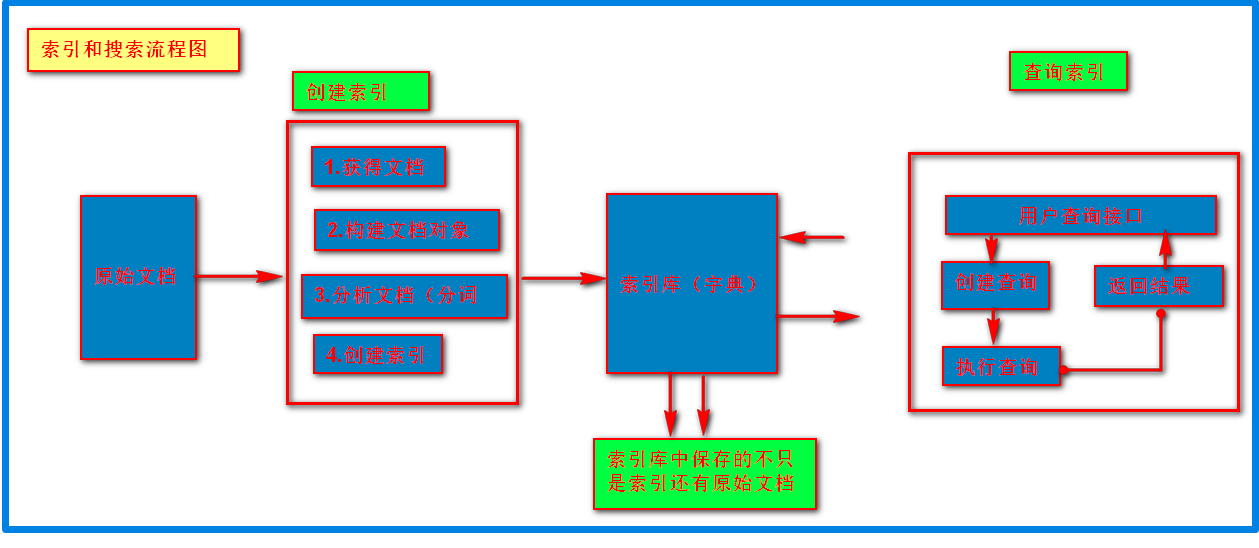
(1)首先需要获取原始内容然后进行索引,在索引前需要将原始内容创建成文档,文档中包含很多域,这些域主要用于存储内容。
先上代码演示:
创建
package com.baizhi.lucence; import java.io.File;
import java.io.IOException; import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.RAMDirectory;
import org.apache.lucene.util.Version; public class TestCreateIndexWriter { //创建索引写入器 (并且存入一篇文章)
public static void main(String[] args) {
IndexWriter indexWriter = null;
try {
//创建indexConfig对象 保存了两个主要的属性一个是 Lucene的版本 另外一个是分词器以及版本
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LUCENE_44,new StandardAnalyzer(Version.LUCENE_44)); //创建内存索引目录
Directory direction = FSDirectory.open(new File("D:/lucenezhulina"));
//创建 索引写入器对象 需要两个对象一个 索引目录 封装的需要的配置
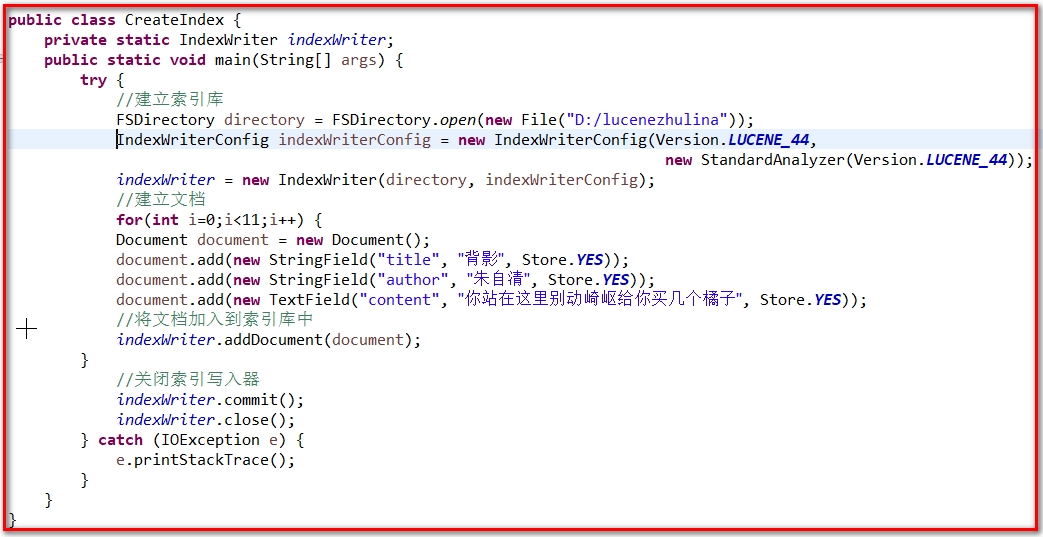
indexWriter = new IndexWriter(direction, indexWriterConfig); //创建文档
for(int i=0;i<10;i++) { Document document = new Document();
document.add(new StringField("id", String.valueOf(i), Store.YES));
document.add(new StringField("title", "背影"+i, Store.YES));
document.add(new StringField("author", "朱自清", Store.YES));
document.add(new TextField("content", "你站这里不要动,我去给你买几个橘子", Store.YES));
//添加文章
indexWriter.addDocument(document); }
indexWriter.commit();
indexWriter.close(); } catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} }
创建代码
搜索

package com.baizhi.lucence; import java.io.File;
import java.io.IOException; import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory; public class TestSearchIndex {
/*
* 八种基本数据类型 +String 类型不分词
* Text类型分词 标准分词器的规则 单字分词
*
*/
public static void main(String[] args) {
try {
//获取指定索引库
Directory direction = FSDirectory.open(new File("D:/lucenezhulina")); //将索引库放入DirectoryReader中
DirectoryReader reader = DirectoryReader.open(direction); //创建索引搜索对象
IndexSearcher indexSearcher = new IndexSearcher(reader); //搜索条件
TermQuery query = new TermQuery(new Term("content","橘")); //相关度排序
TopDocs topDocs = indexSearcher.search(query, 100);
//获取索引编号
ScoreDoc[] scoreDocs = topDocs.scoreDocs; for(int i=0;i<scoreDocs.length;i++) { System.out.println("索引编号 "+scoreDocs[i].doc);
System.out.println("文章分数 "+scoreDocs[i].score); //获取一个文章
Document document = indexSearcher.doc(scoreDocs[i].doc);
System.out.println("文章编号 "+document.get("id"));
System.out.println("文章标题 "+document.get("title"));
System.out.println("文章作者 "+document.get("author"));
System.out.println("文章内容 "+document.get("content"));
System.out.println("===================================");
} } catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} } }
搜索代码
更改
1 import static org.junit.Assert.assertNotNull;
2
3 import java.io.File;
4 import java.io.IOException;
5
6 import org.apache.lucene.analysis.standard.StandardAnalyzer;
7 import org.apache.lucene.document.Document;
8 import org.apache.lucene.document.StringField;
9 import org.apache.lucene.document.TextField;
10 import org.apache.lucene.document.Field.Store;
11 import org.apache.lucene.index.IndexWriter;
12 import org.apache.lucene.index.IndexWriterConfig;
13 import org.apache.lucene.index.Term;
14 import org.apache.lucene.store.FSDirectory;
15 import org.apache.lucene.util.Version;
16 public class TestUpdateIndex {
17
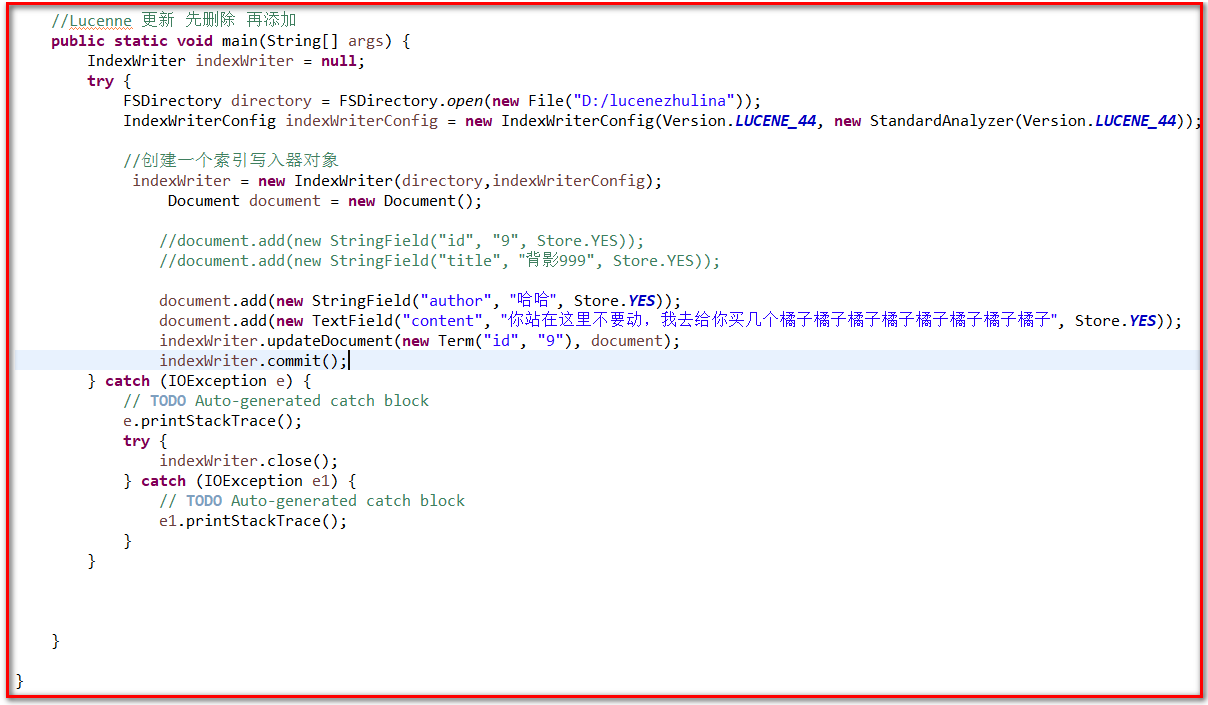
18 //Lucenne 更新 先删除 再添加
19 public static void main(String[] args) {
20 IndexWriter indexWriter = null;
21 try {
22 FSDirectory directory = FSDirectory.open(new File("D:/lucenezhulina"));
23 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LUCENE_44, new StandardAnalyzer(Version.LUCENE_44));
24
25 //创建一个索引写入器对象
26 indexWriter = new IndexWriter(directory,indexWriterConfig);
27 Document document = new Document();
28
29 //document.add(new StringField("id", "9", Store.YES));
30 //document.add(new StringField("title", "背影999", Store.YES));
31
32 document.add(new StringField("author", "哈哈", Store.YES));
33 document.add(new TextField("content", "你站在这里不要动,我去给你买几个橘子橘子橘子橘子橘子橘子橘子橘子", Store.YES));
34 indexWriter.updateDocument(new Term("id", "9"), document);
35 indexWriter.commit();
36 } catch (IOException e) {
37 // TODO Auto-generated catch block
38 e.printStackTrace();
39 try {
40 indexWriter.close();
41 } catch (IOException e1) {
42 // TODO Auto-generated catch block
43 e1.printStackTrace();
44 }
45 }
46
47
48
49 }
50
51 }
更改代码
删除
1 import java.io.File;
2 import java.io.IOException;
3
4 import org.apache.lucene.analysis.standard.StandardAnalyzer;
5 import org.apache.lucene.index.IndexWriter;
6 import org.apache.lucene.index.IndexWriterConfig;
7 import org.apache.lucene.index.Term;
8 import org.apache.lucene.store.FSDirectory;
9 import org.apache.lucene.util.Version;
10
11 public class TestDeleteIndex {
12 public static void main(String[] args) {
13 IndexWriter indexWriter= null;
14 try {
15 //打开一个索引库
16 FSDirectory directory = FSDirectory.open(new File("D:/lucenezhulina"));
17 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LUCENE_44,new StandardAnalyzer(Version.LUCENE_44));
18
19 //创建一个索引写入器对象
20 indexWriter = new IndexWriter(directory, indexWriterConfig);
21
22 indexWriter.deleteDocuments(new Term("id","10"));
23 indexWriter.commit();
24
25 } catch (IOException e) {
26 // TODO Auto-generated catch block
27 e.printStackTrace();
28 try {
29 indexWriter.rollback();
30 } catch (IOException e1) {
31 // TODO Auto-generated catch block
32 e1.printStackTrace();
33 }
34 }
35
36
37
38
39
40 }
41 }
删除 这个是代码
Lucene基础入门的更多相关文章
- [全文检索]Lucene基础入门.
本打算直接来学习Solr, 现在先把Lucene的只是捋一遍. 本文内容: 1. 搜索引擎的发展史 2. Lucene入门 3. Lucene的API详解 4. 索引调优 5. Lucene搜索结果排 ...
- Lucene从入门到实战
Lucene 在了解Lucene之前,我们先了解下全文数据查询. 全文数据查询 我们的数据一般分为两种:结构化数据和非结构化数据 结构化数据:有固定格式或有限长度的数据,如数据库中的数据.元数据 非结 ...
- 【转载】Lucene.Net入门教程及示例
本人看到这篇非常不错的Lucene.Net入门基础教程,就转载分享一下给大家来学习,希望大家在工作实践中可以用到. 一.简单的例子 //索引Private void Index(){ Index ...
- Lucene 02 - Lucene的入门程序(Java API的简单使用)
目录 1 准备环境 2 准备数据 3 创建工程 3.1 创建Maven Project(打包方式选jar即可) 3.2 配置pom.xml, 导入依赖 4 编写基础代码 4.1 编写图书POJO 4. ...
- Elasticsearch 基础入门
原文地址:Elasticsearch 基础入门 博客地址:http://www.extlight.com 一.什么是 ElasticSearch ElasticSearch是一个基于 Lucene 的 ...
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- 「译」JUnit 5 系列:基础入门
原文地址:http://blog.codefx.org/libraries/junit-5-basics/ 原文日期:25, Feb, 2016 译文首发:Linesh 的博客:JUnit 5 系列: ...
- .NET正则表达式基础入门
这是我第一次写的博客,个人觉得十分不容易.以前看别人写的博客文字十分流畅,到自己来写却发现十分困难,还是感谢那些为技术而奉献自己力量的人吧. 本教程编写之前,博主阅读了<正则指引>这本入门 ...
- 从零3D基础入门XNA 4.0(2)——模型和BasicEffect
[题外话] 上一篇文章介绍了3D开发基础与XNA开发程序的整体结构,以及使用Model类的Draw方法将模型绘制到屏幕上.本文接着上一篇文章继续,介绍XNA中模型的结构.BasicEffect的使用以 ...
随机推荐
- NOIP 模拟 $19\; \rm v$
题解 一道概率与期望的状压题目 这种最优性的题目,我们一般都是倒着转移,因为它的选择是随机的所以我们无法判断从左还是从右更有,所以我们都搜一遍 时间一定会爆,采用记忆化搜索,一种状态的答案一定是固定的 ...
- Java社区——个人项目开发笔记(二)
1.B\S架构通信原理 浏览器,服务器之间产生通信,浏览器访问服务器,服务器返回一个HTML,浏览器会对HTML进行解析,并渲染相关的内容. 在解析过程中,会发现HTML里引用了css文件,js文件, ...
- ReentrantLock可重入锁lock,tryLock的区别
void lock(); Acquires the lock. Acquires the lock if it is not held by another thread and returns im ...
- 5、二进制安装K8s 之 部署kube-scheduler
二进制安装K8s之部署kube-scheduler 1.创建配置文件 cat > /data/k8s/config/kube-scheduler.conf << EOF KUBE_S ...
- uwp 之后台音频
C# code 后台任务 ---------------------------- public sealed class BgTask : IBackgroundTask { #region 私有字 ...
- 关于腾讯云redis 无法外网访问的解决方案
问题简介: 今天购买了一台腾讯云的redis:如图 可是我没有找到 腾讯云提供的外网地址,我该怎么连接呢?百度了一大堆 全部是 在腾讯云服务器上搭建的Redis实例的解决办法.完全不匹配. 开始解决: ...
- 求证:-1/2 <= {2x} - {x} < 1/2
证:由 x = [x] + {x},知2x = 2[x] + 2{x}. 1.若{x}落在[0,1/2),则2{x} < 1,于是有{2x} = 2{x},此时 {2x} - {x} = {x} ...
- Servlet学习笔记(三)之HttpServletResponse
init() 方法中参数 ServletConfig 对象使用 通过ServletConfig 获得 ServletContext对象 使用 HttpServletRequest 与HttpServl ...
- Java 学习:对象和类
对象和类 从认识的角度考虑是先有对象后有类.对象,是具体的事物.类,是抽象的,是对对象的抽象. 从代码运行角度考虑是先有类后又对象.类是对象的模板. 对象:对象是类的一个实例,有状态和行为. 类:类是 ...
- vue 之 后端返回空字符串用 null 和 “”以及 undefind 判断不到的问题
原文: <!-- <span v-if="scope.row.buyer_credit_score != '' || scope.row.buyer_credit_score ! ...