RocketMQ架构原理解析(二):消息存储
一、概述
由前文可知,RocketMQ有几个非常重要的概念:
- broker 服务端,负责存储、收发消息
- producer 客户端1,负责产生消息
- consumer 客服端2,负责消费消息
既然是消息队列,那消息的存储的重要程度不言而喻,本节我们聚焦broker服务端,看下消息在broker端是如何存储的,它的落盘策略是怎样的,又是如何保证高效
二、写入流程
RocketMQ的普通单消息写入流程如下

简单可以分为三大块:
- 写入前准备
- 加锁后消息写入
- 消息落盘及集群同步
2.1 准备
其实消息的写入准备工作也比较好理解,主要是消息状态的检查以及各类存储状态的检查,可以参看上图中的流程
根据上图,在准备阶段前,RocketMQ会判断操作系统的Page Cache是否繁忙,他是怎么做到的呢?其实Java本身没有提供接口或函数来查看Page Cache的状态,但如果磁盘带宽已经打满,在Page Cache要将数据刷disk时,很有可能便陷入了阻塞,导致Page Cache资源紧张。而当我们的程序又有新的消息要写入Page Cache时,反向阻塞写入请求,我们说这时Page Cache就产生了回压,也就是Page Cache相当繁忙,请求已经不能及时处理了。RocketMQ判断Page Cache是否繁忙的条件也很简单,就是监控某个请求加锁后,写入是否超过1秒,如果超时的话,新的请求会快速失败
2.2 消息协议
RocketMQ有一套相对复杂的消息协议编码,大部分协议中的内容都是在加锁前拼接生成

大部分消息协议项都是定长字段,变长字段如下:
- 1、born inet 产生消息的producer的IP信息 ipv4占用4byte,ipv6占16byte
- 2、broker inet 接收消息的broker的IP信息 ipv4占用4byte,ipv6占16byte
- 3、msg content 消息内容 变长字段(1-21亿)byte
- 4、topic content 消息内容 变长字段(1-127)byte
- 5、properties content 属性内容 变长字段(0-32767)byte
2.3 加锁
此处rmq提供了2种加锁方式
- 1、基于AQS的ReentrantLock (默认方式)
- 2、基于CAS的自旋锁,加锁不成功的话,会无限重试
无论采用哪种策略,都是独占锁,即同一时刻只允许一个线程加锁成功。具体采用哪种方式,可通过配置修改。
两种加锁适用不同的场景,方式1在高并发场景下,能保持平稳的系统性能,但在低并发下表现一般;而方式二正好相反,在高并发场景下,因为采用自旋,会浪费大量的cpu,但在低并发时,却可以获得很高的性能。
所以官方文档中,为了提高性能,建议用户在同步刷盘的时候采用独占锁,异步刷盘的时候采用自旋锁。这个是根据加锁时间长短决定的
2.4 锁内操作
上文提到,写入消息的锁是独占锁,也就意味着同一时刻,只能有一个线程进入,我们看一下锁内都做了哪些操作
- 1、拿到或创建文件操作对象
MappedFile- 此处涉及点较多,我们在文件写入大节详细展开
- 2、二次整理要落盘的消息格式
- 之前已经整理过消息协议了,为什么此处还要进行二次整理?因为之前一些消息协议在没有加锁的时候,还无法确定。主要是以下三项内容:
- a、queueOffset 队列偏移量,此值需要最终返回,且需要保证严格递增,所以需要在锁内进行
- b、physicalOffset 物理偏移量,也就是全局文件的位置,注:此位置是全局文件的偏移量,不是当前文件的偏移量,所以其值可能会大于1G
- c、storeTimestamp 存储时间戳,此处在锁内进行,主要是为了保证消息投递的时间严格保序
- 之前已经整理过消息协议了,为什么此处还要进行二次整理?因为之前一些消息协议在没有加锁的时候,还无法确定。主要是以下三项内容:
- 3、记录写入信息
- 记录当前文件写入情况:比如已写入字节数、存储时间等
三、文件开辟及写入
3.1 文件开辟
文件的开辟是异步进行,有独立的线程专门负责开辟文件。我们可以先看下文件开辟的简单模型

也就是putMsg的线程会将开辟文件的请求委托给allocate file线程,然后进入阻塞,待allocate file线程将文件开辟完毕后,再唤醒putMsg线程
那此处我们便产生了2点疑问:
- 1、putMsg把开辟文件的请求交给了allocate file线程,直到allocate file线程开辟完毕后才会唤醒putMsg线程,其实并没有起到异步开辟节省时间的目的,直接在putMsg线程中开辟文件不好吗?
- 2、创建文件本身感觉并不耗时,不管是拿到文件的
FileChannnel还是MappedByteBuffer,都是一件很快的操作,费尽周章的异步开辟真的有必要吗?
这两个疑问将逐步说明
3.1.1 开启堆外缓冲池
至此我们要引入一个非常重要的配置变量transientStorePoolEnable,该配置项只在异步刷盘(FlushDiskType == AsyncFlush)的场景下,才会生效
如果配置项中,将transientStorePoolEnable置为false,便称为“开启堆外缓冲池”。那么这个变量到底起到什么作用呢?

系统启动时,会默认开辟5个(参数transientStorePoolSize控制)堆外内存DirectByteBuffer,循环利用。写消息时,消息都暂存至此,通过线程CommitRealTimeService将数据定时刷到page cache,当数据flush到disk后,再将DirectByteBuffer归还给缓冲池
而开辟过程是在broker启动时进行的;如上图所示,空间一旦开辟完毕后,文件都是预先创建好的,使用时直接返回文件引用即可,相当高效。但首次启动需要大量开辟堆外内存空间,会拉长broker的启动时长。我们看一下这块开辟的源码
/**
* It's a heavy init method.
*/
public void init() {
for (int i = 0; i < poolSize; i++) {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(fileSize);
......
availableBuffers.offer(byteBuffer);
}
}
注释中也标识了这是个重量级的方法,主要耗时点在ByteBuffer.allocateDirect(fileSize),其实开辟内存并不耗时,耗时集中在为内存区域赋0操作,以下是JDK中DirectByteBuffer源码:
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
......
long base = 0;
try {
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
......
}
我们发现在开辟完内存后,开始执行了赋0操作unsafe.setMemory(base, size, 0)。其实可以利用反射巧妙地绕过这个耗时点
private static Field addr;
private static Field capacity;
static {
try {
addr = Buffer.class.getDeclaredField("address");
addr.setAccessible(true);
capacity = Buffer.class.getDeclaredField("capacity");
capacity.setAccessible(true);
} catch (NoSuchFieldException e) {
e.printStackTrace();
}
}
public static ByteBuffer newFastByteBuffer(int cap) {
long address = unsafe.allocateMemory(cap);
ByteBuffer bb = ByteBuffer.allocateDirect(0).order(ByteOrder.nativeOrder());
try {
addr.setLong(bb, address);
capacity.setInt(bb, cap);
} catch (IllegalAccessException e) {
return null;
}
bb.clear();
return bb;
}
3.1.2 关闭堆外缓冲池
关闭堆外内存池的话,就会启动MappedByteBuffer

- a、首次启动
- 第一次启动的时候,allocate线程会先后创建2个文件,第一个文件创建完毕后,便会返回putMsg线程并唤醒它,然后allocate线程进而继续异步创建下一个文件
- b、后续启动
- 后续请求allocate线程都会将已经创建好的文件直接返回给putMsg线程,然后继续异步创建下一个文件,这样便真正实现了异步创建文件的效果
3.1.3 文件预热
我们再回顾一下本章刚开始提出的2个疑问:
- 1、putMsg把开辟文件的请求交给了allocate file线程,直到allocate file线程开辟完毕后才会唤醒putMsg线程,其实并没有起到异步开辟节省时间的目的,直接在putMsg线程中开辟文件不好吗?
- 2、创建文件本身感觉并不耗时,不管是拿到文件的
FileChannnel还是MappedByteBuffer,都是一件很快的操作,费尽周章的异步开辟真的有必要吗?
第一个问题已经迎刃而解,即allocate线程通过异步创建下一个文件的方式,实现真正异步
本节讨论的便是第二个问题,其实如果只是单纯创建文件的话,的确是非常快的,不至于再使用异步操作。但RocketMQ对于新建文件有个文件预热(通过配置warmMapedFileEnable启停)功能,当然目的是为了磁盘提速,我么先看下源码
org.apache.rocketmq.store.MappedFile#warmMappedFile
for (int i = 0, j = 0; i < this.fileSize; i += MappedFile.OS_PAGE_SIZE, j++) {
byteBuffer.put(i, (byte) 0);
// force flush when flush disk type is sync
if (type == FlushDiskType.SYNC_FLUSH) {
if ((i / OS_PAGE_SIZE) - (flush / OS_PAGE_SIZE) >= pages) {
flush = i;
mappedByteBuffer.force();
}
}
}
简单来说,就是将MappedByteBuffer每隔4K就写入一个0 byte,然后将整个文件撑满;如果刷盘策略是同步刷盘的话,还需要调用mappedByteBuffer.force(),当然这个操作是相当相当耗时的,所以也就需要我们进行异步处理。这样也就解释了第二个问题
但文件预热真的有效吗?我们不妨做个简单的基准测试
public class FileWriteCompare {
private static String filePath = "/Users/likangning/test/index3.data";
private static int fileSize = 1024 * 1024 * 1024;
private static boolean warmFile = true;
private static int batchSize = 4096;
@Test
public void test() throws Exception {
File file = new File(filePath);
if (file.exists()) {
file.delete();
}
file.createNewFile();
FileChannel fileChannel = FileChannel.open(file.toPath(), StandardOpenOption.WRITE, StandardOpenOption.READ);
MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, fileSize);
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(batchSize);
long beginTime = System.currentTimeMillis();
mappedByteBuffer.position(0);
while (mappedByteBuffer.remaining() >= batchSize) {
byteBuffer.position(batchSize);
byteBuffer.flip();
mappedByteBuffer.put(byteBuffer);
}
System.out.println("time cost is : " + (System.currentTimeMillis() - beginTime));
}
}
简单来说就是通过MappedByteBuffer写入1G文件,在我本地电脑上,平均耗时在 550ms 左右
然后在MappedByteBuffer写文件前加入预热操作
private void warmFile(MappedByteBuffer mappedByteBuffer) {
if (!warmFile) {
return;
}
int pageSize = 4096;
long begin = System.currentTimeMillis();
for (int i = 0, j = 0; i < fileSize; i += pageSize, j++) {
mappedByteBuffer.put(i, (byte) 0);
}
System.out.println("warm file time cost " + (System.currentTimeMillis() - begin));
}
耗时情况如下:
warm file time cost 492
time cost is : 125
预热后,写文件的耗时缩短了很多,但预热本身的耗时也几乎等同于文件写入的耗时了
以上是没有强制刷盘的测试效果,如果强制刷盘(#force)的话,个人经验是文件预热一定会带来性能的提升。从前两天结束的第二届中间件性能挑战赛来看,文件预热至少带来10%以上的提升。但是同非强制刷盘一样,文件预热操作实在是太重了
整体来看,文件预热后的写入操作,确实能带来性能上的提升,但是如果在系统压力较大、磁盘吞吐紧张的场景下,势必导致broker抖动,甚至请求超时,反而得不偿失。明白了此层概念后,再通过大量benchmark来决定是否开启此配置,做到有的放矢
3.2 文件写入
经过以上整理分析后,文件写入将变得非常轻;不论是DirectByteBuffer还是MappedByteBuffer都可以抽象为ByteBuffer,进而直接调用ByteBuffer.write()
四、刷盘策略
4.1 异步刷盘

4.1.1 异步+关闭写缓冲
对应如下配置
FlushDiskType == AsyncFlush && transientStorePoolEnable == false
异步刷盘,且关闭缓冲池,对应的异步刷盘线程是FlushRealTimeService
上文可知,次策略是通过MappedByteBuffer写入的数据,所以此时数据已经在 page cache 中了
我们总结一下刷盘的策略:
- 1、固定频率刷盘
不响应中断,固定500ms(可配置)刷盘,但刷盘的时候,如果发现未落盘数据不足16K(可配置),那么将进入下一个循环,如果满16K的话,会将所有未落盘的数据落盘。此处补充说明下,不论是FileChannel还是MappedByteBuffer都不提供指定区间的刷盘策略,只提供一个force()方法,所以无法精确控制落盘数据的大小。
如果数据写入量很少,一直没有填充满16K,就不会落盘了吗?不是的,此处兜底的方案是,线程发现距离上次无条件全量刷盘已经超过10000ms(可配置),那么此时就会无条件触发全量刷盘
- 2、非固定频率刷盘
与「固定频率刷盘」比较相似,唯一不同点是,当前刷盘策略是响应中断的,即每次有新的消息到来的时候,都会发送唤醒信号,如果刷盘线程正好处在500ms等待期间的话,将被唤醒。但此处的唤醒并非严谨的唤醒,有可能发送了唤醒信号,但刷盘线程并未成功响应,兜底方案便是500ms的重试。下面简单黏贴一下等待、唤醒的代码,不再赘述
org.apache.rocketmq.common.ServiceThread
// 唤醒
public void wakeup() {
if (hasNotified.compareAndSet(false, true)) {
waitPoint.countDown(); // notify
}
}
// 睡眠并响应唤醒
protected void waitForRunning(long interval) {
if (hasNotified.compareAndSet(true, false)) {
this.onWaitEnd();
return;
}
//entry to wait
waitPoint.reset();
try {
waitPoint.await(interval, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
log.error("Interrupted", e);
} finally {
hasNotified.set(false);
this.onWaitEnd();
}
}
综上,数据在page cache中最长的等待时间为(10000+500)ms
4.1.2 异步+开启写缓冲
对应如下配置
FlushDiskType == AsyncFlush && transientStorePoolEnable == true
异步刷盘,且开启缓冲池,对应的异步刷盘线程是CommitRealTimeService
首先需要明确一点的是,当前配置下,在写入阶段,数据是直接写入DirectByteBuffer的,这样做的好处及弊端也非常鲜明。
- 好处:数据不用写page cache,放入
DirectByteBuffer后便很快返回,减少了用户态与内核态的切换开销,性能非常高 - 弊端:数据可靠性降为最低级别,即进程挂掉的话,就会丢数据。因为数据即没有写入page cache,也没有落盘至disk,仅仅是在进程内部维护了一块临时缓存,进程重启或crash掉的话,数据一定会丢失
值得一提的是,此种刷盘模式,写入动作使用的是FileChannel,且仅仅调用FileChannel.write()方法将数据写入page cache,并没有直接强制刷盘,而是将强制落盘的任务转交给FlushRealTimeService线程来操作,而FlushRealTimeService线程最终也会调用FileChannel进行强制刷盘
在RocketMQ内部,无论采用什么刷盘策略,都是单一操作对象在写入/读取文件;即如果使用MappedByteBuffer写文件,那一定会通过MappedByteBuffer刷盘,如果使用FileChannel写文件,那一定会通过FileChannel 刷盘,不存在混合操作的情况
疑问:为什么RocketMQ不依赖操作系统的异步刷盘,而费劲周章的设计如此刷盘策略呢?
个人理解,作为一个成熟开源的组件,数据的安全性至关重要,还是要尽可能保证数据稳步有序落盘;OS的异步刷盘固然好使,但RocketMQ对其把控较弱,当操作系统crash或者断电的时候,造成的数据丢失影响不可控
4.2 同步刷盘
需要说明的是,如果FlushDiskType配置的是同步刷盘的话,那么此处数据一定已经被MappedByteBuffer写入了pageCache,接下来要做的便是真正的落盘操作。与异步落盘相似,同步落盘要根据配置项Message.isWaitStoreMsgOK()(等待消息落盘)来分别说明
同步刷盘的落盘线程统一都是GroupCommitService

4.2.1 不等待落盘ack
当前模式如图所示,整体流程比较简单,写入线程仅仅负责唤醒落盘线程,然后便执行后续逻辑,线程不阻塞;落盘线程每次休息10ms(可被写入线程唤醒)后,如果发现有数据未落盘,便将page cache中的数据强制force到磁盘
我们发现,其实相比较异步刷盘来说,同步刷盘轮训的时间只有10ms,远小于异步刷盘的500ms,也是比较好理解的。但当前模式写入线程不会阻塞,也就是不会等待消息真正存储到disk后再返回,如果此时反生操作系统crash或者断电,那未落盘的数据便会丢失
个人感觉,将FlushDiskType已经设置为Sync,表明数据会强制落盘,却又引入Message.isWaitStoreMsgOK(),来左右落盘策略,多多少少会给使用者造成使用及理解上的困惑
4.2.2 等待落盘ack
相比较上文,本小节便是数据需要真正存储到disk后才进行返回。写入线程在唤醒落盘线程后便进入阻塞,直至落盘线程将数据刷到disk后再将其唤醒
不过这里需要处理一个边界问题,即旧CommitLog的tail,及新CommitLog的head。例如现在有2个写入线程将数据写入了page cache,而这2个请求一个落在前CommitLog的尾部,另外一个落在新CommitLog的头部,这个时候,落盘线程需要检测到这两个消息的分布,然后依次将两个CommitLog数据落盘
五、线程模型
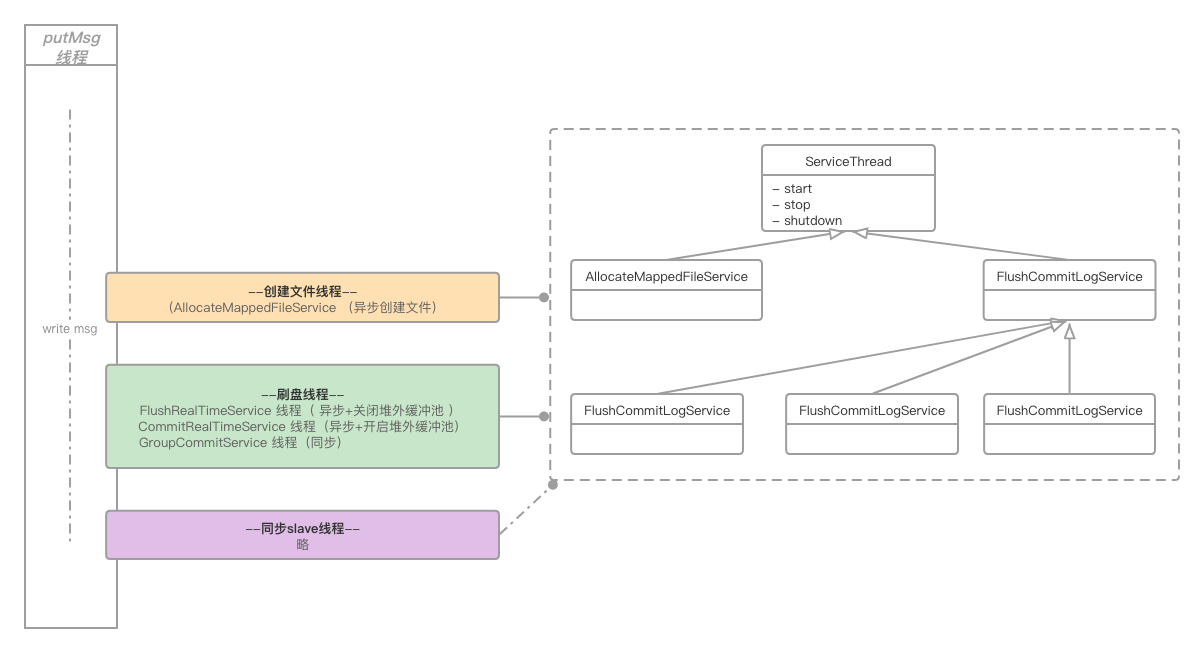
RocketMQ中所有的异步处理线程都继承自抽象类org.apache.rocketmq.common.ServiceThread,此类定义了简单的唤醒、通知模型,但并不严格保证唤醒,而是通过轮训作为兜底方案。实测发现唤醒动作在数据量较大时,存在性能损耗,改为简单的轮询落盘模式,性能提高明显
六、结束语
本章我们聚焦分析了一条消息在broker端落地的全过程,但整个流程还是比较复杂的,不过有些部分没有提及(比如说消息在master落地后是如何同步至salve端的),主要是考虑这些部分跟存储关联度不是很强,放在一起思路容易发散,这些部分会放在后文专门开标题阐述
RocketMQ架构原理解析(二):消息存储的更多相关文章
- RocketMQ架构原理解析(四):消息生产端(Producer)
RocketMQ架构原理解析(一):整体架构 RocketMQ架构原理解析(二):消息存储(CommitLog) RocketMQ架构原理解析(三):消息索引(ConsumeQueue & I ...
- RocketMQ架构原理解析(一):整体架构
RocketMQ架构原理解析(一):整体架构 RocketMQ架构原理解析(二):消息存储(CommitLog) RocketMQ架构原理解析(三):消息索引(ConsumeQueue & I ...
- RocketMQ架构原理解析(三):消息索引
一.概述 "索引"一种数据结构,帮助我们快速定位.查询数据 前文我们梳理了消息在Commit Log文件的存储过程,讨论了消息的落盘策略,然而仅仅通过Commit Log存储消息是 ...
- Tomcat 架构原理解析到架构设计借鉴
Tomcat 发展这么多年,已经比较成熟稳定.在如今『追新求快』的时代,Tomcat 作为 Java Web 开发必备的工具似乎变成了『熟悉的陌生人』,难道说如今就没有必要深入学习它了么?学习它我们又 ...
- Request 接收参数乱码原理解析二:浏览器端编码原理
上一篇<Request 接收参数乱码原理解析一:服务器端解码原理>,分析了服务器端解码的过程,那么浏览器是根据什么编码的呢? 1. 浏览器解码 浏览器根据服务器页面响应Header中的“C ...
- tomcat原理解析(二):整体架构
一 整体结构 前面tomcat实现原理(一)里面描述了整个tomcat接受一个http请求的简单处理,这里面我们讲下整个tomcat的架构,以便对整体结构有宏观的了解.tomat里面由很多个容器结合在 ...
- 分布式架构原理解析,Java开发必修课
1. 分布式术语 1.1. 异常 服务器宕机 内存错误.服务器停电等都会导致服务器宕机,此时节点无法正常工作,称为不可用. 服务器宕机会导致节点失去所有内存信息,因此需要将内存信息保存到持久化介质上. ...
- 消息中间件-技术专区-RocketMQ架构原理
RocketMQ是阿里开源的分布式消息中间件,跟其它中间件相比,RocketMQ的特点是纯JAVA实现:集群和HA实现相对简单:在发生宕机和其它故障时消息丢失率更低. 一.RocketMQ专业术语 P ...
- Scrapy框架的架构原理解析
爬虫框架--Scrapy 如果你对爬虫的基础知识有了一定了解的话,那么是时候该了解一下爬虫框架了.那么为什么要使用爬虫框架? 学习框架的根本是学习一种编程思想,而不应该仅仅局限于是如何使用它.从了解到 ...
随机推荐
- Liunx下Mysql,MongoDB性能优化的配置
场景 这几天在赶十一上线的项目,但是突然发现接口性能不好,高并发支持不住.又不想改代码,就在数据库层面进行优化. Mysql 分区:项目中有对40万条的数据进行时间查询的要求,就算对DateTime建 ...
- php页面 数组根据下标来排序
$a = [ ['id'=>1,'title'=>'星期二的早晨','author'=>'张三','date'=>'2021-6-1'], ['id'=>2,'title ...
- windows下如何查看所有端口及占用
1.在windows下查看所有端口: 先点击电脑左下角的开始,然后选择运行选项,接着我们在弹出的窗口中,输入[cmd]命令,进行命令提示符. 然后我们在窗口中输入[netstat -ano]按下回车, ...
- redis 5.0.12 install
redis 5.0.12 install ## check directory ls -l /XXXXXXX ##create dir mkdir -p /XXXXXXX/dataredis mkdi ...
- ShardingSphere 知识库更新 | 官方样例集助你快速上手
Apache ShardingSphere 作为 Apache 顶级项目,是数据库领域最受欢迎的开源项目之一.经过 5 年多的发展,ShardingSphere 已获得超 14K Stars 的关注, ...
- 关于 Binomial Coefficient is Fun
题目传送门 Solution 应该这个做法不是很常见吧. 我们设 \(f_{i,j}\) 表示前面 \(i\) 个数,选出的数和为 \(j\) 的贡献之和.因为我们有以下式子: \[\sum_{i=a ...
- 题解 CF241E Flights
题目传送门 题目大意 给出一个 \(n\) 个点 \(m\) 条边的 \(\texttt{DAG}\) ,给每条边设定边权为 \(1\) 或者 \(2\) ,使得 \(1\to n\) 的每条路径长度 ...
- 更好的 java 重试框架 sisyphus 入门简介
What is Sisyphus sisyphus 综合了 spring-retry 和 gauva-retrying 的优势,使用起来也非常灵活. 为什么选择这个名字 我觉得重试做的事情和西西弗斯很 ...
- 【数据结构与算法Python版学习笔记】递归(Recursion)——定义及应用:分形树、谢尔宾斯基三角、汉诺塔、迷宫
定义 递归是一种解决问题的方法,它把一个问题分解为越来越小的子问题,直到问题的规模小到可以被很简单直接解决. 通常为了达到分解问题的效果,递归过程中要引入一个调用自身的函数. 举例 数列求和 def ...
- .Net2.0连接PG数据注意事项
.Net2.0连接PG数据注意事项 第一次用.net操作PG[.NET2.0] 一:Npgsql版本问题 1:如果是.net2.0 建议用2.0.11.0[NuGet搜索npgsql第一个的最低版本 ...